mysql中limit深度分页详细剖析【爽文】
目录
一 mysql中limit深度分页
1.1 背景描述
1.2 mysql深度分页很慢原因
1.2.1 mysql的sql执行流程
1.2.2 mysql的深度分页很慢原因
1.3 解决办法
1.3.1 覆盖索引
1.3.2 子查询
1.3.3 标签查询
1.3.4 分区表
一 mysql中limit深度分页
1.1 背景描述
Limit深度分页造成慢sql,导致系统数据库cpu高负载,使用率爆满,其他业务的数据库请求无法得到及时响应。造成接口超时,最后,拖垮主服务器。
语法:select * from t limit m,n
分页查询时,我们会在LIMIT后面传两个参数,一个是偏移量(offset),一个是获取的条数(rows)。LIMIT分页查询的时间与偏移量值成正比。当偏移量越大时,查询时间越长。
| 偏移量 | 耗时 |
| 10w | 61 |
| 100w | 273 |
对于普通的业务而言,超过1秒的查询是绝对不可以忍受的。
1.2 mysql深度分页很慢原因
1.2.1 mysql的sql执行流程
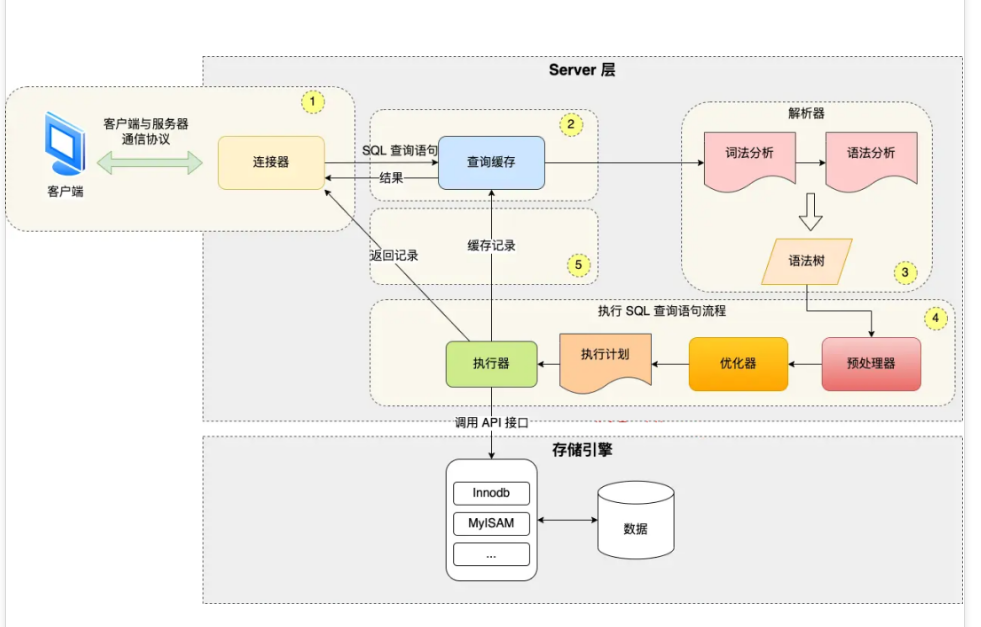
mysql服务端架构包括两层,server层和存储引擎层
1)server层:查询缓存,解析sql语句生成语法树,执行sql。
在执行sql中包括预处理器,优化器和执行器。
预处理器:将查询字段展开(如select * 展开为具体字段)并检查字段是否合法
优化器:指定sql执行计划,如选择合适的索引
执行器:与存储引擎层交互,执行sql语句
2)Engine层:存储引擎层 如InnoDB和MyISAM。
以InnoDB为例,访问B+树数据结构获取记录(聚簇索引,二级索引等的访问都在存储引擎层)
3)归结:对于limit m,n,则在引擎层返回m+n条数据,server层丢弃m条,返回n条数据给客户端。
1.2.2 mysql的深度分页很慢原因
mysql服务端架构包括两层,server层和存储引擎层
对于limit m,n,则在引擎层返回m+n条数据,server层丢弃m条,返回n条数据给客户端。https://mp.weixin.qq.com/s/LXvQMQFf_SyLWh1zI6onkA
当 Limit 抛弃的数据量太大的时候,server层的优化器认为索引扫描 的效率,甚至不如【全表扫描 +文件排序filesort】,于是将索引扫描优化为【全表扫描】。而一个大表的全表扫描,本身就是很慢的。
1.3 解决办法
1.3.1 覆盖索引
将查询的字段作为索引的子集或者全集;使用覆盖索引可以直接查询索引页,不必查找数据页;减少I/O次数,提高查询效率。
在val和name中加联合索引;如下,走覆盖索引
select val,name from test where val=4 limit 300000,5;
1.3.2 子查询
如果不能使用索引覆盖扫描,或者查询字段较多,可以尝试使用子查询。
先用子查询将需要查询的内容的id找到,然后主查询通过这些id,查询出需要的完整信息。
select * from test where id in (select id from test where val=5 limit 200000,10);
这样,Mysql 先执行子查询,在 val 索引上进行范围扫描,并返回 10个 id 值。然后,Mysql 再执行主查询,在 id 索引上进行点查找,并返回所有字段。这样,Mysql 只需要扫描10个数据页,而不是200010个数据页,提高了查询效率。
1.3.3 标签查询
使用这种方式,表中必须有连续自增id的情况下才能使用。上一次查询的最后一条的数据id,代入本次查询,作为起始位置,进行pagesize翻页。这样的话,后面无论翻多少页,性能都会不错的,因为命中了id索引。但是这种方式有局限性:需要一种类似连续自增的字段。
select id,name,balance FROM account where id > 100000 limit 10;
1.3.4 分区表
如果表中数据分布不均匀,将表进行分区,查询时候查询某个范围的区域,而不是整个表中数据,则可以提高查询效率。
如果按照 val 字段将 test 表分成 10 个分区表(test_1 到 test_10),每个分区表只存储 val 等于某个值的记录,可以执行以下语句:
select * from test_4 limit 300000,5;
这样,Mysql 只需要访问 test_4 这个分区表,而不需要访问其他分区表,提高了查询效率。