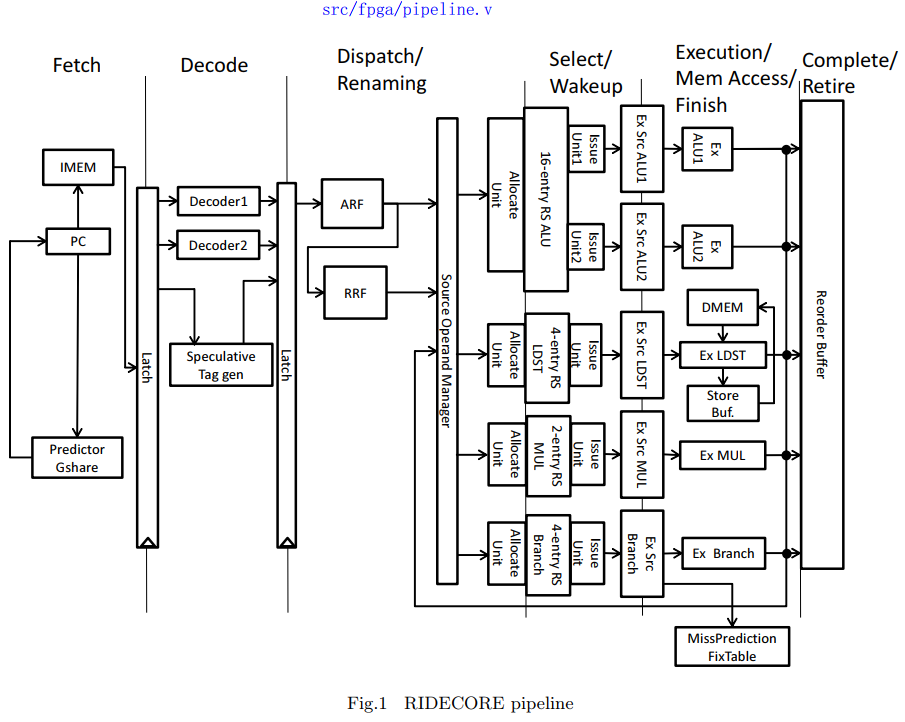
文章目录 流水线stage分属前后端 PC pipeline IF ID DP DP 与 SW 中间没有latch SW COM
IF -> ID -> DP -> SW -> EX -> COM
分类 阶段 说明 前端 IF 指令获取阶段。PC 使用分支预测器,访问指令存储器。典型前端操作。 前端 ID 解码并寄存器重命名,这仍然属于前端操作,因为没有开始实际执行。 中间(交界处) DP 分发阶段是前端和后端的“桥梁”:它决定指令是否能够进入执行系统(Reservation Station)。 后端 SW Issue 阶段已经涉及硬件调度和等待执行资源。 后端 EX 执行阶段。指令在对应的执行单元中运行。 后端 COM 提交/写回阶段,更新寄存器状态和 ROB,彻底属于后端。
Dispatch(DP)阶段通常被认为是“前端的最后阶段”或者“前后端的分界点”。它从解码器/ 寄存器重命名器中取出指令,并将它们放入合适的 Reservation Station(RS)。你可以把它看成是:前端准备好的指令交给后端执行的关键一步,所以分析系统时,很多资料会将 DP 归为前端,但也有资料将它作为交界点来单独分析。结论:DP 更偏向前端,但有一定后端属性。
PC的值根据优先级优先级1 ( top) : reset时 : ENTRY_POINT 优先级2 : prmiss : jmpaddr : stall_IF : pc : 其余情况 : npc
1.指令的获取及invalid // 不考虑
2.npc的计算
npc的计算gshare 命中 : btb中计算出来的 地址第二条指令 invalid : pc+ 4 其他 : pc+ 8 gshare 的设计 模块BHR PHT PCBTB 流程在每个时钟的负边沿,使用的读取地址是 PC[ 12 : 3 ] 和 BHR 做异或(⊕)得到的结果, 从 PHT 中读取预测信息. 如果( 读出的值大于1 , 即2 或3 ) 跳转(Taken):用 PC 查 BTB → 得到 跳转目标地址将目标地址 更新到 npc否则(Not Taken):npc += 4 or 8 (顺序执行)模块读写BHR 的读写会基于当前预测结果进行更新;但如果最终证明预测是错误的,BHR 会回滚到更新前的状态。因此,在每次更新之前,BHR 都会先被备份。PHT 的读写 读一个用于 IF 阶段;一个用于 COM 阶段。写一个写端口用于 COM 阶段的写操作 BTB 的读写TODO1. 按地址 0x4 取指, 那么 inst2 会 invalid 吗 ? 另外, 岂不是 会存在 一拍 没有 inst2 发送到后端 会是的,确实会出现某一拍中只有一条有效指令(Inst1)被送入 IF/ ID latch。
1. 给 每一条处于投机路径的指令 分配一个 Speculative Tag
2. 解码
项目 内容 功能 为每条投机路径上的指令分配 Speculative Tag,以支持分支恢复 核心输出 sptagN 和 speculativeN使用者 Decoder、Dispatch、ROB、RS(Reservation Station)、Commit 等 解决问题 精确追踪投机指令,支持分支预测失败时快速恢复系统状态
模块 主要用途 寄存器重命名 tag(如RRF中分配的物理寄存器编号) 建立写后读/写后写依赖关系,支持乱序执行 投机 tag(Tag Generator 生成) 标记哪些指令是投机的,支持错误恢复
以一个预测成功的分支为例:
分支指令 B 发射 → branchvalid1=1, enable=1 Tag Generator: 分配一个新的 Tag(比如 00010) 设置 sptag1=00010, speculative1=1 tagreg 左移(进入下一轮准备)brdepth+1 后续投机指令 C、D、E 都被分配同样的 sptag=00010 如果分支 B 后来预测成功(prsuccess=1): brdepth--,该 Tag 被释放,其他无影响 如果分支 B 后来预测失败(prmiss=1): tagreg ← tagregfix(恢复到分支预测前状态)brdepth ← 0所有 sptag==00010 的指令都将被清除(flush) 阶段 动作 模块 说明 IF 预测(Prediction) Branch Predictor(BTB / GShare) 猜跳不跳、跳到哪,控制 PC ID 恢复环境(Prediction) Speculative Tag gen 跟踪指令的投机状态 EX 验证(Resolution) exunit_branch分支指令实际执行,看预测对不对,发出 prsuccess / prmiss 信号
1.为每个指令中的"被写入寄存器" 分配 rename register
2.
tag generator 与 寄存器重命名机制 原理 tag generator避免 写后读(RAW)( Read After Write) 、写后写(WAW)、读后写(WAR) 等寄存器冲突( 乱序执行导致的冲突) 问题,会使用寄存器重命名机制每条指令的目标寄存器在进入后端之前都会被重新命名为一个“Tag”,这个 tag 是由 Tag Generator 生成的。
模块 功能 Tag Generator 为目标寄存器生成唯一的标识符(Tag),用于寄存器重命名与依赖跟踪 所在阶段 通常在 Decode 或 Dispatch 阶段 在乱序中的地位 关键,维持指令依赖关系和正确性
模块Architected Register File ( ARF) :程序员视角下的寄存器集合(逻辑寄存器)Rename Register File ( RRF) :物理寄存器集合(或者是寄存器标记表)Reorder Buffer ( ROB) :保持提交顺序,支持恢复/ 回滚Tag Generator:为每条指令分配唯一标识符(tag),表示结果的位置
步骤 描述 分配 tag 为每个目标寄存器分配唯一 tag 更新 Rename Table 建立逻辑寄存器到物理 tag 的映射 消除冒险 使用 tag 跟踪依赖,避免多个指令写同一个寄存器 回写/提交 使用 ROB 确保乱序执行但顺序提交
如果只是顺序执行,那么根本不需要引入 RRF
为了支持乱序执行,必须引入物理寄存器(RRF)来保存未提交的指令结果,并通过 tag 建立依赖关系,使得即使写同一个逻辑寄存器也能正确调度。
乱序执行了之后,也需要计算依赖,然后重新执行吧,是不是浪费资源了只有发生 分支错误预测 时,才需要回滚和重新执行后续指令。这种情况虽然代价高,但在正确率高的预测器(如 Gshare)下,概率已经较低。