Linux操作系统之进程(一):进程属性与进程创建
目录
前言
什么是进程?
进程的管理
为什么需要PCB?
proc目录
PCB的exe与cwd属性
父子进程关系
总结
前言
在上一节课中,我们了解到操作系统是计算机系统的"大管家",负责管理所有软硬件资源。今天,我们聚焦这个大管家如何管理其中最重要的资源之一——进程。
关键概念:进程 = 内核数据结构(task_struct) + 程序的代码和数据
什么是进程?
想象一下,操作系统就像一家大型医院的院长,而进程就是医院里的各个科室和医护人员。院长不需要知道每个医生具体怎么给病人看病,但他需要知道:
- 医院有多少科室在运行
- 每个科室需要多少资源
- 如何协调各科室的工作
这就是操作系统对进程的管理!
进程的直观理解:进程 = 正在运行的程序。
但更准确地说:
进程 = 内核数据结构(task_struct) + 程序的代码和数据(我们后面会更加深入理解这句话)
我们可以用烹饪来类比:
- 程序:就像菜谱(静态的指令集合)
- 进程:就是实际按照菜谱烹饪的过程(动态的执行实体)
进程的管理
操作系统需要管理进程,因为:
- 资源分配:CPU时间、内存、IO设备等资源有限
- 隔离保护:防止进程相互干扰
- 效率提升:通过并发执行提高系统吞吐量
就像医院院长需要管理:
- 哪些手术室分配给哪个科室
- 确保一个科室的传染病不会影响其他科室
- 合理安排医护人员提高医院整体效率
操作系统想要管理进程,就需要通过进程的属性数据来管理。因此,操作系统会为进程创建一个数据结构,在linux中叫做 struct PCB(process control block)。
PCB就像进程的完整档案,包含操作系统管理进程所需的所有信息。没有PCB,操作系统就无法有效管理进程。而这个结构体里面含有各种参数,例如pid,status等等,通过这些参数,操作系统就可以轻松知道进程的状态,从而对其进行管理。
关键信息如表格所示:
| 属性类别 | 具体属性 | 说明 | 类比解释 |
|---|---|---|---|
| 标识信息 | pid | 进程唯一ID | 医生的工号 |
| ppid | 父进程ID | 所属科室主任 | |
| 状态信息 | state | 进程状态 | 医生是在坐诊/休息/手术中 |
| 资源信息 | memptr | 内存指针 | 医生使用的诊室和器材 |
| files | 打开的文件 | 医生正在查看的病历 | |
| 调度信息 | priority | 优先级 | 急诊医生优先 |
| counter | 时间片剩余 | 看诊剩余时间 | |
| 文件系统 | exe | 可执行文件路径 | 医生的专业资格证书 |
| cwd | 当前工作目录 | 医生当前所在的诊室 |
在PCB的内部,有个内存指针:void * memptr(通过这个指针就可以直接或间接找到自己的代码与数据)。同时也有个struct task_struct * next指针,这个指针会让我们找到下一个PCB结构体对象的位置,形成一个链表,我们称之为:struct task_struct* Task_list,这个Task_list就类似于学生的花名册,因此操作系统对进程的管理,就变成了对数据结构的增删查改(这里在上一篇文章中也有介绍) ,类比于你投递简历,本质就是HR在通过这个链表,根据需求条件(PCB的优先级)筛选每一个PCB(简历)。
运行起来的程序→是因为:进程会被根据task_struct属性被os调度,运行、
所以, 进程 = 内核数据结构(task_struct) + 程序的代码和数据。
为什么需要PCB?
PCB就像进程的身份证,包含了管理进程所需的所有信息。没有PCB,操作系统就无法有效管理进程。
想象你去医院看病,医院需要你的病历档案(PCB)来记录你的各种信息,才能提供合适的治疗(CPU时间片)。
关于PCB的属性上文已有提到,我们可以通过系统调用来获取到这些属性:(以PID为例)
我们在linux服务器上有以下文件:
Makefile:
# 定义编译器和编译选项
CXX = g++
CXXFLAGS = -Wall -std=c++11# 定义目标文件和可执行文件名
TARGET = proc
SRC = proc.cpp# 默认目标
all: $(TARGET)# 直接生成可执行文件(不生成.o文件)
$(TARGET): $(SRC)$(CXX) $(CXXFLAGS) -o $@ $<# 清理生成的文件
clean:rm -f $(TARGET)# 运行程序
run: $(TARGET)./$(TARGET).PHONY: all clean runproc.cpp:
#include<iostream>
using namespace std;
#include <sys/types.h>
#include <unistd.h> int main()
{cout << "my pid: " << getpid() << endl;cout << "my ppid: " << getppid() << endl;return 0;
}我们在linux终端运行Makefile生成可执行exe文件后运行文件,得到一个结果:
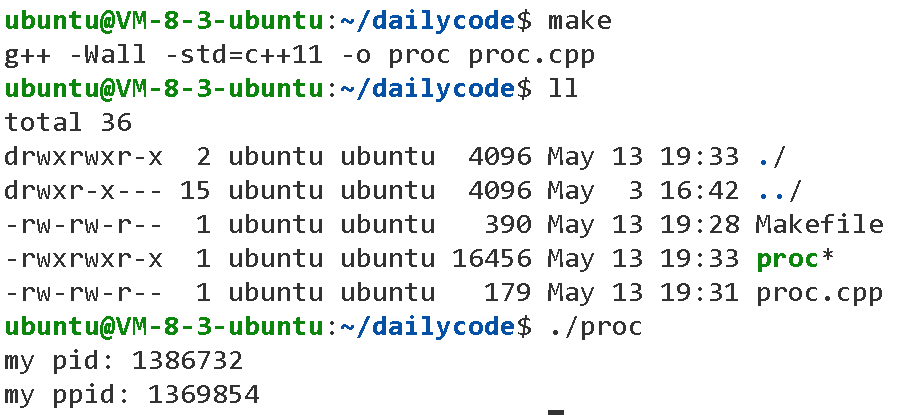
可以看到PID已经被获取并打印出来了。
getpid与getppid分别就是获取本进程的pid与ppid的系统调用接口。
我们可以将proc.cpp代码更改为循环代码:
proc.cpp:
#include<iostream>
using namespace std;
#include <sys/types.h>
#include <unistd.h> int main()
{cout << "my pid: " << getpid() << endl;cout << "my ppid: " << getppid() << endl;while(1){cout << "my pid: " << getpid() << endl;sleep(1);}return 0;
}重新生成可执行文件后运行该代码,我们让程序每隔一秒钟打印一次自己的pid信息。
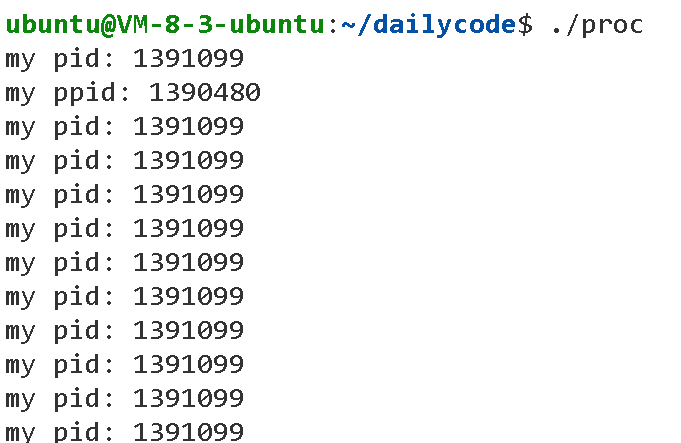 这个时候,我们打开另外一个终端登录相同的,输入以下指令:
这个时候,我们打开另外一个终端登录相同的,输入以下指令:
ps ajx | head -1 && ps ajx | grep proc | grep -v grep 这个命令组合用于查看和筛选进程信息,具体解释如下:
命令分解:
-
ps ajx | head -1ps ajx:显示所有进程的详细信息(BSD风格格式)a:显示所有用户的进程j:显示任务控制信息(PGID/SID等)x:包括没有控制终端的进程
| head -1:只输出第一行(即表头信息)
-
ps ajx | grep proc | grep -v grepps ajx:同上,显示所有进程信息| grep proc:筛选包含"proc"关键字的行| grep -v grep:排除掉包含"grep"的行(避免显示grep进程自身)
组合效果:
- 先显示进程列表的表头(列名)
- 然后显示所有包含"proc"关键字的进程(排除grep自身)

我们可以看到最下面有一个进程的PID正是我们运行的proc程序所在的PID:1391099。所以我们运行的proc就是个进程。由此我们可以知道,把程序(指令本身也是)运行起来,本质上就是在系统中启动了一个进程。
而进程分为两种,第一种是执行完就退出。比如ls、pwd的命令。第二种是一直不退,直到用户退出,命名为常驻进程。
系统中会有许多进程,若用进程名字(字符串)来比较或管理就会很麻烦,所以起了一个编号叫做进程的PID,而所谓的PPID,就是这个进程的父进程的PID(后面进程创建会有所介绍)
PID就像进程的身份证号码,具有唯一性。同一个程序在不同时间启动,会有不同的PID。
怎么停止一下正在运行的进程呢?在终端中,当我们按下ctrol + c时,就会强制让进程结束,实际上,是因为内部使用了kill 命令来杀死进程。
kill 是 Linux/Unix 系统中用于向进程发送信号(signal)的命令(信号大家先不用理解),主要用于终止、暂停或控制进程的行为。有着多种选项如下:

我们可以通过选项9来杀死进程:kill -9 <PID>...
proc目录
在linux相同的根目录下,通常有个子目录叫做proc。这个目录下存放着多种信息,包括进程等信息。
我们可以通过/proc目录查看进程的详细信息:

PCB的exe与cwd属性
进行以下操作:
1、继续允许上面的无限循环的代码proc.cpp.
2、随后我们继续在另一个终端中找到/proc目录查看进程信息

进入对应进程PID的目录,可以看到cwd与exe两个属性
说明,exe 是进程控制块(PCB,如 Linux 的 task_struct)中的一个关键属性,表示进程对应的可执行文件的绝对路径
3、尝试删除正在运行的程序:
kill -9 1402057
再次查看/proc/1402057/exe,你会发现它显示为deleted,但进程仍在运行!这是因为程序已经被加载到内存中了。
而cwd又是什么呢?
我们在进行文件管理操作时,进程会用到fopen,当打开一个不存在的文件时,我们通常会在当前目录创建一个同名文件,那操作系统怎么知道当前目录呢?这就是进程的cwd所代表的含义:进程的当前工作目录。
当进程使用相对路径(如 ./file.txt 或 ../data/)访问文件时,系统会基于 CWD 解析完整路径。例如,若 CWD 是 /home/user,则 ./doc.txt 会被解析为 /home/user/doc.txt。最终新建文件时,实际上是一个全路径。
我们可以通过chdir系统调用接口来更改进程的cwd:

父子进程关系
在Linux中,除了init进程(PID为1)外,所有进程都有父进程。当我们从命令行运行程序时,实际上是bash(bash是命令行解释器)进程创建了子进程来执行我们的代码。
我们可以用fork()系统调用创建子进程:

因此,当使用fork创建子进程失败时,会返回负数,对于父进程,会返回子进程的pid,对于子进程,会返回一个0。
所以fork()会返回两次!在父进程中返回子进程的PID,在子进程中返回0。这是因为fork创建的新进程会复制父进程的PCB,然后两者都从fork调用后继续执行,随后父子进程分别执行了一次return,导致返回了两个pid_t的数据。
对于父子进程来说,他们的代码一般来说是共享的,但是数据确实格子独立私有一份的,这就是进程的独立性。即使是父子进程也是如此。让我们看个例子:
更改proc.cpp代码如下:
#include<iostream>
using namespace std;
#include <sys/types.h>
#include <unistd.h> int gval=0;int main()
{pid_t id = fork();//之后会有两个进程运行相同的代码,对于子进程来说,id返回值为0,对于父进程来说,id返回值为子进程的pid//fork之后谁先运行由调度器自己决定,所以父子进程的打印顺序不一定//fork之后,父子进程各自有自己的代码段,数据段,堆,栈,文件描述符表,//但是共享正文段,全局变量,常量,环境变量,用户id,宿主id,工作目录,信号处理方式if(id == 0){//子进程while(1){cout << "I am child" << " gval: " << gval << endl;gval += 1;sleep(1);}}else if(id > 0){//父进程while(1){cout << "I am parent" << " gval: " << gval << endl;sleep(1);}}
}
运行proc,有以下现象:
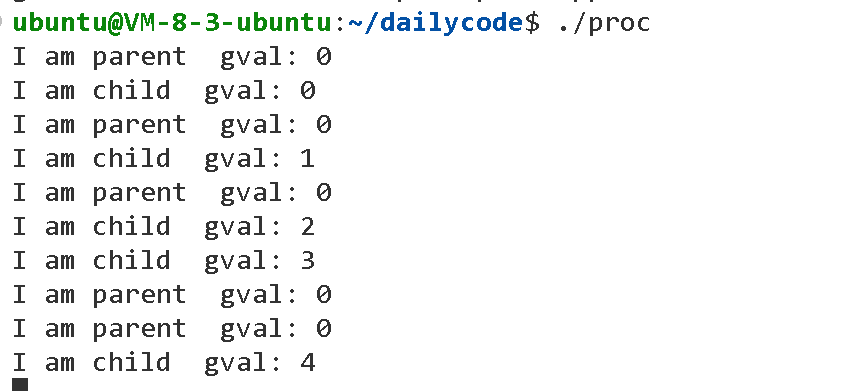
对于这个代码,对于全局变量gval,父进程进行只读操作,子进程进行改写的加加操作,发现同一个全局变量,但打印结果不同,说明数据各自独立一份。
总结
关键知识点总结
-
进程的本质
- 进程是运行中的程序,由代码、数据和PCB(进程控制块)组成。
- PCB(
task_struct)是进程的核心数据结构,存储所有管理信息(如PID、状态、资源等)。
-
进程的标识
- PID(进程ID):唯一标识一个进程。
- PPID(父进程ID):标识创建该进程的父进程(除
init进程外,所有进程都有父进程)。
-
进程的独立性
- 每个进程拥有独立的内存空间和运行环境,即使父子进程也数据隔离(修改互不影响)。
-
进程的查看与管理
-
/proc文件系统:可查看进程详细信息(如/proc/<PID>/cwd、/proc/<PID>/exe)。 -
fork()系统调用:创建子进程,父子进程代码共享,数据独立。
-
-
进程的工作目录
- CWD(Current Working Directory):进程访问文件的基准路径,影响相对路径解析。
- EXE 是进程控制块(PCB)中的一个关键属性,表示进程对应的可执行文件的绝对路径
核心结论
- 操作系统通过PCB管理进程,进程的运行、资源分配、隔离均依赖PCB。
-
fork()是进程创建的基石,父子进程的独立性保障了系统稳定性。 - CWD决定了文件访问的基准路径,是进程环境的关键组成部分。
理解这些概念对深入学习Linux系统编程至关重要。希望这篇博客能帮助你更好地理解进程属性!如果有任何问题,欢迎在评论区留言讨论。