Transformer LLM
NLP任务可以分类成:
(1)判别式任务:给定一个句子,希望得到某种分类结果,例如情感分析、文本分类、文本蕴含等;
(2)生成式任务:给定一个句子,想要生成下一个词元,语言建模,例如机器翻译。
方法:
(1)RNN循环神经网络
(2)CNN卷积神经网络
(3)LSTM
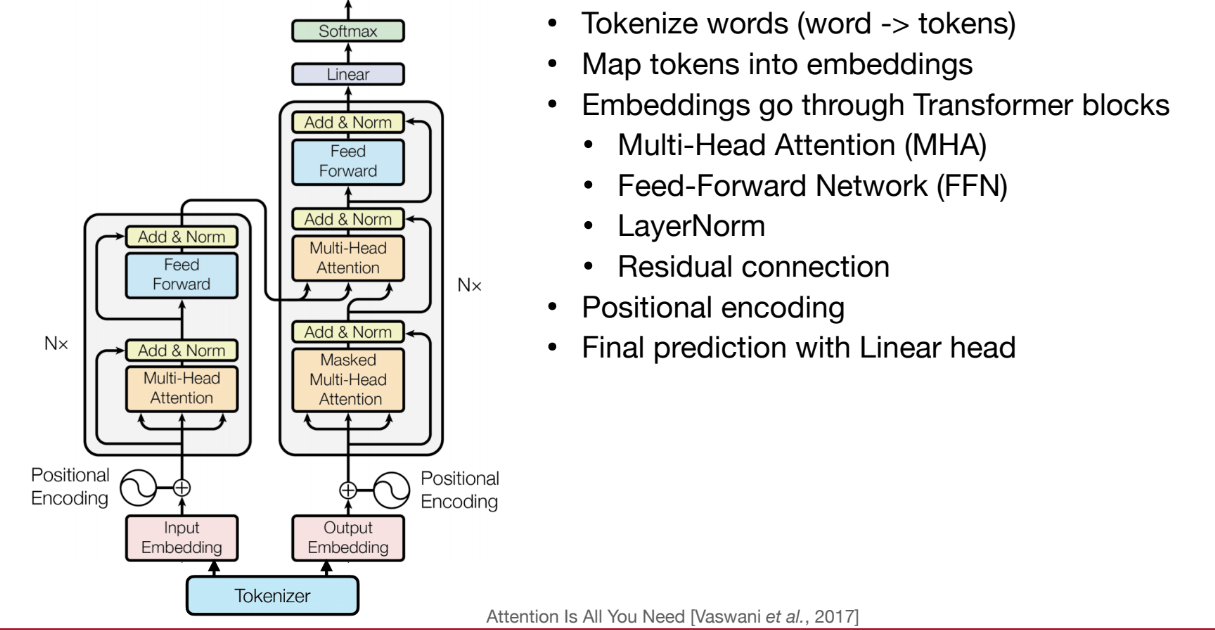
1. Tokenize words
A tokenizer maps a word to one/multiple tokens.

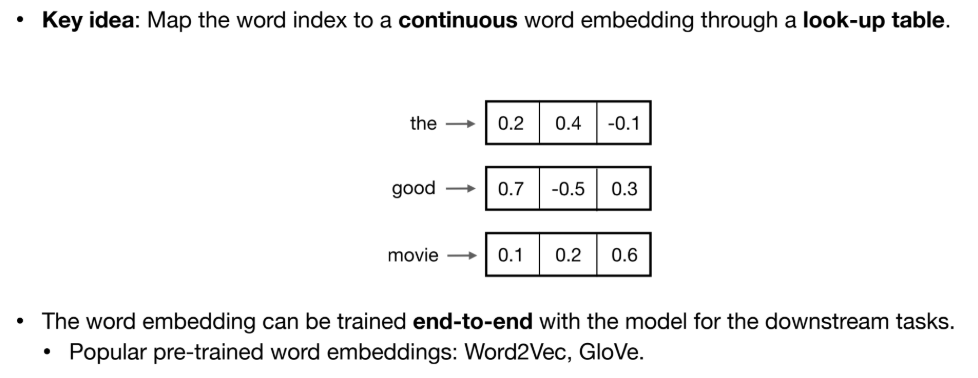
2. embeddings
词表中有很多单词,每个单词使用一个数组表示,将单词编码成数字。
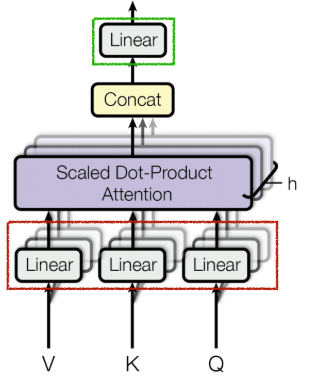
3. Multi-Head Attention (MHA)
(1)Self-Attention
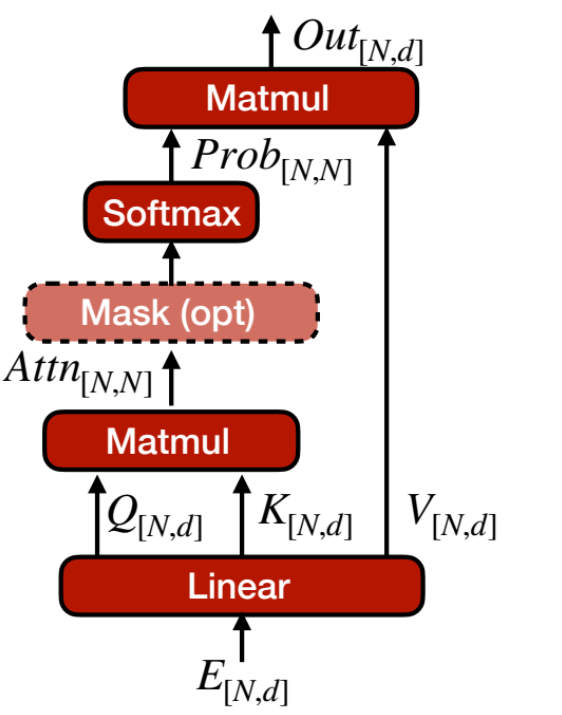
Attention(Q,K,V) = softmax(Q * K^T / sqrt(d_k)) V;
(2)Multi-Head Attention
想要建模的是多种多样的关系,由于存在多种关系,需要引入多头注意力机制,让每个头捕捉不同的语义信息。

(3)Attention Masking
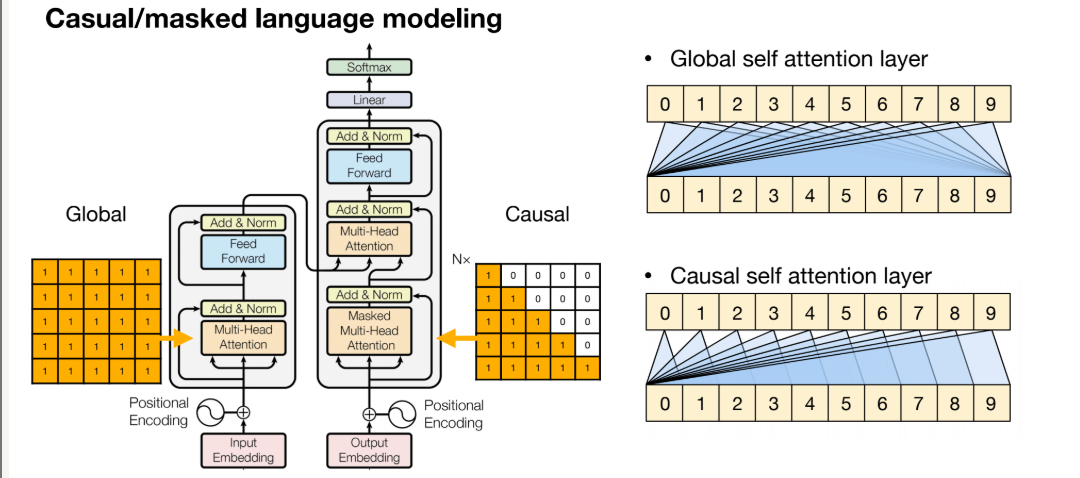
注意力掩码,有两种,一种是因果掩码,另一种是全局掩码
全局注意力:每个词元都能看到其他所有词元,甚至包括未来的词元
因果掩码:每个词元只能看到它之前的所有内容,但看不到之后的任何信息
4. Feed-Forward Network(FFN)
由于自注意力机制专注于建模词元之间的关系,因此它并不包含逐元素的非线性变换。
不仅要建模词元之间的关系,还要赋予模型一定的能力,使其能够独立地处理每个词元,因此我们加入了前馈网络,即全连接层,以增强对局部特征的建模能力。

5. Layer Norm(LN)