【大模型学习】项目练习:文档对话助手

✨ 个人主页:在线OJ的阿川
💖文章专栏:AI入门到进阶
🌏代码仓库:
写在开头
现在您看到的是我的结论或想法,但在这背后凝结了大量的思考、经验和讨论


📚目录
- 一、设计思路
- 二、具体流程操作
- 三、想说的话
🚀实现视频脚本生成器
文档对话助手

一、⛳设计思路
本文档对话助手采用模块化设计,主要包含二大核心模块:
- 后端模块:将上传的pdf文件传入本地,并使用文本分割,再训练开源的GPT4AllEmbeddings嵌入模型,使用FAISS向量存储库,创建检索器,最终传入参数使用对话检索链,返回对话的结果
- 前端模块:Streamlit前端及部署云和调用后端代码,实现pdf上传和历史消息及新对话
说明:
编译器为Visual Studio code,Python版本为3.12,安装库(requirements.txt)为:
aiohappyeyeballs==2.6.1
aiohttp==3.12.13
aiosignal==1.3.2
altair==5.5.0
annotated-types==0.7.0
anyio==4.9.0
attrs==25.3.0
blinker==1.9.0
cachetools==6.1.0
certifi==2025.6.15
charset-normalizer==3.4.2
click==8.2.1
colorama==0.4.6
dataclasses-json==0.6.7
distro==1.9.0
faiss-cpu==1.11.0
frozenlist==1.7.0
gitdb==4.0.12
GitPython==3.1.44
gpt4all==2.8.2
greenlet==3.2.3
h11==0.16.0
httpcore==1.0.9
httpx==0.28.1
httpx-sse==0.4.1
idna==3.10
Jinja2==3.1.6
jiter==0.10.0
jsonpatch==1.33
jsonpointer==3.0.0
jsonschema==4.24.0
jsonschema-specifications==2025.4.1
langchain==0.3.26
langchain-community==0.3.26
langchain-core==0.3.67
langchain-deepseek==0.1.3
langchain-openai==0.3.27
langchain-text-splitters==0.3.8
langsmith==0.4.4
MarkupSafe==3.0.2
marshmallow==3.26.1
multidict==6.6.3
mypy_extensions==1.1.0
narwhals==1.45.0
numpy==2.3.1
openai==1.93.0
orjson==3.10.18
packaging==24.2
pandas==2.3.0
pillow==11.3.0
propcache==0.3.2
protobuf==6.31.1
pyarrow==20.0.0
pydantic==2.11.7
pydantic-settings==2.10.1
pydantic_core==2.33.2
pydeck==0.9.1
pypdf==5.7.0
python-dateutil==2.9.0.post0
python-dotenv==1.1.1
pytz==2025.2
PyYAML==6.0.2
referencing==0.36.2
regex==2024.11.6
requests==2.32.4
requests-toolbelt==1.0.0
rpds-py==0.26.0
six==1.17.0
smmap==5.0.2
sniffio==1.3.1
SQLAlchemy==2.0.41
streamlit==1.46.1
tenacity==9.1.2
tiktoken==0.9.0
toml==0.10.2
tornado==6.5.1
tqdm==4.67.1
typing-inspect==0.9.0
typing-inspection==0.4.1
typing_extensions==4.14.0
tzdata==2025.2
urllib3==2.5.0
watchdog==6.0.0
yarl==1.20.1
zstandard==0.23.0
二、🎉具体流程操作
2.1 安装虚拟环境
方式一:使用anaconda安装(不推荐)
1.下载anaconda
2.打开
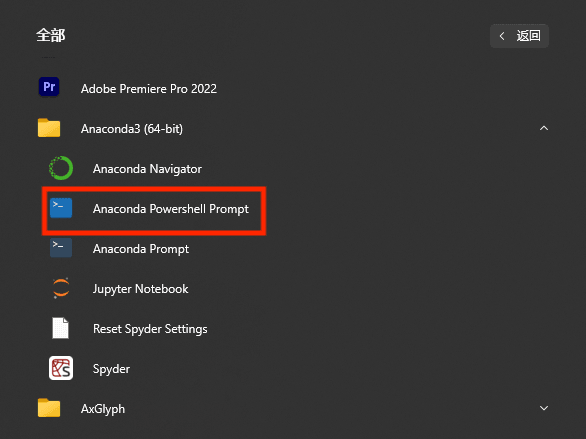
3.创建并进入虚拟环境
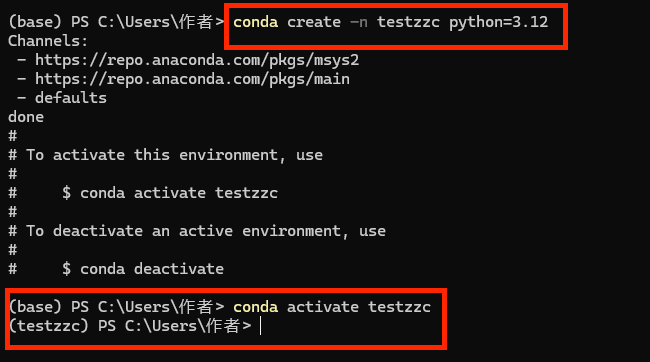
4.正常安装相应的库即可

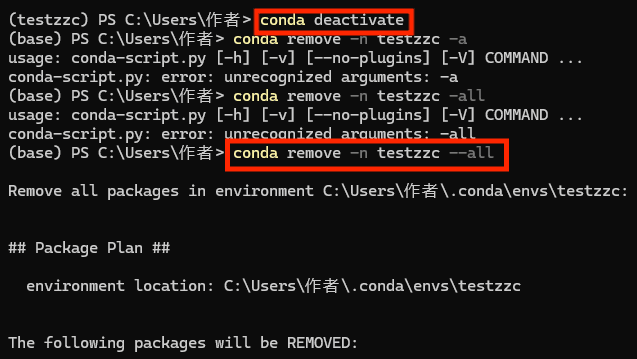
5.删除虚拟环境(可选)
先退出当前虚拟环境,再删除虚拟环境
6.打开vscode选择虚拟环境

方式二:直接在Visual Studio code创建虚拟环境(推荐)
1.根据图操作
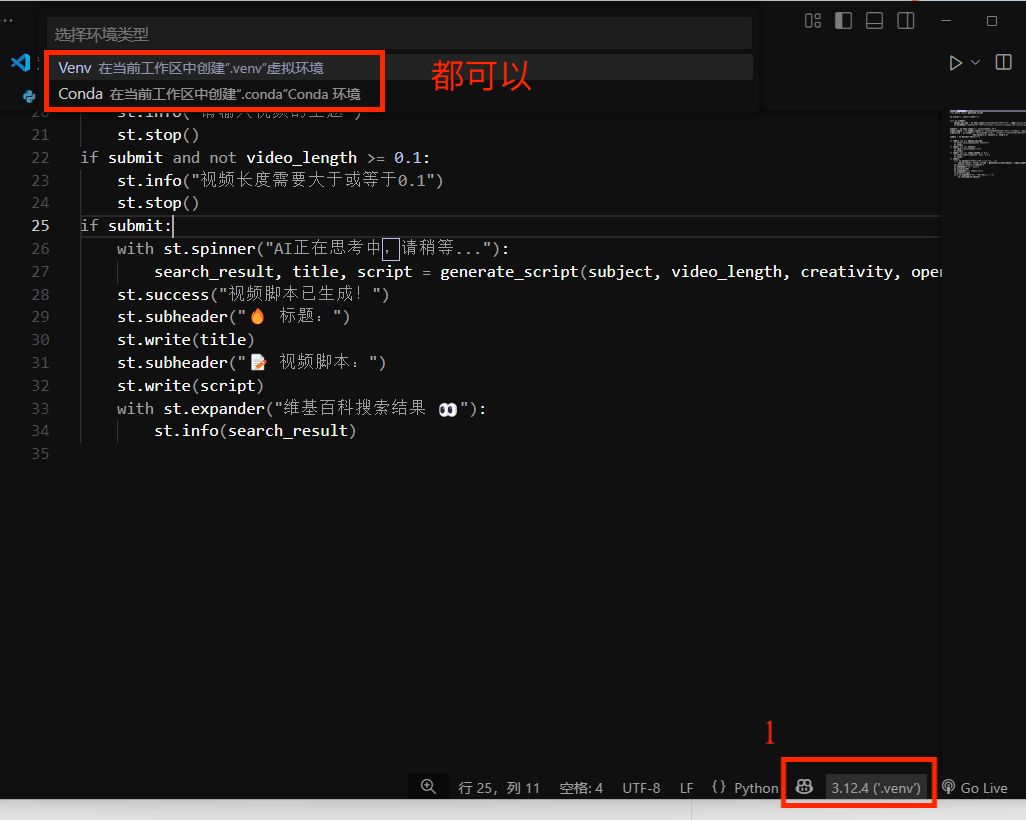
2.找到Python安装环境配置即可
3.进入虚拟环境

4.退出虚拟环境(可选)

或者
1.打开终端,直接输入

2.进入虚拟环境
2.2 安装相应的库
1.打开终端
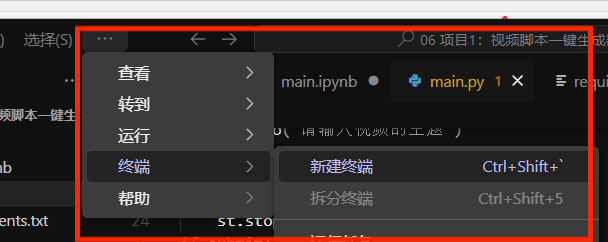
2.进入虚拟环境
3.输入

注意: requirements.txt自己把相应的库创建出txt文件
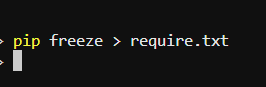
4.导出相应的库 (可选)
打开终端,输入:
2.3 后端
主要实现功能:
1.回答获取:主要使用LangChain中的对话检索链,参数模型选用DeepSeek的R1模型,检索器为文本分割嵌入模型存储到FAISS向量库的检索器。–Langchain文档
2.记忆获取:使用Langchain中的对话检索链的参数键chat_history
from langchain.chains import ConversationalRetrievalChain # 对话检索链
from langchain_community.document_loaders import PyPDFLoader # PDF加载库
from langchain_community.vectorstores import FAISS # 向量存储库
from langchain_community.embeddings import GPT4AllEmbeddings #嵌入模型
from langchain_deepseek import ChatDeepSeek # DeepSeek聊天模型
from langchain_text_splitters import RecursiveCharacterTextSplitter #文档分割 def main_logic(deepseek_api_key, memory, file, ask):model = ChatDeepSeek(model="deepseek-reasoner", api_key=deepseek_api_key)file_content = file.read() # 读取上传的PDF文件内容,返回二进制数据temp_path = "temp_path.pdf" # 临时文件路径with open(temp_path, "wb") as temp_file: # 将二进制数据写入临时文件,作为本地路径temp_file.write(file_content)post = PyPDFLoader(temp_path) # 传入本地路径pdfs = post.load() # 加载PDF文档text_split = RecursiveCharacterTextSplitter(chunk_size=1500, # 每块文档最大字符大小chunk_overlap=50, # 重叠部分,避免信息丢失separators=["\n", "。", "!", "?", ",", "、", ""] # 中文分割符)texts = text_split.split_documents(pdfs) # 分割文档为多个文本块hf = GPT4AllEmbeddings(model_name="all-MiniLM-L6-v2.gguf2.f16.gguf",gpt4all_kwargs={'allow_download': 'True'})db = FAISS.from_documents(texts, hf) # 使用FAISS向量存储库存储文本块retriever = db.as_retriever() # 创建检索器conver_chain = ConversationalRetrievalChain.from_llm( # 创建对话检索链llm=model,retriever=retriever,memory=memory)response = conver_chain.invoke({"chat_history": memory, "question": ask}) # 调用对话检索链,参数键传入历史对话和问题return response # 返回键包含 "answer" 键(回答内容)和 "source_documents" 键(引用的文档)
2.4🚀前端
主要实现功能:
1.历史消息:主要利用后端的对话检索链的参数键chat_history实现
2.pdf上传:主要使用file_uploader实现
3.对话展示:主要利用会话状态的messages搭配chat_message实现
4.重置对话:主要利用重置会话状态实现
import streamlit as st # 导入Streamlit库from langchain.memory import ConversationBufferMemory # 导入对话记忆
from backend import main_logic # 导入后端col1, col2, col3 = st.columns([1, 2, 1])
with col2:st.title(" 🤖 文档对话助手")with st.sidebar: # 在侧边栏中输入DeepSeek API密钥deepseek_api_key = st.text_input("请输入DeepSeek API密钥:", type="password")st.markdown("[获取DeepSeek API key](https://platform.deepseek.com/api_keys)")st.divider() # 添加分隔线if "chat_history" in st.session_state:with st.expander("历史消息"):for i in range(0, len(st.session_state["chat_history"]), 2):human_message = st.session_state["chat_history"][i] # 获取人类消息ai_message = st.session_state["chat_history"][i+1] # 获取AI消息st.write(human_message.content) # 显示人类消息内容st.write("AI:",ai_message.content) # 显示AI消息内容if i < len(st.session_state["chat_history"]) - 2: # 如果不是最后一轮消息,则添加分隔线st.divider()if "memory" not in st.session_state: # 如果会话状态中没有记忆,则初始化记忆st.session_state["memory"] = ConversationBufferMemory( # 对话记忆return_messages=True,# 返回消息memory_key="chat_history", # 记忆键output_key="answer" # 输出键)st.session_state["messages"] = [{"role": "ai","content": "**铁子,我是本地文档对话客服,可以根据你上传的文档进行对话,有什么可帮你的吗?**"}] # 初始消息pdfs = st.file_uploader("上传PDF文件:", type="pdf") # 上传PDF文件,accept_multiple_files=True允许多文件上传
for message in st.session_state["messages"]: # 遍历会话状态中的消息st.chat_message(message["role"]).write(message["content"]) # chat_message用于显示不同角色的消息,这里是AI角色question = st.chat_input("你好呀",disabled=not pdfs) #disabled参数根据是否上传文件来决定是否可以输入if question:if pdfs and question and not deepseek_api_key: # 如果上传了文件和问题,但没有输入API密钥st.info("请输入你的DeepSeek API密钥")st.stop()st.session_state["messages"].append({"role": "human", "content": question})st.chat_message("human").write(question)with st.spinner("AI正在思考中,请稍等..."):response = main_logic(deepseek_api_key, st.session_state["memory"],pdfs, question)msg = {"role": "ai", "content": response["answer"]} # 保存AI角色的消息st.session_state["messages"].append(msg) # 将AI角色的消息添加到会话状态中st.chat_message("ai").write(response["answer"]) # 显示AI角色的消息st.session_state["chat_history"] = response["chat_history"] # 将对话历史存储到会话状态中st.rerun()refresh_button = st.button("重置对话")
if refresh_button: # 如果点击了重置对话按钮if not deepseek_api_key: # 如果没有输入API密钥st.info("请输入你的DeepSeek API Key")st.stop()st.session_state["messages"] = [{"role": "ai","content": "**铁子,我是本地文档对话客服,可以根据你上传的文档进行对话,有什么可帮你的吗?**"}] # 重置消息st.session_state["chat_history"] = [] # 清空对话历史st.session_state["memory"] = ConversationBufferMemory( # 重置记忆return_messages=True,memory_key="chat_history",output_key="answer")st.rerun() # 重新运行应用程序
2.5 本地运行
0.进入虚拟环境
1.终端运行

2.第一次运行之后,会叫你输入邮箱,输入即可
3.运行成功

2.6 streamlit云部署 (可选)
注意:进行云部署时,由于GPT4AllEmbeddings嵌入模型需要GLIBC 2.32,而streamlit官方部署为GLIBC 2.31,因此部署上传的代码为HuggingFaceBgeEmbeddings嵌入模型,其余代码未变动。
具体可见:上传的代码,有需要的可以下载(但注意本地大概率运行不起,因为HuggingFace网页对中国用户访问很慢,甚至拒绝访问。所以想要本地运行建议用我上面的代码,而想要云部署则用这个上传的代码)
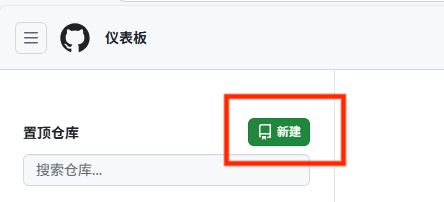
1.注册并登入github网页
2.新建仓库

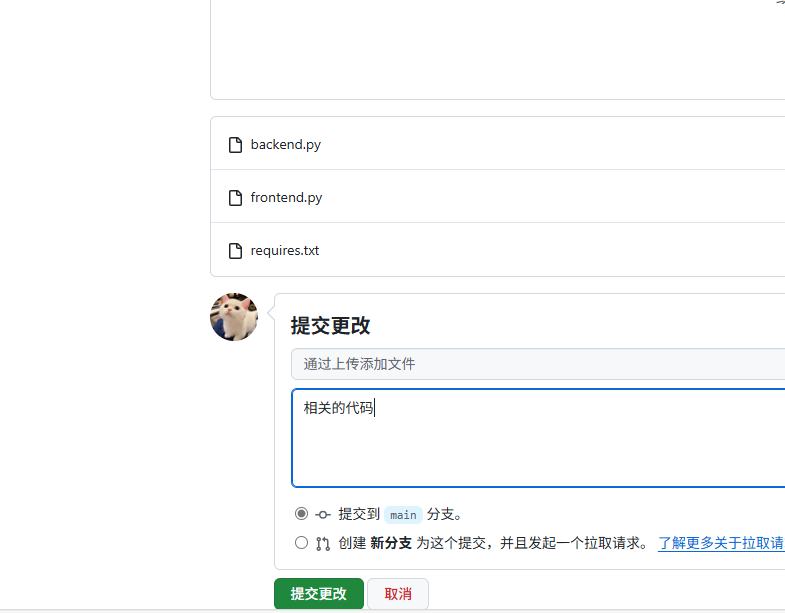
3.上传文件
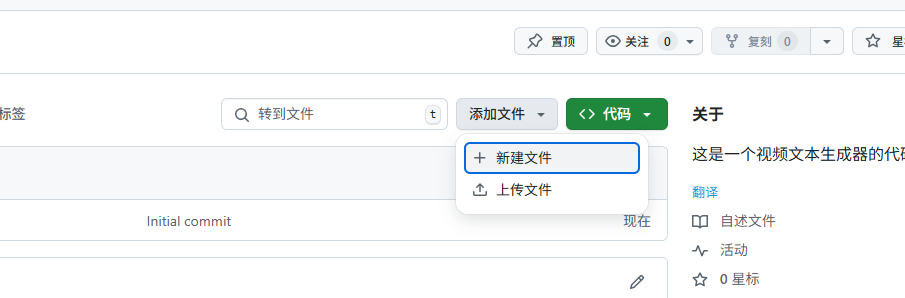
4.提交文件
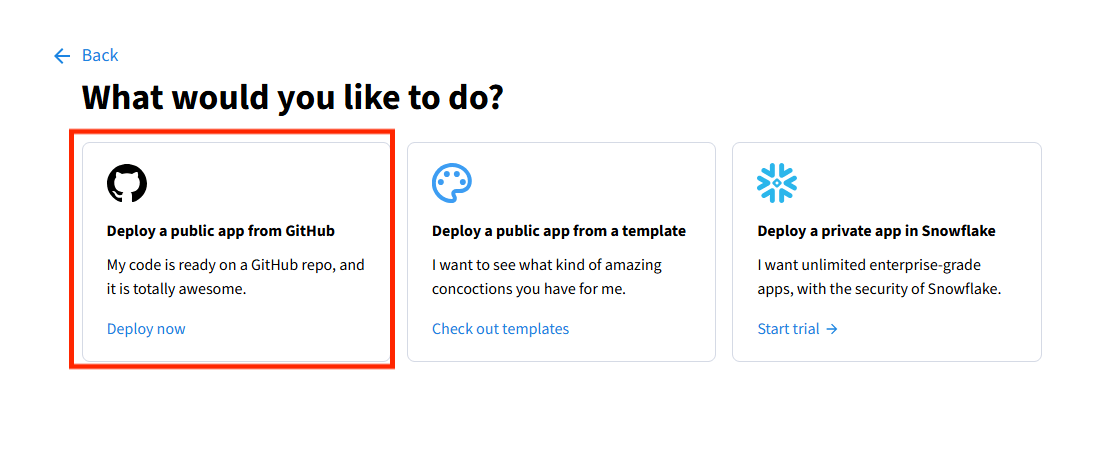
5.登入streamlit云
6.选择
7.然后选择
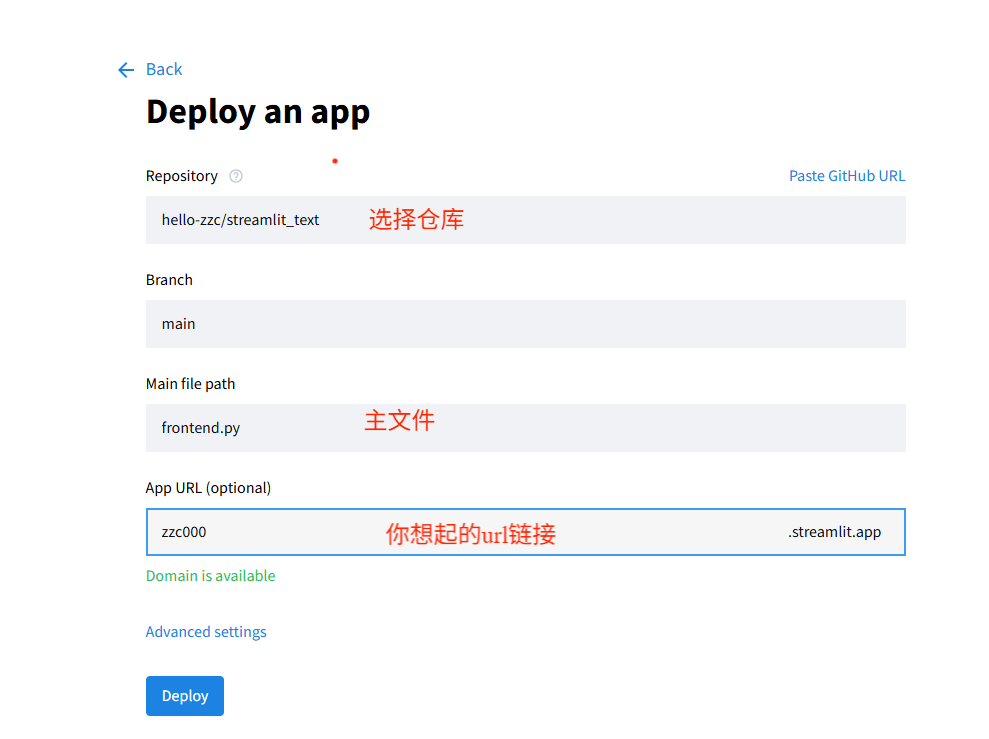
8.部署成功
文档对话助手
9.若部署失败,需要删除失败的操作(可选)
三、😉想说的话
3.1 代码现状
个人感兴趣,玩一下,不足之处多多包涵。
主要问题有:
- 可以实现语音转文字功能
- 可以实现多文档功能
- 变量名起的不够精炼
3.2 改进方案
如何解决:
- 多学习,多练习,熟练度上去后,尝试表达想法。
- 勤注释,换位思考
- 多背单词
3.3 开发困难记录
练习过程中遇到的困难:
- 当对话形式展开时,PDF没有正确的固定在最上面,而是随着对话轮数不断的重复展示,而且有一版的代码中点击了上传PDF之后,PDF按钮不存在了
- 当一轮对话完成的时候,历史消息没有正确的展示而是当第二轮对话完成时,历史消息才展示第一轮
- 对话检索链的参数键进行了更改,运行时报错
- 最开始使用的HuggingFaceBgeEmbeddings嵌入模型,但由于是国外的网站,已经对中国区用户进行了封禁访问,大部分的嵌入模型都需要API,为了简化代码,选择了开源GPT4AllEmbeddings嵌入模型,在自己本地也成功运行,但云部署失败,因为Streamlit的官方后端使用的是GLIBC 2.31,而这个GPT4AllEmbeddings嵌入模型需要GLIBC 2.32
3.4 解决方案
如何解决的困难:
- 摒弃PDF的分支逻辑改成局部变量,且将PDF上传的代码放在循环遍历消息之前,这样Streamlit多次运行始终PDF都会正确的固定在最上面,符合主观逻辑。
- 加入强制重新刷新rerun第一轮消息完成,历史消息正确展示
- 查看了langchain官方文档,明白了参数键的意义
- 采取折中思维,本地的代码就使用GPT4AllEmbeddings嵌入模型,云端的代码就使用HuggingFaceBgeEmbeddings嵌入模型
3.5代码汇总
个人主页csdn资源
3.6 想说的话
若你能看到看到这篇文章且能看到这,则说明你我有缘,留个关注吧,后面还会接着计算机408、底层原理、开源项目、以及数据、后端研发相关、实习、笔试/面试、秋招/春招、各种竞赛相关、简历相关、考研、学术相关……,祝你我变得更强
好的,到此为止啦,祝您变得更强

| 道阻且长 行则将至 |
|---|
个人主页:在线OJ的阿川大佬的支持和鼓励,将是我成长路上最大的动力  |