弹性Reasoning!通过RL训练控制推理预算,提升模型的推理能力和效率!
摘要:大型推理模型(LRMs)通过生成扩展的思维链(CoT)在复杂任务上取得了显著进展。然而,它们不受控制的输出长度对于实际部署构成了重大挑战,在实际部署中,对令牌、延迟或计算的推理时间预算有严格的限制。我们提出了弹性推理,这是一种可扩展的思维链的新框架,它明确地将推理分为两个阶段——思考和解决,并分配独立的预算。在测试时,弹性推理优先考虑解决方案部分的完整性,在资源紧张的情况下显著提高了可靠性。为了训练对截断思考具有鲁棒性的模型,我们引入了一种轻量级的预算受限的滚动策略,集成到GRPO中,该策略教导模型在思考过程被截断时适应性地推理,并在没有额外训练的情况下有效地泛化到未见过的预算限制。在数学(AIME,MATH500)和编程(LiveCodeBench,Codeforces)基准上的实证结果表明,弹性推理在严格的预算限制下表现出色,同时比基线方法承担显著更低的训练成本。值得注意的是,我们的方法即使在不受限制的环境中也能产生更简洁高效的推理。
本文目录
一、背景动机
二、核心贡献
三、实现方法
3.1 推理模型架构
3.2 分离预算(Separate Budgeting)
3.3 预算约束的 rollout 策略
四、实验结果
4.1 数学推理任务
4.2 代码推理任务
五、局限性
六、总结
一、背景动机
论文题目:Scalable Chain of Thoughts via Elastic Reasoning
论文地址:https://arxiv.org/pdf/2505.05315
大模型推理通过思维链在复杂任务上取得了显著进展。然而,这些模型在推理时生成的输出长度往往不受控制,这在实际部署中带来了显著挑战,因为推理时间、计算量或内存等资源通常是严格受限的。
为了应对这一挑战,目前主流的方法如下:
- Long2Short:通过强化学习或压缩感知微调来减少推理长度,但这种方法通常会显著降低性能。
- 长度控制:通过引入特殊标记(如“Wait”或“Final Answer”)来控制推理长度,但这种方法也会导致性能下降。
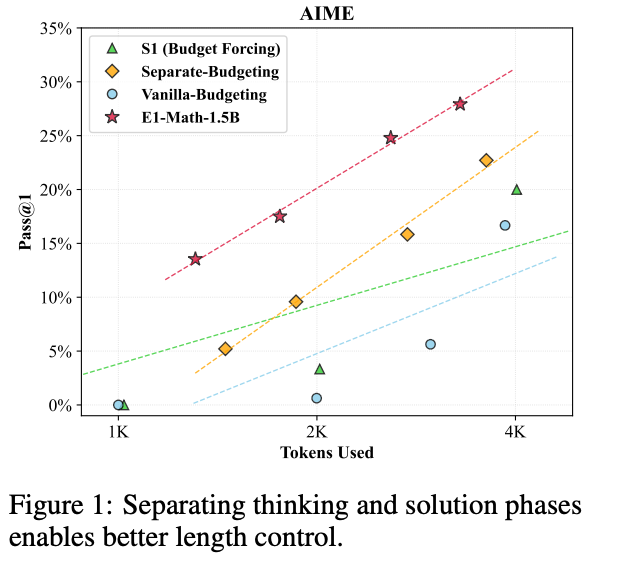
这些方法虽然在一定程度上解决了问题,但仍然存在训练成本高、性能下降等问题。因此,该文章提出了一种新的方法——Elastic Reasoning,旨在通过分离推理过程为“思考”和“解决方案”两个阶段,并为每个阶段分配独立的预算,从而实现更灵活和高效的推理。
二、核心贡献
1、提出 Elastic Reasoning 框架,其通过将推理过程分为“思考”和“解决方案”两个阶段,并为每个阶段分配独立的预算,显著提高了在严格资源约束下的推理性能。
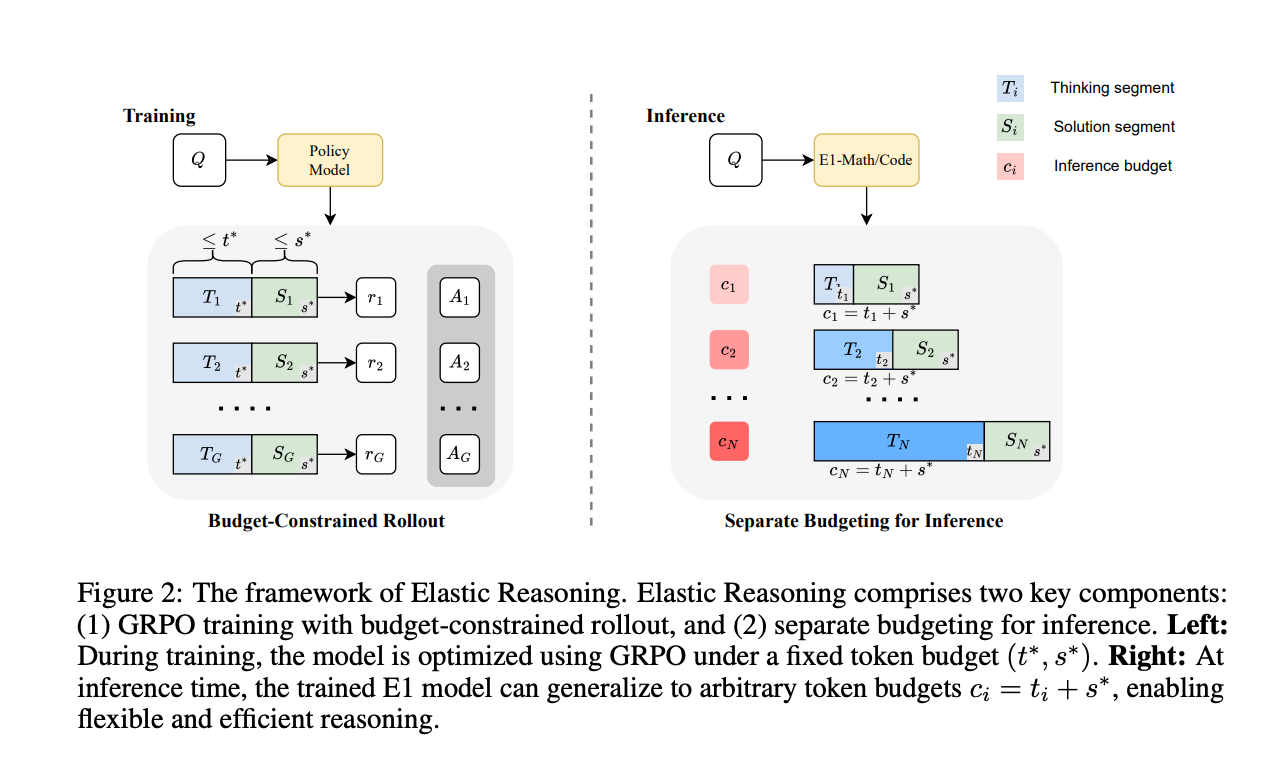
2、提出预算分离的推理策略,将总预算 ( c ) 分为两部分:思考预算 ( t ) 和解决方案预算 ( s ),其中 ( c = t + s )。在推理过程中,模型在思考阶段使用 ( t ) 个标记,然后强制终止并进入解决方案阶段,使用 ( s ) 个标记生成解决方案。
三、实现方法
3.1 推理模型架构
推理模型生成的输出包括两个部分
- 思考部分(Thinking Segment):包含中间推理步骤,用特殊标记
<think>和</think>包裹。 - 解决方案部分(Solution Segment):包含最终解决方案。
3.2 分离预算(Separate Budgeting)
- 在推理时,模型首先在
<think>块中生成思考部分,直到达到预算 ( t )。 - 如果模型在达到预算 ( t ) 之前发出
</think>,则立即进入解决方案阶段。 - 如果预算 ( t ) 用完仍未发出
</think>,则强制终止推理并附加</think>,然后生成解决方案部分,最多使用 ( s ) 个标记。
3.3 预算约束的 rollout 策略
- 使用 GRPO 算法进行强化学习训练,模拟推理时的分离预算过程。
- 在训练过程中,模型在预算 ( t^* ) 内生成思考部分,如果发出
</think>则继续生成解决方案部分,否则强制附加</think>并生成解决方案部分。 - 优化目标是最大化期望奖励:
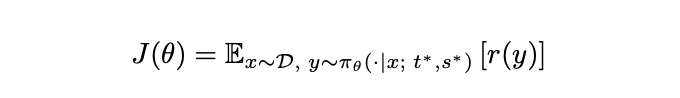
- 使用 GRPO 的梯度估计器进行优化。
四、实验结果
4.1 数学推理任务
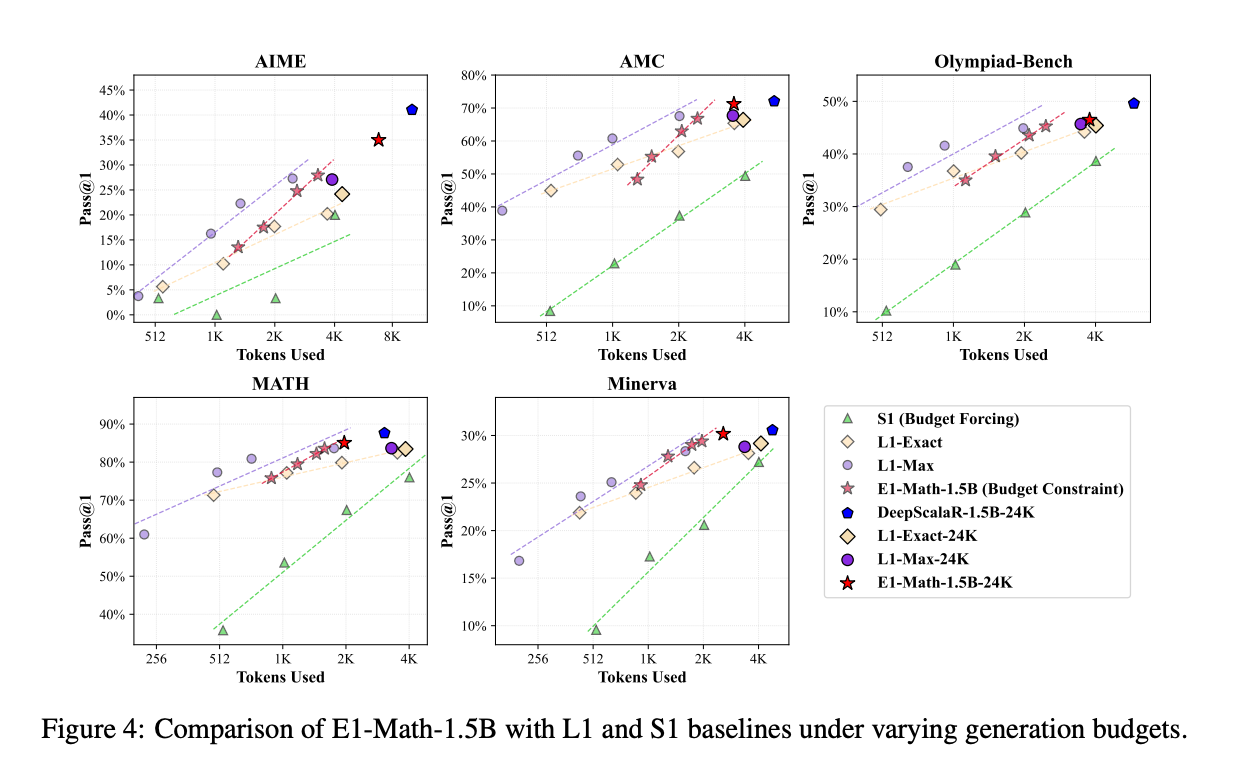
- E1-Math-1.5B 在 AIME2024 数据集上实现了 35.0% 的准确率,相比 L1-Max 的 27.1% 和 L1-Exact 的 24.2% 有显著提升,同时训练步骤更少。
- 在 MATH500 数据集上,E1-Math-1.5B 实现了 83.6% 的准确率,使用 1619 个标记,而 L1-Exact 和 L1-Max 分别使用 1959 和 1796 个标记,准确率分别为 79.9% 和 83.6%。
- 在无约束设置中,E1-Math-1.5B 的性能优于所有基线方法,平均标记使用量减少了 30% 以上。
4.2 代码推理任务
- E1-Code-14B 在 LiveCodeBench 数据集上表现出色,随着推理预算的增加,性能稳步提升。
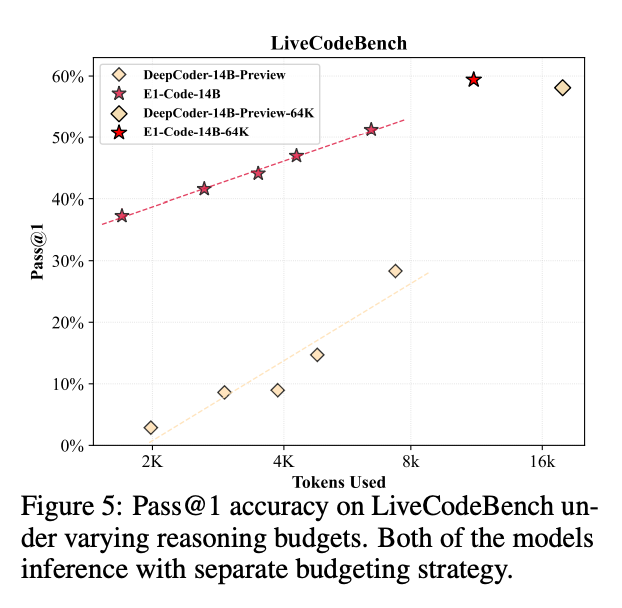
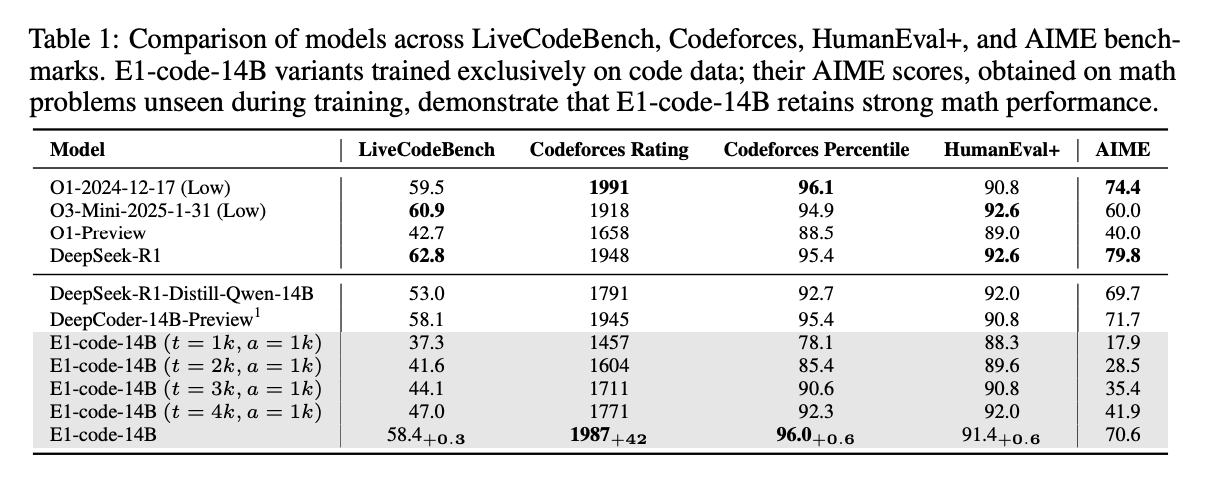
- 在 Codeforces 上,E1-Code-14B 实现了 1987 的评分,排名在 96.0 百分位,与 O1-2024-12-17 (Low) 的 1991 评分和 96.1 百分位相当。
- 在无约束设置中,E1-Code-14B 的性能提升了 0.3%,同时标记使用量减少了 37.4%。
五、局限性
1、训练预算特定性:文章发现,使用不同的思考预算 ( t* ) 对模型性能有显著影响。虽然 ( t* = 1K ) 在实验中表现最佳,但这一选择可能需要根据具体任务进行调整。
2、拓展性有限:文章尝试了迭代训练,即在初始训练后使用更大的预算进行进一步训练,但发现这并没有提升性能,反而略有下降。这表明一旦模型学会了在较短预算下有效推理,进一步增加预算可能不会带来额外的好处。
六、总结
Elastic Reasoning 提供了一种在严格推理时间约束下实现可扩展推理链的有效方法。通过分离推理过程为“思考”和“解决方案”两个阶段,并为每个阶段分配独立的预算,该方法不仅提高了在资源受限环境下的推理性能,还减少了推理时的标记使用量,同时保持了较高的推理质量。此外,Elastic Reasoning 在无约束设置中也表现出色,生成的推理链更加简洁高效。