【RAG】11种Chunking Strategies分块策略介绍和选择
【今日鸡汤】学习之路上,勤奋是比 “聪明” 远远更珍贵的品质。
参考原文地址:https://masteringllm.medium.com/11-chunking-strategies-for-rag-simplified-visualized-df0dbec8e373
在构建强大的检索增强生成(RAG)系统时,一个至关重要的环节就是分块(Chunking)。它直接影响着系统检索的效率和生成内容的质量。
简单来说,分块就是将大型文档分割成更小、更易于管理的部分,方便后续的索引和检索。
本文将带你深入了解11种常用的RAG分块策略,并通过可视化图解,让你轻松掌握各种方法的优缺点以及适用场景。
为什么分块策略很重要?
好的分块策略能带来诸多好处:
-
效率提升: 更小的块降低了检索时的计算开销。
-
相关性提高: 精确的块能增加检索到相关信息的几率。
-
上下文保留: 合理的分段能保持信息的完整性,确保生成连贯的回复。
但如果分块策略不当,也可能导致:
-
上下文丢失: 在不合理的位置分割信息会破坏其含义。
-
信息冗余: 重叠的分段可能会引入重复信息。
-
一致性问题: 可变长度的块会增加检索和索引的复杂性。
11种分块策略介绍
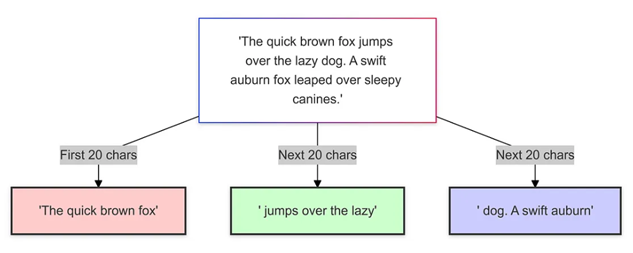
1. 固定长度分块(Fixed-Length Chunking)
-
原理: 将文本按照预定义的长度(例如,字符数或Token数量)分割成块。
-
优点: 简单易实现,chunk大小均匀,易于索引。
-
缺点: 可能破坏句子或段落的完整性,导致上下文丢失。
-
适用场景: 简单文档、FAQ,或对处理速度要求高的场景。
-
实现建议: 选择合适的chunk大小,可以结合滑动窗口机制缓解上下文丢失问题。
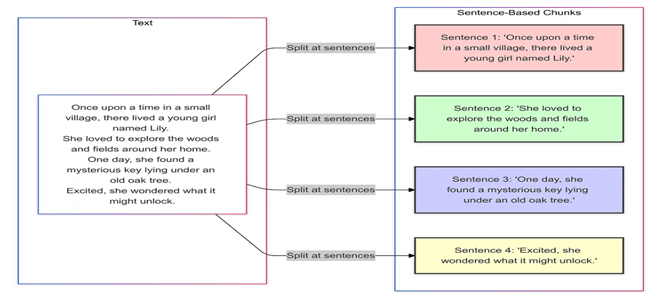
2. 基于句子的分块(Sentence-Based Chunking)
-
原理: 以句子为单位分割文本。
-
优点: 保持句子完整性,易于实现(借助NLP工具)。
-
缺点: 单个句子可能上下文信息不足,句子长度差异可能导致chunk大小不一致。
-
适用场景: 简短、直接的回复,例如客户查询或对话式AI。
-
实现建议: 使用NLP库进行句子边界检测,可以将短句子合并以创建更大的块。
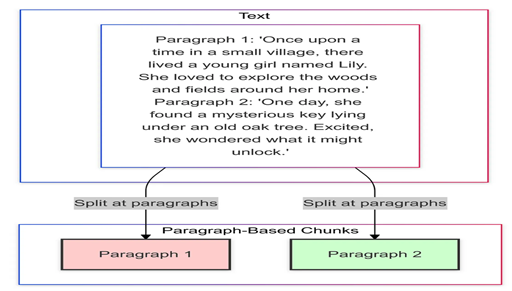
3. 基于段落的分块(Paragraph-Based Chunking)
-
原理: 以段落为单位分割文本。
-
优点: 包含比句子更丰富的上下文,符合文本的自然结构。
-
缺点: 段落长度差异较大,长段落可能超出模型Token限制。
-
适用场景: 结构化文档,例如文章、报告或论文。
-
实现建议: 监控chunk大小,避免超出Token限制,必要时进一步拆分长段落。
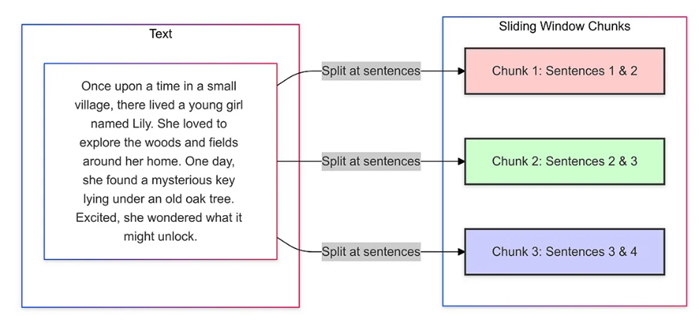
4. 滑动窗口分块(Sliding Window Chunking)
-
原理: 使用滑动窗口在文本上创建重叠的块,相邻块共享部分内容。
-
优点: 保持上下文连续性,提高检索的准确性。
-
缺点: 存在冗余信息,计算和存储成本较高。
-
适用场景: 需要跨章节保持上下文的文档,例如法律或医学文本。
-
实现建议: 根据文档特性优化窗口大小和重叠比例,使用去重技术处理冗余信息。
5. 语义分块(Semantic Chunking)
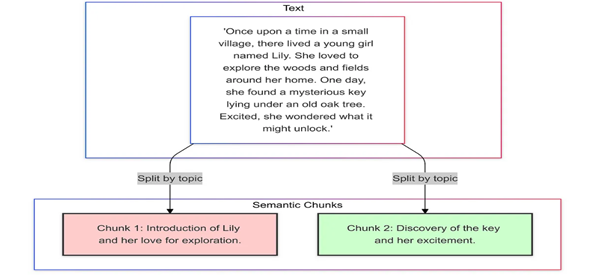
-
原理: 利用嵌入或机器学习模型,根据语义意义分割文本,确保每个chunk在主题或想法上具有连贯性。
-
优点: 上下文相关性好,灵活性高。
-
缺点: 需要高级NLP模型和计算资源,处理时间较长。
-
适用场景: 需要深度理解的复杂查询,例如技术手册或学术论文。
-
实现建议: 使用预训练模型进行语义分割,平衡计算成本和chunk粒度。
6. 递归分块(Recursive Chunking)
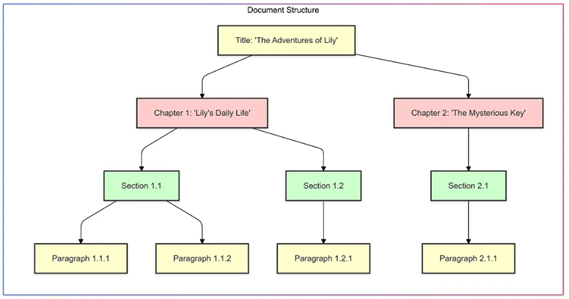
-
原理: 使用层级分隔符(如标题、副标题、段落、句子)逐步将文本分解成更小的块。
-
优点: 维护文档的结构关系,适用于大型文本。
-
缺点: 实现复杂,最小的块可能仍然会丢失上下文。
-
适用场景: 大型、层级结构的文档,例如书籍或大型报告。
-
实现建议: 使用文档结构(如HTML标签)识别层次结构,存储每个块在层次结构中的位置信息。
7. 上下文增强分块(Context-Enriched Chunking)
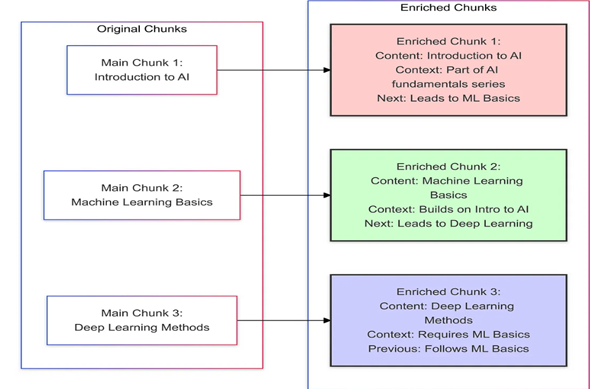
-
原理: 通过添加来自周围块的摘要或元数据来丰富每个块,保持序列中的上下文。
-
优点: 增强上下文信息,提高生成内容的连贯性。
-
缺点: 需要额外处理生成摘要或元数据,存储开销增加。
-
适用场景: 需要跨多个块保持一致性的长文档。
-
实现建议: 生成简洁的摘要,可以将关键术语或概念作为元数据添加。
8. 模态特定分块(Modality-Specific Chunking)
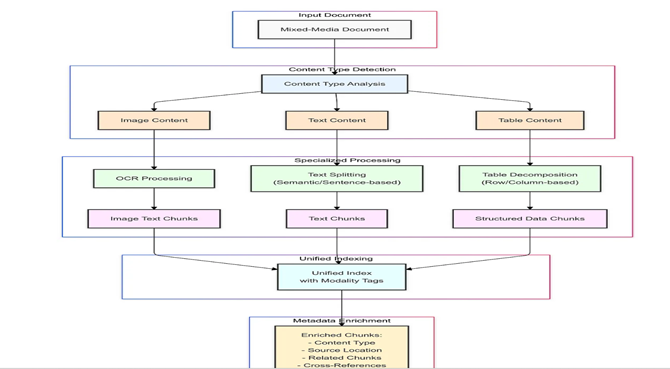
-
原理: 分别处理不同类型的内容(文本、表格、图像),并根据其性质进行分块。
-
优点: 针对不同内容类型进行优化,提高检索准确性。
-
缺点: 实现复杂,需要对每种模态进行自定义逻辑,整合来自不同模态的信息具有挑战性。
-
适用场景: 混合媒体文档,例如科学论文或用户手册。
-
实现建议: 对包含文本的图像使用OCR,将表格转换为结构化数据格式,在不同模态之间保持一致的索引系统。
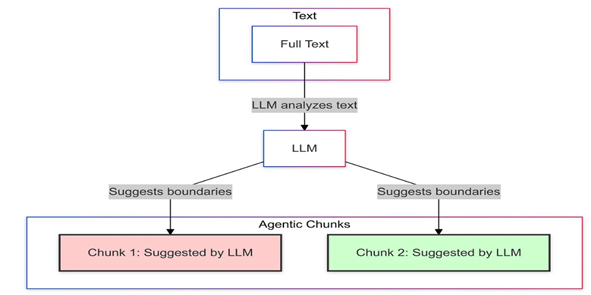
9. 智能分块(Agentic Chunking)
-
原理: 利用大型语言模型(LLM)分析文本,并根据内容结构和语义建议分块边界。
-
优点: 智能分段,能够有效处理多样化和非结构化内容。
-
缺点: 计算密集型,成本较高。
-
适用场景: 在需要保留意义和上下文的情况下处理复杂文档。
-
实现建议: 对关键文档选择性地使用,优化LLM提示词以高效地识别逻辑分块边界。
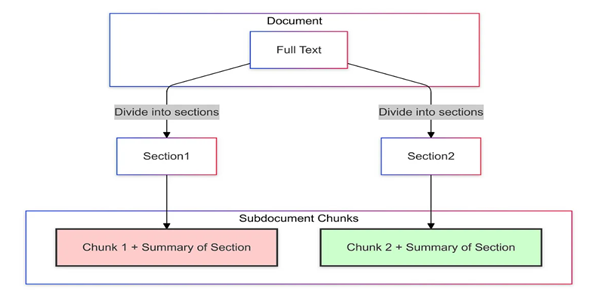
10. 子文档分块(Subdocument Chunking)
-
原理: 总结整个文档或大章节,并将这些总结作为元数据附加到各个分块上。
-
优点: 允许检索系统在多个上下文级别上操作,提供额外的信息层。
-
缺点: 需要生成和管理摘要,增加了索引系统的复杂性。
-
适用场景: 提高大规模文档集合中的检索效率。
-
实现建议: 使用NLP技术自动进行摘要处理,高效存储摘要以最小化存储影响。
11. 混合分块(Hybrid Chunking)
-
原理: 结合多种分块策略,以适应不同查询类型或文档结构。
-
优点: 灵活性高,能够在不同应用场景中平衡速度和准确性。
-
缺点: 需要复杂的决策算法,维护成本较高。
-
适用场景: 适用于处理多种查询和文档类型的通用系统。
-
实现建议: 制定选择分块策略的标准,进行广泛的测试和验证以确保可靠性。
不同分块策略的特点
| 策略 | 上下文保留能力 | 实现复杂度 | 计算成本 | 最佳应用场景 |
| Fixed-Length Chunking 固定长度分块 | 低 | 低 | 低 | 简单文档,对速度要求高的应用 |
| Sentence-Based Chunking 基于句子的分块 | 中等 | 低 | 低 | 短查询,对话式AI |
| Paragraph-Based Chunking 基于段落的分块 | 中等到高 | 低 | 中等 | 结构化文档 |
| Sliding Window Chunking 滑动窗口分块 | 高 | 中等 | 高 | 对上下文要求严格的文本 |
| Semantic Chunking 语义分块 | 高 | 高 | 高 | 技术或学术文档 |
| Recursive Chunking 递归分块 | 高 | 中等 | 中等 | 大型,分层结构的文档 |
| Context-Enriched Chunking 上下文增强分块 | 非常高 | 高 | 高 | 需要连贯性的长文档 |
| Modality-Specific Chunking 模态特定分块 | 可变 | 高 | 可变 | 混合模态(例如,文本+图片)文档 |
| Agentic Chunking 代理式分块 | 非常高 | 非常高 | 非常高 | 需要深度理解的复杂文档 |
| Subdocument Chunking 子文档分块 | 高 | 高 | 高 | 大型文档集合 |
| Hybrid Chunking 混合分块 | 可变 | 非常高 | 可变 | 通用系统 |
如何选择合适的分块策略?
选择合适的分块策略需要考虑以下因素:
-
文档类型: 结构化程度、长度、模态。
-
查询复杂度: 简单FAQ还是复杂的技术查询。
-
资源可用性: 计算能力和时间限制。
-
预期结果: 速度、准确率、上下文保留。
以下是一些指导原则:
-
追求速度: 使用固定长度或基于句子的分块。
-
追求上下文: 选择滑动窗口、语义或上下文增强分块。
-
处理混合内容: 采用特定模态或混合分块。
-
大规模系统: 在效率和上下文之间取得平衡,使用递归或子文档分块。
总结:理解各种策略的优缺点和适用场景,可以帮助你根据具体需求定制RAG系统,从而有效地增强语言模型的能力。
记住,没有万能的策略,需要不断尝试和优化,才能找到最适合你的RAG的方案。:))