Datawhale AI春训营学习
一、数据竞赛的概念:
数据竞赛的题目通常来源于实际的业务问题或社会问题,具有重要的现实意义。通过竞赛的方式,可以让全球数据科学研究者共同解决这些问题。这些数据可以来生活的各个方面,比如:在医疗方面,参赛者可以通过分析医疗数据,开发出疾病诊断辅助系统、医疗资源管理系统等,提高医疗服务的质量和效率等。
二、赛题回顾(合成生物赛道):
上海科学智能研究院携手复旦大学在上智院平台发布“第三届世界科学智能大赛”。大赛设置航空安全、材料设计、合成生物、创新药、新能源五大赛道,本次我在Datawhale训练营里参加了合成生物赛道。这个赛道的题目核心是IDRs(无序蛋白)预测问题,需要参赛者基于给定的蛋白质序列信息,准确预测蛋白质的内在无序区域。参赛者需要基于给定的蛋白质序列信息,准确预测蛋白质中的内在无序区域。参赛者将获得一系列蛋白质的氨基酸序列。每个序列由一串氨基酸组成,每个氨基酸用单字母表示(如 A、C、D 等)。
• 序列标注:参赛者需要对每个氨基酸位置进行标注,判断该位置是否属于无序区域。
• 标注方式:使用二进制标签(0 或 1)表示每个氨基酸是否属于无序区域。
通过我们对赛题的分析,发现其是一个典型的序列标注的任务。你可以将赛题视为一个典型的自然语言处理任务,因为输入的数据为文本序列。接下来我们需要考虑到输入蛋白质序列长度与标注结果长度相同,想到相关序列标注模型。然后有如下参考实体识别路线:词向量模型、LSTM模型、BERT模型、GPT模型。
三、自然语言处理基础
自然语言是计算机科学和语言学交叉的学科,致力于让计算机能够和人类一样理解和生成自然语言。它和编程语言如python......有本质的区别。自然语言具有高度的复杂性、模糊性和多样性,这使得自然语言处理成为一项极具挑战性的任务。
四、NLP常见任务
文本分类是自然语言处理(NLP)中的基础任务之一。序列标注是为文本中每个单元(通常是词或字符)分配一个标签任务,考虑序列中元素之间的依赖关系。
• 文本分类的输入输出 :为整个文本分配一个或多个类别标签。
• 序列标注的输入输出 :输出是一个与输入等长的标签序列。
五、词向量
词向量是自然语言处理中的一种重要的技术,用于将词汇映射到低维的连续空间里,使语法和语义相似的词在向量空间中距离相近。
传统方法的缺点:1、词汇表有多大,向量就有多大;2、无法表达词语词之间的语义关系(比如"猫"和"鱼"都是动物,传统方法无法体现)。
词向量的优势:1、低维,向量密集;2、语意相近的词在向量空间的距离相近;3、可以计算词之间的相似度。
六、BERT模型
BERT的核心特点是其双相性,即是它可以同时考虑上下文的左右信息,从而可以生成更精准的语言表示。这个双向性使得BERT在理解词语的多义性和上下文关系方面表现出色。该模型基于 Transformer 架构,完全依赖自注意力机制来处理序列数据。 BERT模型训练的与训练过程包括两个主要任务:
1、掩码语言模型:
在训练过程中,BERT 会随机掩盖输入序列中的一些词(通常用特殊标记[MASK] 替换),然后预测这些被掩盖的词。这种方式迫使模型理解句子的双向上下文。[其实这个过程类似与高考英语考试里的完形填空],例如,在句子"今天天气很好,我决定出去跑步",如果通过一些办法把"决定"掩盖掉,那么模型需要同时考虑"今天天气很好"和"出去跑步"来预测"决定"。
2、下一句预测:
BERT训练了一个二分类任务,即判断给定两个句子是否连续。例如,给出句子A和B,模型需要判断B是否紧接在A之后出现,这个任务有利于模型理解连个句子之间的逻辑关系。
BERT模型的应用:文本分类:如情感分析、垃圾邮件检测、主题分类等;命名实体识别(NER):识别文本中的人名、组织名、地点等实体、问答系统:理解问题的上下文并提供相关答案、机器翻译:捕捉语言的细微差别,提高翻译的准确性、文本摘要:生成简洁而有意义的文本摘要、语义相似性:测量句子或文档之间的语义相似性,用于重复检测、释义识别等任务。
七、GPT大模型
GPT是由 OpenAI 开发的一系列自然语言处理模型,基于 Transformer 架构的解码器部分,通过大规模语料库的预训练,学习语言的统计规律,并能够生成连贯、自然的文本。GPT采取回归的方式生成文本,即在给定前面的文本基础上逐步预测并生成下一个词。其核心架构Transformer 的解码器部分,利用多头自注意力机制捕捉句子中单词之间的关系,并通过前馈神经网络进行非线性变换。与传统的循环神经网络(RNN)不同,Transformer 能够在一个时间步中并行计算整个输入序列,大大加快了训练和推理速度。
GPT 使用单向 Transformer 解码器,通过自回归语言模型训练,预测句子中的下一个词。这种单向训练方式使得 GPT 在生成连贯文本时表现强大,但对上下文的理解相对较弱。
GPT和BERT模型比较:BERT模型设计是为了加强对文本的理解能力,而不是生成文本,可以通过上下文理解句子或者是词语的意思;GPT模型设计是为了加强生成文本的能力,适用于创意写作、生成文章等。
八、机器学习与深度学习
机器学习的核心目标是让计算机能够通过数据驱动的方法,自动发现数据中的模式和规律,并据此做出预测或决策,而无需进行明确的编程。机器学习可以分为以下几种主要类型:1、监督学习,用标记好的训练数据来训练模型。2、无监督学习:使用未标记的数据来训练模型,目标时发现数据中的内在结构和模式。
深度学习能够自动学习数据中的复杂特征和模式。深度学习模型通常包含多个隐藏层,这些隐藏层能够逐层提取数据的高级特征,从而实现更强大的表示能力。常见的神经网络:前馈神经网络、卷积神经网络、循环神经网络、Transformer 架构。
九、模型训练和评价
端到端学习是一种学习范式,它直接从原始数据输入到最终输出结果进行学习,中间不需要人工设计特征或者是进行复杂的预处理。目标是通过一个统一的模型,直接输入到输出进行映射。
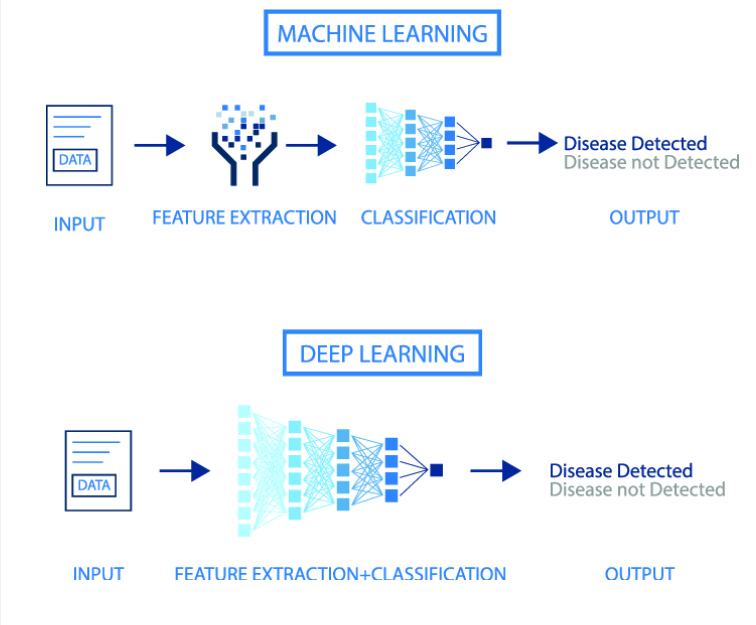
• 机器学习:通常需要人工设计特征,将数据转换为适合模型的格式。例如,在图像识别任务中,可能需要人工提取图像的边缘、纹理等特征。
• 深度学习:通过多层神经网络自动学习特征,不需要人工设计特征。深度学习模型能够自动从原始数据中提取高级特征。
十、解决赛题的方案
方法:词向量+机器学习
step1、训练词向量
• 使用gensim库里Word2Vec模型对氨基酸序列进行词向量训练。
• 将每个蛋白序列转化为有空格分隔的字符串(" ".join(x["sequence"]))。
• vector_size=100:词向量的维度为100。
• min_count=1:单词字少出现一次。
step2.编码词向量
•对于序列中的每个氨基酸,提取其上下文窗口内的词向量,并计算平均值作为特征。
◦ sequence[max(0, idx-2): min(len(sequence), idx+2)]:获取当前氨基酸及其前后两个氨基酸的窗口。
◦ model_w2v.wv[...]:获取窗口内氨基酸的词向量。
◦ .mean(0) :对窗口内的词向量取平均值,得到一个固定维度的特征向量。
• 将特征向量添加到data_x,将对应的标签添加到data_y。
data_x = []
data_y = []
for data in datas:sequence = list(data["sequence"])for idx, (_, y) in enumerate(zip(sequence, data['label'])):data_x.append(model_w2v.wv[sequence[max(0, idx-2): min(len(sequence), idx+2)]].mean(0))data_y.append(y)step3、训练贝叶斯模型
使用GaussianNB (高斯朴素贝叶斯)分类器对提取的特征进行训练。 • model.fit(data_x, data_y) :将特征和标签传入模型进行训练。