C++初阶-string类4
目录
1.String operations
1.1string::c_str
1.2string::data
1.3string::copy
1.4string::find
1.5string::rfind
1.6string::find_first_of
1.7string::find_last_of
1.8string::find_first_not_of和string::find_last_not_of
find_first_not_of
功能
典型用途
find_last_not_of
功能
典型用途
1.9string::substr
1.10string::compare
2.成员变量
string::npos
3.非成员函数重载
3.1std::operator+(string)
3.2relational operators(string)
3.3std::swap(string)
3.4std::operator<<(string)和std::operator>>(string)
3.5std::getline(string)
4.*string的扩容Vs和g++版本(扩展知识)
5.总结

1.String operations
在string operations分类中包含以下函数:

除了get_allocator函数外基本上都讲。
1.1string::c_str
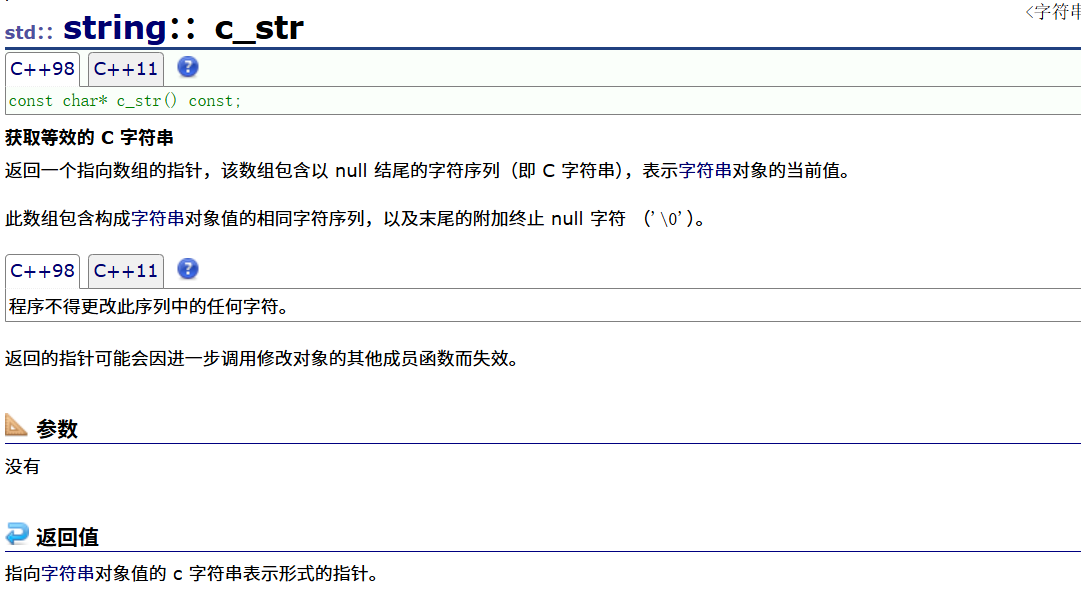
这个函数的功能是返回底层的字符串,若存在buff则返回buff(这个会放到扩容的章节去讲),否则返回str,返回C形式的字符串,因为C语言的字符串结尾有\0,因为C/C++是混着使用的,这个函数我们可以用来打开一个文件函数,因为若是string类的形式,则文件函数第一个参数是C形式的字符串,即const char*类型,而没有string类型,用法如下:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
#include<string>
//string::c_str
int main()
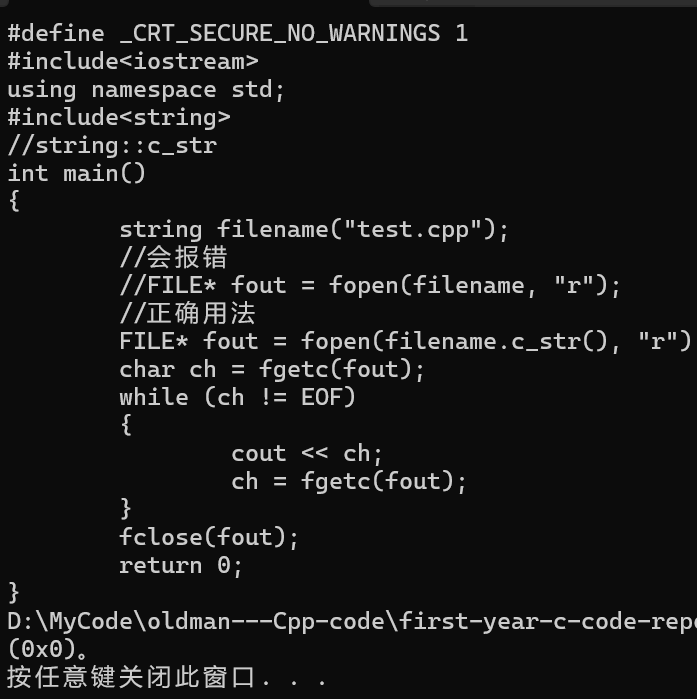
{string filename("test.cpp");//会报错//FILE* fout = fopen(filename, "r");//正确用法FILE* fout = fopen(filename.c_str(), "r");char ch = fgetc(fout);while (ch != EOF){cout << ch;ch = fgetc(fout);}fclose(fout);return 0;
}则运行结果如下:
1.2string::data
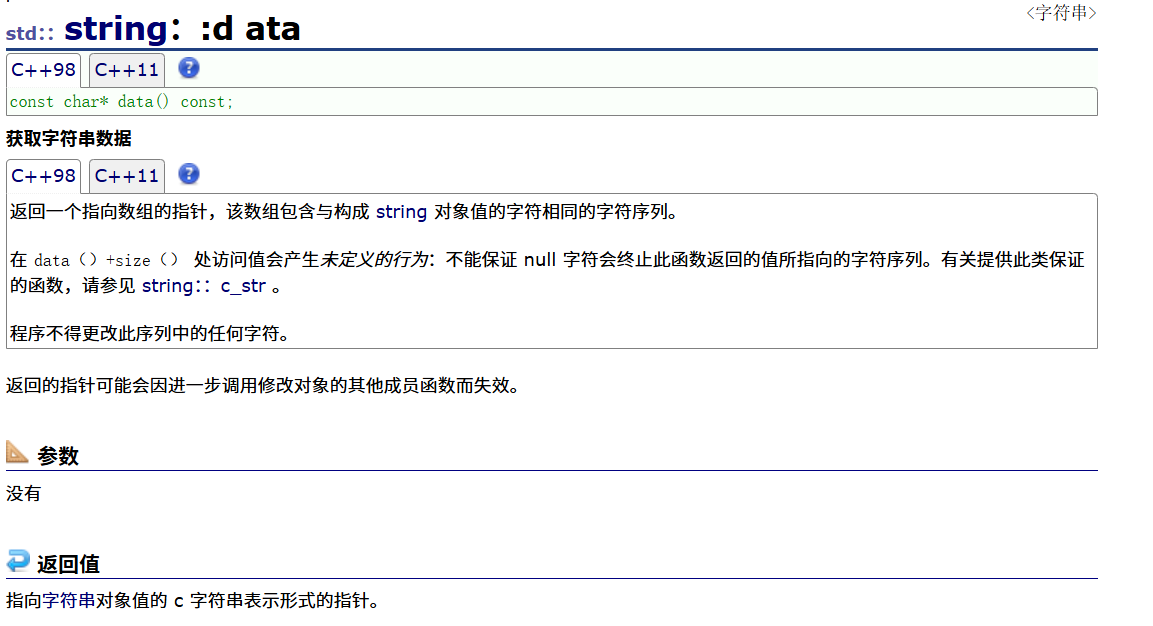
这个函数的作用是:返回一个字符数组,如:
#include<iostream>
using namespace std;
#include<string>
//string::data
int main()
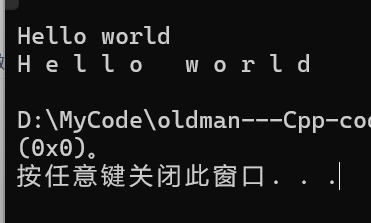
{string s2("Hello world");const char* a = s2.data();cout << s2 << endl;auto i = 0;while(a[i]!='\0'){cout << a[i++] << " ";}cout << endl;return 0;
}运行结果如下:
1.3string::copy

把字符串对象当前值的子字符串复制到s指向的数组中,此子字符串包含从pos位置开始的len个字符。
#include<iostream>
using namespace std;
#include<string>
//string::copy
int main()
{string s1("hello world");char s[10] = "abcdefg";s1.copy(s, 5);cout << s << endl;return 0;
}运行结果如下:
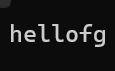
这个函数一般情况下用得不多,所以就不做过多讲解了。
1.4string::find

顾名思义,这个函数的功能就是找一个字符串/字符/string对象,然后返回第一个找到元素的下标。第一个函数是string对象从pos位置开始找str的位置;第二个函数是从string对象的pos位置开始找s的位置;第三个是从pos位置开始找s的前n个字符;第四个函数是从pos位置开始找字符c。若都没找到就返回npos(第二部分会讲)。
#include<iostream>
using namespace std;
#include<string>
//string::find
int main()
{string s("abcdefghi");//(1)//找到string s1("cdef");cout << s.find(s1) << endl;//未找到string s2("cef");cout << s.find(s2) << endl;//(2)//找到cout << s.find("efghi") << endl;//未找到cout << s.find("efhi") << endl;//(3)//找到cout << s.find("efghil",0, 4) << endl;//未找到cout << s.find("abchi",0, 4) << endl;//(4)//找到cout << s.find('a') << endl;//未找到cout << s.find("z") << endl;return 0;
}运行结果为:
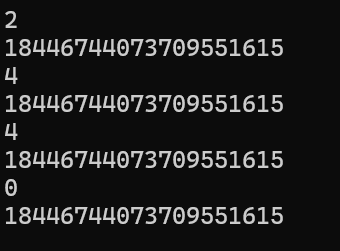
我们发现这个未找到的时候会返回一个很大的值,这个值在64位系统是指的2^64-1即整型的最大值(npos),所以我们一般用npos来判断是否找到该字符(串)或string对象。
1.5string::rfind

这个函数的作用是反着找字符串/字符/string对象,假设我们s="abababab",s1="ab",s2='b'那么find返回的是第一个出现的ab的'a'的下标,而rfind是返回最后一个出现的ab的‘a’的下标。
#include<iostream>
using namespace std;
#include<string>
//string::rfind
int main()
{string s("abababababababababa");//(1)string s1("ab");cout << s.find(s1) << endl;cout << s.rfind(s1) << endl;//(2)cout << s.find("ba",3) << endl;cout << s.rfind("ba",3) << endl;//(3)cout << s.find("ababab", 0) << endl;cout << s.rfind("ababab", 0) << endl;//(4)cout << s.find('a') << endl;cout << s.rfind('b') << endl;return 0;
}运行结果如下:
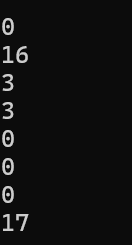
1.6string::find_first_of

功能:


也就是说寻找的是参数str、s或者c中有的字符,也就是假设string对象是abcdefg,若str是efghi,则由于e是在string对象的下标为4的位置出现的,所以就返回的是4;若是fghi这些字符在下标4这个位置前面出现过,那么就返回的是那个下标了,这个函数的功能就这样了,不是很重要,所以就不演示了。
1.7string::find_last_of

用于从字符串末尾向前搜索,查找任意一个指定字符集合中的字符最后一次出现的位置。如果未找到,则返回std::string::npos。对于pos则:指定搜索的起始位置(从该位置向前搜索),默认为npos(即从字符串末尾开始搜索)。
-
返回目标字符集合中任意字符最后一次出现的位置(索引从0开始)。
-
如果未找到,返回
std::string::npos。
常见用途:
-
提取文件名(不含路径)
std::string full_path = "/home/user/file.txt"; size_t slash_pos = full_path.find_last_of('/'); std::string filename = full_path.substr(slash_pos + 1); // 获取"file.txt" -
检查文件扩展名
std::string filename = "image.png"; size_t dot_pos = filename.find_last_of('.'); if (dot_pos != std::string::npos) {std::string ext = filename.substr(dot_pos + 1); // 获取"png" }这个函数用得也不是很多,不过有些题目里面也会涉及到,所以还是有必要了解的!
1.8string::find_first_not_of和string::find_last_not_of
这两个函数则刚好和find_fist_of与find_last_of刚好相反,寻找的是从开始或最后开始找没有在模板字符集合中出现的字符的位置:
find_first_not_of
功能
从字符串的起始位置开始搜索,返回第一个不在指定字符集合中的字符的位置。如果所有字符均匹配集合,则返回npos。
-
pos(可选):开始搜索的起始位置(默认为0)。
典型用途
-
跳过前缀中的特定字符(如空格、数字等)。
-
验证字符串是否包含非法字符。
find_last_not_of
功能
从字符串的末尾开始向前搜索,返回最后一个不在指定字符集合中的字符的位置。如果所有字符均匹配集合,则返回npos。
-
pos(可选):开始搜索的起始位置(默认为npos,即从末尾开始)。
典型用途
-
去除字符串末尾的空白字符。
-
检查文件路径是否以分隔符结尾。
1.9string::substr

这个函数是从pos位置开始取len个字符,两个参数都可以不传递,只是最终把这个string对象的pos位置开始的len个字符拷贝到新的string对象去了,用法如下:
#include<iostream>
#include<string>
using namespace std;
//string::substr
int main()
{string s1("hello world");string s2 = s1.substr();string s3 = s1.substr(1);string s4 = s1.substr(2, 7);int c;cin >> c;string s5 = s1.substr(c, s1.size() - c);cout << s1 << endl;cout << s2 << endl;cout << s3 << endl;cout << s4 << endl;cout << s5 << endl;return 0;
}运行结果如下:
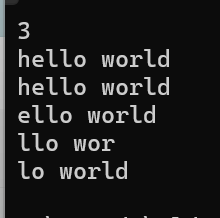
其中我们要注意一点,我们如果想要传第二个参数的话我们是直接用size的大小去减去第一个参数,第一个元素代表的是下标位置,而size返回的是下标到最大小标的后一个位置即\0的位置,所以我们可以通过size函数来计算就是这个原因,因此我们不需要加1来算需要拷贝的个数。
这个函数的功能与string::copy函数类似,也可以视为copy函数是另外一种substr函数,但是copy函数的函数参数顺序不同,也没有全部给缺省值,一般用得也不多。
1.10string::compare
compare这个单词的意思是比较,第一个重载函数是和一个string对象进行比较;第二个重载函数是把该string对象的一部分与str或者str的一部分进行比较;第三个重载函数是把该string对象与s这个字符串或者把该string对象的一部分进行比较(从pos位置开始的len个字符)进行比较;第四个重载函数是把string对象的从pos位置开始的len个字符与s的前n个字符进行比较。如果该string对象比另一个大(从二者的第一个字符开始比较),则返回1;若二者相等,则返回0;若该string对象(或该对象的一部分)比另一个小,则返回-1 。该用法和我们C语言学过的strcmp函数一样。用法如下:
#include<iostream>
#include<string>
using namespace std;
//sting::compare
int main()
{string s1("Hello world");//(1)string s2("World");cout << s1.compare(s2) << endl;//(2.1)string s3("Hello");cout << s1.compare(0, 5, s3) << endl;//(2.2)string s4("WorlD");cout << s1.compare(6, 5, s4) << endl;cout << s1.compare(7, 3, s4, 1,3) << endl;//(3.1)cout << s1.compare("Hello") << endl;//(3.2)cout << s1.compare(0, 5, "Hello") << endl;//(4)cout << s1.compare(0, 10, "Hello CSDN") << endl;cout << s1.compare(0, 10, "Hello CSDN", 5) << endl;return 0;
}则结果如下:

我们发现compare能比较的情况还是比较多的,我们用得时候也需要注意其每个参数对应的位置!
2.成员变量

这个不是真正的变量,因为它是不能被改变的,只能为一个值。
为何要单独设置一个分类呢?
这个npos在string类中用得还是比较多的,然后也是很多人不了解它的用法的,所以单独列出来也有作用的。
string::npos

我们在它的定义中可以看到该东西表示最大值,这个最大值取决于操作系统,在64位系统上是2^64-1,它用法除了在string类定义里面用到外,还用作很多判断是否到结尾等等,如我们用string::find函数时没有找到的时候就会返回npos,而我们可以通过这个来判断是否找到该字符串/字符/string对象,也可以用作缺省值,还可以用来做循环语句的判断等等。
总之,这个npos就是-1,虽然它是size_t类型,但是C/C++ 标准规定的,任何负数赋值给无符号变量都会按模运算转换为正数。而-1则会通过正反补码转换为整型最大值。
为什么它会置为-1,而不是其他值?
以下是deepseek的回答:
-
find()等函数返回的是位置索引,合法范围是[0, str.size()-1]。 -
npos必须是一个不可能出现在正常字符串中的索引值,而size_t的最大值(-1)显然远大于任何可能的字符串长度(str.size()最大也远小于npos),因此可以安全表示“未找到”。 -
C++ 的
string类设计借鉴了 C 风格字符串的处理方式,其中size_t是无符号类型,-1被广泛用于表示“无效索引”或“未找到”(如string::find和strchr的返回逻辑类似)。 -
使用
-1(即无符号最大值)可以避免与任何合法的字符串位置冲突。 -
这种设计既符合 C++ 标准库的通用规范,又能高效、安全地处理字符串查找逻辑。
3.非成员函数重载
该部分包含以下函数(不是string类中定义的,但是和string类用法有关联,可以视为是string类的友元函数):

3.1std::operator+(string)

这些重载函数都会返回一个string对象(不是对象的引用,因为这样会导致返回无效)。
我们都知道+可以把两个对象连接起来的作用,可以视为+这个函数可以把两个string对象连接起来,并返回一个结果,也可以连接一个字符串和一个string对象或者连接一个字符和一个string对象。可以视为它不仅可以用作头插,也可以用作尾插,只是功能没有std::string::insert和std::string::push_back两个函数功能多而已,而且理解和使用也很方便。所以一般不是很复杂的用法都可以用这个函数。用法如下(不过多讲解):
#include<iostream>
#include<string>
using namespace std;
//std::operator+(string)
int main()
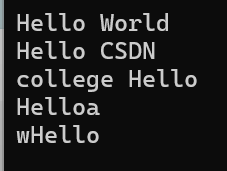
{string s1("Hello");//(1)string s2(" World");cout << s1 + s2 << endl;//(2.1)cout << s1 + " CSDN" << endl;//(2.2)cout << "college " + s1 << endl;//(3.1)cout << s1 + 'a' << endl;//(3.2)cout << 'w' + s1 << endl;return 0;
}运行结果如下:
3.2relational operators(string)
这些都是关系运算符,就不做过多讲解了。
3.3std::swap(string)
我们发现这个之前好像讲过(在string类的成员函数里面有的)!这是之前讲的:

这是这次讲的:

为什么还要专门为string类设置一个swap函数?
我们需要了解一下在标准库里面的swap函数了!
我们发现这个标准库里面的函数是模板函数,如果我们想要交换俩个string类,而不想要用string类里面定义的成员函数的话,我们就会写为string a,b;swap(a,b);而标准库里面的是模板函数,如果想要用它还要实例化一个特定的函数,代价大,我们知道在实现交换函数的时候会创建一个临时变量,而且还需要三个=来进行赋值,这样会调用拷贝构造,很麻烦,还要额外创建一个对象,代价比较大,所以我们需要一个函数来减少代价。
之前我们了解到当有现成的函数的时候,编译器会优先使用现成的函数,而不会重新创建一个新函数来得到结果,所以额外重载了一个专门用作string的swap函数,方便一些,虽然它也是包含于标准库里面的,但是它用法和成员函数差不多,只要用string s1,s2;std::swap(s1,s2);即可(如果using namespace std展开了std就不用指定类域了)。这样也是C++设计的巧妙之处。
这个就不做过多讲解了!
3.4std::operator<<(string)和std::operator>>(string)
这两个是流插入和流提取操作符,流插入的用法之前在演示中都讲过了,只是现在流提取没有演示,这里演示一下:
#include<iostream>
#include<string>
using namespace std;
//std::operator<<(string)
//std::operator>>(string)
int main()
{string s1;cin >> s1;cout << s1 << endl;return 0;
}运行结果如下:
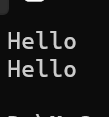
第一行是输入结果,第二行是输出结果。此外输入输出都可以连续输入连续输出,但是如果输入string类是不能通过>>来进行‘ ’的输入的,因为C++默认‘ ’是给下一个提取串的。这就需要我们的另外一个解决该问题的函数std::getline函数了。
3.5std::getline(string)

我们看不懂那个istream这个类型,先不用管他,我们只要知道它的用法即可。
这个函数可以获取一行到所有串给str对象,也可以自己设置一个结束符,遇到这个结束符即结束了,这是这个函数的用法:
#include<iostream>
#include<string>
using namespace std;
//std::geline(string)
int main()
{//传统输入string s1;cin >> s1;cout << s1 << endl;getline输入//string s2;//getline(cin, s2);//cout << s2 << endl;getline设置结束符的输入//string s3;//getline(cin, s3, '&');//cout << s3 << endl;return 0;
}运行结果如下:
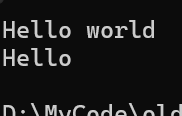
第一行为输入,第二行为结果,我们发现是不能全部读取的,只能读取前面一部分,和scanf函数的结束一样,我们如果遇到\n也是会结束输入的,但是getline就不一样了!
#include<iostream>
#include<string>
using namespace std;
//std::geline(string)
int main()
{传统输入//string s1;//cin >> s1;//cout << s1 << endl;//getline输入string s2;getline(cin, s2);cout << s2 << endl;//getline设置结束符的输入//string s3;//getline(cin, s3, '&');//cout << s3 << endl;return 0;
}运行结果如下:
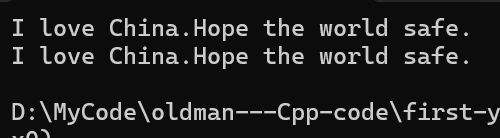
getline默认是遇到\n换行的,所以我们可以用这种方式来实现一行的输入。
当然我们也可以设置一个指定的字符来结束:
#include<iostream>
#include<string>
using namespace std;
//std::geline(string)
int main()
{传统输入//string s1;//cin >> s1;//cout << s1 << endl;//getline输入//string s2;//getline(cin, s2);//cout << s2 << endl;//getline设置结束符的输入string s3;getline(cin, s3, '&');cout << s3 << endl;return 0;
}运行结果如下:
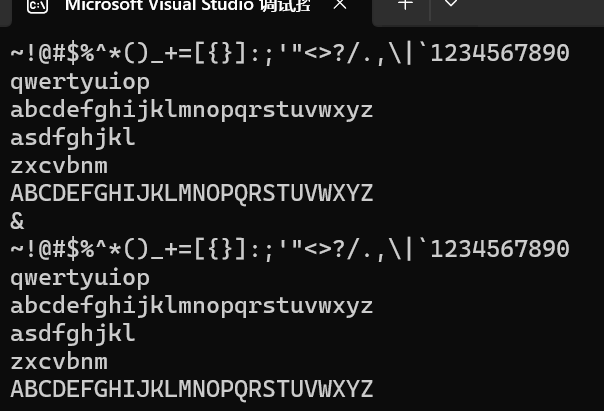
我们发现我们的\n是不会打印出来的,而是直接换行,我们遇到换行也不结束,只有遇到了&才结束插入,这个函数也是用处很多的。
4.*string的扩容Vs和g++版本(扩展知识)
在我们学了string类后我们确实也知道了一部分的string的知识,但如果我们运行以下代码,你觉得结果会怎么样:
#include<iostream>
#include<string>
using namespace std;
//string的扩容
int main()
{string s;//s.reserve(1000);size_t old = s.capacity();cout << "capacity changed: " << old << '\n';cout << "making s grow:\n";for (int i = 0; i < 1000; ++i){//s.push_back('c');s += 'c';if (old != s.capacity()){old = s.capacity();cout << "capacity changed: " << old << '\n';}}return 0;
}在VS运行结果如下:
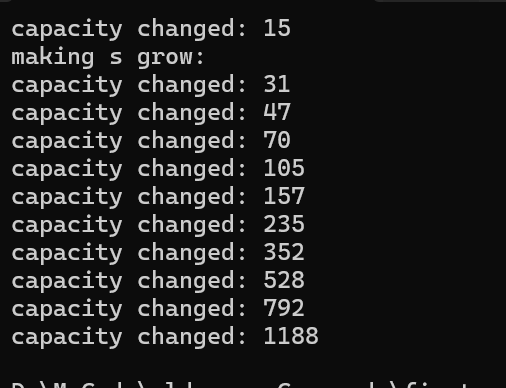
这个打印的结果是不包含\0的结果,所以需要+1这个结果,我们可以通过观察发现开始本来是二倍扩容,结果到后面就变成了1.5倍扩容,这是什么原因呢?
我们如果用常规的想法确实是很难猜出来个大概的,所以我们需要考虑一下到底、string类定义的成员变量有哪些了!
我们一般认为string类里面有这几个成员变量:size用于表示有效元素个数;capacity用于表示该string类最多能存储的元素个数;str(准确来说前面加了_)用来存储数据的数组(不一定是字符)。
但是我们有没有想过一个问题:为什么开始是能存储16个数据,而不是其他结果?
这就涉及到一个额外的知识了,如果string类存储的数据不是很多,那么就不会额外开辟空间去存储数据了,而是存储在一个名字叫buff的数组里面,而这个数组刚好是开辟16个元素的空间,如果在空间不够的时候,它不会扩容,但是会把capacity*2,并把数组里面的数据拷贝到那个str数组中,也就是说如果我们运行string s1;cout<<sizeof(s1)<<endl;如果在VS2022上运行,那么结果为:
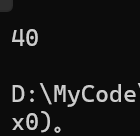
原因我问了deepseek它的结果如下:
在 MSVC 的 STL 实现中,std::string 可能包含:
-
指向堆内存的指针(8 字节,64位系统)。
-
字符串长度信息(8 字节,
size_t)。 -
SSO 缓冲区(通常 16 字节,存储短字符串)。
-
其他控制信息(如分配器、调试信息等)。
-
指针:8 字节
-
大小:8 字节
-
SSO 缓冲区:16 字节
-
其他(调试/对齐):8 字节
总计:8 + 8 + 16 + 8 = 40 字节
因为指针是有8个内存的地址的,而int类型有两个变量,占4个字节,而且之前我们还讲过有npos这个静态变量,但是它是不在里面的,所以可以视为还有其他的变量等。
但是这个16字节是一定存在的,而且开始就创建了(实例化对象时),所以证明了这个观点。
那么为什么还要有g++的结果呢?
因为每个编译器对这种情况的处理不同,而在g++中是二倍扩容,而且是一定的,如下:
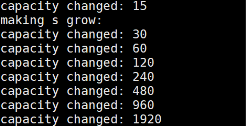
虽然开始的也是16个空间,而后面就是一直二倍扩容了,所以扩容在不同的编译器是不一样的,故我们不能用C++来解释如何扩容,因为每个扩容方式都有各自的好处,而只能通过注意来知道。
为什么要了解它呢?
这样我们就知道buff的作用了,也解决了一部分后面我们如果插入10个数据结果不是其他的结果的原因等问题了,所以这了解一下还是有用的!
5.总结
该讲已经把基本涉及string类的函数讲完了,而下讲将是string类的应用,只有几个简单的题目,因为之前的讲的函数太多了,而且C++讲了快一半了,没有练习一些也是不好的,所以感兴趣的可以看一下。喜欢的可以一键三连哦,下讲再见!
