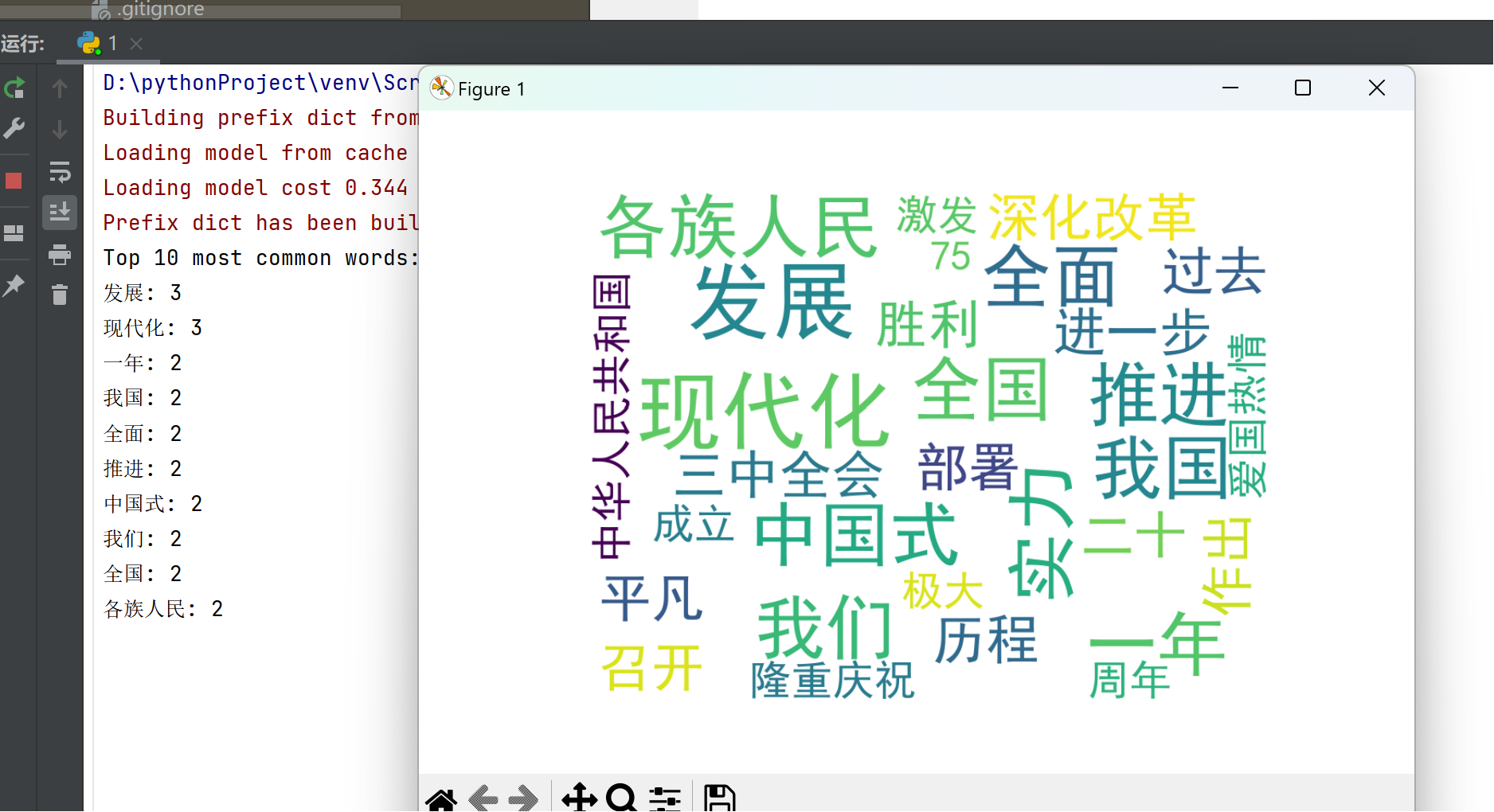
编写程序,统计两会政府工作报告热词频率,并生成词云
代码:
import jieba
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as pltdef generate_wordcloud():try:# 读取文本文件with open('E:\\桌面\\s.txt', 'r', encoding='utf-8') as file:text = file.read()# 中文分词words = jieba.lcut(text)# 直接使用分词结果,不过滤停用词filtered_words = [word for word in words if len(word) > 1]# 统计词频word_counts = Counter(filtered_words)# 获取前 10 高频词top_10_words = word_counts.most_common(10)print("前 10 高频词:", top_10_words)# 生成词云wordcloud = WordCloud(font_path='simhei.ttf', # 中文字体路径,可根据实际情况修改background_color='white',width=800,height=600).generate_from_frequencies(dict(top_10_words))# 显示词云plt.figure(figsize=(8, 6))plt.imshow(wordcloud, interpolation='bilinear')plt.axis('off')plt.show()except FileNotFoundError:print("未找到文本文件,请检查文件路径和文件名。")if __name__ == "__main__":generate_wordcloud()运行截图: