25:三大分类器原理
1.分类的逻辑;
2.统计学与数据分析。
************************
Mlp 多层感知系统
GMM 高斯混合模型-极大似然估计法
SVM 支持向量机建立一个超平面作为决策曲面,使得正例和反例的隔离边界最大化
Knn
1.MLP整个模型就是这样子的,上面说的这个三层的MLP用公式总结起来就是,函数G是softmax
因此,MLP所有的参数就是各个层之间的连接权重以及偏置,包括W1、b1、W2、b2。对于一个具体的问题,怎么确定这些参数?求解最佳的参数是一个最优化问题,解决最优化问题,最简单的就是梯度下降法了(SGD):首先随机初始化所有参数,然后迭代地训练,不断地计算梯度和更新参数,直到满足某个条件为止(比如误差足够小、迭代次数足够多时)。这个过程涉及到代价函数、规则化(Regularization)、学习速率(learning rate)、梯度计算等,本文不详细讨论,读者可以参考本文顶部给出的两个链接。
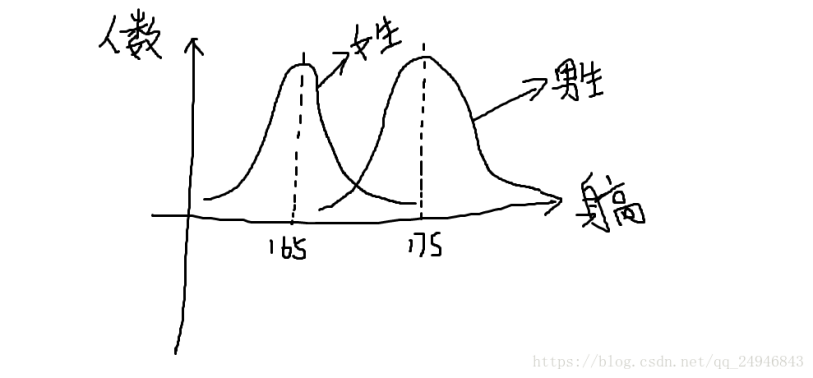
2.高斯混合模型是将多个服从高斯分布的模型进行线性组合,几乎能拟合成任何一条曲线。比如在生活中男生身高普遍在175左右,女生身高普遍在165左右,并且都服从高斯分布,就可通过中间交叉点进行分类。
3.EM算法原理推导
3.1 EM算法与极大似然估计的区别于联系(直接饮用李航-统计学习方法中的内容)
概率模型有时即含有观测变量,又含有隐变量或潜在变量,如果概率模型的变量都是观测变量,那么给定数据,可以直接用极大似然估计法,或者贝叶斯估计法估计模型参数。但是当模型含有隐量时,就不能简单的用这些估计方法,EM算法就是含有隐变量的概率模型参数的极大似然估计法
什么是隐变量?
举例:比如现要在一所学校中随机选取1000个人测量身高,最终我们会得到一个包含1000个身高数据的数据集,此数据集就称为观测变量,那这1000个学生中,既有男生又有女生,我们在选取完成以后并不知道男生和女生的比例是多少?此时这1000名学生中男生的占比以及女生的占比就称为隐变量
-
- SVM
快速理解SVM原理
很多讲解SVM的书籍都是从原理开始讲解,如果没有相关知识的铺垫,理解起来还是比较吃力的,以下的一个例子可以让我们对SVM快速建立一个认知。
给定训练样本,支持向量机建立一个超平面作为决策曲面,使得正例和反例的隔离边界最大化。
决策曲面的初步理解可以参考如下过程,
- 如下图想象红色和蓝色的球为球台上的桌球,我们首先目的是找到一条曲线将蓝色和红色的球分开,于是我们得到一条黑色的曲线。
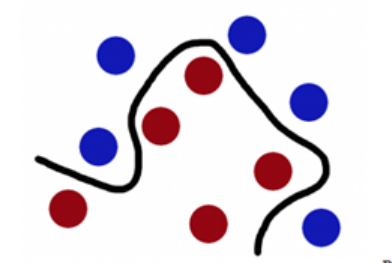
图一.
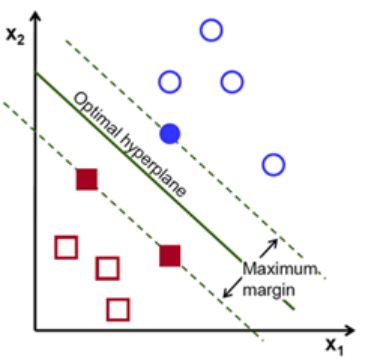
2) 为了使黑色的曲线离任意的蓝球和红球距离(也就是我们后面要提到的margin)最大化,我们需要找到一条最优的曲线。如下图,
- 多层感知机(MLP)原理简介
- https://blog.csdn.net/xueli1991/article/details/52386611
多层感知机(MLP,Multilayer Perceptron)也叫人工神经网络(ANN,Artificial Neural Network),除了输入输出层,它中间可以有多个隐层,最简单的MLP只含一个隐层,即三层的结构,如下图:
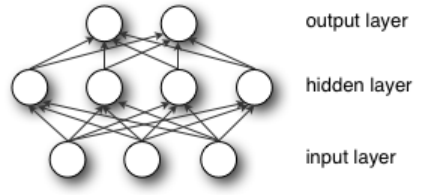
从上图可以看到,多层感知机层与层之间是全连接的(全连接的意思就是:上一层的任何一个神经元与下一层的所有神经元都有连接)。多层感知机最底层是输入层,中间是隐藏层,最后是输出层。
输入层没什么好说,你输入什么就是什么,比如输入是一个n维向量,就有n个神经元。
隐藏层的神经元怎么得来?首先它与输入层是全连接的,假设输入层用向量X表示,则隐藏层的输出就是
f(W1X+b1),W1是权重(也叫连接系数),b1是偏置,函数f 可以是常用的sigmoid函数或者tanh函数:
最后就是输出层,输出层与隐藏层是什么关系?其实隐藏层到输出层可以看成是一个多类别的逻辑回归,也即softmax回归,所以输出层的输出就是softmax(W2X1+b2),X1表示隐藏层的输出f(W1X+b1)。
MLP整个模型就是这样子的,上面说的这个三层的MLP用公式总结起来就是,函数G是softmax
因此,MLP所有的参数就是各个层之间的连接权重以及偏置,包括W1、b1、W2、b2。对于一个具体的问题,怎么确定这些参数?求解最佳的参数是一个最优化问题,解决最优化问题,最简单的就是梯度下降法了(SGD):首先随机初始化所有参数,然后迭代地训练,不断地计算梯度和更新参数,直到满足某个条件为止(比如误差足够小、迭代次数足够多时)。这个过程涉及到代价函数、规则化(Regularization)、学习速率(learning rate)、梯度计算等,本文不详细讨论,读者可以参考本文顶部给出的两个链接。
了解了MLP的基本模型,下面进入代码实现部分。
- 高斯混合模型GMM是一个非常基础并且应用很广的模型。对于它的透彻理解非常重要。网上的关于GMM的大多资料介绍都是大段公式,而且符号表述不太清楚,或者文笔非常生硬。本文尝试用通俗的语言全面介绍一下GMM,不足之处还望各位指正。
浅显易懂的GMM模型及其训练过程 - maxandhchen - 博客园
首先给出GMM的定义
这里引用李航老师《统计学习方法》上的定义,如下图:

定义很好理解,高斯混合模型是一种混合模型,混合的基本分布是高斯分布而已。
第一个细节:为什么系数之和为0?
PRML上给出过一张图:

这图显示了拥有三个高斯分量的一个维度的GMM是如何由其高斯分量叠加而成。这张图曾经一度对我理解GMM造成了困扰。因为如果是这样的话,那么这三个高斯分量的系数应该都是1,这样系数之和便为3,才会有这样直接叠加的效果。而这显然不符合GMM的定义。因此,这张图只是在形式上展现了GMM的生成原理而并不精确。
那么,为什么GMM的各个高斯分量的系数之和必须为1呢?
其实答案很简单,我们所谓的GMM的定义本质上是一个概率密度函数。而概率密度函数在其作用域内的积分之和必然为1。GMM整体的概率密度函数是由若干个高斯分量的概率密度函数线性叠加而成的,而每一个高斯分量的概率密度函数的积分必然也是1,所以,要想GMM整体的概率密度积分为1,就必须对每一个高斯分量赋予一个其值不大于1的权重,并且权重之和为1。
第二个细节:求解GMM参数为什么需要用EM算法
总所周知,求解GMM参数使用EM算法。但是为什么呢?这样是必须的吗?
首先,类似于其他的模型求解,我们先使用最大似然估计来尝试求解GMM的参数。如下:

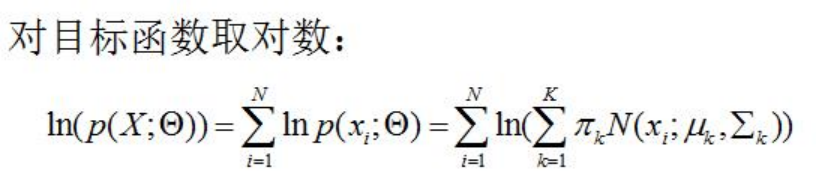
可以看出目标函数是和的对数,很难展开,优化问题麻烦,难以对其进行求偏导处理。因此只能寻求其它方法。那就是EM算法。
第三个细节:求解GMM的EM算法隐变量的理解
使用EM算法必须明确隐变量。求解GMM的时候设想观测数据x是这样产生的:首选依赖GMM的某个高斯分量的系数概率(因为系数取值在0~1之间,因此可以看做是一个概率取值)选择到这个高斯分量,然后根据这个被选择的高斯分量生成观测数据。然后隐变量就是某个高斯分量是否被选中:选中就为1,否则为0。
按照这样的设想:隐变量是一个向量,并且这个向量中只有一个元素取值为1,其它的都是0。因为假设只有一个高斯分量被选中并产生观测数据。然而我们的GMM的一个观测数据在直观上应该是每个高斯分量都有产生,而不是由一个高斯分量单独生成,只是重要性不同(由系数控制)。那么,这样的隐变量假设合理吗?
答案是合理,只是理解起来比较“费劲”而已。
首先明确一点:GMM的观测数据是啥,GMM的函数结果又是啥。如果是一个一维的GMM,那么其观测数据就是任意一个实数。而GMM这个概率密度函数在输入这个观测数据之后输出的是这个实数被GMM产生的概率而已。
接着,现在我们不知道GMM具体的参数值,想要根据观测数据去求解其参数。而GMM的参数是由各个高斯分量的参数再加上权值系数组成的。那么我们就先假定,如果这个观测值只是由其中一个高斯分量产生,去求解其中一个高斯分量的参数。我们假设不同的观测值都有一个产生自己的唯一归宿,就像K-means算法一样。然后在后面的迭代过程中,根据数据整体似然函数的优化过程,逐渐找到一个最优的分配方案。然而,不同于K-means算法的是,我们最终给出的只是某一个观测是由某一个高斯分量唯一生成的概率值,而不是确定下来的属于某一类。每个高斯分量其实都可以产生这个观测数据只是输出不同而已,即产生观测数据的概率不同。最后,根据每个高斯分量产生观测数据的可能性不同,结合其权值汇总出整个GMM产生这个观测数据的概率值。
终极理解:使用EM算法求解GMM参数
1、定义隐变量
我们引入隐变量γjk,它的取值只能是1或者0。
- 取值为1:第j个观测变量来自第k个高斯分量
- 取值为0:第j个观测变量不是来自第k个高斯分量
那么对于每一个观测数据yj都会对应于一个向量变量Γj={γj1,...,γjK},那么有:
∑k=1Kγjk=1
p(Γj)=∏k=1Kαkγjk
其中,K为GMM高斯分量的个数,αk为第k个高斯分量的权值。因为观测数据来自GMM的各个高斯分量相互独立,而αk刚好可以看做是观测数据来自第k个高斯分量的概率,因此可以直接通过连乘得到整个隐变量Γj的先验分布概率。
2、得到完全数据的似然函数
对于观测数据yj,当已知其是哪个高斯分量生成的之后,其服从的概率分布为:
p(yj|γjk=1;Θ)=N(yj|μk,Σk)
由于观测数据从哪个高斯分量生成这个事件之间的相互独立的,因此可以写为:
p(yj|Γj;Θ)=∏k=1KN(yj|μk,Σk)γjk
这样我们就得到了已知Γj的情况下单个观测数据的后验概率分布。结合之前得到的Γj的先验分布,则我们可以写出单个完全观测数据的似然函数为:
p(yj,Γj;Θ)=∏k=1KαkγjkN(yj|μk,Σk)γjk
最终得到所有观测数据的完全数据似然函数为:
p(y,Γj;Θ)=∏j=1N∏k=1KαkγjkN(yj|μk,Σk)γjk
取对数,得到对数似然函数为:
lnp(y,Γj;Θ)=∑j=1N∑k=1K(γjklnαk+γjklnN(yj|μk,Σk))
3、得到各个高斯分量的参数计算公式
首先,我们将上式中的lnN(yj|μk,Σk)根据单高斯的向量形式的概率密度函数的表达形式展开:
lnN(yj|μk,Σk)=−D2ln(2π)−12ln|Σk|−12(yj−μk)TΣ−1k(yj−μk)
假设我们已经知道隐变量γjk的取值,对上面得到的似然函数分别对αk和Σk求偏导并且偏导结果为零,可以得到:
μk=∑Nj=1∑Kk=1γjkyj∑Nj=1∑Kk=1γjk
Σk=∑Nj=1∑Kk=1γjk(yj−μk)(yj−μk)T∑Nj=1∑Kk=1γjk
由于在上面两式的第二个求和符号是对k=1...K求和,而在求和过程中γjk只有以此取到1,其它都是0,因此上面两式可以简化为:
μk=∑Nj=1γjkyj∑Nj=1γjk
Σk=∑Nj=1γjk(yj−μk)(yj−μk)T∑Nj=1γjk
现在参数空间中剩下一个αk还没有求。这是一个约束满足问题,因为必须满足约束ΣKk=1αk=1。我们使用拉格朗日乘子法结合似然函数和约束条件对αk求偏导,可以得到:
αk=∑Nj=1γjk−λ
将上式的左右两边分别对k=1...K求和,可以得到:
λ=−N
将λ代入,最终得到:
αk=∑Nj=1γjkN
至此,我们在隐变量已知的情况下得到了GMM的三种类型参数的求解公式。
4、得到隐变量的估计公式
根据EM算法,现在我们需要通过当前参数的取值得到隐变量的估计公式也就是说隐变量的期望的表达形式。即如何求解E{γjk|y,Θ}。
E{γjk|y,Θ}=P(γjk=1|y,Θ)
=P(γjk=1,yj|Θ)∑Kk=1P(γjk=1,yj|Θ)
=P(yj|γjk=1,Θ)P(γjk=1|Θ)∑Kk=1P(yj|γjk=1,Θ)P(γjk=1|Θ)
=αkN(yj|μk,Σk)∑Kk=1αkN(yj|μk,Σk)
5、使用EM算法迭代进行参数求解
熟悉EM算法的朋友应该已经可以从上面的推导中找到EM算法的E步和M步。
GMM和K-means直观对比
最后我们比较GMM和K-means两个算法的步骤。
GMM:
- 先计算所有数据对每个分模型的响应度
- 根据响应度计算每个分模型的参数
- 迭代
K-means:
- 先计算所有数据对于K个点的距离,取距离最近的点作为自己所属于的类
- 根据上一步的类别划分更新点的位置(点的位置就可以看做是模型参数)
- 迭代
可以看出GMM和K-means还是有很大的相同点的。GMM中数据对高斯分量的响应度就相当于K-means中的距离计算,GMM中的根据响应度计算高斯分量参数就相当于K-means中计算分类点的位置。然后它们都通过不断迭代达到最优。不同的是:GMM模型给出的是每一个观测点由哪个高斯分量生成的概率,而K-means直接给出一个观测点属于哪一类。
3.支持向量机
1.支持向量机介绍:
支持向量机(Support Vector Machine,SVM)是Corinna Cortes和Vapnik于1995年首先提出的,它在解决小样本、非线性及高维模式识别表现出许多特有的优势。
- 支持向量机原理:
2.1在n维空间中找到一个分类超平面,将空间上的点分类,虚线上的点叫做支持向量机Supprot Verctor,中间红线叫超级平面,SVM目的是拉大所有点到超级平面的距离。