Redis源码阅读(一)跳表
文章目录
- Redis跳表实现详解
- 1. 核心数据结构
- 1.1 跳表节点
- 1.2 跳表结构
- 2. 核心功能实现
- 2.1 创建跳表
- 2.2 层数随机化函数
- 2.2.1 函数详细解析
- 初始化层数
- 随机决定是否增加层数
- 限制最大层数
- 概率分析
- 位操作说明
- 位操作示例
- 在随机层数中的应用
- 2.3 插入操作
- 3. 插入操作的步骤解析
- 3.1 查找插入位置
- 3.2 随机生成新节点的层数
- 3.3 创建新节点并设置指针关系
- 3.4 更新高层的跨度
- 3.5 设置后退指针
- 3.6 更新跳表节点计数并返回
- 4. Redis跳表中的跨度与排名作用分析
- 4.1 跨度(span)的定义与作用
- 4.1.1 跨度的核心作用
- 4.2 排名(rank)数组的作用
- 4.2.1 排名数组的主要用途
- 4.3 跨度计算与更新实例
- 4.4 实际应用场景
- 4.5 设计优势
- 5. Redis跳表插入中记录前驱节点的作用
- 5.1 示例说明
- 5.1.1 找到前驱节点并填充update数组
- 5.1.2 随机生成新节点层数
- 5.1.3 利用update数组插入新节点
- 5.2 update数组的关键作用
- 6. 删除操作
- 6.1 删除操作的关键步骤
- 6.2 删除操作的复杂度
- 7. 查找操作
- 7.1 查找操作的原理
- 7.2 查找效率分析
- 8. 按排名查找
- 8.1 按排名查找的实现原理
- 8.2 按排名查找的应用
- 8.3 效率分析
- 附(问题)
- 9.1 什么场景下会需要用到跳表和红黑树?
- 9.1.1 跳表适用场景
- 9.1.2 红黑树适用场景
- 9.1.3 Redis选择跳表而非红黑树的原因
- 9.2 普通链表的查找复杂度,为什么双向链表可以降低查询复杂度?
- 9.2.1 普通链表的查找复杂度
- 9.2.2 双向链表如何降低查询复杂度
- 9.2.3 相关问题
- 1. 跳表与平衡树相比有什么优势和劣势?
- 2. 为什么Redis不使用B+树作为有序集合的实现?
- 3. 跳表的空间复杂度是多少?
- 4. 如何优化跳表以减少内存使用?
- 5. 跳表在并发环境下的表现如何?
- 参考
Redis跳表实现详解
跳表只在Redis的有序集合中用到了。
- 什么场景下会需要用到跳表和红黑树
- 普通链表的查找复杂度,为什么双向链表可以降低查询复杂度
1. 核心数据结构
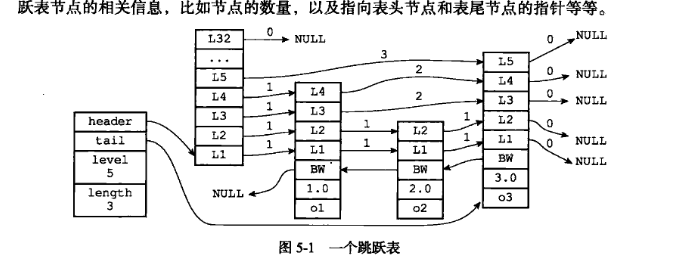
1.1 跳表节点
typedef struct zskiplistNode {sds ele; // 成员对象(键)double score; // 分值struct zskiplistNode *backward; // 后退指针struct zskiplistLevel {struct zskiplistNode *forward; // 前进指针unsigned long span; // 跨度} level[]; // 柔性数组,每个节点的层
} zskiplistNode;
1.2 跳表结构
typedef struct zskiplist{struct zskiplistNode *header, *tail;unsigned long length;int level;
}zskiplist;
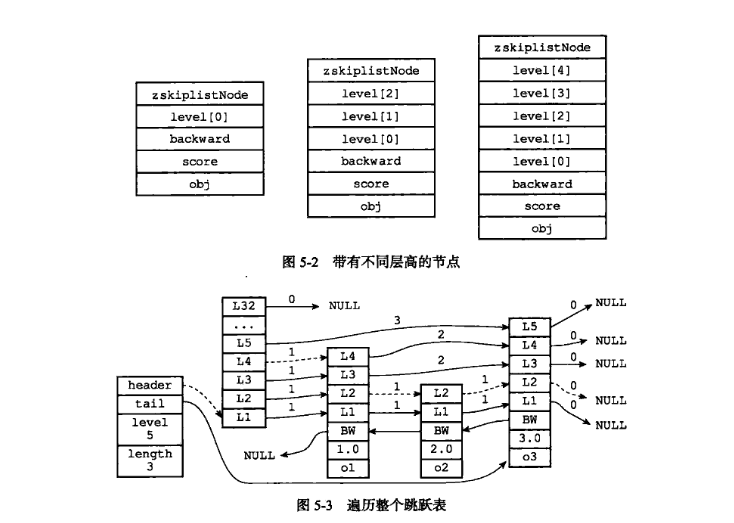
2. 核心功能实现
2.1 创建跳表
zskiplistNode *zslCreateNode(int level, double score, sds ele){zskiplistNode *zn = zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));zn->score = score;zn->ele = ele;return zn;
}zskiplist *zslCreate(void){int j;zskiplist *zsl;zsl = zmalloc(sizeof(*zsl));zsl->level = 1;zsl->length = 0;//初始化表头节点,表头节点层数为ZSKIPLIST_MAXLEVEL=32zsl->header = zslCreateNode();for(int j = 0; j < ZSKIPLIST_MAXLEVEL; j++){zsl->header->level[j].forward = null;zsl->header->level[j].span = 0;}zsl->header->backward = null;zsl->tail = null;return zsl;
}
2.2 层数随机化函数
int zslRandomLevel(void) {int level = 1;while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))level += 1;return (level < ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
2.2.1 函数详细解析
初始化层数
每个节点至少有1层(level = 1)。
随机决定是否增加层数
random()生成一个随机数&0xFFFF对随机数进行位与操作,取低16位(0-65535)ZSKIPLIST_P * 0xFFFF计算概率阈值(Redis中ZSKIPLIST_P=0.25)- 当随机数小于概率阈值时,层数加1
限制最大层数
- 如果生成的层数小于
ZSKIPLIST_MAXLEVEL(32),则使用生成的值 - 否则使用
ZSKIPLIST_MAXLEVEL作为上限
概率分析
这个函数实现了几何分布,具有以下特性:
- 每个节点至少有1层(概率为1)
- 有2层的概率是0.25(25%)
- 有3层的概率是0.25²(6.25%)
- 有4层的概率是0.25³(约1.56%)
这种分布保证了:
- 大多数节点只有少数几层,节省内存
- 少数节点有较多层,提供快速访问路径
- 理论上层数期望值为 1/(1-p) = 1/(1-0.25) = 4/3 ≈ 1.33层
位操作说明
使用random()&0xFFFF是为了:
- 将随机数限制在固定范围(0-65535)
- 避免处理负数和浮点数计算
- 使用位操作比取模更高效
位操作示例
例子1:random() = 42949
十进制值: 42949
二进制表示: 0000 0000 0000 1010 0111 1100 0101
与 0xFFFF 进行位与:0000 0000 0000 1010 0111 1100 0101 (42949)
& 0000 0000 0000 0000 1111 1111 1111 (0xFFFF)--------------------------------0000 0000 0000 0000 0111 1100 0101 (1985)
例子2:random() = 98732
十进制值: 98732
二进制表示: 0000 0000 0001 1000 0001 1101 1100
与 0xFFFF 进行位与:0000 0000 0001 1000 0001 1101 1100 (98732)
& 0000 0000 0000 0000 1111 1111 1111 (0xFFFF)--------------------------------0000 0000 0000 0000 0001 1101 1100 (476)
例子3:random() 返回 2147483647 (0x7FFFFFFF,32位有符号整数的最大值)
十进制值: 2147483647
二进制表示: 0111 1111 1111 1111 1111 1111 1111
与 0xFFFF 进行位与:0111 1111 1111 1111 1111 1111 1111 (2147483647)
& 0000 0000 0000 0000 1111 1111 1111 (0xFFFF)--------------------------------0000 0000 0000 0000 1111 1111 1111 (65535)
结果:65535 (0xFFFF的十进制值)
在随机层数中的应用
- 范围限制: 将随机数限制在0-65535之间
- 概率计算: 与概率阈值比较(0.25*65535≈16383)
- 随机值<16383时(25%概率),层数增加
- 简化: 使用位操作提高效率
这种设计确保了跳表形成有效的"跳跃"特性,实现O(log n)的查找复杂度。
2.3 插入操作
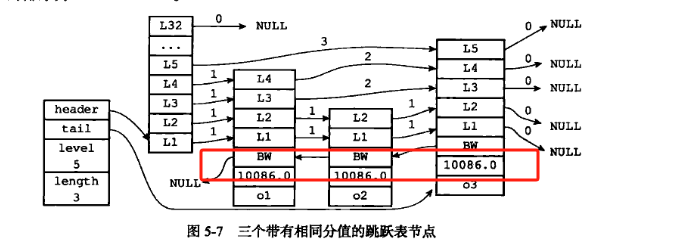
因为可能会有score相等的情况所以还要增加一个比较字典续
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;unsigned int rank[ZSKIPLIST_MAXLEVEL];int i, level;x = zsl->header;// 自上而下遍历每一层for (i = zsl->level-1; i >= 0; i--) {// 初始化rank值rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];// 在当前层查找合适的插入位置while (x->level[i].forward &&(x->level[i].forward->score < score ||(x->level[i].forward->score == score &&sdscmp(x->level[i].forward->ele,ele) < 0))){rank[i] += x->level[i].span; // 累加跨度x = x->level[i].forward; // 前进}update[i] = x; // 记录每一层插入位置的前驱节点}// ... 后续代码
}
3. 插入操作的步骤解析
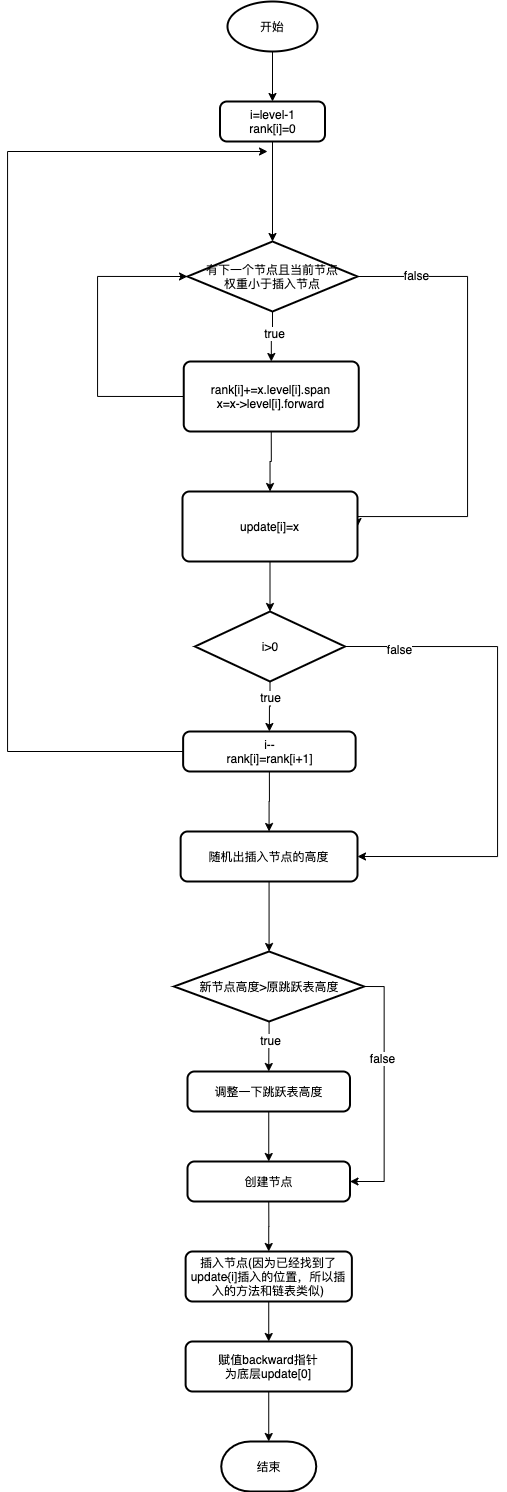
3.1 查找插入位置
首先,函数从跳表的最高层开始,自上而下查找新节点的插入位置:
update数组:记录每一层中新节点的前驱节点rank数组:记录每一层中前驱节点的排名
查找过程中有两个关键操作:
- 在每一层查找score值大于等于新节点的节点
- 如果score值相同,则比较成员(ele)的字典序
3.2 随机生成新节点的层数
level = zslRandomLevel();
if (level > zsl->level) {for (i = zsl->level; i < level; i++) {rank[i] = 0;update[i] = zsl->header;update[i]->level[i].span = zsl->length;}zsl->level = level; // 更新跳表最大层数
}
如果新节点的层数超过当前跳表的最大层数,则需要更新跳表的层数并初始化新增层的update和rank信息。
3.3 创建新节点并设置指针关系
x = zslCreateNode(level, score, ele);// 设置前进指针和跨度
for (i = 0; i < level; i++) {x->level[i].forward = update[i]->level[i].forward;update[i]->level[i].forward = x;// 更新跨度x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
这部分代码完成了新节点的插入和前进指针的设置,并更新了跨度值。跨度计算特别重要:
rank[0]是最底层前驱节点的排名rank[i]是第i层前驱节点的排名rank[0] - rank[i]表示从第i层前驱节点下降到最底层前驱节点需要跨越的节点数
3.4 更新高层的跨度
// 更新高于新节点的那些层的跨度
for (i = level; i < zsl->level; i++) {update[i]->level[i].span++;
}
对于高于新节点的那些层,需要增加跨度以反映新节点的加入。
3.5 设置后退指针
// 设置后退指针
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)x->level[0].forward->backward = x;
elsezsl->tail = x;
后退指针只在最底层维护,用于支持反向遍历。如果新节点是表尾,还需要更新跳表的tail指针。
3.6 更新跳表节点计数并返回
zsl->length++; // 跳表节点计数增一
return x;
4. Redis跳表中的跨度与排名作用分析
跨度(span)和排名(rank)是Redis跳表实现中的关键概念,它们共同支持了有序集合(sorted set)中按排名查找和操作的功能。
4.1 跨度(span)的定义与作用
跨度存储在跳表节点的每个前向指针中,表示从当前节点沿着前向指针到达下一个节点时"跳过"的节点数量。
struct zskiplistLevel {struct zskiplistNode *forward; // 前进指针unsigned long span; // 跨度
};
4.1.1 跨度的核心作用
- 支持按排名访问:
- 跨度的累加可以精确计算节点的排名
- 跳表可以在O(log n)时间内定位到特定排名的节点
- 范围查询优化:
- 在范围查询中,可以利用跨度快速确定范围内有多少个元素
- 避免不必要的节点访问
- 排名变化追踪:
- 插入或删除节点时,通过更新跨度来反映排名变化
- 无需重新计算整个跳表的排名信息
4.2 排名(rank)数组的作用
rank数组是跳表操作中的临时变量,用于在插入和删除操作中跟踪每一层前驱节点的排名。
unsigned int rank[ZSKIPLIST_MAXLEVEL]; // 在zslInsert函数中
4.2.1 排名数组的主要用途
- 插入时计算新节点的确切位置:
- 记录每层前驱节点的排名
- 用于计算新节点在各层的精确跨度
- 跨度更新依据:
rank[0] - rank[i]表示从第i层前驱下降到最底层前驱的节点数- 用这个差值可以正确计算新节点的跨度
- 确保排名一致性:
- 通过正确更新跨度,保证节点的排名在所有层级上一致
4.3 跨度计算与更新实例
在插入操作中:
// 查找阶段,累加跨度以计算排名
while (x->level[i].forward && ...) {rank[i] += x->level[i].span; // 累加跨度获取排名x = x->level[i].forward;
}// 插入阶段,更新跨度
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;// 更新高层跨度
for (i = level; i < zsl->level; i++) {update[i]->level[i].span++;
}
4.4 实际应用场景
- 排行榜功能:
- ZRANK命令:返回成员在有序集合中的排名
- ZRANGE命令:返回指定排名范围内的成员
- 分页查询:
- 根据排名高效实现数据分页
- 例如:获取排名100-120的用户
- Top-N查询:
- 快速获取分数最高/最低的N个元素
- 无需扫描整个集合
4.5 设计优势
- 性能优化:O(log n)时间复杂度快速定位排名
- 空间高效:只需每个前向指针额外存储一个整数
- 实现简化:避免了复杂的树形结构平衡操作
- 动态维护:插入删除时只需局部更新跨度
跨度和排名的设计体现了Redis数据结构实现的精巧之处,通过巧妙的数据组织,在不增加结构复杂度的前提下实现了高效的排名操作。这一设计为Redis的有序集合提供了强大的排序和排名功能,使其在排行榜、计时统计等场景中有着出色的表现。
5. Redis跳表插入中记录前驱节点的作用
update[i] = x; 这一步骤是Redis跳表插入操作中的关键,它记录了将要插入的新节点在每一层的前驱节点。
5.1 示例说明
假设我们有一个跳表,包含以下节点及其分值(score):
Level 3: header --------------------------------------------------------> 30
Level 2: header ----------------> 10 --------------> 20 ---------------> 30
Level 1: header ------> 5 ------> 10 ------> 15 ---> 20 ------> 25 ---> 30
Level 0: header -> 3 -> 5 -> 7 -> 10 -> 12 -> 15 -> 17 -> 20 -> 23 -> 25 -> 30
现在我们要插入一个新节点,分值为 13。
5.1.1 找到前驱节点并填充update数组
从最高层(Level 3)开始向下搜索:
Level 3:
- 从header开始,下一个节点是30,30 > 13,停止
update[3] = header
Level 2:
- 从header开始,下一个是10,10 < 13,前进
- 到达10,下一个是20,20 > 13,停止
update[2] = 节点10
Level 1:
- 从10开始,下一个是15,15 > 13,停止
update[1] = 节点10
Level 0:
- 从10开始,下一个是12,12 < 13,前进
- 到达12,下一个是15,15 > 13,停止
update[0] = 节点12
最终update数组的值为:
update[3] = header
update[2] = 节点10
update[1] = 节点10
update[0] = 节点12
5.1.2 随机生成新节点层数
假设随机生成的层数为2 (Level 0和Level 1)
5.1.3 利用update数组插入新节点
现在我们创建值为13的新节点,并需要将它插入到跳表中。这时update数组的作用就显现出来了:
对于Level 0:
x->level[0].forward = update[0]->level[0].forward; // 新节点指向节点15
update[0]->level[0].forward = x; // 节点12指向新节点
对于Level 1:
x->level[1].forward = update[1]->level[1].forward; // 新节点指向节点15
update[1]->level[1].forward = x; // 节点10指向新节点
插入后的跳表结构变为:
Level 3: header --------------------------------------------------------> 30
Level 2: header ----------------> 10 --------------> 20 ---------------> 30
Level 1: header ------> 5 ------> 10 ------> 13 ---> 15 ---> 20 ------> 25 ---> 30
Level 0: header -> 3 -> 5 -> 7 -> 10 -> 12 -> 13 -> 15 -> 17 -> 20 -> 23 -> 25 -> 30
5.2 update数组的关键作用
图中这种向下查找的过程就需要每层查找的时候都保留前驱,
第一层是header
第二层y
第三层w
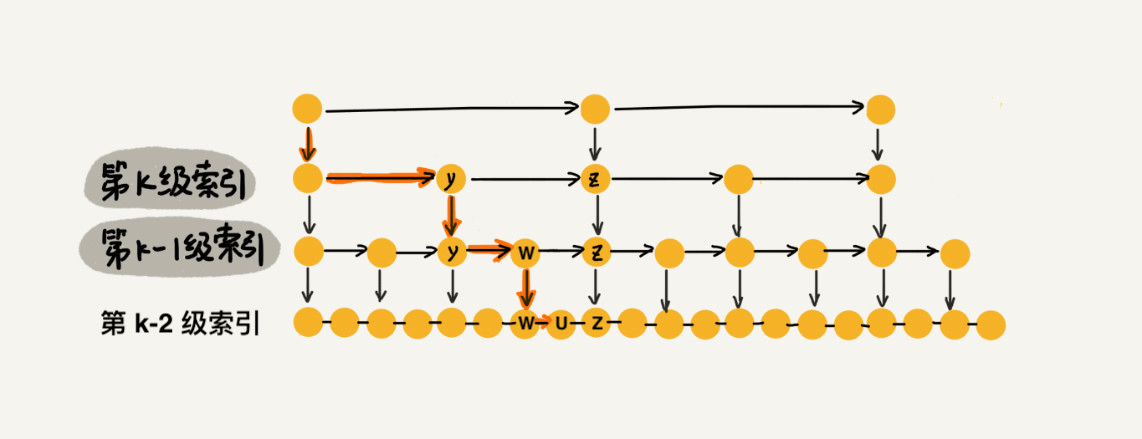
图片来自 https://blog.csdn.net/Zhouzi_heng/article/details/127554294
- 连接前后节点:
- 通过update数组,我们知道每层中新节点应该插入在哪个节点之后
- 这使得我们可以正确连接前后节点的指针,保持跳表的有序性
- 更新跨度值:
- 利用update数组中记录的前驱节点,可以更新这些节点的span值
- 同时设置新节点的span值,确保排名计算的正确性
- 设置后退指针:
- 最底层的前驱节点(update[0])用于设置新节点的后退指针
x->backward = update[0]
- 处理边界情况:
- 如果新节点层数高于当前跳表最大层数,通过update可以连接新增层
- 如果新节点将成为表尾,可以通过update判断并更新tail指针
没有update数组,插入操作将变得非常复杂,可能需要多次遍历跳表来找到每一层的正确插入位置。通过使用update数组,我们只需一次遍历就可以记录所有必要信息,大大提高了插入效率。
6. 删除操作
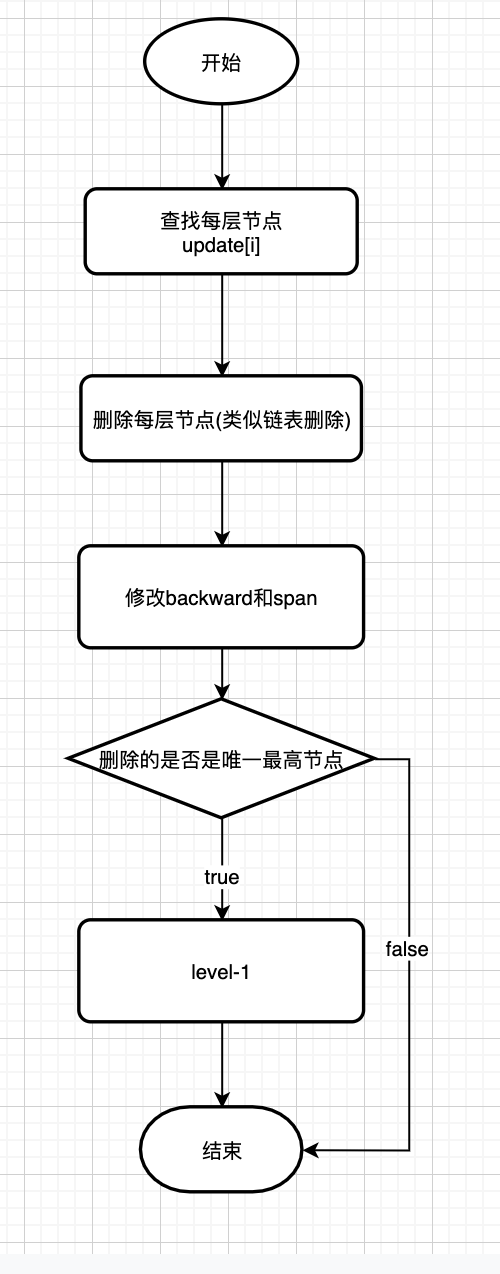
删除操作需要:
- 找到目标节点前驱
- 调整指针和跨度
- 可能需要降低跳表最大层数
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node) {zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;int i;// 从最高层开始查找目标节点的前驱x = zsl->header;for (i = zsl->level-1; i >= 0; i--) {// 查找前驱节点while (x->level[i].forward &&(x->level[i].forward->score < score ||(x->level[i].forward->score == score &&sdscmp(x->level[i].forward->ele,ele) < 0))){x = x->level[i].forward;}update[i] = x; // 记录每层的前驱节点}// 定位到目标节点(如果存在)x = x->level[0].forward;if (x && score == x->score && sdscmp(x->ele,ele) == 0) {// 找到目标节点,执行删除操作zslDeleteNode(zsl, x, update);if (!node)zslFreeNode(x); // 如果不需要返回被删除节点,则释放内存else*node = x; // 否则通过node参数返回被删除节点return 1;}return 0; // 没找到目标节点,返回0表示删除失败
}// 实际执行节点删除的函数
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {int i;// 调整所有层的前进指针和跨度for (i = 0; i < zsl->level; i++) {if (update[i]->level[i].forward == x) {update[i]->level[i].span += x->level[i].span - 1;update[i]->level[i].forward = x->level[i].forward;} else {update[i]->level[i].span -= 1; // 不直接相连的层,只需减少跨度}}// 调整后退指针if (x->level[0].forward) {x->level[0].forward->backward = x->backward;} else {zsl->tail = x->backward;}// 如果删除的是最高层的节点,可能需要降低跳表的最大层数while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)zsl->level--;// 跳表节点计数减一zsl->length--;
}
6.1 删除操作的关键步骤
-
查找目标节点:
- 和插入操作类似,从最高层向下查找
- 记录每一层的前驱节点到update数组
-
调整指针:
- 对于每一层,修改前驱节点的forward指针,绕过被删除节点
- 调整后继节点的backward指针,保持双向链表特性
-
更新跨度:
- 对于直接相连的层:
update[i]->level[i].span += x->level[i].span - 1 - 对于不直接相连的层:
update[i]->level[i].span -= 1
- 对于直接相连的层:
-
处理特殊情况:
- 如果删除的是尾节点,更新tail指针
- 如果删除后最高层没有节点,降低跳表的level值
6.2 删除操作的复杂度
- 时间复杂度:O(log N),主要在于查找目标节点的过程
- 空间复杂度:O(1),仅使用常数额外空间(update数组)
7. 查找操作
查找从最高层开始,逐层降低,每一层都尽可能向前搜索。
zskiplistNode *zslFind(zskiplist *zsl, double score, sds ele) {zskiplistNode *x;int i;// 从最高层开始查找x = zsl->header;for (i = zsl->level-1; i >= 0; i--) {// 在当前层尽可能前进while (x->level[i].forward &&(x->level[i].forward->score < score ||(x->level[i].forward->score == score &&sdscmp(x->level[i].forward->ele,ele) < 0))){x = x->level[i].forward;}}// 现在x->level[0].forward可能是我们要找的节点x = x->level[0].forward;if (x && score == x->score && sdscmp(x->ele,ele) == 0)return x; // 找到目标节点return NULL; // 没找到
}
7.1 查找操作的原理
-
多层跳跃:
- 从最高层开始查找,利用高层快速跳过大量节点
- 当无法在当前层继续前进时,降低一层继续查找
-
匹配条件:
- 首先比较score值
- 如果score相同,则比较成员对象(ele)
-
查找策略:
- 贪心策略:在每一层尽可能向前,直到下一个节点的score大于等于目标score
- 当到达最底层时,检查最后到达的节点是否为目标节点
7.2 查找效率分析
-
平均时间复杂度:O(log N)
- 高层作为快速通道,大大减少了需要访问的节点数
- 层数分布的随机性保证了查找路径的平均长度是对数级的
-
最坏时间复杂度:仍为O(log N)
- 即使在最不利情况下,层数的随机分布也能保证一定的性能
-
空间开销与查找速度的平衡:
- 通过概率分布控制节点的平均层数为常数(约1.33)
- 在空间效率和查找速度之间取得良好平衡
8. 按排名查找
利用跨度(span)快速定位到特定排名的节点。
zskiplistNode *zslGetElementByRank(zskiplist *zsl, unsigned long rank) {zskiplistNode *x;unsigned long traversed = 0;int i;// 从最高层开始查找x = zsl->header;for (i = zsl->level-1; i >= 0; i--) {// 尝试在当前层前进,只要不超过目标排名while (x->level[i].forward && (traversed + x->level[i].span) <= rank) {traversed += x->level[i].span;x = x->level[i].forward;}// 如果已经到达目标排名,返回该节点if (traversed == rank) {return x;}}return NULL; // 目标排名不存在
}
8.1 按排名查找的实现原理
-
利用跨度累加:
- 维护一个traversed变量,记录已经跨越的节点数
- 每次前进时,将当前指针的span值加到traversed上
-
贪心策略:
- 在每一层尽可能前进,直到再前进一步就会超过目标排名
- 然后降低一层继续查找
-
排名匹配:
- 如果traversed正好等于目标rank,说明找到了对应排名的节点
- 注意:Redis的排名是从1开始的,而不是从0开始
8.2 按排名查找的应用
-
ZRANGE命令实现:
- 获取有序集合中指定排名范围的元素
- 首先找到起始排名的节点,然后沿着level[0]前进指定步数
-
ZRANK命令实现:
- 获取指定成员在有序集合中的排名
- 使用类似的遍历方式,但是查找特定成员而非特定排名
8.3 效率分析
- 时间复杂度:O(log N),与普通查找操作相同
- 关键优化:跨度(span)的设计使得跳表可以在不增加结构复杂度的情况下,高效支持按排名查找操作
附(问题)
跳表只在Redis的有序集合中用到了。以下是关于跳表、红黑树和链表的一些常见问题解答。
9.1 什么场景下会需要用到跳表和红黑树?
9.1.1 跳表适用场景
-
范围查询频繁的场景:
- 跳表对范围查询非常友好,可以很容易地找到某个范围内的所有元素
- 例如:Redis的ZRANGEBYSCORE命令,查找分数在某个范围内的所有元素
-
需要按序遍历的场景:
- 跳表的底层是一个有序链表,可以方便地进行顺序遍历
- 例如:获取排名前10的玩家
-
经常需要插入和删除的有序数据结构:
- 跳表插入删除的平均时间复杂度为O(log n),且实现相对简单
- 不需要像平衡树那样进行复杂的旋转操作
-
内存空间相对宽裕的场景:
- 跳表需要存储多个层次的索引,空间消耗相对较大
-
实现简单性优先的场景:
- 跳表比红黑树更容易实现和调试
- 代码可维护性更高
9.1.2 红黑树适用场景
-
内存敏感的场景:
- 红黑树比跳表更节省内存
- 例如:嵌入式系统或内存受限的环境
-
单点查询频繁的场景:
- 红黑树的查找性能非常稳定,最坏情况下仍为O(log n)
- 例如:各种Map和Set的实现(如C++ STL中的map, set)
-
绝对平衡要求高的场景:
- 红黑树保证最坏情况下的平衡性,而跳表是概率平衡
- 例如:实时系统需要稳定的响应时间
-
不需要范围查询的有序数据结构:
- 如果主要是查找、插入、删除单个元素,红黑树可能更合适
9.1.3 Redis选择跳表而非红黑树的原因
-
范围操作效率:
- 在Redis有序集合中,范围操作非常常见(如ZRANGE, ZRANGEBYSCORE)
- 跳表在范围查询上性能优于红黑树
-
实现简单性:
- 跳表的实现远比红黑树简单
- 更少的代码意味着更少的bug和更容易的维护
-
内存布局更好:
- 跳表的内存布局更连续,对缓存更友好
- 可以灵活控制索引密度(通过调整层数概率)
-
更易于并发控制:
- 跳表的结构使得并发插入删除相对容易实现
- 虽然Redis是单线程模型,但这种特性在设计上仍有价值
9.2 普通链表的查找复杂度,为什么双向链表可以降低查询复杂度?
9.2.1 普通链表的查找复杂度
-
单向链表:
- 时间复杂度:O(n),必须从头开始遍历
- 只能朝一个方向遍历
- 空间复杂度:每个节点额外存储一个指针
-
双向链表:
- 时间复杂度:对于随机访问仍然是O(n)
- 但可以从两个方向遍历
- 空间复杂度:每个节点额外存储两个指针
9.2.2 双向链表如何降低查询复杂度
双向链表本身对于随机元素的查询复杂度仍然是O(n),但在特定场景下可以提高效率:
-
已知位置附近的查询:
- 如果知道目标元素大约在链表的什么位置,可以选择从头或尾开始遍历
- 例如:元素可能在链表尾部附近,从尾部开始查找更高效
-
频繁访问两端元素:
- 双向链表可以O(1)时间访问头尾元素
- 例如:实现队列或栈时非常高效
-
插入和删除操作:
- 如果已经有指向节点的指针,可以O(1)时间完成插入和删除
- 不需要查找前驱节点,降低了操作复杂度
-
双向遍历需求:
- 某些算法需要同时向前和向后查看元素
- 例如:LRU缓存的实现
在Redis的跳表实现中,双向链表特性(backward指针)主要用于:
- 反向遍历有序集合
- 在删除节点时更容易更新前驱节点
- 支持ZREVRANGE等反向遍历命令
9.2.3 相关问题
1. 跳表与平衡树相比有什么优势和劣势?
优势:
- 实现更简单,代码更易维护
- 插入和删除不需要复杂的平衡操作
- 范围查询效率高
- 空间利用更灵活(可以通过调整概率控制索引密度)
劣势:
- 内存占用通常更高
- 平衡性基于概率,不是严格保证
- 不像某些特殊的树结构那样可以针对特定应用场景高度优化
2. 为什么Redis不使用B+树作为有序集合的实现?
B+树是数据库系统中常用的数据结构,但Redis选择跳表而非B+树的原因包括:
- 内存vs磁盘:B+树主要优化磁盘访问,而Redis是内存数据库
- 实现复杂度:B+树实现比跳表复杂得多
- 单元素操作:在纯内存环境中,跳表的单元素操作不比B+树慢
- 代码可维护性:跳表的代码更简洁,更易于维护
3. 跳表的空间复杂度是多少?
- 期望空间复杂度:O(n)
- 更准确地说,大约需要2n个指针(约1.33n用于索引层,n用于基本链表)
- 跳表的空间开销主要在于索引节点
- 使用p=1/4的层级概率,平均每个节点的指针数约为1.33
4. 如何优化跳表以减少内存使用?
-
调整层数概率:
- 降低p值(如从1/4降至1/8)可以减少索引层数
- 但会略微增加查找时间
-
压缩技术:
- 对于字符串类型的键,可以使用前缀压缩
- 共享公共前缀减少内存使用
-
节点结构优化:
- 使用柔性数组存储层级信息(Redis已采用)
- 小元素可以考虑内联存储
-
索引稀疏化:
- 不是每个节点都创建索引,而是每k个节点创建一个
- 类似于跳表和B树的混合体
5. 跳表在并发环境下的表现如何?
虽然Redis主要是单线程模型,但跳表在并发环境中有以下特点:
-
并发友好结构:
- 跳表的结构使其比平衡树更容易实现无锁操作
- 插入时只影响局部节点,不会导致全局重平衡
-
锁粒度:
- 理论上可以实现细粒度锁,只锁定需要修改的部分
- 不同级别的锁可以分离(例如对高层索引和数据层使用不同的锁)
-
读写分离:
- 读操作可以与写操作并发执行
- 因为查找过程不需要修改跳表结构
-
无锁实现可能性:
- 跳表相对容易实现无锁版本(使用CAS操作)
- 相比之下,无锁红黑树非常复杂
参考
- https://tech.youzan.com/redisyuan-ma-jie-xi/
- https://blog.csdn.net/Zhouzi_heng/article/details/127554294
- 《redis设计与实现》