深入拆解 MinerU 解析处理流程
概述
MinerU更新频率也相当频繁,在短短一个月内,更新了10个小版本。
本文结合最新版本v1.3.10,深入拆解下它进行文档解析时的内部操作细节。
MinerU仓库地址:https://github.com/opendatalab/MinerU
环境准备
在之前的文章中,已经安装了magic-pdf(MinerU的解析包名),先通过以下的命令进行升级。
pip install magic-pdf --upgrade
如果是第一次安装,不需要加--upgrade参数:
pip install magic-pdf
解析步骤拆解
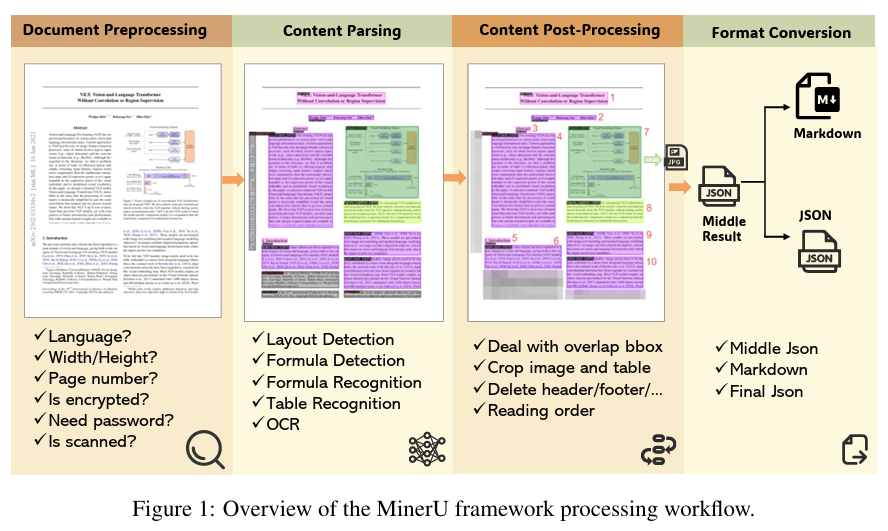
下面根据官方提供的运行示例,一步步拆解具体的流程。
import os# 导入必要的模块和类
from magic_pdf.data.data_reader_writer import FileBasedDataWriter, FileBasedDataReader
from magic_pdf.data.dataset import PymuDocDataset
from magic_pdf.model.doc_analyze_by_custom_model import doc_analyze
from magic_pdf.config.enums import SupportedPdfParseMethod# 参数设置
pdf_file_name = "file.pdf" # 要处理的PDF文件路径,使用时替换为实际路径
name_without_suff = pdf_file_name.split(".")[0] # 去除文件扩展名# 准备环境
local_image_dir, local_md_dir = "output/images", "output" # 图片和输出目录
image_dir = str(os.path.basename(local_image_dir)) # 获取图片目录名# 创建输出目录(如果不存在)
os.makedirs(local_image_dir, exist_ok=True)# 初始化数据写入器
image_writer, md_writer = FileBasedDataWriter(local_image_dir), FileBasedDataWriter(local_md_dir
)# 读取PDF文件内容
reader1 = FileBasedDataReader("") # 初始化数据读取器
pdf_bytes = reader1.read(pdf_file_name) # 读取PDF文件内容为字节流# 处理流程
## 创建PDF数据集实例
ds = PymuDocDataset(pdf_bytes) # 使用PDF字节流初始化数据集## 推理阶段
if ds.classify() == SupportedPdfParseMethod.OCR:# 如果是OCR类型的PDF(扫描件/图片型PDF)infer_result = ds.apply(doc_analyze, ocr=True) # 应用OCR模式的分析## 处理管道pipe_result = infer_result.pipe_ocr_mode(image_writer) # OCR模式的处理管道else:# 如果是文本型PDFinfer_result = ds.apply(doc_analyze, ocr=False) # 应用普通文本模式的分析## 处理管道pipe_result = infer_result.pipe_txt_mode(image_writer) # 文本模式的处理管道### 绘制模型分析结果到每页PDF
infer_result.draw_model(os.path.join(local_md_dir, f"{name_without_suff}_model.pdf"))### 获取模型推理结果
model_inference_result = infer_result.get_infer_res()### 绘制布局分析结果到每页PDF
pipe_result.draw_layout(os.path.join(local_md_dir, f"{name_without_suff}_layout.pdf"))### 绘制文本块(span)分析结果到每页PDF
pipe_result