5. 进程地址空间
目录
1. 空间布局
2. 虚拟地址
3. 地址空间
进程地址空间一共会讲3次,这是第一次,粗浅的理解框架
1. 空间布局
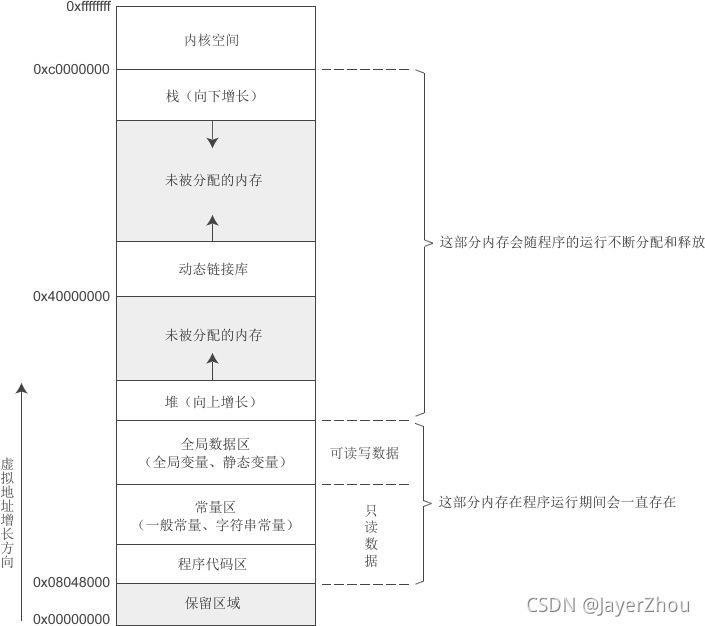
这张图上的内容大家应该很熟悉,可它究竟是什么呢?
先来验证一下各种数据的地址是否严格按它的顺序排布:
#include <stdio.h>
#include <stdlib.h>
int g_val_1;
int g_val_2 = 100;int main()
{printf("code addr: %p\n", main);const char* str = "hello linux";printf("read only string addr: %p\n", str);printf("init global value addr: %p\n", &g_val_2);printf("uninit global value addr: %p\n", &g_val_1);char* mem = (char*)malloc(100);printf("heap addr: %p\n", mem);printf("stack addr: %p\n", &str);printf("stack addr: %p\n", &mem);int a;int b;int c;printf("stack addr: %p\n", &a);printf("stack addr: %p\n", &b);printf("stack addr: %p\n", &c);int i = 0;for(; argv[i]; i++){printf("argv[%d]: %p\n", i, argv[i]);}for(i=0; env[i]; i++){printf("env[%d]: %p\n", i, env[i]);}return 0;
}
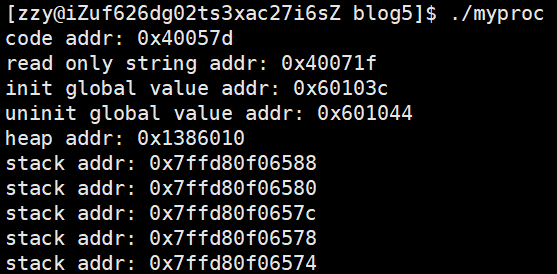
可以看到是严格符合图中地址大小的,栈区地址依次减小,所以栈向下增长,同理堆区向上增长。
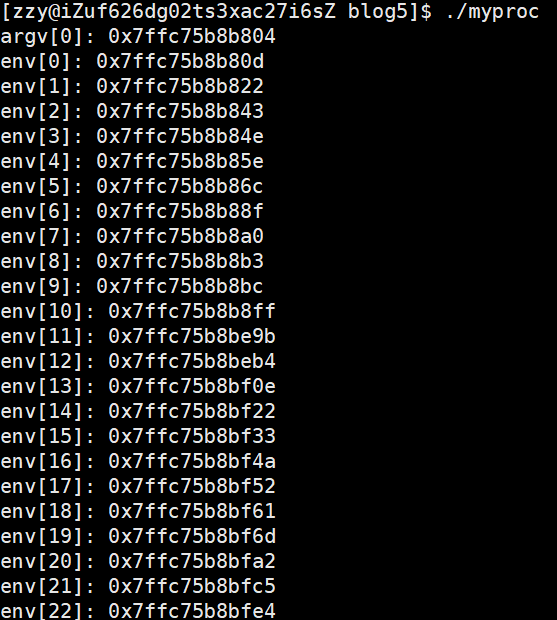
可以看出环境变量地址比命令行参数地址大,在内存布局中环境变量在命令行参数之上。
之前将之理解成内存,但是它其实不是内存,而是地址空间。那什么是地址空间呢?
2. 虚拟地址
这里我们来看一种现象:
int g_val = 100;int main()
{pid_t id = fork();if(id == 0){int cnt = 5;while(1){printf("i am child, pid:%d, ppid:%d, g_val:%d, &g_val:%p\n", getpid(), getppid(), g_val, &g_val);sleep(1);if(cnt)cnt--;else{g_val = 200;printf("子进程change g_val : 100->200\n");}}}else{while(1){printf("i am father, pid:%d, ppid:%d, g_val:%d, &g_val:%p\n", getpid(), getppid(), g_val, &g_val);sleep(1);}}return 0;
}
刚开始他们的g_val都是100,地址也相同,当子进程将g_val修改后,两个进程的g_val不同,前面我们讲过,当子进程修改和父进程共享的数据时,会发生写时拷贝,会在内存中新开一份空间放新修改的值,这都可以理解,但是他们的地址居然一样??
怎么可能同一个变量,同一个地址,不同的内容?

结论:如果变量的地址,是物理地址,不可能存在上面的现象!!所以,这个地址绝对不可能是物理地址,是线性地址/虚拟地址!
我们平时写的C/C++程序里用的指针,指针里面的地址全都不是物理地址。
创建进程时,除了PCB,还有进程地址空间,每个进程都有自己的进程地址空间。
既然进程地址空间中的地址是虚拟地址,它是怎么和物理内存中的地址交互的呢?
答:页表,虚拟地址通过页表映射到物理地址,进程无法直接访问物理内存。
子进程也有自己的PCB,和拷贝父进程来的进程地址空间和页表,既然是拷贝来的,那么他们页表中的地址一样,都指向同一个物理地址,所以子进程与父进程共享代码和数据。
子进程修改数据时,写入时发现和父进程是共享的,发生写时拷贝,物理内存中新开一块空间,子进程页表中那个虚拟地址对应的物理地址就被改成新的了,这也是为什么同一个变量id可以等于不同值,id只是同一个虚拟地址的id,但物理地址却不同,实际上是两个变量。
3. 地址空间
那地址空间究竟是什么?什么是虚拟地址呢?又为什么要搞这么一个虚拟地址呢?
在 32 位系统 中,CPU 和内存之间的 数据总线 宽度通常是 32 位,各根总线有01两种电平。所以共有2^32种01序列,地址总线组合形成地址范围[0,2^32);4GB(0x00000000 ~ 0xFFFFFFFF)。
访问内存空间的本质:CPU向内存充电,内存识别各位高低电平,组合成二进制序列地址。
地址空间上的区域划分:
struct area
{int start;int end;
}在范围内的连续空间中每一个最小单位都有地址,这个地址可以直接使用,所谓的空间区域调整就是改变start和end两个参数。
地址空间本质是内核的一个数据结构对象,类似PCB,地址空间也是要被操作系统管理的:先描述、再组织。
PCB中有一个mm指针,指向地址空间结构体:通过每个区域的start和end划分空间范围。
struct mm_struct
{long code_start;long code_end;long readonly_start;long readonly_end;long init_start;long init_end;long uninit_start;long uninit_end;long heap_start;long heap_end;long stack_start;long stack_end;
}所以,地址空间是什么?
本质是一个描述进程可视范围大小的一个数据结构,地址空间是操作系统为每个进程提供的虚拟内存的抽象,在操作系统内核中,地址空间通常由一个结构体(或类)表示,一定要有各种区域的划分,对线性地址进行start、end即可。地址空间中的地址就是虚拟地址。
为什么要有地址空间?
1. 让进程以统一的视角看待内存,开发者只需关注虚拟地址,无需适配不同机器。如果直接操作物理内存,多个进程可能覆盖彼此的数据;物理内存被不同进程分割成碎片,无法满足大块连续内存需求。
2. 最开始的物理内存是直接暴露给用户的,增加进程虚拟地址空间可以让我们访问内存时,增加一个转换的过程,在转化过程中,可以对我们的寻址请求进行审查,一旦异常访问,直接拦截,该请求不会到达物理内存,保护物理内存。
操作系统怎么找到进程对应的页表呢?页表地址存在CPU中一个寄存器上,它是一个物理地址,本质属于进程的上下文。
页表不只有虚拟地址和物理地址,还有一个标识位,代表该物理地址可读/可写,由于物理地址本身是随意读写的,所以需要这个标识位。字符常量就是只读的,进程在向一个只读的地址写入时会挂掉。
我们可以建立一个共识:现代操作系统几乎不做任何浪费空间和时间的事情。在进程被挂起时,代码数据可能被换出,当进程重新运行时,OS需要知道它的代码数据在不在内存中,如果在就直接访问物理地址,如果不在就去磁盘中找。怎么知道进程的代码数据在不在内存呢?
页表中还有一列标识位,代表对应的代码或数据是否已经被加载到内存。若位1,直接读取物理地址访问。若为0,触发缺页中断,找到代码或数据后放到内存中,置为1,页表中填好物理地址,之后才能访问。
有些程序是很大的,在程序启动时,不立即加载所有代码和数据到内存,而是等到进程实际访问某部分时再触发加载(缺页中断),这就是惰性加载。这样OS就可以对大文件实现分批加载,边使用边加载。
3. 正因为页表的存在,可以让进程管理无需关心内存管理,虚拟地址的存在在软件层面上实现了进程管理和内存管理的解耦。
所以进程切换时,不仅切换PCB,还有地址空间和页表,PCB中有指针指向地址空间。所以PCB切换了进程地址空间就切换了,页表地址存在寄存器中属于进程上下文,上下文切换了页表也就切换了。
进程在被创建时,先创建内核数据结构,再加载对应可执行程序。
我们平时写的代码中的变量在编译后都没了,其实都是地址。