DAY20-新世纪DL(DeepLearning/深度学习)战士:终(目标检测/YOLO)3
本文参考文章0.0 目录-深度学习第一课《神经网络与深度学习》-Stanford吴恩达教授-CSDN博客
1.目标定位
目标检测是计算机视觉领域中一个新兴的应用方向,在此之前,我们先看目标定位
本文我们要研究的分类定位问题,通常只有一个较大的对象位于图片中间位置,我们要对它进行识别和定位。而在对象检测问题中,图片可以含有多个对象,甚至单张图片中会有多个不同分类的对象。因此,图片分类的思路可以帮助学习分类定位,而对象定位的思路又有助于学习对象检测。
如果你想定位图片中汽车的位置,我们可以让神经网络多输出几个单元,输出一个边界框。具体说就是多输出4个数字,标记为这四个数字是被检测对象的边界框的参数。图片左上角的坐标为(0,0),右下角标记为(1,1)。指定红色方框的中心点,这个点表示为
,边界框的高度为
,宽度为
。因此训练集不仅包含神经网络要预测的对象分类标签,还要包含表示边界框的这四个数字。接着采用监督学习算法,输出一个分类标签和四个参数值。下图为四个参数值的大概预测
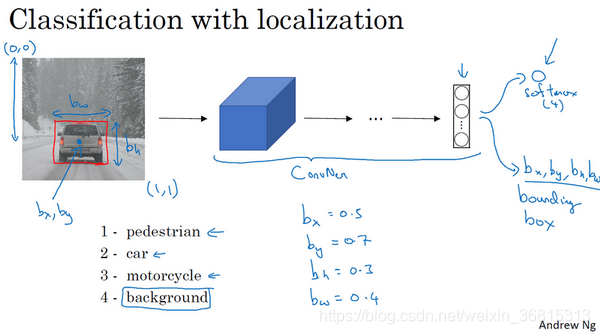
监督学习任务定义目标标签 ,这里的
表示是否含有对象,果对象属于前三类(行人、汽车、摩托车),则为1,否则为0(其它参数将变得毫无意义,这里我全部写成问号),如果为一(检测到对象),就同时输出
。最后,对于该对象,属于哪一类(行人、汽车、摩托车),来输出
,这里面只能有一个是1
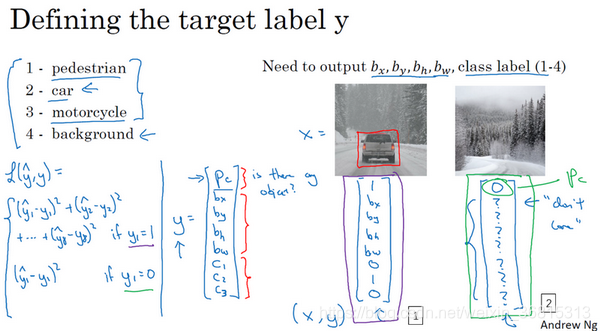
最后介绍一下神经网络的损失函数,其参数类别为和网络输出
,实际应用中是用平方差预测,则有
,损失值等于每个元素相应差值的平方和。平方误差策略可以减少这8个元素预测值和实际输出结果之间差值的平方。当
=0时,只需要考虑第一项即可
2.目标点检测
神经网络可以通过输出图片上特征点的 (x,y) 坐标来实现对目标特征的识别。

假设你正在构建一个人脸识别应用,出于某种原因,你希望算法可以给出眼角的具体位置。眼角坐标为 (x,y) ,你可以让神经网络的最后一层多输出两个数字和
,作为眼角的坐标值。如果你想知道两只眼睛的四个眼角的具体位置,那么从左到右,依次用四个特征点来表示这四个眼角。对神经网络稍做些修改,输出第一个特征点
,第二个特征点
,依此类推,这四个脸部特征点的位置就可以通过神经网络输出了。
你可以设定特征点的个数,假设脸部有64个特征点,有些点甚至可以帮助你定义脸部轮廓或下颌轮廓。选定特征点个数,并生成包含这些特征点的标签训练集,然后利用神经网络输出脸部关键特征点的位置。
具体做法是,准备一个卷积网络和一些特征集,将人脸图片输入卷积网络,输出1或0,然后输出到
,这里有129个(1+64*2)输出单元,由此实现对图片的人脸检测和定位。
一旦了解如何用二维坐标系定义人物姿态,操作起来就相当简单了,批量添加输出单元,用以输出要识别的各个特征点( x,y )的坐标值。另外,标签在所有图片中必须保持一致
3目标检测

假如你想构建一个汽车检测算法,步骤是,首先创建一个标签训练集,也就是 x 和 y 表示适当剪切的汽车图片样本,这张图片(编号1,2,3) x 是一个正样本,因为它是一辆汽车图片。出于我们对这个训练集的期望,你一开始可以使用适当剪切的图片,就是整张图片x 几乎都被汽车占据有了这个标签训练集,你就可以开始训练卷积网络了,输入这些适当剪切过的图片(编号6),卷积网络输出 y ,0或1表示图片中有汽车或没有汽车。训练完卷积网络,就可以用它实现滑动窗口目标检测,具体步骤如下。
假设这是一张测试图片,首先选定一个特定大小的窗口,比如图片下方这个窗口,将这个红色小方块输入卷积神经网络,卷积网络开始进行预测,即判断红色方框内有没有汽车。

滑动窗口目标检测算法接下来会继续处理第二个图像,即红色方框稍向右滑动之后的区域,并输入给卷积网络,因此输入给卷积网络的只有红色方框内的区域,再次运行卷积网络,然后处理第三个图像,依次重复操作,直到这个窗口滑过图像的每一个角落。思路是以固定步幅移动窗口,遍历图像的每个区域,把这些剪切后的小图像输入卷积网络,对每个位置按0或1进行分类,这就是所谓的图像滑动窗口操作。
重复上述操作,你可以换一个更大的窗口或者以某个不同的固定步幅
这种算法叫作滑动窗口目标检测,以某个步幅滑动这些方框窗口遍历整张图片,对这些方形区域进行分类,判断里面有没有汽车。
这个算法的缺点之一就是计算成本,因为你在图片中剪切出太多小方块,卷积网络要一个个地处理。如果你选用的步幅很大,显然会减少输入卷积网络的窗口个数,但是粗糙间隔尺寸可能会影响性能。反之,如果采用小粒度或小步幅,传递给卷积网络的小窗口会特别多,这意味着超高的计算成本。
4.卷积的滑动窗口实现
卷积网络实现滑动窗口对象检测算法,但效率很低
为了构建滑动窗口的卷积应用,首先要把神经网络的全连接层转化成卷积层。
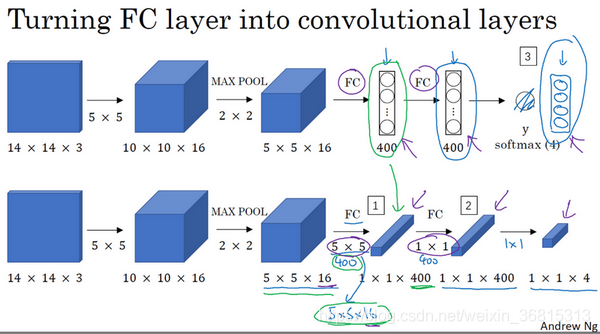
如图,昨天的文章有详细联系过,这里不再解释。其实你掌握了过滤器的性质后,卷积层代替全连接层的过程挺简单的
再来看看如何通过卷积实现滑动窗口对象检测算法
假设输入给卷积网络的图片大小是14×14×3,测试集图片是16×16×3,现在给这个输入图片加上黄色条块,在最初的滑动窗口算法中,你会把这片蓝色区域输入卷积网络(红色笔标记)生成0或1分类。接着滑动窗口,步幅为2个像素,向右滑动2个像素,将这个绿框区域输入给卷积网络,运行整个卷积网络,得到另外一个标签0或1。继续将这个橘色区域输入给卷积网络,卷积后得到另一个标签,最后对右下方的紫色区域进行最后一次卷积操作。我们在这个16×16×3的小图像上滑动窗口,卷积网络运行了4次,于是输出了4个标签。和卷积相乘的知识类似
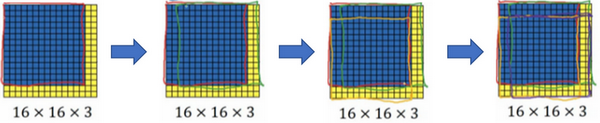
结果发现,这4次卷积操作中很多计算都是重复的。所以执行滑动窗口的卷积时使得卷积网络在这4次前向传播过程中共享很多计算,卷积网络运行同样的参数,使得相同的5×5×16过滤器进行卷积操作,得到12×12×16的输出层。然后执行同样的最大池化,输出结果6×6×16。照旧应用400个5×5的过滤器,得到一个2×2×400的输出层,现在输出层为2×2×400,而不是1×1×400。应用1×1过滤器,得到另一个2×2×400的输出层。再做一次全连接的操作,最终得到2×2×4的输出层,而不是1×1×4。最终,在输出层这4个子方块中,你可以看见各个颜色箭头标识的方块来源
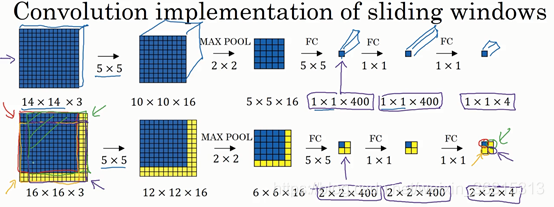
所以该卷积操作的原理是我们不需要把输入图像分割成四个子集,分别执行前向传播,而是把它们作为一张图片输入给卷积网络进行计算,其中的公共区域可以共享很多计算。
下面我们再看一个更大的图片样本,假如对一个28×28×3的图片应用滑动窗口操作,如果以同样的方式运行前向传播,最后得到8×8×4的结果。跟上一个范例一样,以14×14区域滑动窗口,首先在这个区域应用滑动窗口,其结果对应输出层的左上角部分。接着以大小为2的步幅不断地向右移动窗口,直到第8个单元格,得到输出层的第一行。然后向图片下方移动,最终输出这个8×8×4的结果。因为最大池化参数为2,相当于以大小为2的步幅在原始图片上应用神经网络。

总结一下滑动窗口的实现过程,在图片上剪切出一块区域,把它输入到卷积网络。继续输入下一块区域,重复操作,直到某个区域识别到汽车
5.Bouding Box预测
滑动窗口法算法效率虽然高,但是不能输出最精准的边界框

其中一个能得到更精准边界框的算法是YOLO算法,YOLO(You only look once)意思是你只看一次。
是这么做的,比如你的输入图像是100×100的,然后在图像上放一个网格。为了介绍起来简单一些,我用3×3网格,实际实现时会用更精细的网格,可能是19×19。基本思路是使用图像分类和定位算法,然后将算法应用到9个格子上。更具体一点,你需要这样定义训练标签,所以对于9个格子中的每一个指定一个标签 y ,y 是8维的,和你之前看到的一样,
表示是否含有对象,就同时输出
(边界框坐标)。最后,对于该对象,俗语哪一类,来输出
这张图里有9个格子,所以对于每个格子都有这么一个向量。

左上方的格子就是,(这里用*来代替问号)。同理编号2的格子与其他什么都没有的格子输出标签y都是这样的
现在这个格子呢?讲的更具体一点,这张图有两个对象,YOLO算法做的就是,取两个对象的中点,然后将这个对象分配给包含对象中点的格子。所以左边的汽车就分配到这个格子上(编号4),然后另一辆中点在这里,分配给这个格子(编号6)。所以即使中心格子(编号5)同时有两辆车的一部分,我们就假装中心格子没有任何我们感兴趣的对象,所以对于中心格子,分类标签 y 和这个向量类似,和这个没有对象的向量类似,即,然后对于编号4,6
=1,其他参数就可以填写了
所以对于这里9个格子中任何一个,你都会得到一个8维输出向量,因为这里是3×3的网格,所以有9个格子,总的输出尺寸是3×3×8,所以目标输出是3×3×8。
所以你要做的是,有一个输入 x ,就是这样的输入图像,然后你有这些3×3×8的目标标签 y 。当你用反向传播训练神经网络时,将任意输入 x 映射到这类输出向量 y
所以这个算法的优点在于神经网络可以输出精确的边界框,所以测试的时候,你做的是喂入输入图像 x ,然后跑正向传播,直到你得到这个输出 y 。只要每个格子中对象数目没有超过1个,这个算法应该是没问题的。但实践中,我们这里用的是比较小的3×3网格,实践中你可能会使用更精细的19×19网格,所以输出就是19×19×8。这样的网格精细得多,那么多个对象分配到同一个格子得概率就小得多。
这是单次卷积实现,但你使用了一个卷积网络,有很多共享计算步骤,在处理这3×3计算中很多计算步骤是共享的,或者你的19×19的网格,所以YOLO效率很高,运行速率非常快。
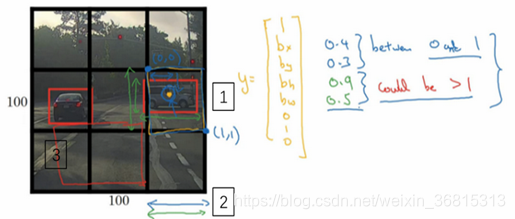
单位是相对于格子尺寸的比例。
必须在0和1之间,因为从定义上看,橙色点位于对象分配到格子的范围内,如果它不在0和1之间,如果它在方块外,那么这个对象就应该分配到另一个格子上
可能会大于1,特别是如果有一辆汽车的边界框是这样的(编号3所示),那么边界框的宽度和高度有可能大于1。
6.交并比
如何判断对象检测算法运作良好呢,这里介绍并交比函数,可以用来评价对象检测算法。

在对象检测任务中,你希望能够同时定位对象,所以如果实际边界框是这样的,你的算法给出这个紫色的边界框,那么这个结果是好还是坏?所以交并比(loU)函数做的是计算两个边界框交集和并集之比(即交集的大小/并集大小)。那么交并比就是交集的大小,这个橙色阴影面积,然后除以绿色阴影的并集面积。
一般约定,在计算机检测任务中,如果loU≥0.5 ,就说检测正确,如果预测器和实际边界框完美重叠,loU就是1,但一般来说只要IoU≥0.5 ,那么结果是可以接受的,如果你希望更严格一点,你可以将loU定得更高,比如说大于0.6或者更大的数字,但loU越高,边界框越精确。
7.非极大值抑制
到目前为止你们学到的对象检测中的一个问题是算法可能对同一个对象做出多次检测,非极大值抑制这个方法可以确保你的算法对每个对象只检测一次

假设你需要在这张图片里检测行人和汽车,你可能会在上面放个19×19网格,理论上这辆车只有一个中点,所以它应该只被分配到一个格子里,左边的车子也只有一个中点,所以理论上应该只有一个格子做出有车的预测。而事实上,编号1,2,3,4,5,6格子都认为自己格子内有车。
非极大值抑制做的就是清理这些检测结果。这样一辆车只检测一次,而不是每辆车都触发多次检测。
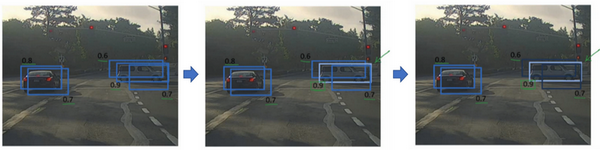
具体上,这个算法做的是首先看看每次报告每个检测结果相关的概率,现在我们说这个
检测概率,首先看概率最大的那个,这个例子(右边车辆)中是0.9,然后就说这是最可靠的检测,所以我们就用高亮标记,就说我这里找到了一辆车。这么做之后,非极大值抑制就会逐一审视剩下的矩形,所有和这个最大的边框有很高交并比,高度重叠的其他边界框,那么这些输出就会被抑制(变暗)。所以这两个矩形分别是0.6和0.7,这两个矩形
和淡蓝色矩形重叠程度很高,所以会被抑制,变暗,表示它们被抑制了。
现在来看算法细节,这里假设只检测一种对象(即没有c1c2c3之分)首先这个19×19网格上执行一下算法,你会得到19×19×8的输出尺寸。

现在要实现非极大值抑制,你可以做的第一件事是,去掉所有边界框,我们就将所有的预测值,所有的边界框 小于或等于某个阈值,比如
≤0.6 的边界框去掉。
接下来剩下的边界框,你就一直选择概率 最高的边界框,然后把它输出成预测结果
接下来去掉所有剩下的边界框,任何没有达到输出标准的边界框,之前没有抛弃的边界框,把这些和输出边界框有高重叠面积和上一步输出边界框有很高交并比的边界框全部抛弃。所以while循环的第二步是上张图片变暗的那些边界框,和高亮标记的边界重叠面积很高的那些边界框抛弃掉。在还有剩下边界框的时候,一直这么做,把没处理的都处理完,直到每个边界框都判断过了,它们有的作为输出结果,剩下的会被抛弃,它们和输出结果重叠面积太高,和输出结果交并比太高,和你刚刚输出这里存在对象结果的重叠程度过高。
所以这就是非极大值抑制,非最大值意味着你只输出概率最大的分类结果,但抑制很接近,但不是最大的其他预测结果,所以这方法叫做非极大值抑制。
8.Anchor Boxes
到目前为止,对象检测中存在的一个问题是每个格子只能检测出一个对象,如果你想让一个格子检测出多个对象,可以使用anchor box,实践中这种情况很少发生,特别是如果你用的是19×19网格而不是3×3的网格,两个对象中点处于361个格子中同一个格子的概率很低,确实会出现,但出现频率不高。
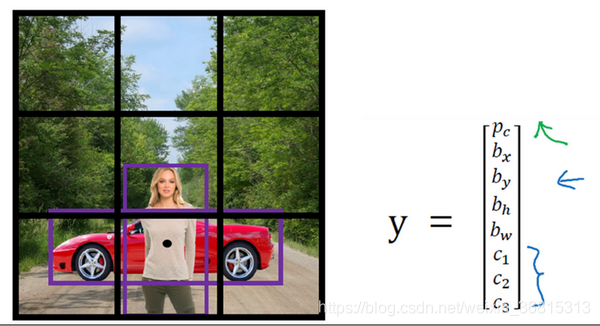
假设你有这样一张图片,对于这个例子,我们继续使用3×3网格,注意行人的中点和汽车的中点几乎在同一个地方,两者都落入到同一个格子中。如果输出这个向量你可以检测这两个类别,它将无法输出检测结果。
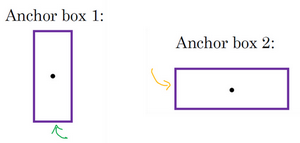
anchor box的思路是预先定义两个不同形状的anchor box(形状),然后把预测结果和这两个anchor box关联起来(我个人理解就是多对象输出整合多个单对象输出)。一般你可能会用更多的anchor box(≥5),但对于本例,我们就用两个anchor box,这样来简单一些。
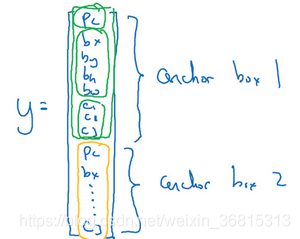
此时你定义的y就是上图的样子(整合了原本的两个向量)
对于第一个box更像人,所以
对于第二个,
现在每个对象都和之前一样分配到同一个格子中,分配到对象中点所在的格子中,以及分配到和对象形状交并比最高的anchor box中,然后你观察哪一个anchor box和实际边界框的交并比更高,不管选的是哪一个,这个对象不只分配到一个格子,而是分配到一对,所以现在输出 y 就是3×3×16,如果此时人走了,那么第一个就要改为。
其他情况:如果你有两个anchor box,但在同一个格子中有三个对象;两个对象都分配到一个格子中,而且它们的anchor box形状也一样。需要引入一些打破僵局的默认手段
最后,怎么选择anchor box,人们一般手工指定anchor box形状,你可以选择5到10个anchor box形状,覆盖到多种不同的形状,可以涵盖你想要检测的对象的各种形状。还有一个更高级的版本,简单说一句,你们如果接触过一些机器学习,可能知道后期YOLO论文中有更好的做法,就是所谓的k-平均算法,可以将两类对象形状聚类,如果我们用它来选择一组anchor box,选择最具有代表性的一组anchor box,可以代表你试图检测的十几个对象类别,但这其实是自动选择anchor box的高级方法。如果你就人工选择一些形状,合理的考虑到所有对象的形状,你预计会检测的很高很瘦或者很宽很胖的对象,这应该也不难做。
9.YOLO算法
你们已经学到对象检测算法的大部分组件了,本节把所有组件组装在一起构成YOLO对象检测算法
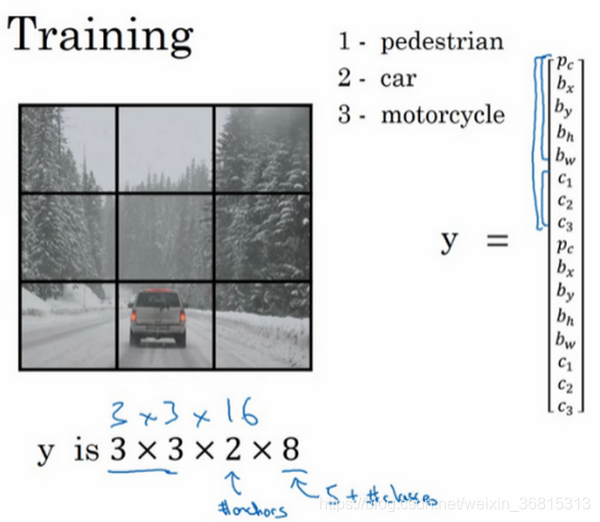
还是之前的例子。这里有3个类别标签,如果你要用两个anchor box,那么输出 y 就是3×3×2×8,其中3×3表示3×3个网格,2是anchor box的数量,8是向量维度(1+4+3),要构造训练集,你需要遍历9个格子,然后构成对应的目标向量 y
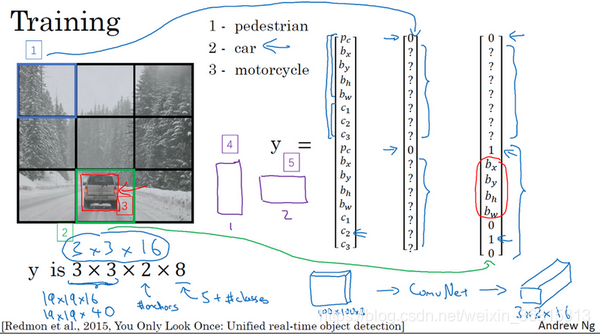
易知编号1的格子目标 ,现在网格中大多数格子都是空的,但那里的格子(编号2)会有这个目标向量
,
所以假设你的训练集中,对于车子有这样一个边界框(编号3),水平方向更长一点。所以如果这是你的anchor box,这是anchor box 1(编号4),这是anchor box 2(编号5),然后红框和anchor box 2的交并比更高,那么车子(anchor box 2)就和向量的下半部分相关。这里和anchor box 1有关的 是0,剩下这些分量不用管,而anchor box 2的
是1,然后四个参数值+正确类别(010)。
接下来看看算法是怎样做出预测的,输入图像,你的神经网络的输出尺寸是这个3×3×2×8,对于左上的格子(编号1),那里没有任何对象,那么你的神经网络在那里(第一个 )输出的是0,这里(第二个
)是0,然后输出一些值,你的神经网络不能输出问号,剩下的我输入一些数字,但这些数字基本上会被忽略。编号2格子同理,不再赘述,这就是神经网络做出预测的过程
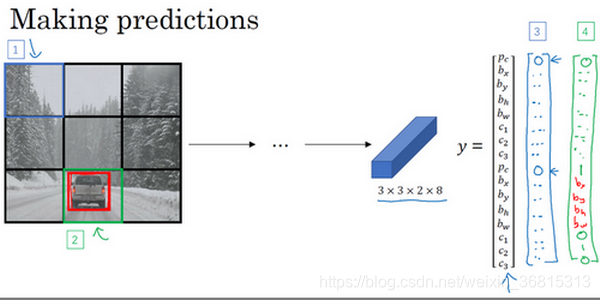
最后你要运行一下这个非极大值抑制,我们看看一张新的测试图像,这就是运行非极大值抑制的过程。如果你使用两个anchor box,那么对于9个格子中任何一个都会有两个预测的边界框,其中一个的概率 很低。但9个格子中,每个都有两个预测的边界框,比如说我们得到的边界框是是这样的,注意有一些边界框可以超出所在格子的高度和宽度(编号1所示)。接下来你抛弃概率很低的预测(编号2所示)。
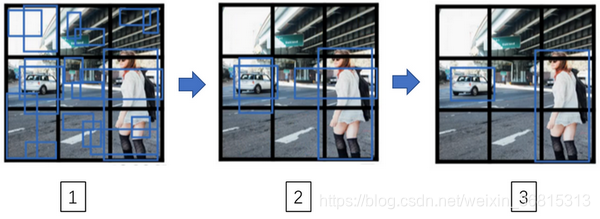
最后,如果你有三个对象检测类别(行人,汽车和摩托车),那么你要做的是,对于每个类别单独运行非极大值抑制,处理预测结果所属类别的边界框,运行三次来得到最终的预测结果。所以算法的输出最好能够检测出图像里所有的车子,还有所有的行人(编号3所示)。
10.候选区域(可看)
候选区域是计算机视觉领域是非常有影响力的概念。

你可以运行一下卷积算法,这个算法的其中一个缺点是,它在显然没有任何对象的区域浪费时间
R-CNN的算法,意思是带区域的卷积网络,或者说带区域的CNN。这个算法尝试选出一些区域,在这些区域上运行卷积网络分类器是有意义的,所以这里不再针对每个滑动窗运行检测算法,而是只选择一些窗口,在少数窗口上运行卷积网络分类器。
选出候选区域的方法是运行图像分割算法,分割的结果是下边的图像,为了找出可能存在对象的区域。比如说,分割算法在这里得到一个色块,所以你可能会选择这样的边界框(编号1),然后在这个色块上运行分类器,就像这个绿色的东西(编号2),在这里找到一个色块,接下来我们还会在那个矩形上(编号2)运行一次分类器,看看有没有东西。在这种情况下,如果在蓝色色块上(编号3)运行分类器,希望你能检测出一个行人,如果你在青色色块(编号4)上运行算法,也许你可以发现一辆车,我也不确定。
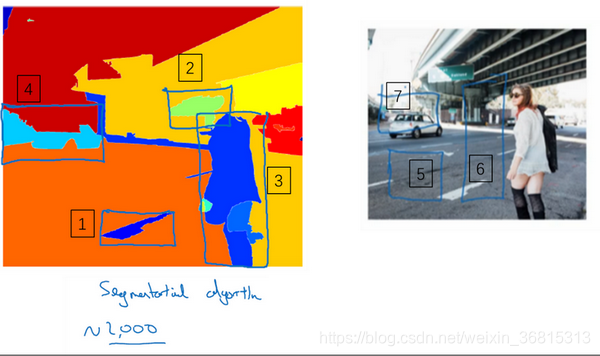
所以这个细节就是分割算法,你先找出可能2000多个色块,然后在这2000个色块上放置边界框,然后在这2000个色块上运行分类器,这样需要处理的位置可能要少的多,可以减少卷积网络分类器运行时间。特别是这种情况,现在不仅是在方形区域(编号5)中运行卷积网络,我们还会在高高瘦瘦(编号6)的区域运行,尝试检测出行人,然后我们在很宽很胖的区域(编号7)运行,尝试检测出车辆,同时在各种尺度运行分类器。
R-CNN算法是使用某种算法求出候选区域,然后对每个候选区域运行一下分类器,每个区域会输出一个标签,R-CNN算法不会直接信任输入的边界框,它也会输出一个边界框
再往深的相关知识点本文就不讲了,感兴趣可以自行搜索
11.总结与习题
3.11 总结-深度学习第四课《卷积神经网络》-Stanford吴恩达教授_如果你想要构建一个能够输入人脸图片,输出为n个标记的神经网络(假设图像只包含一-CSDN博客