AI 在金融、医疗、教育、制造业等领域有着广泛的应用,以下是这些领域的一些落地案例
金融领域
- 美国银行智能客服与风控体系
- 案例介绍:美国银行推出了虚拟助手 Erica,运用语音识别和自然语言处理技术,能为客户提供 24 小时服务,可解答账户查询、贷款政策咨询等问题。同时,美国银行构建了先进的风险评估模型,可整合多维度信息对信用风险等精准评估,在欺诈检测方面引入机器学习 AI 系统。
- 技术实现:虚拟助手 Erica 主要依靠语音识别和自然语言处理技术来理解客户的问题并提供相应的回答。风险评估模型则通过机器学习算法,整合客户的各种数据,如交易记录、信用历史等,来精准评估信用风险和检测欺诈行为。
- 效果:Erica 自上线后已累计产生 25 亿次客户互动,活跃用户达 2000 万,人工客服数量也减少了约 20%。其异常交易识别效率相较传统模式提升 300 倍。
- 某股份制银行的 JBoltAI 智能风控系统
- 案例介绍:某股份制银行部署了 JBoltAI 系统用于智能风控,该系统可同步解析文本、图像等金融数据,自动提取合同等文件的关键特征。
- 技术实现:采用先进的机器学习和深度学习算法,对金融数据进行多维度分析和特征提取,从而实现对风险的准确识别和评估。
- 效果:银行审批效率提升了 47%,风险识别准确率达到 98.6%,年度风险损失减少 1.2 亿元。
- 基于 LoRA 的 Qwen-7B 模型微调用于信贷风控
- 案例介绍:针对城商行审批场景,通过 LoRA 轻量化微调 Qwen-7B 模型,以更好地结合本地小微企业经营数据和区域经济特征进行信贷审批。
- 代码实现:
python
# 安装大模型训练、金融数据处理依赖库
# 金融数据集加载与预处理(城商行信贷数据)
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from datasets import Dataset# 1. 加载城商行信贷数据集(含企业基本信息、财务数据、风险标签)
# 数据字段示例:企业名称、纳税额(万元)、水电费(万元)、经营年限(年)、是否违约(0=正常,1=违约)、区域经济指数
df = pd.read_csv("city_bank_credit_data.csv")
# 2. 数据清洗:处理缺失值(金融数据常用均值填充数值型,众数填充类别型)
df["纳税额(万元)"] = df["纳税额(万元)"].fillna(df["纳税额(万元)"].mean())
df["水电费(万元)"] = df["水电费(万元)"].fillna(df["水电费(万元)"].mean())
df["区域经济指数"] = df["区域经济指数"].fillna(df["区域经济指数"].median())
df["经营年限(年)"] = df["经营年限(年)"].fillna(df["经营年限(年)"].mode()[0])
# 3. 特征编码:将类别型特征转为模型可识别格式
le = LabelEncoder()
df["区域"] = le.fit_transform(df["区域"]) # 如:0=华东,1=华南...
# 4. 构建模型输入格式(大模型需文本化输入,将结构化数据转为自然语言描述)
def format_credit_input(row):return f"""企业信贷审批评估:
企业名称:{row["企业名称"]}
纳税额:{row["纳税额(万元)"]}万元,水电费:{row["水电费(万元)"]}万元
经营年限:{row["经营年限(年)"]}年,区域:{le.inverse_transform([row["区域"]])[0]}
区域经济指数:{row["区域经济指数"]}
请判断该企业是否存在信贷违约风险(输出0=正常,1=违约):"""
df["input_text"] = df.apply(format_credit_input, axis=1)
df["label"] = df["是否违约"]
# 5. 划分训练集/测试集(金融场景常用8:2划分,保证数据分布一致)
train_df, test_df = train_test_split(df[["input_text", "label"]], test_size=0.2, random_state=42, stratify=df["label"])
# 6. 转为HuggingFace Dataset格式(适配大模型训练流水线)
train_dataset = Dataset.from_pandas(train_df)
test_dataset = Dataset.from_pandas(test_df)# LoRA微调Qwen-7B模型
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, Trainer
from peft import LoraConfig, get_peft_model, TaskType
import torch# 1. 加载预训练模型与Tokenizer(Qwen-7B为阿里通义千问开源模型,适配中文金融场景)
model_name = "qwen/Qwen-7B"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token # 补充pad_token(Qwen默认无pad_token)
# 加载模型,使用4-bit量化降低显存占用(单A10显卡可运行)
model = AutoModelForCausalLM.from_pretrained(model_name,trust_remote_code=True,torch_dtype=torch.float16,load_in_4bit=True,device_map="auto" # 自动分配设备(GPU优先)
)
# 2. 配置LoRA参数(轻量化微调核心,仅训练部分参数)
lora_config = LoraConfig(task_type=TaskType.CAUSAL_LM, # 因果语言模型任务(适用于生成式判断)r=8, # LoRA秩(控制参数更新幅度,金融场景8-16较优)lora_alpha=32, # 缩放因子,r*lora_alpha越大,微调影响越强target_modules=("c_attn"), # Qwen模型注意力层参数(重点优化语义理解)lora_dropout=0.05,bias="none",modules_to_save=("lm_head") # 保存输出层,适配分类任务
)
# 3. 注入LoRA适配器到模型
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 查看可训练参数比例(仅0.1%-0.5%,大幅降低成本)
# 4. 数据编码函数(将文本转为模型输入的token)
def encode_function(examples):return tokenizer(examples["input_text"], padding=True, truncation=True)
train_dataset = train_dataset.map(encode_function, batched=True)
test_dataset = test_dataset.map(encode_function, batched=True)
# 5. 训练参数配置
training_args = TrainingArguments(output_dir="./lora_qwen_credit",num_train_epochs=3,per_device_train_batch_size=4,per_device_eval_batch_size=4,warmup_steps=500,weight_decay=0.01,logging_dir="./logs",logging_steps=10
)
# 6. 初始化Trainer并开始训练
trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=test_dataset
)
trainer.train()
- 效果:审批准确率提升 15%,推理速度提升 2 倍。
医疗领域
- AlphaFold 3 用于药物研发
- 案例介绍:2025 年发布的 AlphaFold 3,首次实现蛋白质与 DNA、RNA、小分子复合物的联合预测,准确率较传统方法提升 50% 以上。例如在预测感冒病毒刺突蛋白与抗体的结合结构时,与真实结构匹配度超过 95%,为疫苗设计提供关键依据。
- 技术实现:AlphaFold 3 采用了先进的深度学习架构和算法,对蛋白质的结构进行预测。它通过对大量蛋白质结构数据的学习和分析,能够准确地预测蛋白质与其他分子的结合结构。
- 效果:为药物研发提供了更准确的结构信息,加速了药物研发的进程,提高了研发的成功率。
- DeepSeek - Med 用于诊疗决策支持
- 案例介绍:DeepSeek - Med 能够同步解析 CT 影像、基因检测、电子病历等多模态数据,进行早期肺癌诊断,其误诊率低于人类专家 3%。
- 技术实现:利用多模态深度学习技术,将 CT 影像、基因检测数据和电子病历等信息进行整合和分析,通过建立复杂的模型来实现对疾病的准确诊断。
- 效果:为医生提供了更准确的诊断依据,有助于提高肺癌的早期诊断率,从而改善患者的治疗效果和预后。
- Fairtility 利用 AI 提高 IVF 效果
- 案例介绍:Fairtility 通过利用 Google Cloud 中的 AI 和机器学习,分析胚胎图像和相关数据,以识别最有可能成功植入的胚胎,从而提高接受 IVF 的患者的怀孕可能性。
- 技术实现:使用 AI 和机器学习算法对胚胎图像和相关数据进行分析和处理,通过建立模型来预测胚胎的发育潜力和植入成功率。
- 效果:提高了接受 IVF 的患者的怀孕可能性,为不孕不育患者带来了更多的希望。
教育领域
- 科大讯飞智慧课堂
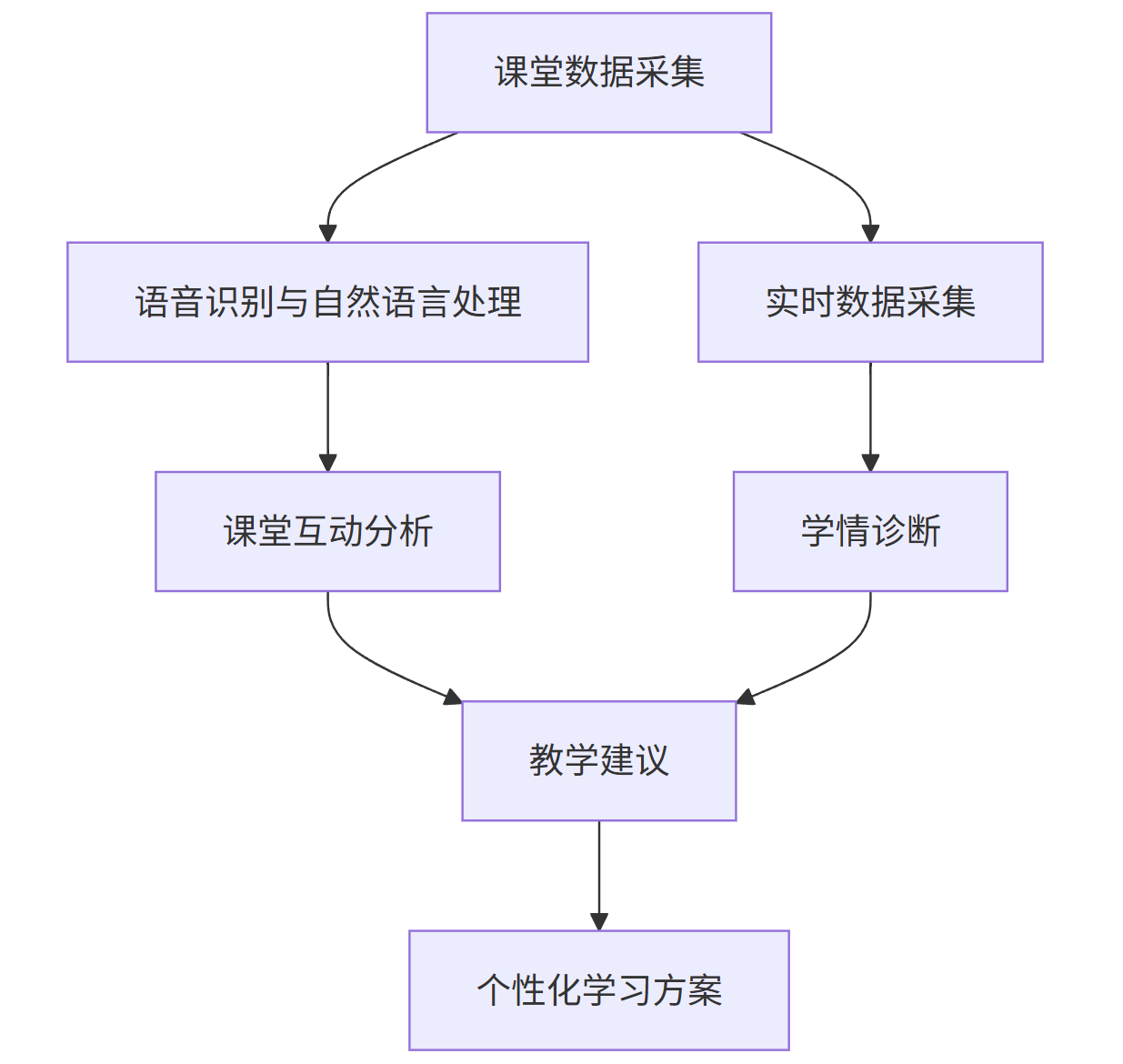
- 案例介绍:科大讯飞智慧课堂结合语音识别、自然语言处理和实时数据采集,实现课堂互动分析和学情诊断。该课堂覆盖全国 5 万余所学校,教师备课效率提升 40%,学生课后作业完成时间减少 30%。
- 技术实现:通过在课堂中安装传感器和使用智能设备,实时采集学生的课堂表现数据,如发言次数、答题情况等。利用语音识别和自然语言处理技术对学生的发言进行分析,了解学生的学习情况和问题。同时,通过建立知识图谱和个性化推荐模型,为教师提供精准的教学建议和为学生提供个性化的学习方案。
- 流程图:
graph TD;A[课堂数据采集] --> B[语音识别与自然语言处理];B --> C[课堂互动分析];A --> D[实时数据采集];D --> E[学情诊断];C --> F[教学建议];E --> F;F --> G[个性化学习方案];
- 基于协同过滤算法的个性化学习推荐
- 案例介绍:基于协同过滤算法(如 SVD)构建个性化推荐模型,结合知识图谱实现知识点关联分析,可使个性化推荐准确率提升 35%,学生平均学习效率提高 20%。
- 代码实现:
python
import numpy as np
from sklearn.decomposition import TruncatedSVD# 假设user_item_matrix是用户-物品评分矩阵,形状为(n_users, n_items)
user_item_matrix = np.array([[5, 3, 0, 1],[4, 0, 0, 1],[1, 1, 0, 5],[1, 0, 0, 4],[0, 1, 5, 4]
])# 使用TruncatedSVD进行降维,分解用户-物品矩阵
n_components = 2 # 降维后的维度
svd = TruncatedSVD(n_components=n_components, random_state=42)
user_features = svd.fit_transform(user_item_matrix)
item_features = svd.components_# 计算用户之间的余弦相似度
from sklearn.metrics.pairwise import cosine_similarity
user_similarity = cosine_similarity(user_features)# 为用户推荐物品
def recommend_items(user_id, user_similarity, user_item_matrix, top_n=5):# 找到与目标用户最相似的用户similar_users = np.argsort(user_similarity[user_id])[::-1][1:top_n + 1]recommended_items = []for similar_user in similar_users:# 找到相似用户评分高但目标用户未评分的物品for item_id in range(len(user_item_matrix[similar_user])):if user_item_matrix[user_id][item_id] == 0 and user_item_matrix[similar_user][item_id] > 0:recommended_items.append((item_id, user_item_matrix[similar_user][item_id]))# 按评分从高到低排序推荐物品recommended_items.sort(key=lambda x: x[1], reverse=True)return [item[0] for item in recommended_items]# 为用户0推荐物品
recommended_items = recommend_items(0, user_similarity, user_item_matrix)
print("为用户0推荐的物品:", recommended_items)
- Prompt 示例:“根据学生 A 的学习成绩和学习习惯,为其推荐适合的数学练习题。”
制造业
- 西门子预测性维护系统
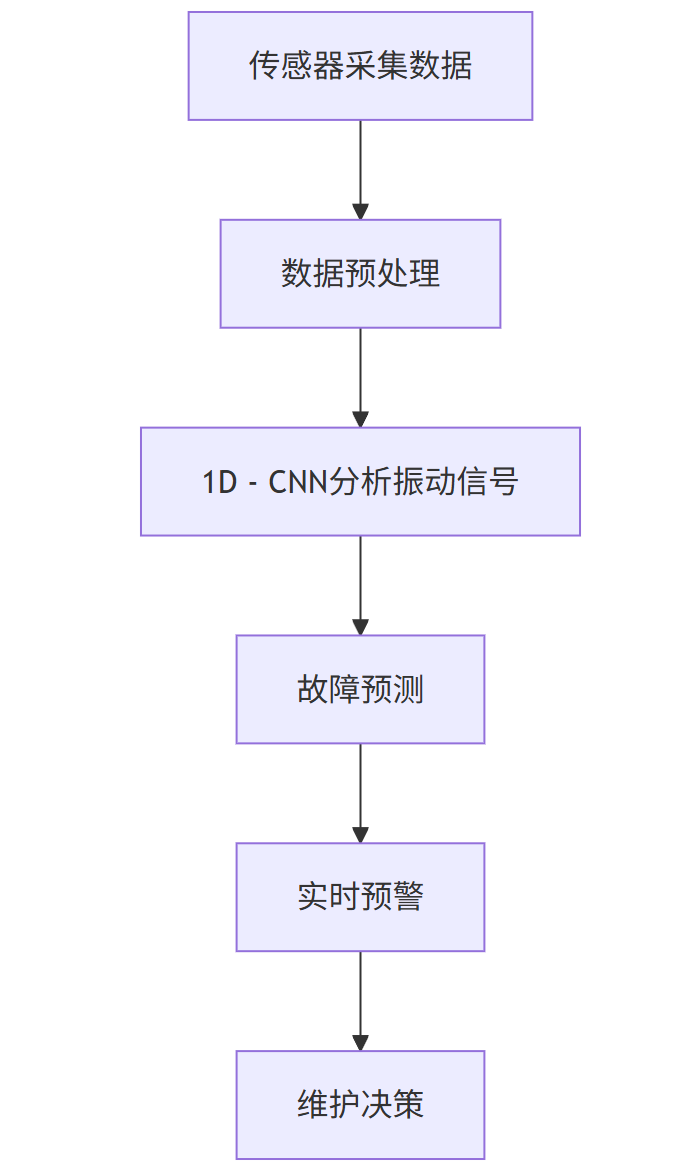
- 案例介绍:西门子预测性维护系统采用 1D - CNN(一维卷积神经网络)分析振动信号,结合 IoT 边缘计算实现实时预警。北京奔驰冲压车间部署的系统,通过 70 + 传感器实时采集数据,成功预测电机异常振动,避免非计划停机,设备停机时间减少 60%,维护成本降低 30%。
- 技术实现:通过在设备上安装传感器,实时采集设备的振动信号等数据。利用 1D - CNN 对采集到的数据进行分析,提取数据中的特征和模式,从而预测设备的运行状态和可能出现的故障。同时,结合 IoT 边缘计算技术,在设备本地对数据进行初步处理和分析,实现实时预警。
- 流程图:
graph TD;A[传感器采集数据] --> B[数据预处理];B --> C[1D - CNN分析振动信号];C --> D[故障预测];D --> E[实时预警];E --> F[维护决策];
- 海尔智能生产线
- 案例介绍:海尔智能生产线结合数字孪生、大模型优化工艺参数,实现全流程无人化生产。其中,发泡工艺优化通过热成像和鲁棒性数据融合算法,发泡质量提升 32%;机器人自适应编程利用多模态大模型 10 秒内生成轨迹代码,调试周期缩短 83%。
- 技术实现:利用数字孪生技术,为生产线建立虚拟模型,通过对虚拟模型的模拟和优化,来指导实际生产。采用大模型对工艺参数进行优化,通过对大量生产数据的学习和分析,找到最优的工艺参数组合。同时,利用热成像和鲁棒性数据融合算法对发泡工艺进行优化,提高发泡质量。对于机器人自适应编程,通过多模态大模型对机器人的任务和环境进行理解和分析,快速生成轨迹代码。
- 效果:实现了全流程无人化生产,提高了生产效率和产品质量,降低了生产成本和人工干预的风险。
以上只是 AI 在各领域应用的一部分案例,随着技术的不断发展和创新,AI 在金融、医疗、教育、制造业等领域的应用将会越来越广泛和深入,为各行业带来更多的变革和发展机遇。