Kafka 架构详解
我们将从核心设计思想、基础组件、到高级特性和工作原理进行层层深入的解析。
一、Kafka 的核心设计思想与定位
在深入架构之前,首先要理解 Kafka 的几个核心设计目标:
高吞吐量:能够处理海量数据流,即使是非常普通的硬件也能支持每秒数十万甚至百万级的消息处理。
可扩展性:通过水平扩展(增加节点)来轻松应对数据增长,扩展过程对客户端透明。
持久性与可靠性:消息被持久化到磁盘,并且支持数据备份(副本),防止数据丢失。
低延迟:保证消息从生产到消费的延迟非常低(通常在毫秒级别)。
Kafka 本质上是一个 分布式、分区化、多副本的提交日志服务。它不仅仅是一个消息队列,更是一个分布式流式处理平台。
二、Kafka 核心架构组件
1. 物理架构(Broker 集群)
Broker: 一个独立的 Kafka 服务器节点就是一个 Broker。它负责接收生产者的消息、分配偏移量、将消息持久化到磁盘,并为消费者提供服务。
Cluster: 由多个 Broker 组成的集合称为集群。一个集群由多个 Broker 组成,从而实现高可用和负载均衡。
ZooKeeper: Kafka 的“大脑”。它负责管理和协调整个集群。
元数据存储: 存储了集群的元信息,如有哪些 Topic、每个 Topic 有哪些 Partition、每个 Partition 的 Leader 是谁、Broker 列表等。
领导者选举: 当某个 Partition 的 Leader Broker 宕机时,ZooKeeper 会协助从 Follower 中选举出新的 Leader,实现故障转移。
服务发现: 帮助生产者和消费者发现当前的 Broker 和 Partition 领导者信息。
注意: 在最新版本中(Kafka 2.8.0+),Kafka 正在逐步移除对 ZooKeeper 的依赖,通过 KRaft 协议实现自管理(内部仲裁),但目前绝大多数生产环境仍依赖 ZooKeeper。
2. 逻辑架构(数据模型)
Topic: 消息的主题或类别,是逻辑上的概念,用于对消息进行分类。生产者和消费者都是面向 Topic 进行操作的。
Partition: 分区是 Kafka 实现高吞吐和水平扩展的核心机制。
一个 Topic 可以被分成多个 Partition,每个 Partition 是一个有序的、不可变的消息序列。
消息在被追加到 Partition 时,会分配一个唯一的、递增的序列号,称为 Offset。它在该 Partition 内唯一标识一条消息。
Partition 的数据在物理上表现为一个文件夹(存储在
log.dirs配置的路径下),里面有多个日志段文件。优点:
并行处理: 不同 Partition 可以放在不同的 Broker 上,从而允许生产和消费操作在多个 Broker 上并行进行,极大地提升了吞吐量。
水平扩展: 可以通过增加 Partition 数量来提升 Topic 的容量和吞吐性能。
Replica: 副本是 Kafka 实现高可用的核心机制。
每个 Partition 可以有多个副本,这些副本分散在不同的 Broker 上,以防止单点故障。
副本分为两类:
Leader Replica: 每个 Partition 都有一个 Leader。所有对该 Partition 的读写请求都由 Leader 处理。
Follower Replica: Follower 会异步地从 Leader 拉取数据,保持与 Leader 的数据同步。如果 Leader 发生故障,其中一个 Follower(必须是 In-Sync Replica, ISR)会被选举为新的 Leader。
Producer: 消息生产者,向 Kafka 的 Topic 发送消息的客户端。
生产者可以将消息发送到指定 Topic 的指定 Partition(通过指定 Key 或使用轮询等分区策略)。
生产者可以配置不同的确认机制(acks)来权衡吞吐量和数据可靠性。
Consumer: 消息消费者,从 Topic 读取消息的客户端。
消费者通过维护其消费的 Offset 来记录当前读取的位置。
消费者通常以消费者组的形式工作。
Consumer Group: 消费者组是 Kafka 实现“发布-订阅”和“点对点”两种模式的核心。
组内每个消费者负责消费一个或多个 Partition 的消息。
一个 Partition 只能被同一个消费者组内的一个消费者消费,但可以被多个不同消费者组的消费者消费。
两种模式:
队列模式: 让所有消费者在同一个消费者组里。这样每条消息只会被组内的一个消费者处理,实现负载均衡。
发布-订阅模式: 让每个消费者属于不同的消费者组。这样每条消息会被广播到所有消费者组。
三、核心架构图与数据流
下图清晰地展示了 Kafka 各组件之间的关系和数据流向:
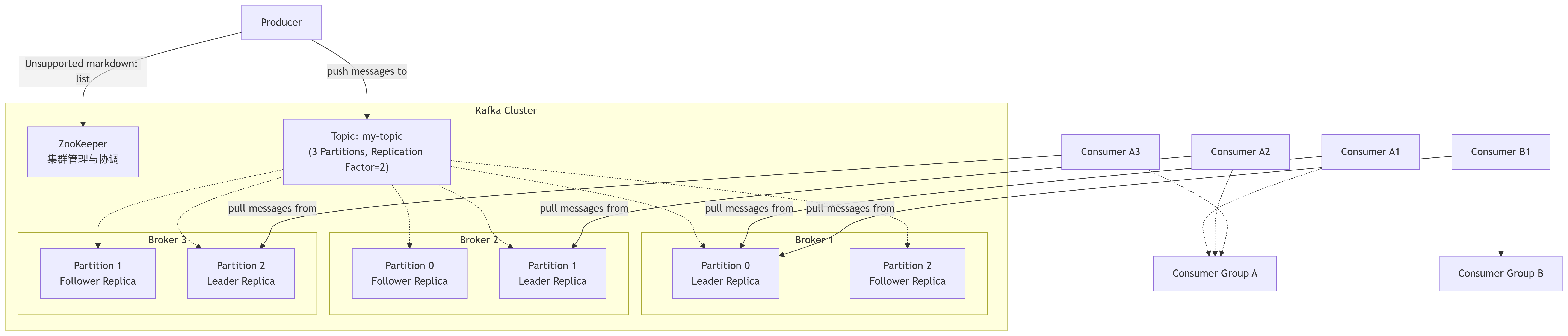
数据流解释:
生产者向 Topic 发送消息。生产者客户端会先从 ZooKeeper 或 Broker 获取元数据,得知目标 Topic 的 Leader Partition 在哪个 Broker 上,然后直接将消息发送给该 Broker。
消息被追加到对应 Partition Leader 的日志文件末尾,并分配一个 Offset。
Partition 的 Follower 会从 Leader 异步拉取数据,进行复制。
消费者以组的形式工作。组内的每个消费者独立地从分配给它的 Partition Leader 上拉取消息。消费者会定期提交其消费到的 Offset(默认存到 Kafka 的内部 Topic
__consumer_offsets中),从而记录消费进度。
四、高级特性与工作原理
1. 日志存储机制
分段存储: Partition 的物理日志文件被切分成多个段。活跃的段只有一个,写入只发生在活跃段。
索引: 每个日志段都有两个索引文件:
.index和.timeindex,用于根据 Offset 或时间戳快速定位消息。零拷贝: Kafka 大量使用操作系统的 零拷贝 技术(
sendfile),将数据直接从磁盘文件传输到网卡缓冲区,而不需要经过应用程序内存周转,极大地减少了上下文切换和数据拷贝次数,提升了 IO 性能。
2. 生产者发送消息流程
序列化与分区: 生产者对消息进行序列化,并根据分区器(Partitioner)决定消息发往哪个 Partition。
批量发送: 消息不会立即发送,而是先放入内存的缓冲区中,达到一定条件(大小或时间)后批量发送,极大减少网络 IO 次数。
确认机制:
acks=0: 生产者不等待任何确认,吞吐量最高,可能丢失数据。acks=1: Leader 成功写入本地日志即返回确认。是吞吐量和可靠性的折中方案(默认)。acks=all: Leader 需要等待所有 ISR 副本都成功同步消息后才返回确认。可靠性最高,吞吐量最低。
3. 消费者组与重平衡
重平衡: 当消费者组内的消费者数量发生变化(增、减、宕机),或 Topic 的 Partition 数量发生变化时,Kafka 会重新分配 Partition 给组内的消费者,这个过程称为重平衡。
重平衡期间,整个消费者组会停止工作,直到分配完成。因此,应尽量避免不必要的重平衡。
4. 副本同步机制与 ISR
ISR: 是指与 Leader 副本保持同步的副本集合(包括 Leader 自己)。
一个 Follower 副本是否在 ISR 中,取决于它是否在规定时间内追上了 Leader 的进度(由
replica.lag.time.max.ms参数控制)。只有 ISR 中的副本才有资格被选举为新的 Leader。
生产者可以配置为只有当消息被所有 ISR 副本确认后才算成功提交(
acks=all),这保证了即使在 Leader 宕机后,新 Leader 也拥有这条消息,从而实现了数据不丢失。
总结
Kafka 的架构是一个精妙的分布式系统设计典范:
分区机制实现了水平扩展和高吞吐。
副本机制实现了高可用和容灾。
生产者批量发送和零拷贝等技术优化了IO性能。
消费者组机制同时支持了队列和发布-订阅两种模型。
通过 ZooKeeper 实现了分布式协调。