Elasticsearch 核心知识与常见问题解析
最近在准备面试,正把平时积累的笔记、项目中遇到的问题与解决方案、对核心原理的理解,以及高频业务场景的应对策略系统梳理一遍,既能加深记忆,也能让知识体系更扎实,供大家参考,欢迎讨论。
一、基础概念与核心原理
(一)倒排索引
倒排索引是 ES 实现高效全文搜索的关键。与传统数据库通过记录找内容的正排索引不同,**倒排索引先对文档内容进行分词,再建立"分词-文档ID"的映射关系。**例如文档"我喜欢 Elasticsearch",分词后得到"我"“喜欢”“Elasticsearch”,倒排索引会记录这些分词分别出现在哪些文档里。当进行搜索时,ES 依据倒排索引能快速定位包含目标分词的文档,极大提升了搜索效率。
(二)索引、分片与副本
- 索引(Index):可将其理解为关系型数据库(MySQL)中的"表",是文档的集合,用于存储具有相同结构的数据。
- 分片(Shard):为了实现数据的分布式存储与横向扩展,一个索引会被划分成多个分片。分片又分为主分片和副本分片,主分片用于数据的写入,副本分片是主分片的备份,能提高数据的可用性和查询性能。
- 副本(Replica):副本分片的主要作用是容错和负载均衡。当主分片出现故障时,副本分片可升级为主分片;同时,多个副本分片能分担查询请求,提升系统的查询能力。
(三)版本与依赖
ES 版本迭代较快,不同版本对 Java 环境有不同要求。例如 ES 8 版本需要 JDK 17 及以上版本来支持运行,这是因为新版本 ES 引入了诸多新特性和优化,对 Java 运行时环境的功能和性能有更高的要求。在实际应用中,要根据项目所使用的 ES 版本,核对自身项目的 JDK 版本,确保兼容性。
(四)近实时特性与数据查询延迟
ES 并非严格实时的搜索引擎,而是“近实时(Near Real-Time, NRT)”系统,新增数据默认需等待约 1 秒才能查询到,核心原因与 “刷新(Refresh)机制” 相关:
- 数据写入流程:新数据首先写入 内存缓冲区(In-Memory Buffer),此时数据不可查询;默认每隔 1 秒,ES 执行一次 Refresh 操作,将内存缓冲区的数据写入 文件系统缓存(FileSystem Cache) 并生成“倒排索引分段(Segment)”,数据至此才具备查询能力;后续当文件系统缓存数据积累到一定量(或默认 30 分钟),会通过 Flush 操作 持久化到磁盘,确保数据不丢失。
- 1 秒延迟的本质:默认 1 秒的 Refresh 间隔是 ES 对“写入性能”与“查询实时性”的权衡——若 Refresh 过频繁(如 100ms),会频繁生成小分段,导致后续分段合并开销激增;1 秒间隔既能满足多数场景的近实时需求,又能控制写入损耗。 工作中由于im聊天消息写入量大,查询并非需要实时的,所以采用1s的默认配置。
- 延迟调整方式:若需更高实时性(如秒杀库存更新),可手动调用
POST /索引名/_refresh强制刷新API,或通过PUT /索引名/_settings修改refresh_interval参数(如设为 200ms);若无需实时性(如批量日志写入),可设为-1关闭自动刷新,待数据积累后手动触发(一般也不至于手动触发,只是了解下有这功能即可)。
二、关键功能与应用
(一)分词与分词器
分词是将文本拆分成若干个分词(Term)的过程,这是倒排索引建立的前提。ES 提供了多种分词器,以满足不同场景的需求:
- 标准分词器(Standard ):是 ES 的默认分词器,会按照单词边界进行分词,还会做小写转换等基本处理,适用英文分词场景,不适用中文分词。
- IK 分词器:专为中文文本设计,能更智能地对中文进行分词,解决了中文文本中"字与字连续书写、无天然分隔符"的分词难题(例如能将"Elasticsearch 是一款搜索引擎"准确拆分为"Elasticsearch"“是”“一款”“搜索引擎”)。它提供两种分词模式:
— ik_max_word最大化拆分,适合细粒度搜索
— ik_smart最小化拆分,适合快速匹配场景 - ICU 分词器:支持多语言分词,可对不同语言的文本进行较为准确的分词处理,在多语言混合的文本场景中表现出色。
在实际应用中,要根据文本的语言和业务需求选择合适的分词器,并且可以通过 Mapping 来为不同的字段指定特定的分词器。
(二)Mapping 与字段类型
Mapping 相当于关系型数据库中的"表结构定义",用于指定索引中文档的字段类型、分词器等属性。
- 字段类型:ES 支持丰富的字段类型,常用的字符串类型:
— keyword 类型适用于精确值的存储与查询,像商品 ID、用户昵称等;
该字段不会被分析处理,支持精确匹配和排序操作,支持倒排索引。
— text 类型则用于全文本内容,会进行分词处理,以便进行模糊搜索。 - 动态映射与静态映射:动态映射下,ES 会根据插入的文档自动推断字段类型;静态映射则需要提前明确定义字段的类型和属性,能更精确地控制索引结构,适合对数据结构要求严格的场景。
三、常见操作与问题
(一)索引操作
索引合并
索引合并是将多个小索引合并成一个大索引的操作,有助于减少索引数量,提高查询性能(工作中在晚上业务低峰期操作过索引合并,查询时间明显提升)。
需要注意的是,索引合并后如果不进行刷新(refresh)操作,可能导致查询暂时不可用。可以使用 ES 提供的命令来刷新索引,保证索引处于可用状态,避免代码执行查询时出现错误。
// 合并主要步骤如下
执行合并
POST /_reindex
刷新索引(使变更可见)
POST /索引名/_refresh
验证查询
GET /索引名/_search
(二)查询相关
查询条数限制
ES 对单次查询的条数有默认限制,size 参数最大支持一次查询 10000 条数据,默认返回 10 条(在工作中需要注意下,当查询所有数据的时候,注意默认值)。如果需要查询所有数据,不能简单地增大 size 参数,因为这会对内存和性能造成很大压力,应该采用滚动查询(Scroll)或 search_after 等方式来分批获取大量数据。 工作中使用了Scroll,根据im消息id 做为scroll_id。Elasticsearch 深分页限制与解决方案.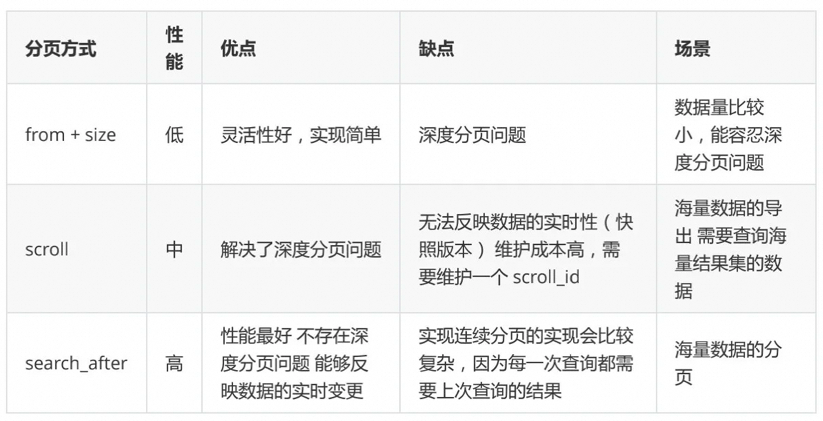
先查后改操作
在进行文档更新操作时,为了确保更新的准确性,通常会采用先查后改的方式。即先根据查询条件获取文档,然后对文档内容进行修改,最后再将修改后的文档写回 ES。这种方式能有效避免并发更新时的数据冲突问题,保证了数据一致性。
(三)性能与优化
分词与倒排索引优化
倒排索引的构建依赖于分词操作,不同的分词器和分词策略会影响索引的大小和查询性能。**要根据业务场景选择合适的分词器,还可以通过调整分词器的参数来优化分词效果。**同时,合理设置字段是否需要建立倒排索引,对于一些只需要精确查询、不需要分词的字段(如 keyword 类型字段),可以适当减少不必要的倒排索引构建,以节省存储空间和提高写入性能。
分片与副本设置
分片和副本的数量要根据数据量、服务器性能和业务需求来合理设置。主分片数量一旦确定就不能修改,所以在创建索引时要充分考虑未来的数据增长情况;副本分片数量可以根据高可用性和查询性能的需求进行动态调整,更多的副本分片能提高查询的并发能力,但也会增加数据同步的开销和存储空间的占用。