GPT-5 正式发布:把一个“博士团队”装进手机,AI 新时代开启
导语:2025年8月,OpenAI 正式发布 GPT-5,标志着大模型进入“统一模型+万字上下文+情感智能”新阶段。它不仅屠榜 LMArena,更在编程、前端、情感理解等维度实现全面突破。本文带你深度解读 GPT-5 的五大核心特性,以及它将如何重塑我们的工作与生活。
一、GPT-5 正式发布,AI 竞技场再起波澜
在万众期待中,OpenAI 于2025年8月初正式发布了 GPT-5。这是继 GPT-4 发布两年半后的又一次重大跃迁,也被 Sam Altman 称为:“把一个博士团队揣在手机里”的时代级产品。

值得一提的是,在 GPT-5 发布前的2025年前七个月,中国 AI 赛道已迎来爆发:阿里(Qwen)、DeepSeek、月之暗面(Kimi)、智谱(GLM)等十余家厂商密集推出开源大模型。在 OpenRouter 趋势榜前10名中,中国模型一度占据9席。
然而,GPT-5 上线后迅速屠榜大模型竞技场 LMArena,在所有细分类目中均位列第一,再次确立了 OpenAI 的技术领先地位。
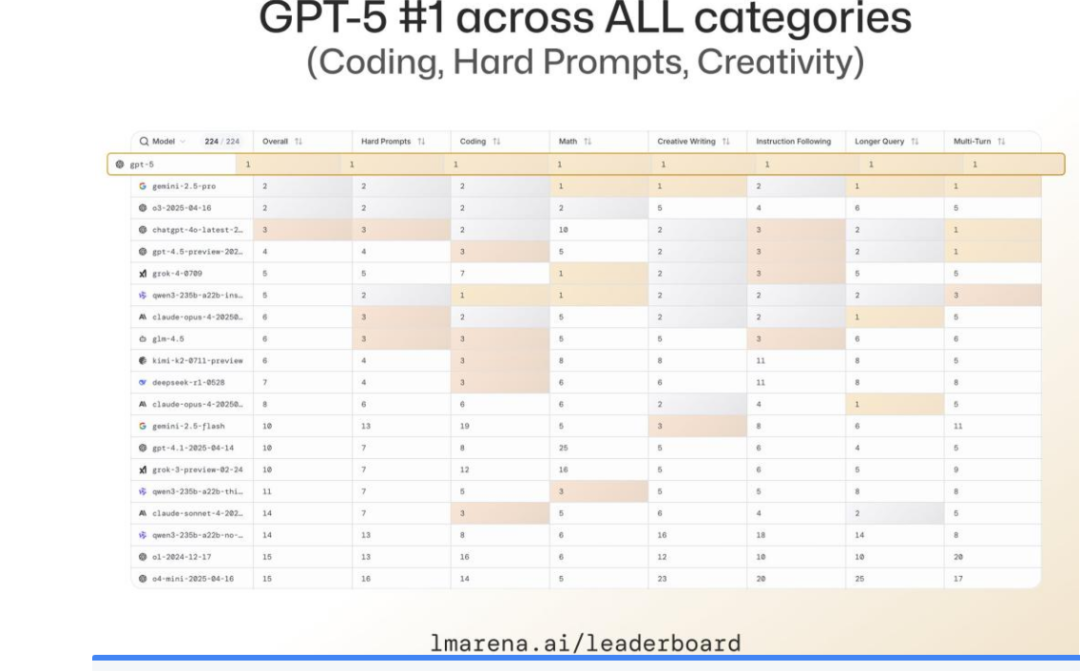
二、GPT-5 五大核心特性,全面进化
1. 统一模型 + 万字上下文:400K 上下文支持
GPT-5 首次实现了模型的统一命名与架构整合。不再区分 GPT-4 Turbo、GPT-4o 等复杂命名,所有模型统一为 GPT-5。
更关键的是,它采用“统一模型架构”,能在“智能”与“速度”之间动态切换:
- 输入简单问题 → 自动进入“快速响应”模式
- 遇到复杂任务 → 切换至“深度推理”模式
- 内置实时路由系统,自动判断最优执行路径
🔥 上下文长度突破:400K Token
相比 GPT-4 的 128K,GPT-5 的上下文长度提升至 400K Token(提升300%),输出也支持 128K Token,彻底告别“内容截断”。
在中文场景下,400K Token 约等于 120万汉字,意味着你可以:
- 一次性上传整本《红楼梦》进行分析
- 将《三体》全集喂给模型做深度解读
- 处理大型代码库、技术文档、学术论文
这为 AI 在科研、工程、法律等复杂场景的应用奠定了基础。
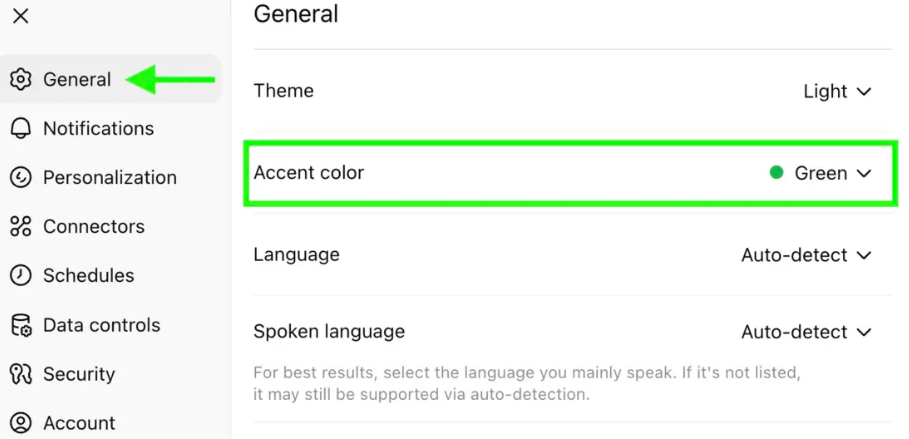
2. 自定义聊天界面:支持主题颜色切换
长久以来,AI 聊天界面多为“白底黑字”,缺乏个性化。GPT-5 首次支持自定义聊天界面主题颜色。
虽然此前 DeepSeek 推出了暗黑模式已获好评,但 GPT-5 的 UI 定制能力更进一步,允许用户根据场景或偏好调整界面风格,提升使用体验。
反观国内产品如通义千问、豆包、元宝等,仍以默认白色主题为主,UI 交互创新相对滞后。
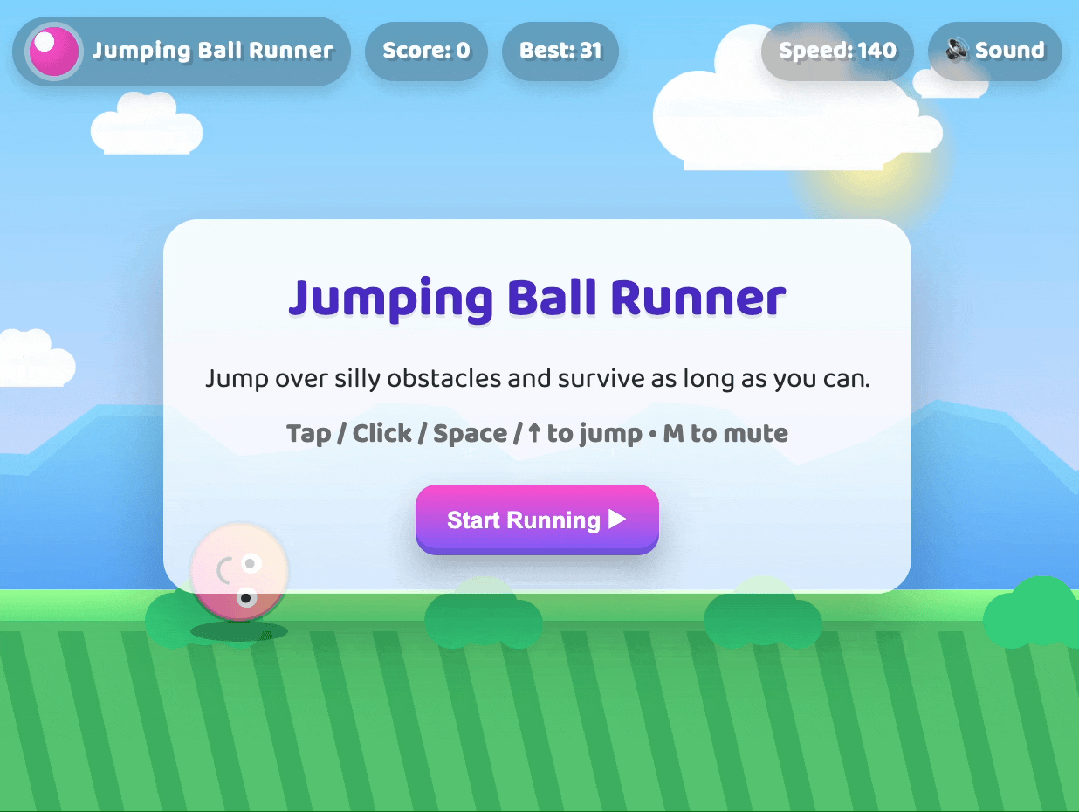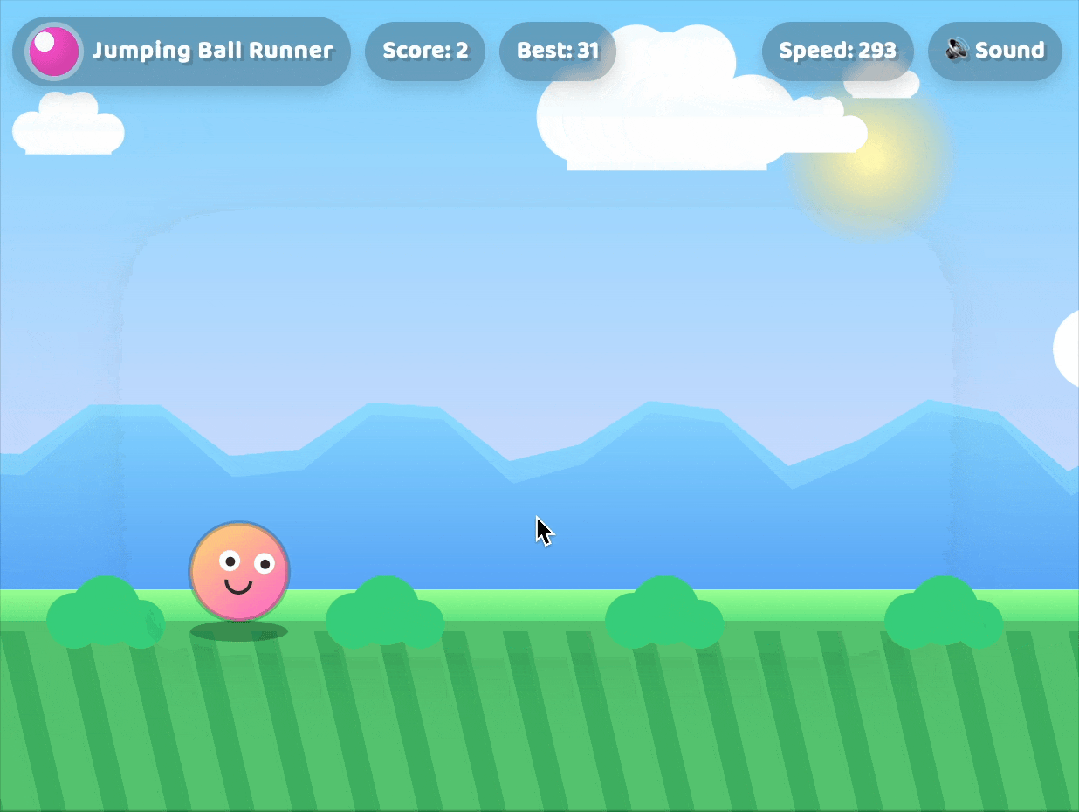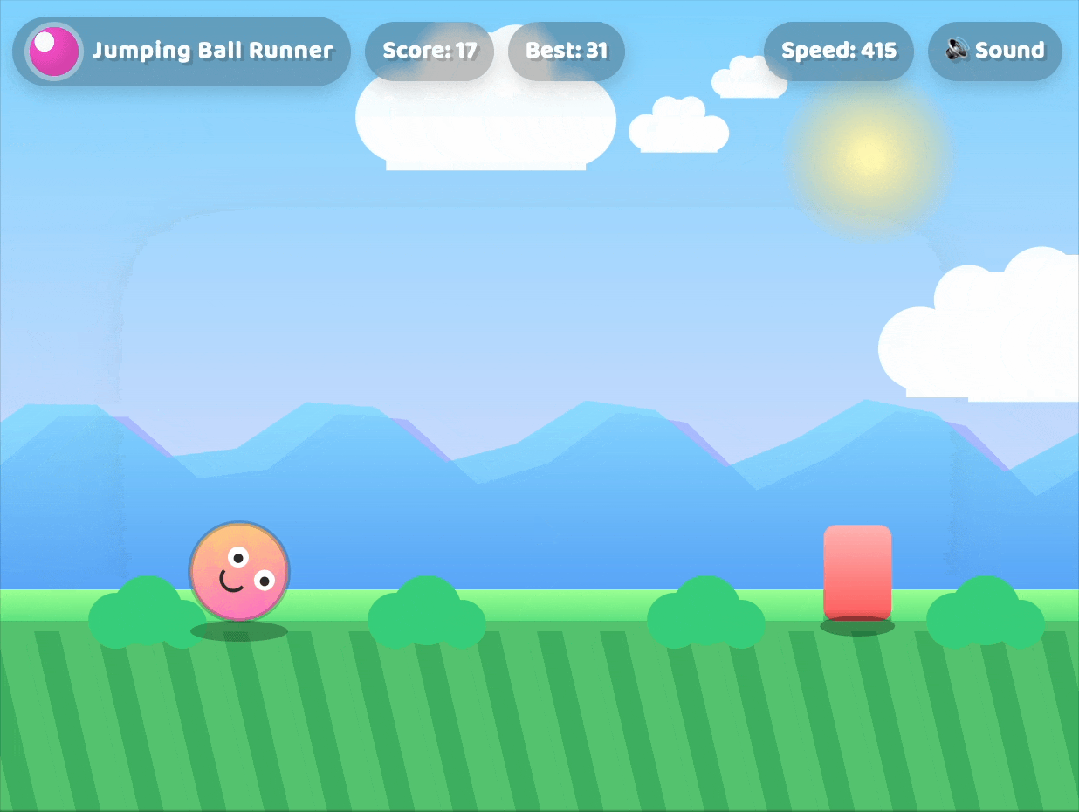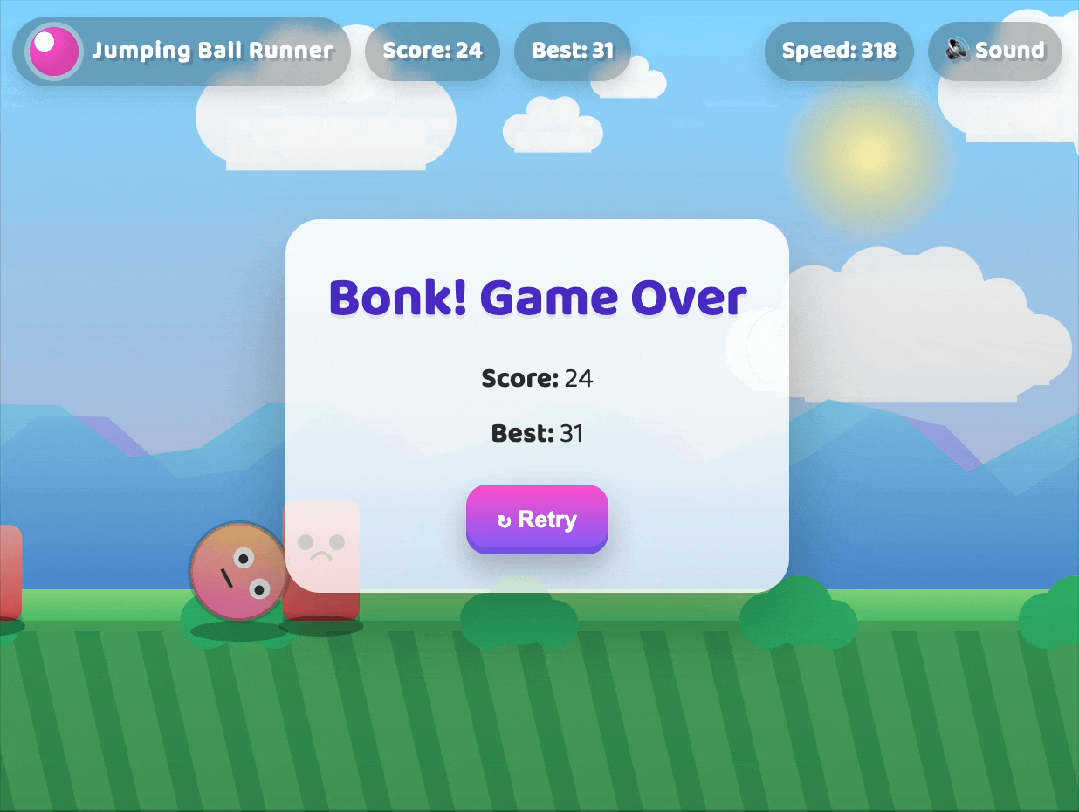
3. 前端工程能力飞跃:几分钟生成可用 UI
前端一直是大模型的“短板”——生成的代码常存在样式错乱、交互缺失等问题。而 GPT-5 在这一领域实现了质的飞跃。
它不仅能生成语义正确、结构清晰的前端代码,还具备:
- 更高的审美水准
- 更强的布局理解能力
- 支持实时预览 UI 效果
💡 演示:几分钟生成一个小游戏
只需几句描述,GPT-5 便能在几分钟内生成一个完整可运行的小游戏,包含:
- HTML/CSS/JS 代码
- 响应式布局
- 交互逻辑
- 可预览的 UI 界面
这极大提升了前端开发效率,真正实现“所想即所得”。
4. 情感智能升级:先共情,再回答
GPT-5 不仅“智商”提升,“情商”也大幅进化。
以往模型面对情感类问题时,往往直接给出冷冰冰的答案。而 GPT-5 能识别用户情绪,在回应前先提供“情绪价值”。
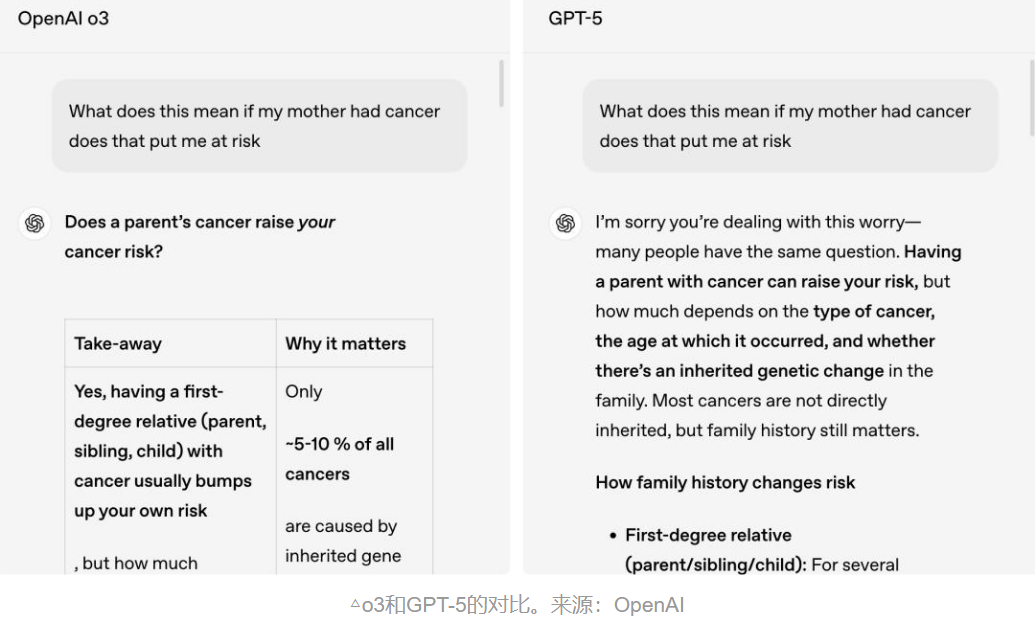
🌰 案例:用户提问
“我妈妈得癌症了,怎么办?我的得癌几率也会很高吗?”
- 旧模型回答:直接列出遗传概率、医学建议
- GPT-5 回答:
- 先表达共情:“听到这个消息,我能感受到你的担忧和痛苦……”
- 再理性分析:“从医学角度看,某些癌症确实有遗传倾向……”
这种“先共情,再解决”的模式,让 AI 更像一个“有温度的伙伴”,而非冰冷的机器。
5. 自动调试 + 任务扩展:开启“AI 半自动化协同”
GPT-5 在编程领域引入了“自我修正与任务延展”能力,标志着从“人工驱动”向“AI 协同”的转变。
🔧 自动调试
- 能主动发现代码中的 Bug
- 自动定位问题并提供修复方案
- 支持多轮迭代优化
🚀 任务扩展
- 不再局限于“你让干啥就干啥”
- 能根据上下文主动建议新功能,如:
- “这个登录页可以加个验证码”
- “建议增加错误日志记录”
这种能力正在催生一种全新开发范式——Vibe Coding(面向感觉编程):
用户只需说:“我想要一个能记录日常开销的小工具”,AI 便能从零开始构建完整应用。
三、编程能力登顶:SWE-bench 准确率 74.9%
在权威的 SWE-bench Verified 基准测试中,GPT-5 取得了 74.9% 的准确率,超越 Claude 等竞品,成为当前最强的代码生成模型。
SWE-bench Verified 是 OpenAI 推出的软件工程能力评估基准,用于衡量模型在真实 GitHub 项目中修复 Bug、实现功能的能力。
Sam Altman 直言:“编码是 GPT-5 的超能力。” 随着生成代码准确率的提升,程序员将从繁琐的 Bug 修复中解放,转向更高价值的架构设计与产品创新。

四、写在最后:AI 不是替代,而是进化
GPT-5 的发布,不是终点,而是新纪元的起点。
它告诉我们:
- AI 不再只是“工具”,而是“协作者”
- 技术的边界在不断扩展,但人类的创造力、情感与决策力,依然是不可替代的核心
“不要在意别人对你的任何评价。别人夸你,只是你符合他的价值判断;别人损你,只是你违背了他的价值判断。”
—— 而我们,正在用自己的方式,定义未来。