HunyuanVideo-Foley - AI视频配音 根据视频和文本描述生成逼真的电影级音频 支持50系显卡 一键整合包下载
HunyuanVideo-Foley 是腾讯混元团队开源的端到端视频音效生成模型,用户只需上传一段视频,输入对应的文字描述(如“海浪声”、“汽车引擎轰鸣”等,也可留空,模型会自动识别),模型就能自动生成与画面精准匹配的电影级音效,让原本无声的视频“活”起来。
核心特点
多模态理解能力
模型能同时“看懂”视频画面和“读懂”文字描述,动态生成环境音、拟音等复合音效。例如,输入一段包含海浪、沙滩人群和海鸥的视频,并描述“海浪声”,模型不仅能生成波浪音效,还能捕捉人群交谈声、海鸥鸣叫声,甚至融入背景环境音,形成层次丰富的音效。
高保真音频生成
通过创新架构和损失函数,模型生成的音频质量接近专业水准,无明显背景噪音或杂音。例如,它能精准还原引擎从怠速到轰鸣的动态变化,或呈现轮胎与地面摩擦的质感。
强泛化能力
团队构建了约10万小时的高质量TV2A(文本-视频-音频)数据集,支持人物互动、动物活动、自然景观、卡通动画、科幻等各类场景,生成音画一致、语义对齐的音频。
应用领域
短视频创作 自动适配搞笑段子、生活Vlog、AI视频等内容的场景氛围,一键生成贴合画面节奏的背景音效,提升创意表达感染力。
电影制作 快速构建环境音、拟音等细节丰富的声效场景,突破传统音效制作的周期与成本瓶颈,实现降本提效的后期制作升级。
广告创意 精准匹配产品宣传片的风格调性,通过沉浸式声效增强视觉冲击力与品牌记忆点。
游戏开发 依据游戏场景的动态变化实时生成沉浸式环境音、角色动作音效等,打造更具代入感的互动体验。
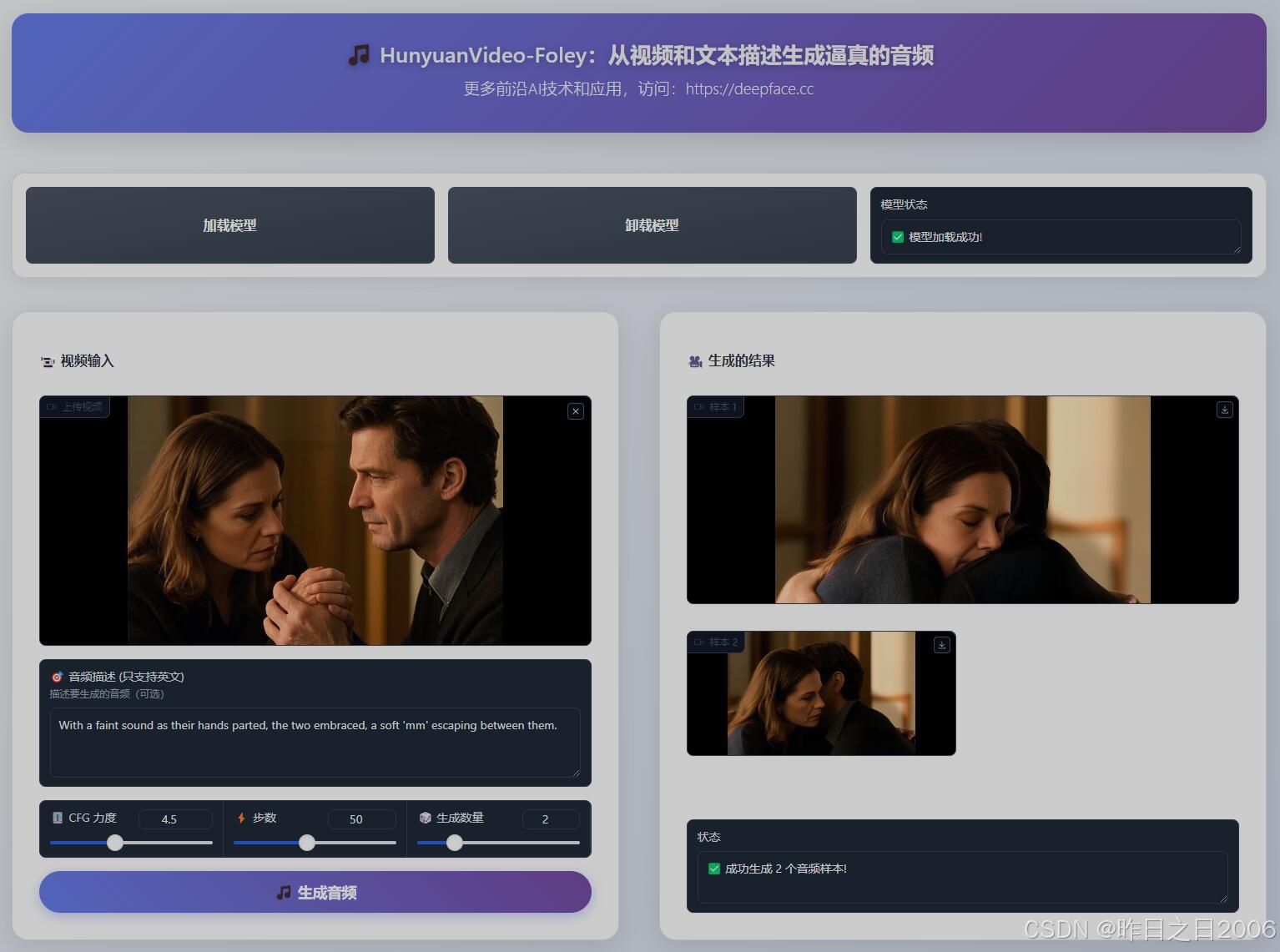
使用教程:(建议N卡,显存16G起,支持50系显卡,基于CUDA12.8)
上传需要生成音频的视频,输入提示词(提示词可选,如果有个性化需求,可以填写,提示词只支持英文),生成即可,支持一次生成多个配音效果供选择。
下载地址:点此下载