大数据毕业设计选题推荐-基于大数据的存量房网上签约月统计信息可视化分析系统-Hadoop-Spark-数据可视化-BigData
✨作者主页:IT毕设梦工厂✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、PHP、.NET、Node.js、GO、微信小程序、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
☑文末获取源码☑
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目
文章目录
- 一、前言
- 二、开发环境
- 三、系统界面展示
- 四、部分代码设计
- 五、系统视频
- 结语
一、前言
系统介绍:
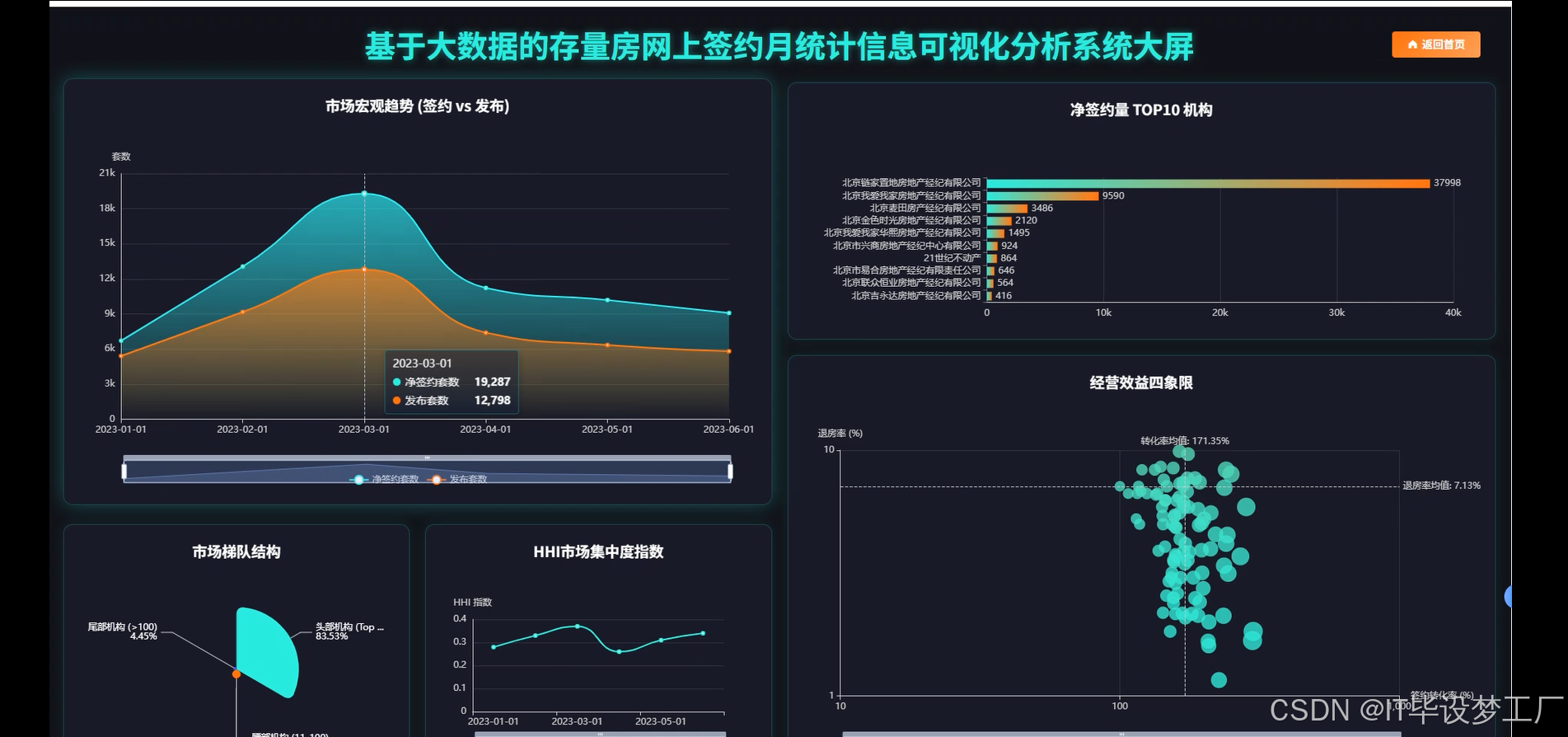
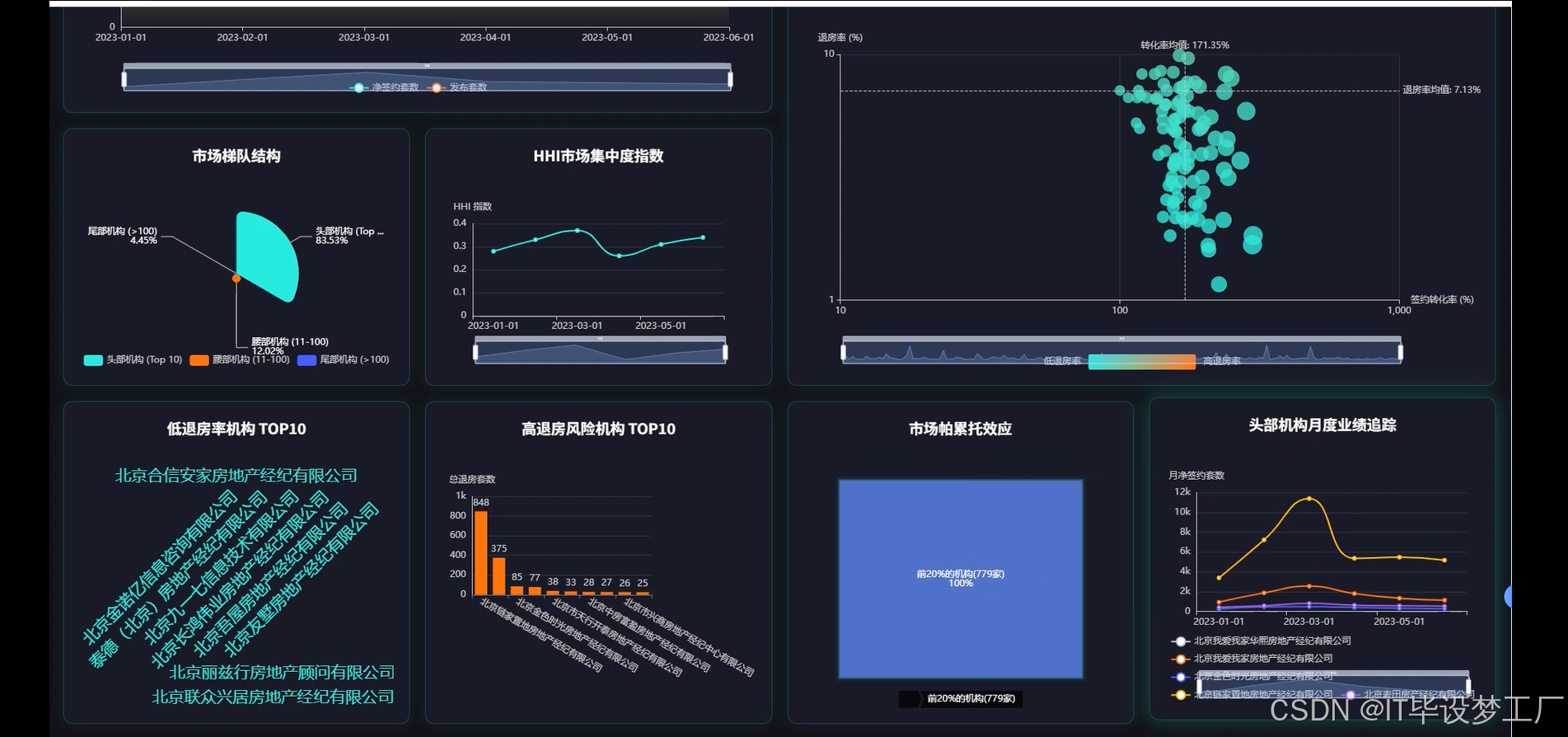
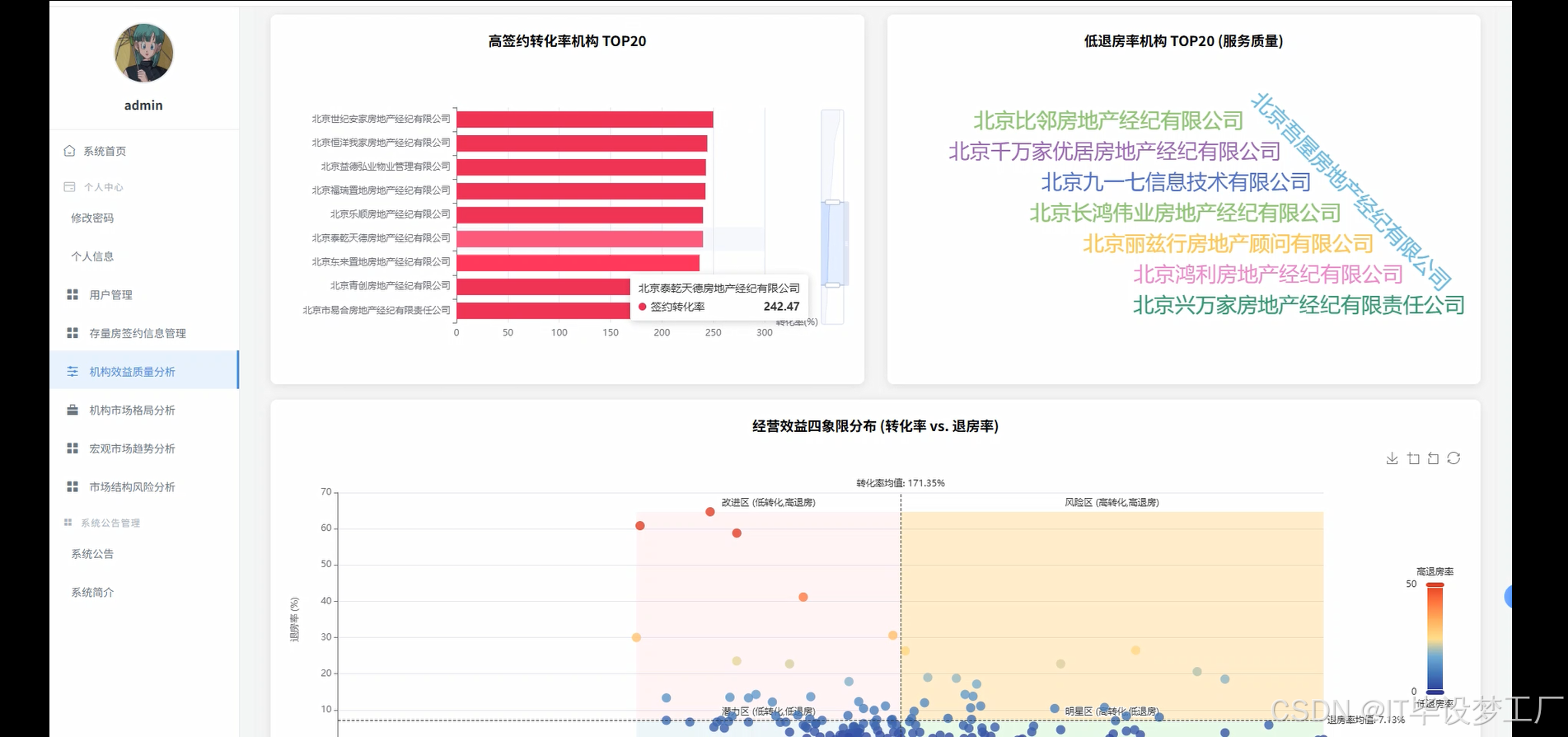
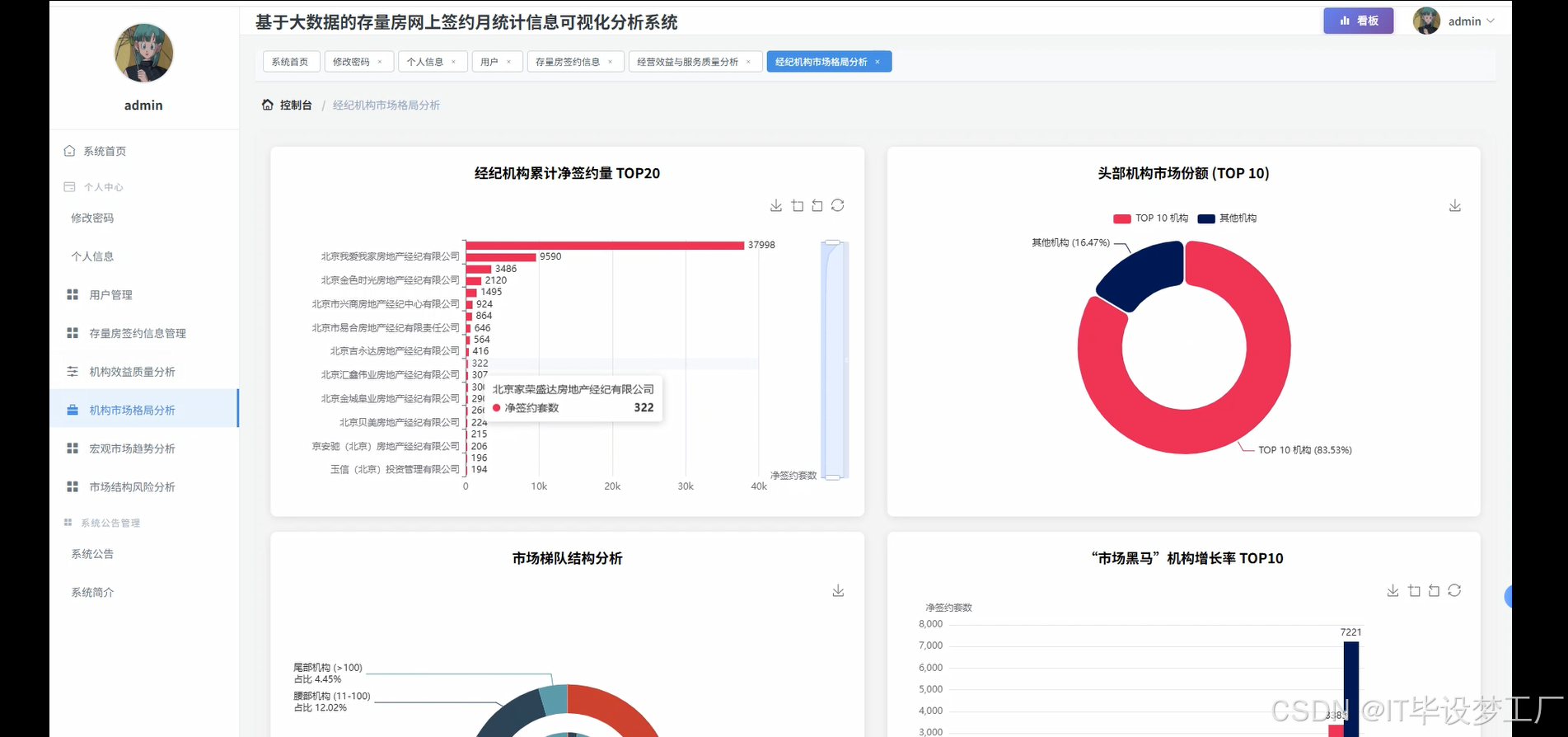
本系统面向“存量房网上签约月度统计信息”的聚合、计算与可视化展示,围绕数据采集、清洗、计算与前端交互建立一套端到端的分析链路。底层以Hadoop/HDFS为存储载体,Spark与Spark SQL承担批量ETL与指标计算,结合Pandas/NumPy完成部分轻量统计与结果回填;数据经由Django或Spring Boot提供统一REST接口,前端以Vue+ElementUI为骨架,Echarts完成趋势、排行榜、四象限、环形占比、帕累托等图表渲染。系统支持对“发布、签约、退房、净签约、活跃机构数”等时序量的月度汇总,对机构维度进行转化率与退房率的联合衡量,并给出HHI市场集中度、二八效应与波动性等结构化指标,便于从宏观走势、市场格局、经营质量和潜在风险四个角度形成闭环判断。数据通道采用可配置的路径与任务参数,既能对接企业现有HDFS目录,又能接收外部CSV/MySQL导入;计算层提供按时间窗、机构清单与阈值的灵活过滤;接口层暴露列表、指标与图表数据三类JSON,前端仅做轻量组装与交互,保障了多端复用与二次开发的空间。
选题背景:
存量房交易逐步线上化,业务链路从发布、带看到签约与退房,产生了大量离散而分散的数据。行业一线通常使用多套表格或简单报表完成统计,颗粒度不一致、时间跨度不统一,导致可比性差,也很难支撑管理侧做节奏判断与资源投入。另一方面,存量房市场受季节、政策与区域结构影响明显,单看绝对量往往误判景气度,需要把“签约、退房、净签约、活跃机构数”放在同一时间基准下观察,并与机构层面的转化与质量指标联动起来。技术层面,企业内部普遍具备Hadoop集群或对象存储,具备以Spark为核心的计算条件,但缺少一套针对“月度签约统计”的轻量方法论与可落地的计算/展示框架。因此,基于大数据栈构建一套可配置、可复算、可视化良好的分析系统,具有现实推动力。
选题意义:
本课题更偏实践化,目标是把常见的签约月报从手工统计升级为自动化计算与交互式展示。对管理者,能快速看到趋势、集中度与机构质量画像,减少手工汇总时间,让讨论聚焦在决策层面。对业务团队,统一的口径与可回溯的计算逻辑有助于复盘策略,识别高退房风险与高增长机构,进行精细化运营。对技术同学,系统把HDFS+Spark+Web后端+前端可视化打通,形成一条可迁移到其它交易统计场景的工程样板,易于在毕业设计或企业内小范围推广。系统并不追求夸张效果,更强调数据口径清晰、计算链路透明与图表表达直接,在有限投入下提升报表的准确性、及时性与可读性,这些朴素目标本身就能产生稳定价值。
二、开发环境
- 大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
- 开发语言:Python+Java(两个版本都支持)
- 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
- 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
- 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
- 数据库:MySQL
三、系统界面展示
- 基于大数据的存量房网上签约月统计信息可视化分析系统界面展示:
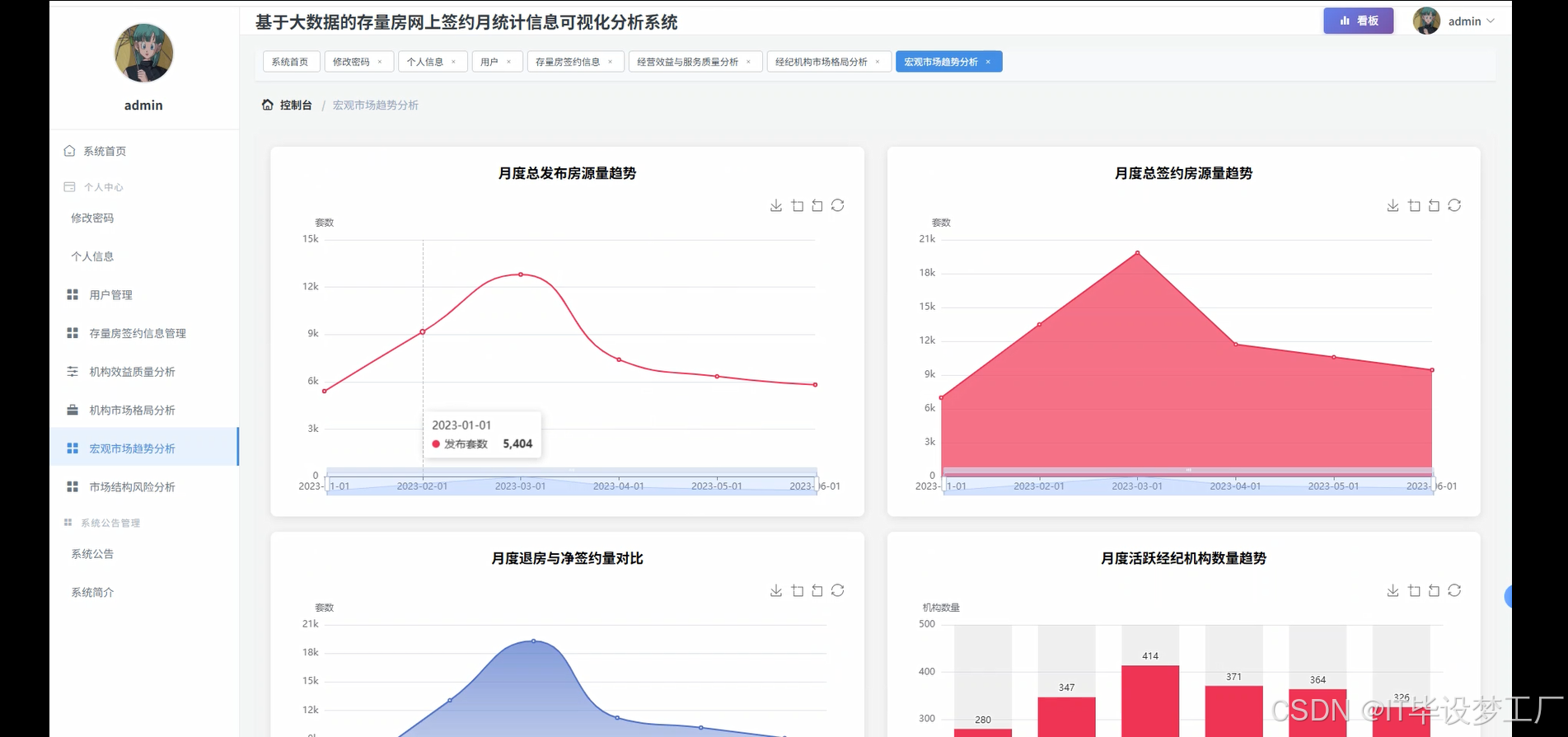
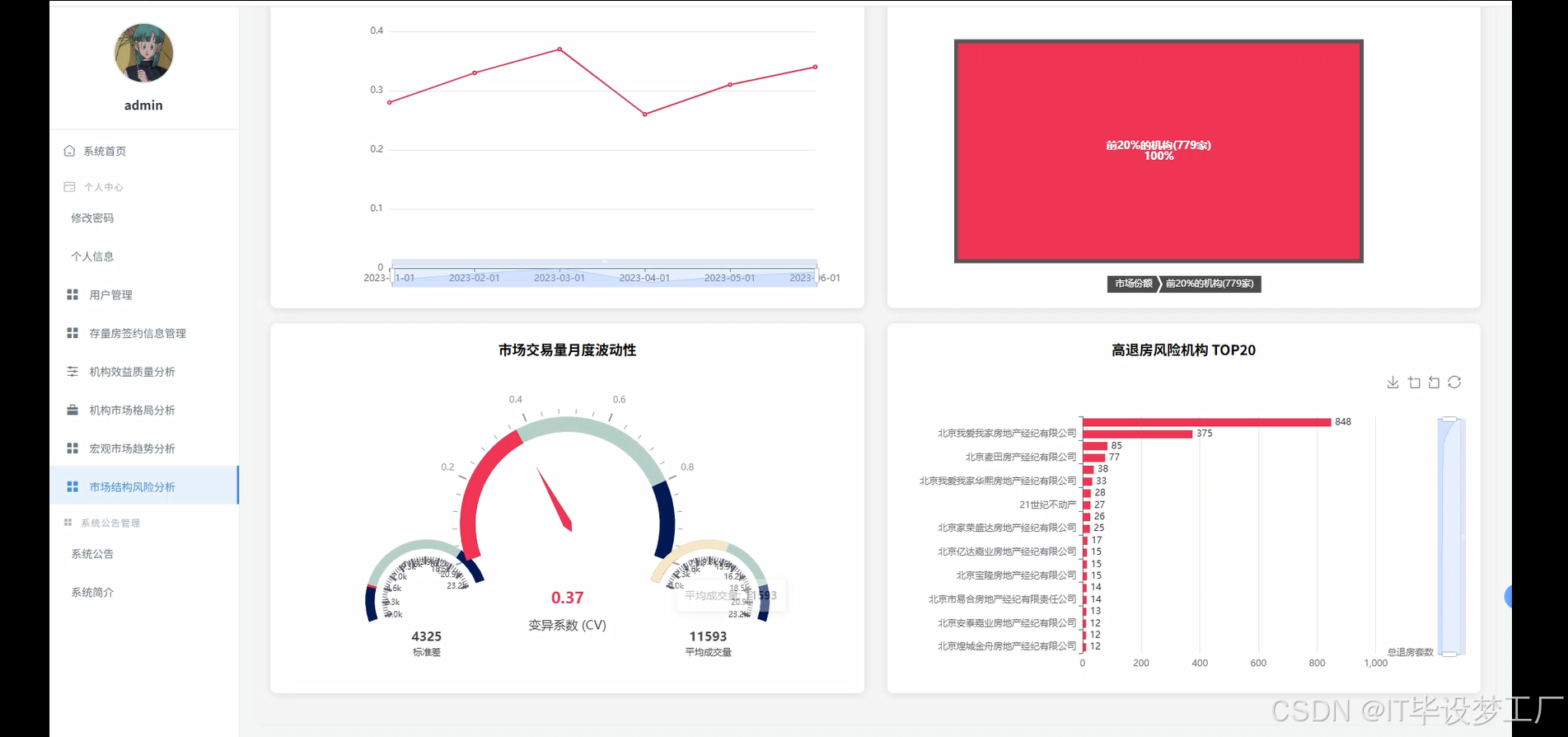
四、部分代码设计
- 项目实战-代码参考:
from pyspark.sql import SparkSession
spark=SparkSession.builder.appName("StockHousingMonthlyAnalytics").enableHiveSupport().getOrCreate()
def monthly_macro_trend(hdfs_path,start_date,end_date,page=1,page_size=12):df=spark.read.option("header","true").option("inferSchema","true").csv(hdfs_path)df.createOrReplaceTempView("raw")sql=f"""with base as(select to_date(`统计时间`) as dt,date_format(to_date(`统计时间`),'yyyy-MM') as ym,cast(`发布套数` as int) as pub,cast(`签约套数` as int) as sig,cast(`退房套数` as int) as ref,`房地产经纪机构名称` as orgfrom raw where to_date(`统计时间`) between to_date('{start_date}') and to_date('{end_date}')),agg as(select ym,sum(pub) as publish_cnt,sum(sig) as sign_cnt,sum(ref) as refund_cnt,sum(sig)-sum(ref) as net_sign_cntfrom base group by ym),active as(select ym,count(distinct org) as active_orgsfrom base where sig>0 group by ym)select a.ym,publish_cnt,sign_cnt,refund_cnt,net_sign_cnt,coalesce(b.active_orgs,0) as active_orgsfrom agg a left join active b on a.ym=b.ym order by a.ym"""res=spark.sql(sql)total=res.count()if page_size<=0: page_size=12offset=max((page-1)*page_size,0)res=res.limit(offset+page_size)res=res.rdd.zipWithIndex().filter(lambda x:x[1]>=offset).map(lambda x:x[0]).toDF(res.schema)out=[row.asDict() for row in res.collect()]return {"total":total,"page":page,"page_size":page_size,"items":out}
def hhi_trend_by_month(hdfs_path,start_date,end_date):df=spark.read.option("header","true").option("inferSchema","true").csv(hdfs_path)df.createOrReplaceTempView("raw2")sql=f"""with base as(select date_format(to_date(`统计时间`),'yyyy-MM') as ym,`房地产经纪机构名称` as org,cast(`签约套数` as int)-cast(`退房套数` as int) as netfrom raw2 where to_date(`统计时间`) between to_date('{start_date}') and to_date('{end_date}')),mkt as(select ym,org,case when net<0 then 0 else net end as netfrom base),sum_mkt as(select ym,sum(net) as total from mkt group by ym),share as(select a.ym,a.org,case when b.total=0 then 0.0 else a.net/b.total end as sfrom mkt a join sum_mkt b on a.ym=b.ym),hhi as(select ym,round(sum(s*s),6) as hhi from share group by ym)select ym,hhi from hhi order by ym"""res=spark.sql(sql)series=[row.asDict() for row in res.collect()]level=[("高度集中" if r["hhi"]>=0.25 else ("中度集中" if r["hhi"]>=0.15 else "竞争充分")) for r in series]annotated=[{**r,"level":lv} for r,lv in zip(series,level)]return {"items":annotated,"explain":"HHI≈∑(机构份额²),阈值可根据行业经验在0.15/0.25附近取值"}
def efficiency_quadrant(hdfs_path,start_date,end_date):df=spark.read.option("header","true").option("inferSchema","true").csv(hdfs_path)df.createOrReplaceTempView("raw3")sql=f"""with base as(select `房地产经纪机构名称` as org,date_format(to_date(`统计时间`),'yyyy-MM') as ym,cast(`发布套数` as int) as pub,cast(`签约套数` as int) as sig,cast(`退房套数` as int) as reffrom raw3 where to_date(`统计时间`) between to_date('{start_date}') and to_date('{end_date}')),agg as(select org,sum(pub) as pub,sum(sig) as sig,sum(ref) as ref from base group by org),metric as(select org,case when pub=0 then 0.0 else sig/pub end as convert_rate,case when sig=0 then 0.0 else ref/sig end as refund_rate,sig as total_sign,pub as total_pub,ref as total_reffrom agg),threshold as(select percentile_approx(convert_rate,0.5) as med_convert,percentile_approx(refund_rate,0.5) as med_refundfrom metric)select m.org,m.convert_rate,m.refund_rate,m.total_sign,m.total_pub,m.total_ref,t.med_convert,t.med_refund,case when m.convert_rate>=t.med_convert and m.refund_rate<=t.med_refund then '明星'when m.convert_rate>=t.med_convert and m.refund_rate> t.med_refund then '蛮牛'when m.convert_rate< t.med_convert and m.refund_rate<=t.med_refund then '稳健'else '问题' end as quadrantfrom metric m cross join threshold t"""res=spark.sql(sql)scatter=[row.asDict() for row in res.collect()]zero_publish=[r for r in scatter if r["total_pub"]==0 and r["total_sign"]>0]top_quality=sorted([r for r in scatter if r["total_sign"]>0],key=lambda x:x["refund_rate"])[:20]return {"scatter":scatter,"special_zero_publish":zero_publish,"low_refund_top20":top_quality}五、系统视频
- 基于大数据的存量房网上签约月统计信息可视化分析系统-项目视频:
大数据毕业设计选题推荐-基于大数据的存量房网上签约月统计信息可视化分析系统-Hadoop-Spark-数据可视化-BigData
结语
大数据毕业设计选题推荐-基于大数据的存量房网上签约月统计信息可视化分析系统-Hadoop-Spark-数据可视化-BigData
想看其他类型的计算机毕业设计作品也可以和我说~谢谢大家!
有技术这一块问题大家可以评论区交流或者私我~
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:⬇⬇⬇
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目