【LLM】Transformer模型中的MoE层详解
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
一、前言
在 Transformer 模型中,MoE 主要包含两个部分:
- 稀疏的 MoE 层取代了通常的密集前馈网络 (FFN) 层。一个 MoE 层包含多个“专家”(例如 8 个)。每个“专家”都是一个独立的神经网络。通常,这些“专家”是 FFN,但它们也可以是更复杂的网络,甚至是另一个 MoE。这就形成了分层的 MoE。
- 门网络(或路由器)决定哪些令牌分配给哪个专家。例如,令牌“HI”可能发送给第二个专家,而令牌“HELLO”则发送给第一个专家。一个令牌也可以发送给多个专家。选择如何路由令牌是多级验证模型 (MoE) 的主要挑战之一。路由器具有可学习的参数,并与模型的其他部分一起训练。
MoE 具有高效预训练、更快推理等优势,但也带来了挑战。
- 训练:它们允许进行计算效率更高的预训练,但在微调过程中往往难以推广,这可能导致过度拟合。
- 推理:推理过程中只有部分参数处于活动状态,因此 MoE 的运行速度比同等大小的密集模型更快。然而,所有参数仍然需要存储在内存中,这意味着对 VRAM 的要求较高。
例如,Mixtral 8x7B 模型在内存中大约有 47B 个参数(而不是 56B),因为只有 FFN 层是独立的专家,而其他层是共享的。在推理过程中,如果每个 token 使用两个专家,则计算结果类似于 12B 模型,而不是完整的 14B 模型,因为只有 2x7B 专家处于活动状态,并且共享层。
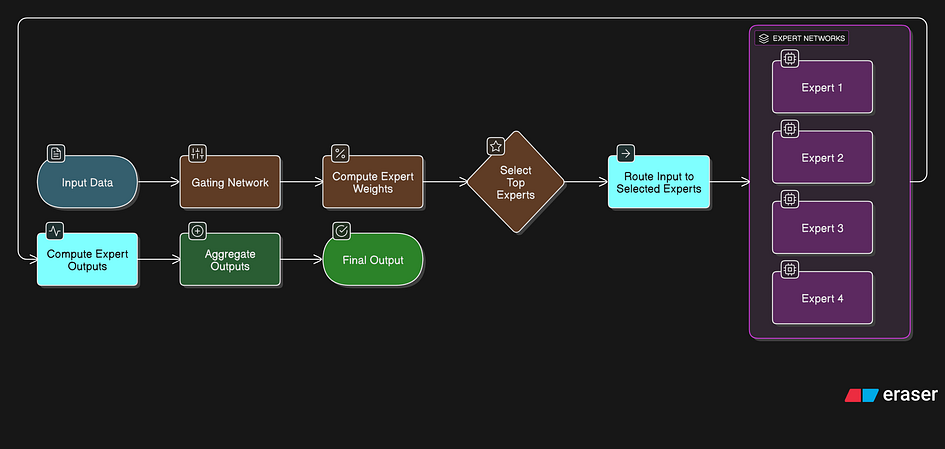
让我们看一下代码,然后清楚地分解它。
class MoEFeedForward(nn.Module):def __init__(self, cfg):super().__init__()self.num_experts_per_tok = cfg["num_experts_per_tok"]self.num_experts = cfg["num_experts"]self.gate = nn.Linear(cfg["emb_dim"], cfg["num_experts"], bias=False, dtype=cfg["dtype"])# meta device - 在加载权重之前初始化模型时减少内存压力meta_device = torch.device("meta")self.fc1 = nn.ModuleList([nn.Linear(cfg["emb_dim"], cfg["moe_intermediate_size"],bias=False, dtype=cfg["dtype"], device=meta_device)for _ in range(cfg["num_experts"])])self.fc2 = nn.ModuleList([nn.Linear(cfg["emb_dim"], cfg["moe_intermediate_size"],bias=False, dtype=cfg["dtype"], device=meta_device)for _ in range(cfg["num_experts"])])self.fc3 = nn.ModuleList([nn.Linear(cfg["moe_intermediate_size"], cfg["emb_dim"],bias=False, dtype=cfg["dtype"], device=meta_device)for _ in range(cfg["num_experts"])])def forward(self, x):b, seq_len, embed_dim = x.shapescores = self.gate(x) # (b, seq_len, num_experts)topk_scores, topk_indices = torch.topk(scores, self.num_experts_per_tok, dim=-1)topk_probs = torch.softmax(topk_scores, dim=-1)expert_outputs = []for e in range(self.num_experts):hidden = silu(self.fc1[e](x)) * self.fc2[e](x)out = self.fc3[e](hidden)expert_outputs.append(out.unsqueeze(-2))expert_outputs = torch.cat(expert_outputs, dim=-2) # (b, t, num_experts, emb_dim)gating_probs = torch.zeros_like(scores)for i in range(self.num_experts_per_tok):indices = topk_indices[..., i:i+1]prob = topk_probs[..., i:i+1]gating_probs.scatter_(dim=-1, index=indices, src=prob)gating_probs = gating_probs.unsqueeze(-1) # (b, t, num_experts, 1)# 专家加权和y = (gating_probs * expert_outputs).sum(dim=-2)return y模型配置:
QWEN3_CONFIG = {"vocab_size": 151_936,"context_length": 262_144,"emb_dim": 2048,"n_heads": 32,"n_layers": 48,"head_dim": 128,"qk_norm": True,"n_kv_groups": 4,"rope_base": 10_000_000.0,"dtype": torch.bfloat16,"num_experts": 128,"num_experts_per_tok": 8,"moe_intermediate_size": 768,
}二、逐一分解代码
仅保留数字部分并跳过所有其他因素(如偏差、数据类型、设备)。
class MoEFeedForward(nn.Module):def __init__(self):super().__init__()self.num_experts_per_tok = 8self.num_experts = 128self.gate = nn.Linear(2048, 128)self.fc1 = nn.ModuleList([nn.Linear(2048, 768) # emb_dim -> moe_intermediate_sizefor _ in range(128) # num_experts])self.fc2 = nn.ModuleList([nn.Linear(2048, 768) # emb_dim -> moe_intermediate_sizefor _ in range(128) # num_experts])self.fc3 = nn.ModuleList([nn.Linear(768, 2048) # moe_intermediate_size -> emb_dimfor _ in range(128) # num_experts])三、把功能分解为四个步骤
步骤一、将输入传递到gate层
输入通过线性层传递,值存储在分数下。
b, seq_len, embed_dim = x.shape # (b, seq_len, 2048)scores = self.gate(x) # (b, seq_len, 2048) -> (b, seq_len, 128)步骤二、MOE 函数
在这里,我们可以将两个不同的步骤视为一个,因为它们是独立的并且不会改变输入但提供决策(路由决策)。
步骤 2.1
- 从分数中检索topk分数和topk指数。(这里k=8)
- 将softmax应用于topk_scores。
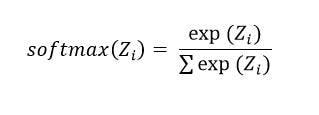
现在每组 8 个分数变成一个概率分布:
- 所有条目≥0
- 对于每个token,8 位专家的得分总和为 1。
# scores = (b, seq_len, 2048) -> (b, seq_len, 128)topk_scores, topk_indices = torch.topk(scores, 8, dim=-1)
topk_probs = torch.softmax(topk_scores, dim=-1)
# (b, seq_len, 128) -> (b, seq_len, 8)步骤 2.2
- 初始化所有零概率(b,seq_len,128)。
- 对于每个token,用softmaxed权重填充前8个位置。
- 循环后:每行(b,seq_len,128)恰好有8个非零(稀疏分布)。
gating_probs = torch.zeros_like(scores) # (b, seq_len, 128)for i in range(8):indices = topk_indices[..., i:i+1]# (b, seq_len, 1)prob = topk_probs[..., i:i+1]# (b, seq_len, 1)gating_probs.scatter_(dim=-1, index=indices, src=prob)# (b, seq_len, 1) -> (b, seq_len, 128)步骤三
对于每个专家 e:output = FC3 [e]( SiLU ( FC1 ) * FC2 )
所有输出都被附加和连接。
expert_outputs = []
for e in range(128):hidden = silu(self.fc1[e](x)) * self.fc2[e](x) # (b, seq_len, 2048) -> (b, seq_len, 768)out = self.fc3[e](hidden)# (b, seq_len, 768) -> (b, seq_len, 2048)expert_outputs.append(out.unsqueeze(-2))# (b, seq_len, 2048) -> (b, seq_len, 1, 2048)# Concatenate all experts: (b, seq_len, 1, 2048) -> (b, seq_len, 128, 2048)
expert_outputs = torch.cat(expert_outputs, dim=-2)步骤四
- 将专家输出乘以门控概率。
- 由于每个token只有8个专家具有非零权重,因此加权和仅涉及这些权重。
sum(dim=-2)折叠专家维度,每个令牌留下专家输出的混合。
# Weighted sum over experts
y = (gating_probs * expert_outputs).sum(dim=-2)
# (b, seq_len, 128, 2048) * (b, seq_len, 128, 1)
# gating_probs * expert_outputs : (b, seq_len, 128, 2048)
# sum over experts (dim=-2) : (b, seq_len, 2048)return y
# (b, seq_len, 2048), same as input embedding dimension