Week 12: 深度学习补遗:RNN与LSTM
文章目录
- Week 12: 深度学习补遗:RNN与LSTM
- 摘要
- Abstract
- 1. Recurrent Neural Network 循环神经网络
- 2. Elman Network和Jordan Network
- 3. Bidirectional RNN 双向RNN
- 4. Long Short-term Memory 长短期记忆存储
- 4.1 LSTM的实际操作的数据表示
- 4.2 LSTM在神经网络中的形态
- 总结
Week 12: 深度学习补遗:RNN与LSTM
摘要
本周继续跟随李宏毅老师的课程进行学习,主要对循环神经网络和长短期记忆进行了解和学习,了解其底层逻辑以及具体数学实现。除此之外,还对其奏效的原因和底层逻辑进行了一定程度的认识。
Abstract
This week, I took a course with Professor Hung-yi Lee on autoencoders and generative models, which are closely related. I mainly studied autoencoders from an abstract and mathematical perspective. The encoder-decoder architecture is a major mainstream structure in current models and is therefore important to learn. Studying autoencoders and generative models has given me a certain understanding of the encoder-decoder architecture.
1. Recurrent Neural Network 循环神经网络
RNN的一个典型应用是Slot Filling,即设置几个槽位(Slot),将句子的相应内容解析到对应的槽位。例如设置“Destination”、“Time of Arrival”两个槽位,对于“Arrive Taipei on November 2nd”这个句子,需要将“Taipei”解析到“Destination”中,“November 2nd”解析到“Time of Arrival”中。
| Destination | Time of Arrival |
|---|---|
| Taipei | November 2nd |
首先需要将句子嵌入成向量,可以通过1-of-N Encoding的方法或者词哈希等方法进行实现。但使用普通前馈神经网络时会出现一个问题,即对于两个句子“Arrive Taipei on November 2nd”和“Leave Taipei on November 2nd”,FNN会先处理“Arrive”和“Leave”再处理“Taipei”。对于这两个句子,FNN无法分辨“Taipei”在当前句子是出发地还是目的地,因为FNN没有记忆能力。
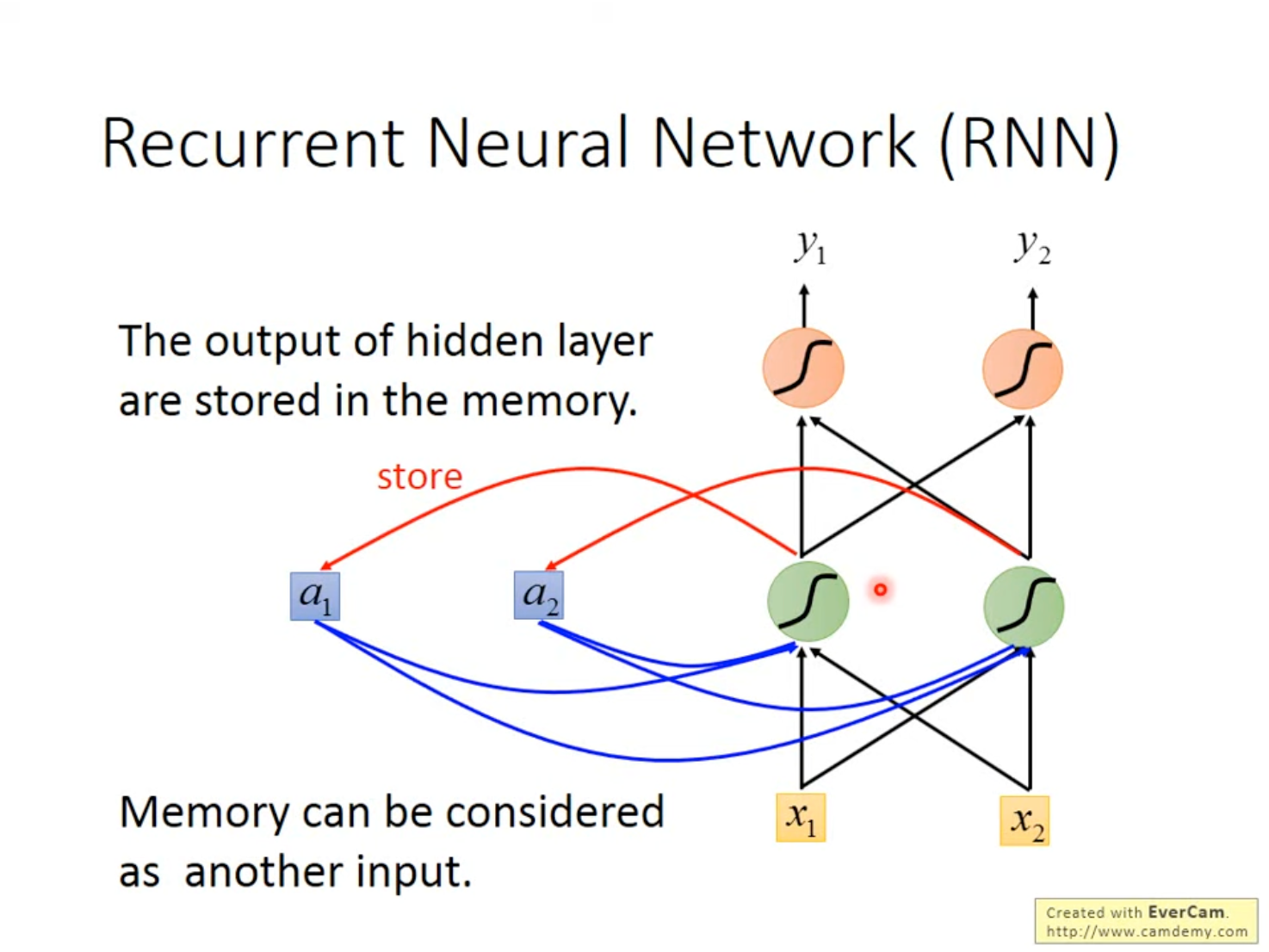
RNN的特点,在于增加了一个暂存模块,隐藏层的输出被存储在内存中,而内存作为一个另外的输入在下次输入进行时一并进行输入。需要注意的时候,在第一次训练时,Memory也必须要被初始化。
设想一个简单的RNN,其权重都被设置为1,无偏差,Memory初始化为0。
Input Sequence:[11][11][22]…Output Sequence:[44][1212][3232]…\text{Input Sequence:}\begin{bmatrix}1\\1\end{bmatrix}\begin{bmatrix}1\\1\end{bmatrix}\begin{bmatrix}2\\2\end{bmatrix} \dots \\ \text{Output Sequence:}\begin{bmatrix}4\\4\end{bmatrix}\begin{bmatrix}12\\12\end{bmatrix}\begin{bmatrix}32\\32\end{bmatrix} \dots\\ Input Sequence:[11][11][22]…Output Sequence:[44][1212][3232]…
对于第一个输入[11]\begin{bmatrix}1\\1\end{bmatrix}[11],第一个隐藏层的结果为[22]\begin{bmatrix}2\\2\end{bmatrix}[22],输出层的结果为[44]\begin{bmatrix}4\\4\end{bmatrix}[44],将输出层的结果存储到Memory中。
对于第二个输入[11]\begin{bmatrix}1\\1\end{bmatrix}[11],此时第一个隐藏层的结果为[22]+[44]=[66]\begin{bmatrix}2\\2\end{bmatrix} + \begin{bmatrix}4\\4\end{bmatrix}=\begin{bmatrix}6\\6\end{bmatrix}[22]+[44]=[66],输出层的结果为[1212]\begin{bmatrix}12\\12\end{bmatrix}[1212],同样将结果存储到Memory中。
对于第三个输入[22]\begin{bmatrix}2\\2\end{bmatrix}[22],第一个隐藏层的结果为[44]+[1212]=[1616]\begin{bmatrix}4\\4\end{bmatrix} + \begin{bmatrix}12\\12\end{bmatrix} = \begin{bmatrix}16\\16\end{bmatrix}[44]+[1212]=[1616],输出层就为[3232]\begin{bmatrix}32\\32\end{bmatrix}[3232],也存储到Memory中。
通过这种形式,输入的顺序就会影响输出的结果。
同理,将向量换成词向量,就可以表示句子理解中用前文影响后文理解的场景。
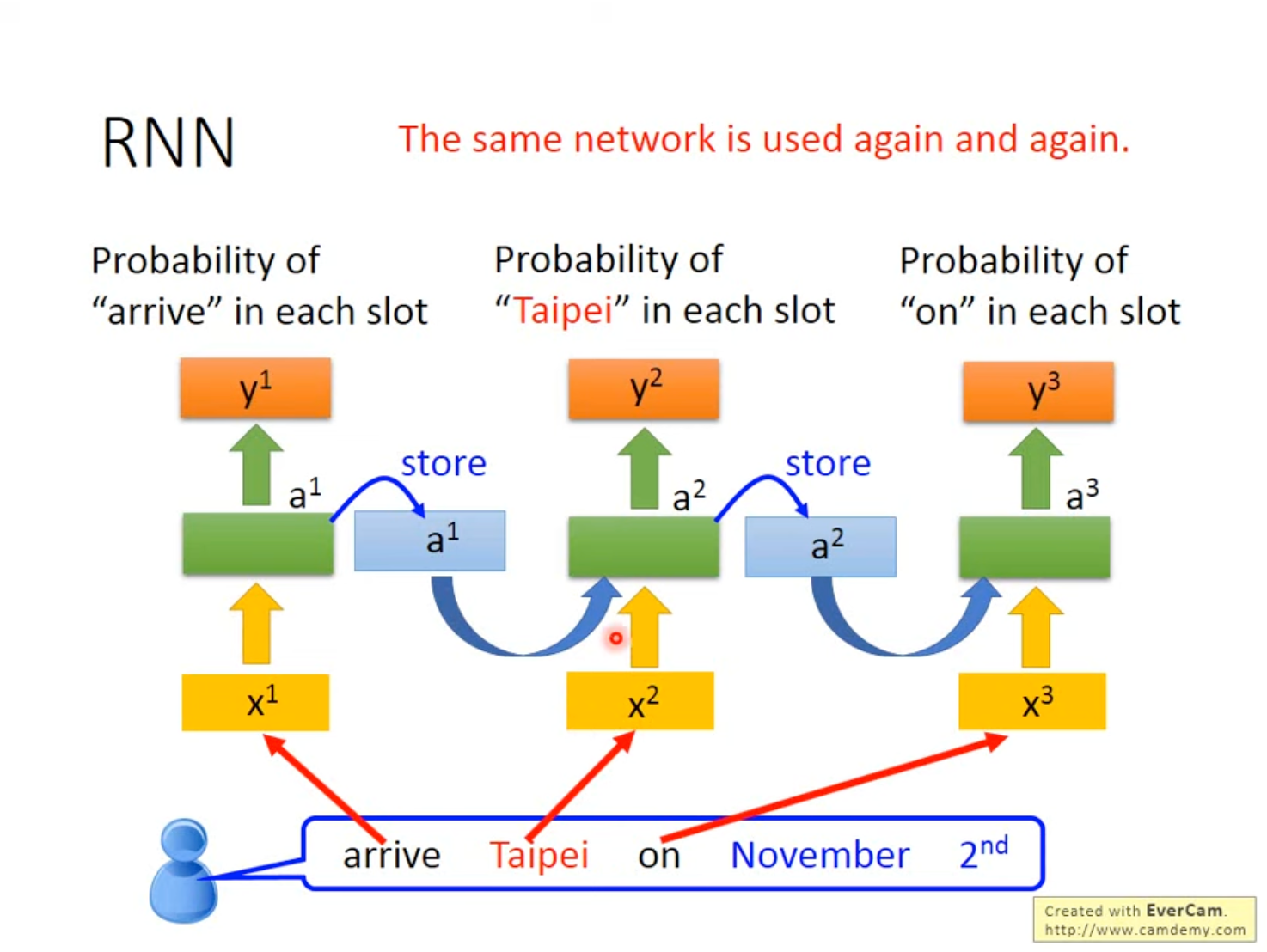
当然,RNN也可以变得更深,使用更多的层数使其网络结构变得复杂。
2. Elman Network和Jordan Network
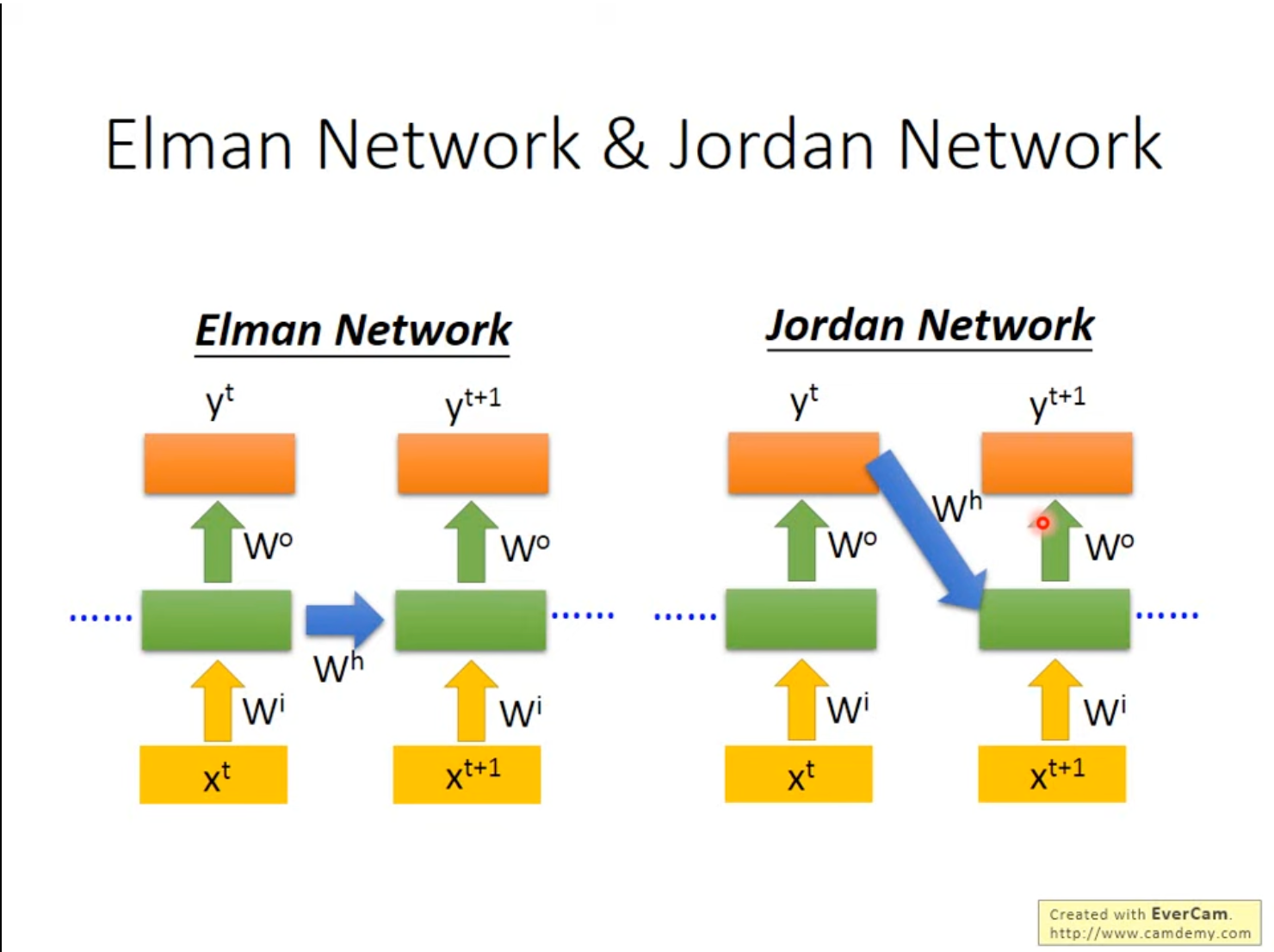
Elman Network和Jordan Network是两种RNN的不同结构,Elman Network将隐藏层的输出存到Memory中,Jordan Network将输出层的结果存储到Memory中。
通常情况下,Jordan Network的表现会更佳,主要是因为单个隐藏层并没有明确的训练目标,但整体的神经网络有一个明确的训练目标,保存输出层结果可以比较有效的保存上一次的状态,因此表现要更好一些。
3. Bidirectional RNN 双向RNN
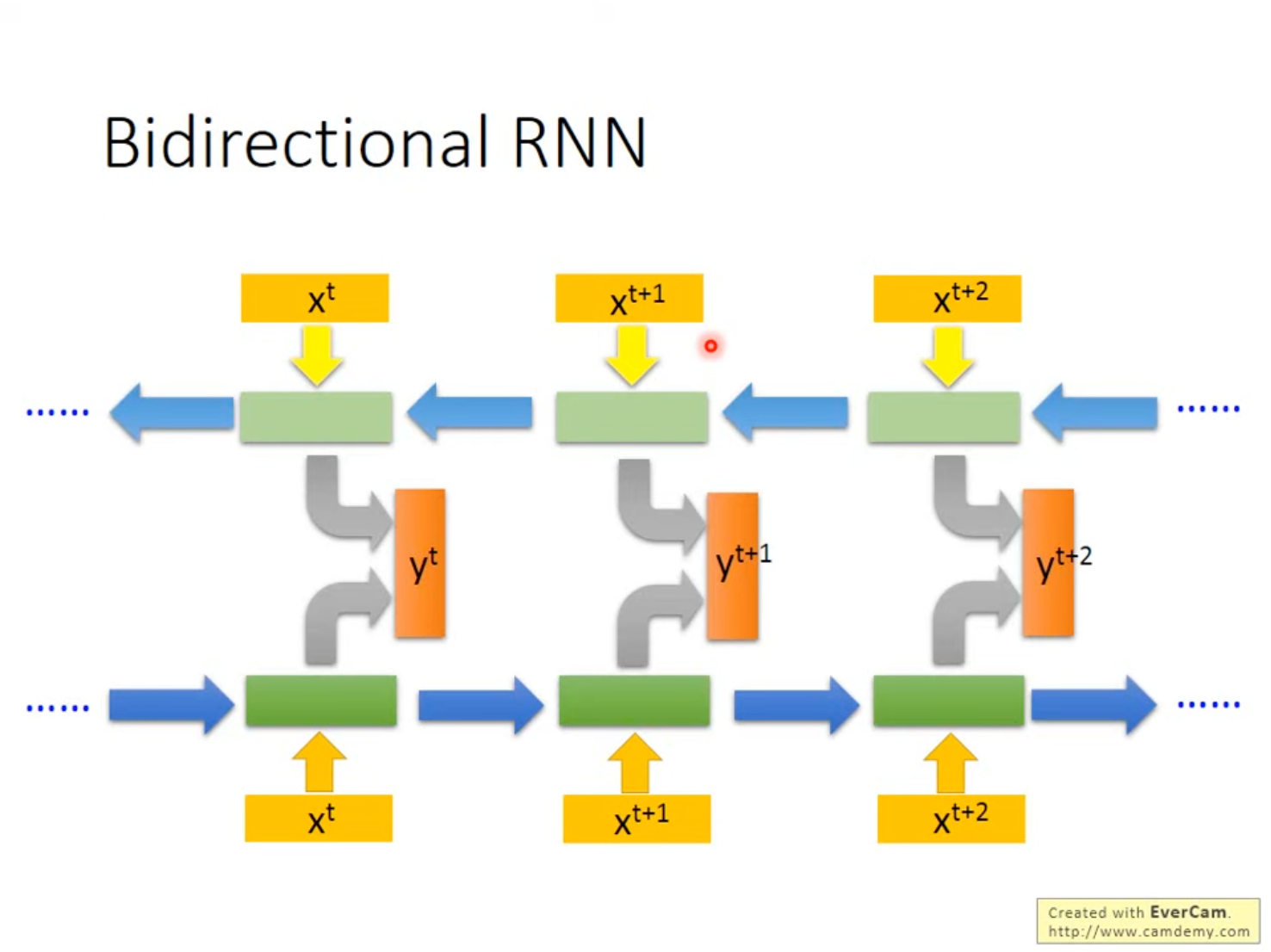
RNN可以是双向的,通过这种方式增加网络的感受野,即训练两个方向的RNN,使用两个RNN的隐藏层得到输出层。
这样可以使得在网络在看当前词汇的时候,不仅看过了前文,而且也看过了后文,即相当于RNN是在看完了前后文之后才进行的预测,因此其感受野更大,预测的依据更全面。
4. Long Short-term Memory 长短期记忆存储
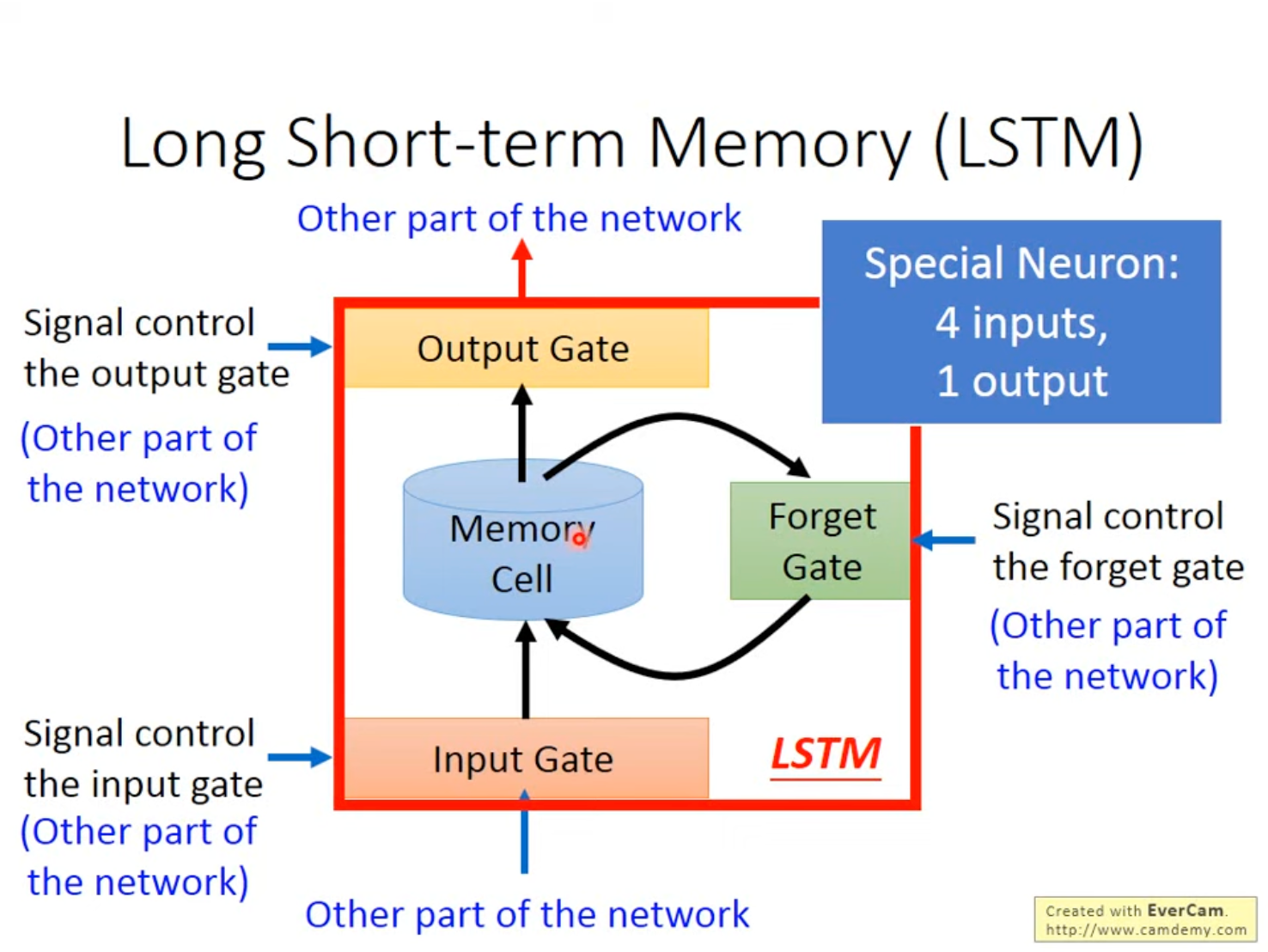
RNN的结构比较简单,可以任意的对Memory进行读写,并没有进行控制。LSTM是一种更流行的Memory管理方式,LSTM既能看到短期内前后文的影响,还能看到更久之前的前文的影响。
LSTM有3个门(Gate)和4个输入(3个门控制信号与一个Memory输入)、1个输出。
- Input Gate 输入门:当某个Neuron的输出想要被写入Memory Cell,需要先经过输入门,如果输入门处于关闭状态,则无法被写入。
- Output Gate 输出门:输出门决定了外界是否能从Memory中读出数据,当其关闭时,同样无法被读取。
- Forget Gate 遗忘门:遗忘门决定了何时遗忘Memory中的内容,何时进行保存。
所有的门的开关都是由神经网络学习到的。
4.1 LSTM的实际操作的数据表示
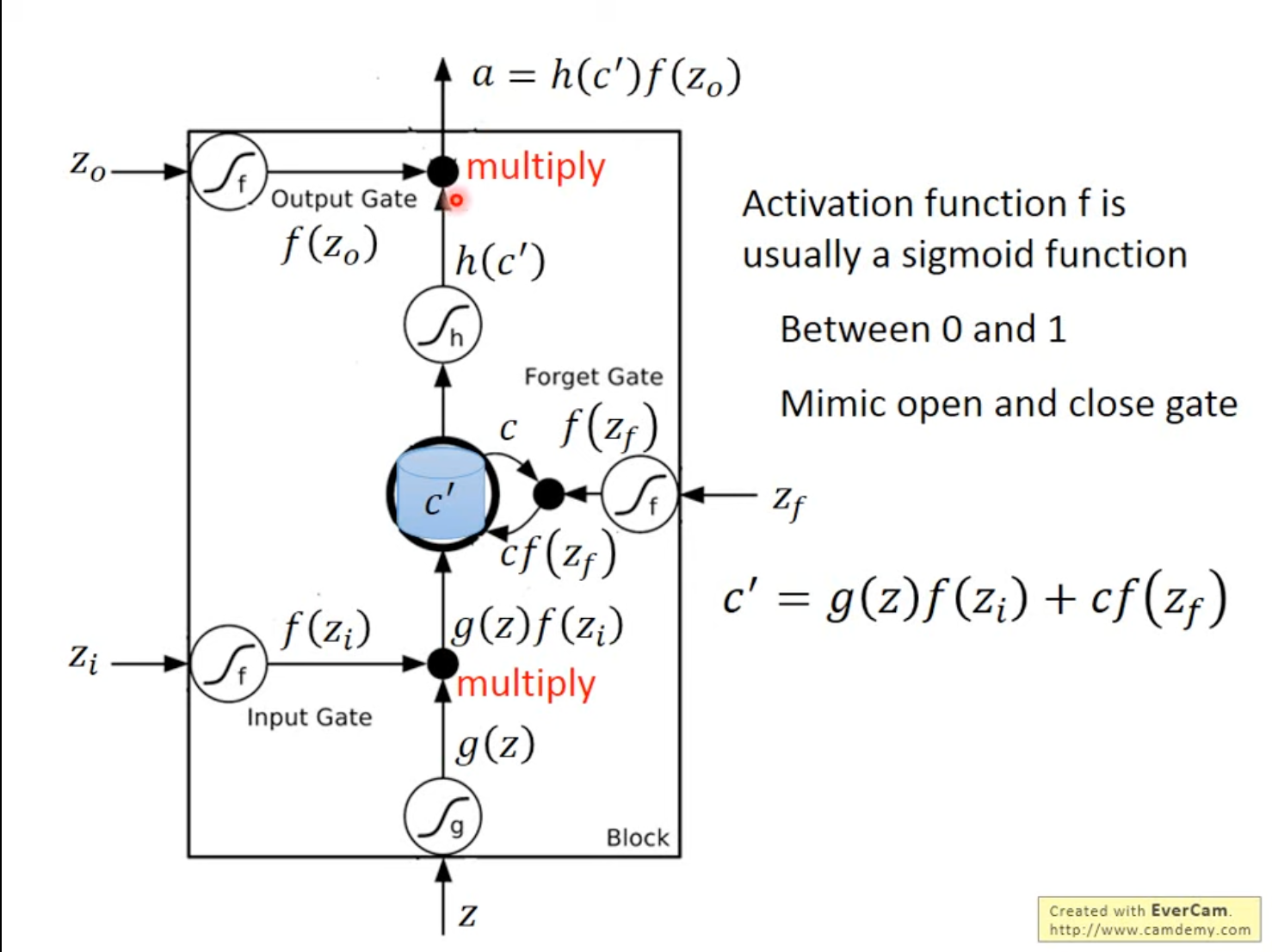
Input: z,zi,zf,zoc′‾Memory Input=g(z)‾Activated Inputf(zi)‾Input Gate+c‾Old Memoryf(zf)‾Forget Gatea‾Output=h(c′)‾Activated Memoryf(zo)‾Output Gate\text{Input: }z, z_i,z_f,z_o \\ \underset{\text{Memory Input}}{\underline{c'}}=\underset{\text{Activated Input}}{\underline{g(z)}}\underset{\text{Input Gate}}{\underline{f(z_i)}}+\underset{\text{Old Memory}}{\underline{c}}\underset{\text{Forget Gate}}{\underline{f(z_f)}} \\ \underset{\text{Output}}{\underline{a}}=\underset{\text{Activated Memory}}{\underline{h(c')}}\underset{\text{Output Gate}}{\underline{f(z_o)}} Input: z,zi,zf,zoMemory Inputc′=Activated Inputg(z)Input Gatef(zi)+Old MemorycForget Gatef(zf)Outputa=Activated Memoryh(c′)Output Gatef(zo)
4.2 LSTM在神经网络中的形态
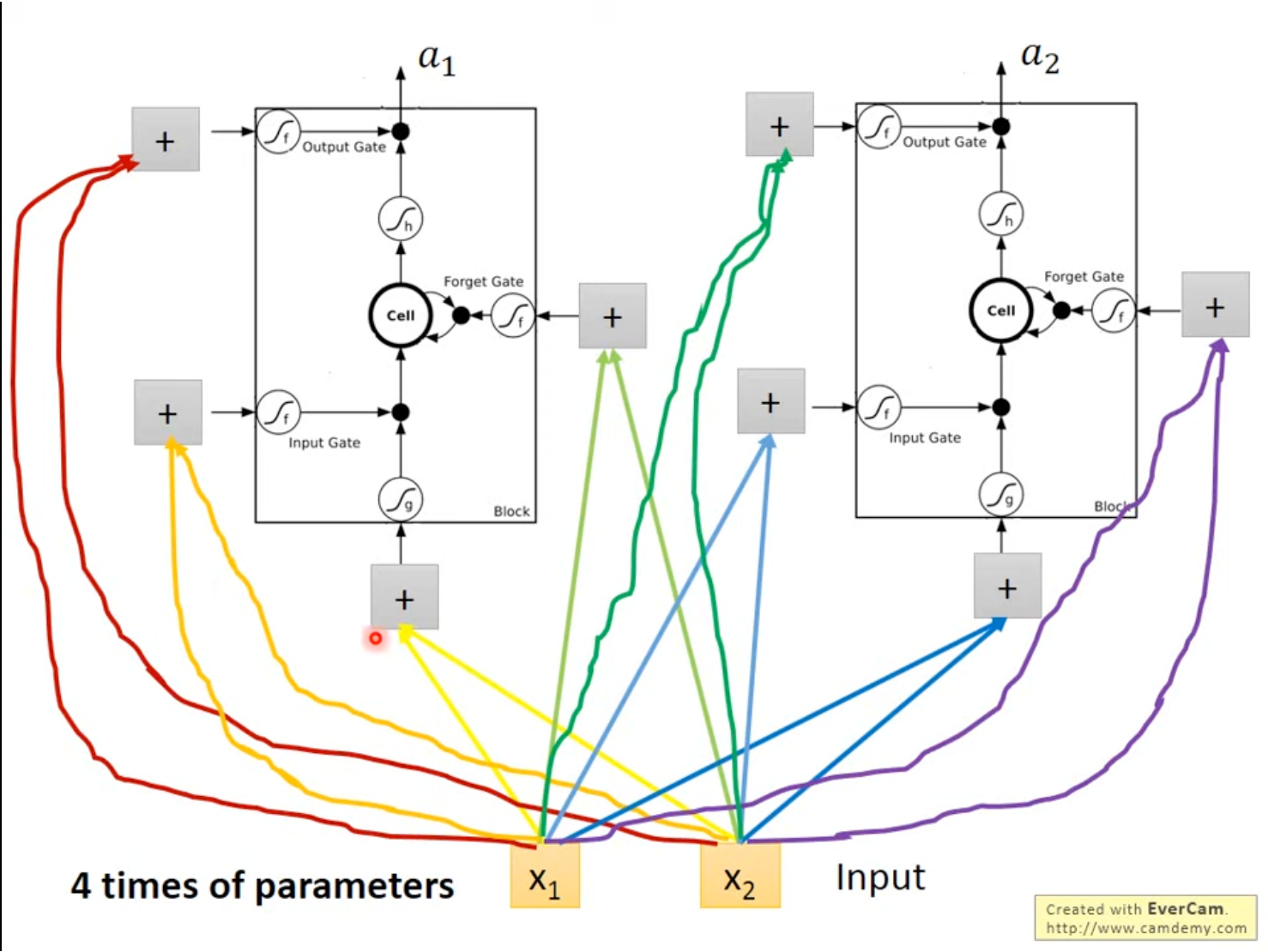
在神经网络中使用LSTM,只需要把LSTM模块看做一个神经元,把输入向量x⃗\vec{x}x简单输入到zzz、zfz_fzf、ziz_izi、zoz_ozo等进行学习,就可以完成LSTM的使用。
LSTM一般需要使用4倍的参数量。
总结
本周对循环神经网络和长短期记忆模块进行了一定的认识,学习了普通的循环神经网络如何让时间序列的前文影响后文,还了解了Elman Network、Jordan Network、双向RNN等几种变种。最后,还学习LSTM的数学表示和底层逻辑以及其应用在神经网络中的具体方式和形态。