Linux系统编程Day10 -- 进程管理
往期内容回顾
理解计算机的软硬件管理
gdb (linux)和lldb(macOS)调试工具
Git 教程(初阶)
基于Linux系统知识的第一个程序
一、从数据结构的角度理解计算机软硬件的管理
用数据结构的思维去理解计算机软硬件管理,你会发现它其实就是一套数据组织与调度策略的综合应用。
1、为什么可以用数据结构来理解软硬件管理?
操作系统的所有管理动作(无论是硬件资源还是软件任务),归根到底就是维护一批数据结构:
-
这些数据结构用来描述资源状态(CPU、内存、磁盘、进程等)
-
操作系统通过增删改查和调度算法对这些数据进行管理
-
资源本身是“实体”,数据结构是它们的抽象表示
也就是说,操作系统是“资源状态表 + 操作算法”的集合。
2、硬件管理中的数据结构
| 硬件资源 | 常用数据结构 | 用途 |
|---|---|---|
| CPU | 队列(Queue) | 就绪队列(ready queue)存储等待运行的进程;阻塞队列存储等待 I/O 的进程 |
| 内存 | 位图(Bitmap)、链表(Linked List)、页表(Page Table) | 记录内存分配情况,分页/分段映射虚拟地址到物理地址 |
| 磁盘 | 链表/数组 + 栈(Stack) | 磁盘空闲块管理表、I/O 请求队列 |
| 网络 | 环形缓冲区(Circular Buffer)、队列 | 数据包缓冲、发送与接收队列 |
3、软件管理中的数据结构
| 软件对象 | 常用数据结构 | 用途 |
|---|---|---|
| 进程管理 | 进程控制块(PCB,结构体/表格) + 队列 | 存储进程 ID、状态、寄存器、调度优先级等 |
| 线程管理 | 线程控制块(TCB) | 保存线程的上下文信息 |
| 文件系统 | 树(Tree) | 目录结构是典型的树形结构 |
| 用户管理 | 哈希表(Hash Table) | 存储用户名、密码散列、权限映射 |
| 权限控制 | 位掩码(Bit Mask) | 存储 rwx 权限 |
| 软件包管理 | 有向图(Graph) | 表示软件依赖关系(节点是包,边是依赖) |
4、管理的本质(数据结构视角)
从数据结构的眼光看,软硬件管理的本质是:
维护一套动态数据集合,通过合适的算法在时间和空间上高效、安全地分配资源。
这可以分为三步:
-
抽象表示(建模)
用合适的数据结构(表、队列、树、图)来表示硬件资源和软件对象。
-
状态维护(更新)
随着任务执行,实时修改这些结构(比如进程切换就更新就绪队列和阻塞队列)。
-
策略调度(算法)
根据管理目标(高效、公平、实时等)选择合适的调度策略(FIFO、优先级、LRU 等)。
5、例子:从数据结构看一次进程调度
假设我们要运行多个任务:
-
建模 → 每个进程用 PCB 结构体表示,放到就绪队列(queue)
-
调度 → 调度器选择队首进程,分配 CPU(时间片轮转就是队列出队/入队)
-
状态变化 → 如果进程等待 I/O,就从就绪队列移到阻塞队列;I/O 完成再回到就绪队列
从外面看是“进程运行”,从里面看就是数据结构的元素在不同队列之间迁移。
6、总结
-
硬件管理 → 关注物理资源的抽象(位图、链表、队列、页表)
-
软件管理 → 关注逻辑对象的抽象(树、图、哈希表、结构体)
-
本质 → 一套基于数据结构和算法的资源建模、状态更新与调度过程
二、从硬件到操作系统再到用户指令
1、分层结构总览(从下到上)
-
硬件层(Hardware Layer)
-
处理器(CPU):执行指令集(ISA),提供寄存器、算术逻辑单元(ALU)、控制单元等
-
内存(RAM、缓存):存放数据与指令
-
I/O设备:硬盘、显示器、网卡、USB等
-
总线系统:CPU与外设之间的通信通道
-
指令集架构(ISA):CPU可执行的机器指令规范(如 x86、ARM、RISC-V)
-
-
固件与驱动层(Firmware & Drivers)
-
固件(Firmware):BIOS/UEFI 等,负责上电自检、初始化硬件、引导操作系统
-
设备驱动(Device Driver):操作系统与硬件之间的翻译器,将高层操作转成硬件能懂的指令(如磁盘读写、显卡渲染)
-
-
操作系统内核层(Operating System Kernel)
-
硬件抽象层(HAL):封装硬件访问接口,让上层不必关心具体硬件细节
-
资源管理:
-
进程管理(调度、同步、通信)
-
内存管理(虚拟内存、页表、分配与回收)
-
文件系统(目录结构、文件权限)
-
设备管理(通过驱动统一访问外设)
-
-
系统调用接口(Syscall Interface):提供给用户空间程序访问内核功能的入口(如 open()、read()、write()、fork())
-
-
系统调用与运行时库层(Syscall & Runtime Libraries)
-
系统调用(System Call):
-
用户程序通过陷入(trap)指令从用户态切换到内核态
-
典型调用:文件操作、进程管理、网络通信
-
-
标准库(如 libc):对系统调用进行封装,提供更易用的 API(printf()、malloc()等)
-
-
用户空间应用与接口层(User Space Applications & Interfaces)
-
命令行接口(CLI):如 Bash、Zsh,用户通过文本命令与系统交互
-
图形用户界面(GUI):如 Windows 桌面、Linux GNOME/KDE
-
应用程序:浏览器、IDE、数据库等
-
-
用户操作层(User Interaction)
-
用户输入指令(键盘、鼠标、触屏)
-
系统执行相应任务并输出结果(文本输出、图形渲染、声音等)
-
2、数据流 & 控制流路径
以用户输入命令 ls 为例:
用户层:在终端中键入 ls + 回车
-
Shell(CLI):解析命令 → 调用 execve() 系统调用
-
系统调用接口:用户态切入内核态,执行加载程序的逻辑
-
内核:
-
从文件系统(驱动 → 硬盘)读取 /bin/ls
-
创建进程(分配 PID、初始化 PCB)
-
加载 ELF 文件到内存,建立虚拟内存映射
-
-
驱动程序:调度磁盘、内存、显示器等硬件
-
CPU 执行机器指令:运行 ls 程序,读取当前目录内容
-
系统调用返回:结果数据传回 Shell
-
终端显示:字符流通过驱动 → 显卡 → 显示器输出
3、分层作用总结表
| 层级 | 主要任务 | 面向对象 |
|---|---|---|
| 硬件层 | 提供计算、存储、I/O能力 | 驱动、固件 |
| 驱动层 | 抽象硬件、提供统一接口 | 操作系统内核 |
| 操作系统层 | 资源管理、进程调度、安全控制 | 应用程序 |
| 系统调用层 | 提供用户态访问内核的入口 | 标准库、运行时 |
| 用户空间接口层 | 提供人机交互(CLI/GUI) | 用户 |
| 用户层 | 发出指令、获取结果 | —— |
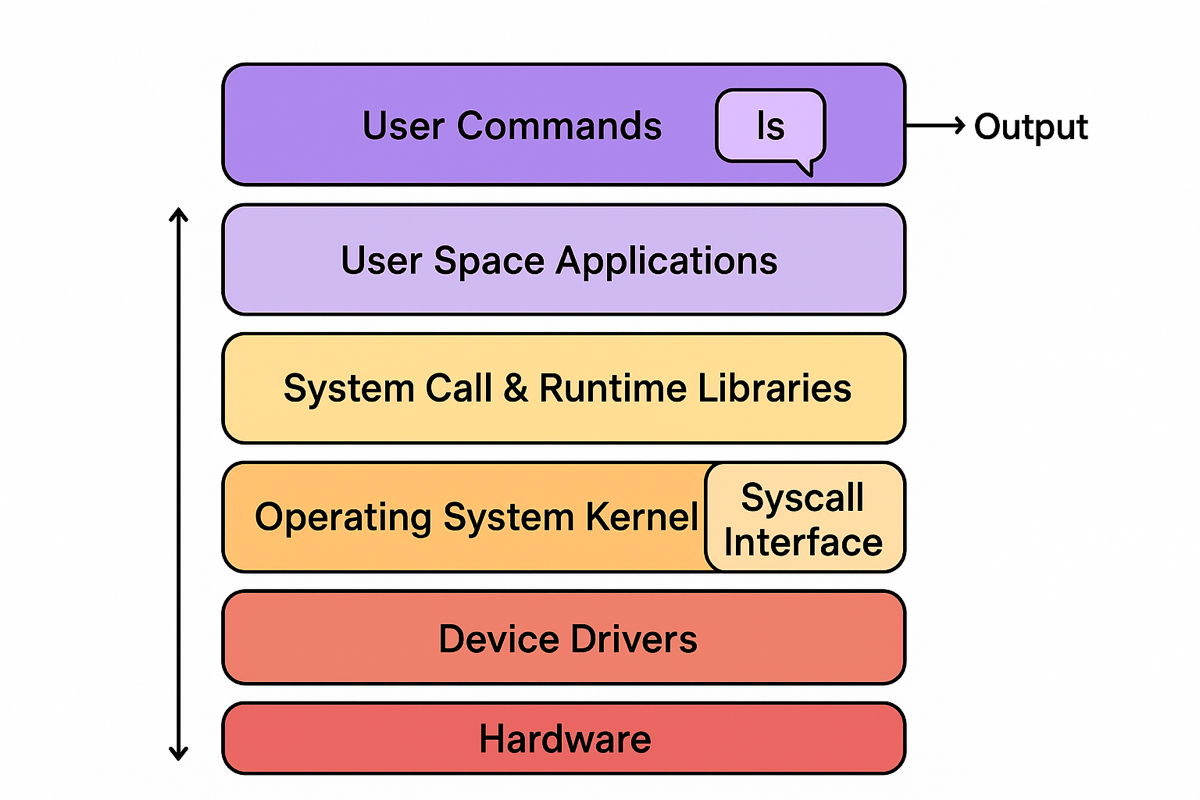
四、整体架构示意图
┌──────────────────────────┐
│ 用户指令/操作 │ ← 用户敲命令或点击
├──────────────────────────┤
│ 用户空间应用(CLI/GUI)│
├──────────────────────────┤
│ 标准库 & 系统调用接口层 │
├──────────────────────────┤
│ 操作系统内核(进程、 │
│ 内存、文件、设备管理)│
├──────────────────────────┤
│ 驱动程序(磁盘、网卡、 │
│ 显卡、输入设备等) │
├──────────────────────────┤
│ 硬件抽象层(CPU、内存、│
│ I/O控制器) │
└──────────────────────────┘
三、什么是进程
进程是操作系统把硬件资源和程序结合起来,为用户任务提供一个独立运行环境的机制。它是软硬件交互的核心枢纽。
1. 进程的本质
-
程序:硬盘上的一组静态指令和数据(比如一个 .exe、/bin/ls)。
-
进程:操作系统把程序加载到内存后,配上运行所需的 CPU、内存、I/O 等资源,就变成了一个“活着的”任务——这就是进程。
程序是静态的,进程是动态的。
2. 进程与操作系统的关系
操作系统要解决三个核心问题:
-
让多个进程可以同时运行(哪怕只有一个 CPU)
-
公平分配资源(不能让一个进程霸占 CPU/内存)
-
防止相互干扰(安全隔离)
这三个目标对应三个主要机制:
-
进程调度(Scheduling):谁先用 CPU,谁后用?
-
进程切换(Context Switching):怎么快速换人?
-
进程同步与通信(Synchronization & IPC):怎么安全合作?
其实操作系统对进程的调度、切换、等待,本质就是在一堆数据结构里做增删查改,只不过这些结构要保证高效和安全。
1. 进程控制块(PCB,Process Control Block)
核心数据结构,操作系统管理进程的“身份证 + 档案袋”。
数据结构上:
struct PCB {
int pid; // 进程ID
int state; // 状态:就绪、运行、阻塞...
int priority; // 优先级
CPUContext context; // 寄存器、PC、栈指针等CPU上下文
MemoryInfo mem_info; // 内存分配信息
FileTable files; // 打开的文件列表
QueueNode *queue_ptr; // 在调度队列中的位置
};
本质:一个结构体(struct)
作用:调度器切换进程时,只需在 PCB 中保存/恢复上下文
2. 数据结构的综合运用(进程的调度流程)
假设有一个进程正在运行(运行队列),I/O 请求发生后:
-
调度器把该进程的 PCB 从就绪队列(优先队列/链表)中删除
-
插入到阻塞队列(链表)
-
当 I/O 完成时,通过事件唤醒,将 PCB 从阻塞队列取出,再放回就绪队列
-
调度器从就绪队列取出下一个进程(可能用堆、链表等),恢复其 PCB 中保存的上下文,继续执行
整个过程就像:
-
多个队列(链表/堆)之间搬运 PCB
-
调度器是总管,负责搬运和挑选
-
PCB 记录进程的全部状态,保证搬来搬去还能接着运行
3. 进程与硬件管理的联系
-
CPU:进程获得 CPU 时间片后执行指令(机器码 → 控制硬件)
-
内存:进程运行时需要自己的内存空间(代码段、数据段、堆、栈)
-
I/O 设备:进程需要通过系统调用访问磁盘、网络、显示器等硬件
-
硬件隔离:操作系统利用内核态/用户态和内存保护机制防止进程直接乱改硬
进程是操作系统把硬件资源打包给用户任务的方式。
4. 进程、线程与多任务
-
进程:独立资源空间,开销大
-
线程:同一进程内共享资源,开销小
-
多任务本质上是操作系统快速切换进程,让你觉得它们同时运行
5. 进程与软件管理
-
软件的安装只是把程序放到硬盘
-
软件的运行就是操作系统把程序变成进程
-
软件的多开(如开两个浏览器窗口)就是创建多个进程
6、查看系统调用进程
这里我们定义了一个c语言程序如下:
#include <stdio.h> #include <unistd.h>int main(){while(1){printf("I am a process!");sleep(1);} }这是一个死循环的程序,一旦执行起来无法退出,这样方便我们查看系统调用的进程模块。
那么如何查看呢,输入以下指令:
ps ajx | head -1 && ps ajx | grep "myproc.o"这样就会显示系统目前执行的相关程序
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
149084 149814 149814 149084 pts/0 149814 S+ 0 0:00 ./myproc.o
149829 149968 149967 149829 pts/1 149967 S+ 0 0:00 grep --color=auto myproc.o
这里介绍一下常用的查看系统进程的命令
ps -ef # 查看所有进程(标准格式) ps aux # 以 BSD 格式查看所有进程 ps -ejH # 以树状结构显示进程关系如果想实时查看进程,可以用:
top # 实时刷新 htop # 更友好(需要安装)2. 查看指定进程
例如想找 nginx 相关的进程:
ps -ef | grep nginx或者查某个 PID(比如 1234):
ps -fp 1234如果想通过名字查 PID:
pgrep nginx如何理解: PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
列名
含义
PPID
Parent Process ID:父进程 ID。谁启动了这个进程
PID
Process ID:进程 ID,全局唯一
PGID
Process Group ID:进程组 ID,用于信号广播等(一个进程组可包含多个相关进程)
SID
Session ID:会话 ID,一个会话可包含多个进程组(登录 shell 会启动一个会话)
TTY
与进程关联的终端(tty,pts/0 表示第一个伪终端),? 表示无终端(后台进程)
TPGID
Terminal foreground process group ID:前台进程组 ID(与终端交互的进程组)
STAT
进程状态(State),常见值:
R:Running(运行中)
S:Sleeping(可中断睡眠)
D:不可中断睡眠(等待 I/O)
T:Stopped(暂停)
Z:Zombie(僵尸进程)
后缀含义:
+ 前台进程
s 会话首进程
l 多线程
< 高优先级
N 低优先级 |
| UID | 用户 ID(拥有该进程的用户) |
| TIME | 占用 CPU 的总时间(用户态+内核态) |
| COMMAND | 启动进程的命令及参数 |
💡 进程层级关系理解:
PPID = 1 表示这个进程的父进程是 init/systemd(可能原父进程已退出,被 init 接管)
同一个 PGID 的进程可以一起被 kill -PGID 终止
同一个 SID 的进程共享一个控制终端
在程序中输出程序运行时的PID号
#include <stdio.h> #include <unistd.h> #include <sys/types.h> int main(){while(1){printf("I am a process,my PID is: %d\n",getpid()); sleep(1);} }输出描述:
I am a process,my PID is: 150252
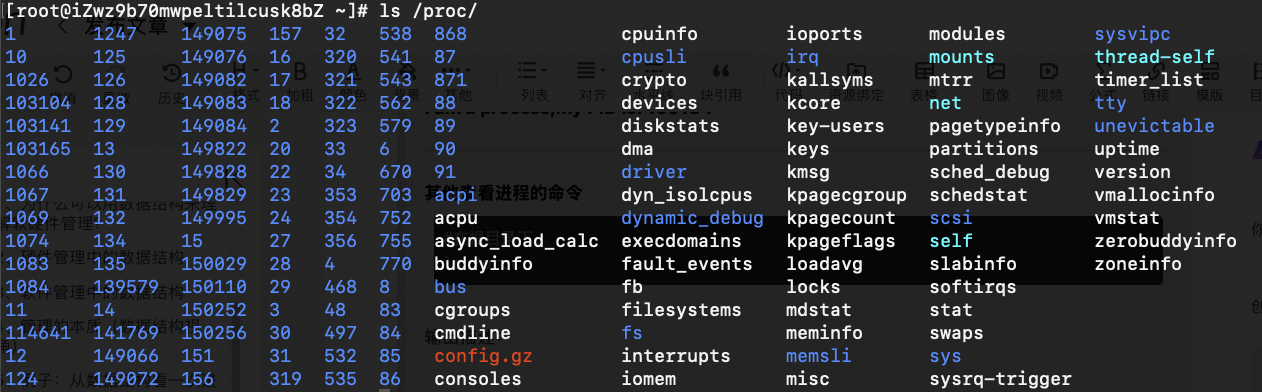
其他查看进程的命令
#在根目录下 ls /proc输出描述:
你可看到很多蓝色颜色的数字的文件夹,其中有我们之前运行程序的pid号 150252
我们可以使用如下命令进行进程的回收
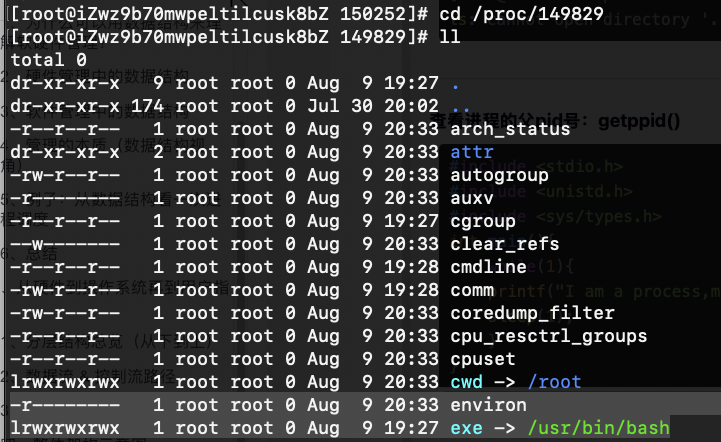
ls /proc/150252 -d列出这个目录,然后cd 进去你会看到一下:
然后你会看到里面有个exe的文件,
ls -l exelrwxrwxrwx 1 root root 0 Aug 9 20:05 exe -> /root/myproc.o
你可看到这个可执行程序指向的是磁盘的myproc.o文件
然后如果我们删除这个程序 myproc.o--> rm myproc.o 会阻止这个进程吗?
lrwxrwxrwx 1 root root 0 Aug 9 20:05 exe -> '/root/myproc.o (deleted)'你会发现这里的exe显示已经被删除了,但是这个进程仍然在运行!
只有当我们按下 ctrl+c,进程才真正被终止了 --> 150252这个文件夹也就消失了!
[root@iZwz9b70mwpeltilcusk8bZ 150252]# ll ls: cannot open directory '.': No such process
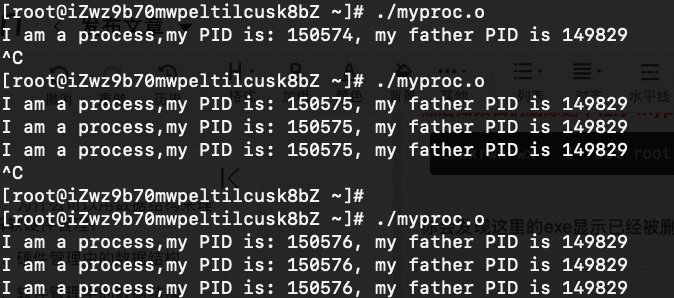
查看进程的父pid号:getppid()
#include <stdio.h> #include <unistd.h> #include <sys/types.h> int main(){while(1){printf("I am a process,my PID is: %d, my father PID is %d\n",getpid(),getppid()); sleep(1);} }输出描述:
你会发现每次执行程序,程序的pid号都会变化,但是对应的父进程不会发生变化。
你会发现父进程对应的是bash。

7、fork创建子进程(简单了解)
1. fork() 是什么?
-
fork() 是 Unix/Linux 系统调用,用于创建一个新进程(子进程)。
-
调用一次,返回两次:
-
在 父进程中返回子进程的 PID(正数)
-
在 子进程中返回 0
-
如果创建失败,返回 -1(只在父进程中返回)
-
fork()之后,会有子进程和父进程一起进行。后续的代码将会被父进程和子进程共享一起执行(并发/并行编程)。
关键特性:
-
子进程是父进程的几乎完全拷贝(代码段、数据段、堆、栈等)
-
父子进程的执行流会继续往下运行,但它们的返回值不同
-
父子进程的 PID 不同,内核用 PCB(进程控制块) 分开管理
2、验证fork创建子进程
#include <stdio.h> #include <unistd.h> #include <sys/types.h> int main(){fork();printf("I am process, my pid is: %d, my father pid is %d\n",getpid(),getppid());sleep(1);//while(1){ //printf("I am a process,my PID is: %d, my father PID is %d\n",getpid(),getppid());//sleep(1);//} }输出结果:
I am process, my pid is: 150711, my father pid is 150427
I am process, my pid is: 150712, my father pid is 150711
150427--> bash
3、fork的返回值
-
在 父进程中返回子进程的 PID(正数)
-
在 子进程中返回 0
-
如果创建失败,返回 -1(只在父进程中返回)
#include <stdio.h> #include <unistd.h> #include <sys/types.h>int main() {pid_t pid;pid = fork(); // ?~H~[建?~P??[??K[?~Kif (pid < 0) {perror("fork failed");return 1;} else if (pid == 0) {// 父进程printf("Child process PID=%d, Father process PPID=%d, The returned ID = %d\n", getpid(), getppid(),pid);} else {// 子进程printf("Child process PID=%d, Father process PPID=%d The returned ID = %d\n", getpid(), getppid(),pid); } return 0;输出描述:
Child process PID=150924, Father process PPID=150427 The returned ID = 150925
Child process PID=150925, Father process PPID=150924, The returned ID = 0
PPID --> bash, PID 150924 是 bash的子进程, PID150925 是150924的子进程。
ID150925表示这fork调用前的父进程,ID = 0 是fork产生的子进程。
4. 原理(数据结构视角)
父进程调用 fork() → 内核为子进程创建一个新的 PCB
内核复制父进程的大部分资源信息到子进程(写时复制 COW 技术,节省内存)
返回值不同:
父进程的 fork() 返回新建子进程的 PID
子进程的 fork() 返回 0
父子进程继续执行 fork() 之后的代码(从同一个指令位置继续,但进程不同)
5. 常见用法
(1) 创建并区分父子进程逻辑
if (pid == 0) {// 子进程的任务 } else {// 父进程的任务 }(2) 创建多个子进程
循环调用 fork() 可以生成多个子进程(注意避免重复创建导致“爆炸”)
(3) 与 exec() 配合
父进程 fork 子进程,子进程调用 exec() 加载新程序(shell、服务器进程等)
进程是程序的“活体”,fork() 是它的“复制术”,复制出一个独立的执行实体,父子进程可并行运行。