深度学习的优化⽅法
深度学习的优化⽅法
1.梯度下降算法【回顾】

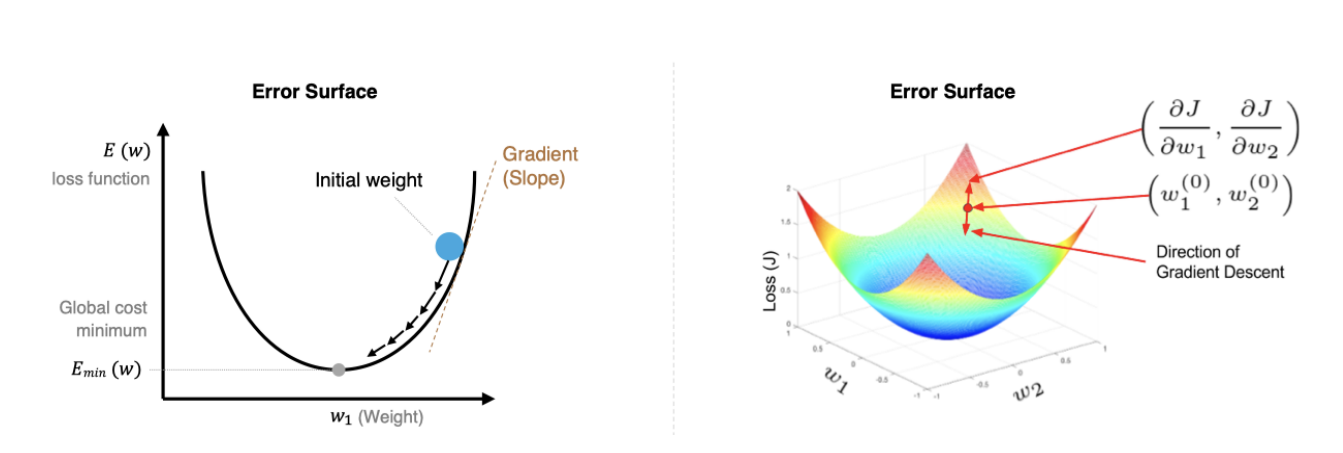
| 梯度下降算法 | 定义 | 缺点 | 优点 |
| BGD(批量梯度下降) | 每次迭代时需要计算每个样本上损失函数的梯度并求和 | 计算量大、迭代速度慢 | 全局最优化 |
| SGD(随机梯度下降) | 每次迭代时只采集一个样本(或一小部分样本),计算这个样本损失函数的梯度并更新参数 | 准确度下降、存在噪音、非全局最优化 | 训练速度快、支持在线学习 |
| MBGD(小批量梯度下降) | 每次迭代时,我们随机选取一小部分训练样本来计算梯度并更新参数 | 准确度不如BGD、非全局最优解 | 计算小批量数据的梯度更加高效、支持在线学习 |
tf.keras.optimizers.SGD(learning_rate=0.01, momentum=0.0, nesterov=False, name=
)# 导⼊相应的⼯具包
import tensorflow as tf
# 实例化优化⽅法:SGD
opt = tf.keras.optimizers.SGD(learning_rate=0.1)
# 定义要调整的参数
var = tf.Variable(1.0)
# 定义损失函数:⽆参但有返回值
loss = lambda: (var ** 2)/2.0
# 计算梯度,并对参数进⾏更新,步⻓为 `- learning_rate * grad`
opt.minimize(loss, [var]).numpy()
# 展示参数更新结果
var.numpy()# 1-0.1*1=0.9
0.9| 名词 | 定义 |
| Epoch | 使用训练集的全部数据对模型进行一次完整训练,被称之为“一代训练” |
| Batch | 使用训练集中的一小部分样本对模型权重进行一次反向传播的参数更新,这一小部分样本被称为“一批数据” |
| Iteration | 使用一个 Batch 数据对模型进行一次参数更新的过程,被称之为“一次训练” |
| 梯度下降方式 | Training Set Size | Batch Size | Number of Batches |
| BGD | N | N | 1 |
| SGD | N | 1 | N |
| Mini-Batch | N | B | N/B+1 |
- 每个 Epoch 要训练的图⽚数量:50000
- 训练集具有的 Batch 个数:50000/256+1=196
- 每个 Epoch 具有的 Iteration 个数:196
- 10个 Epoch 具有的 Iteration 个数:1960
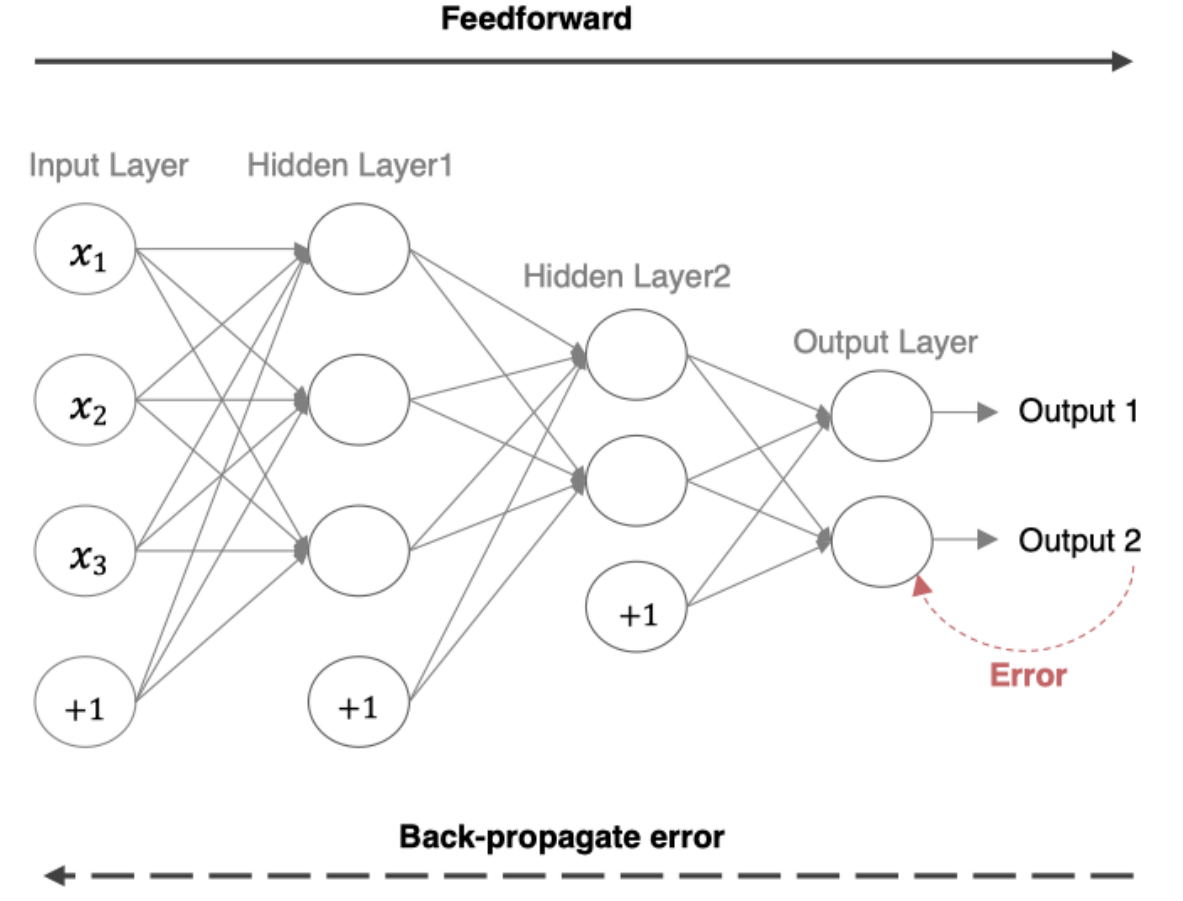
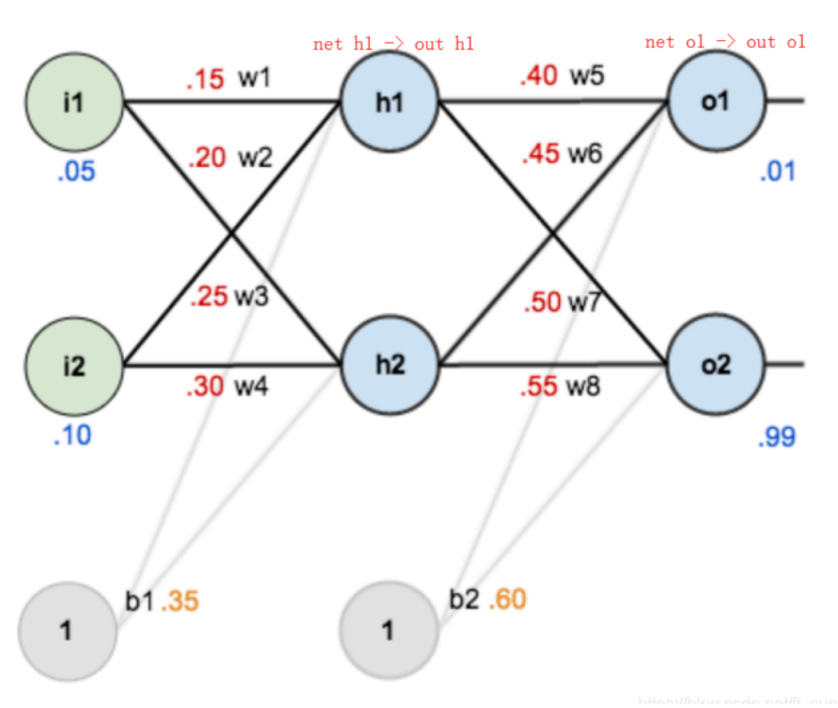
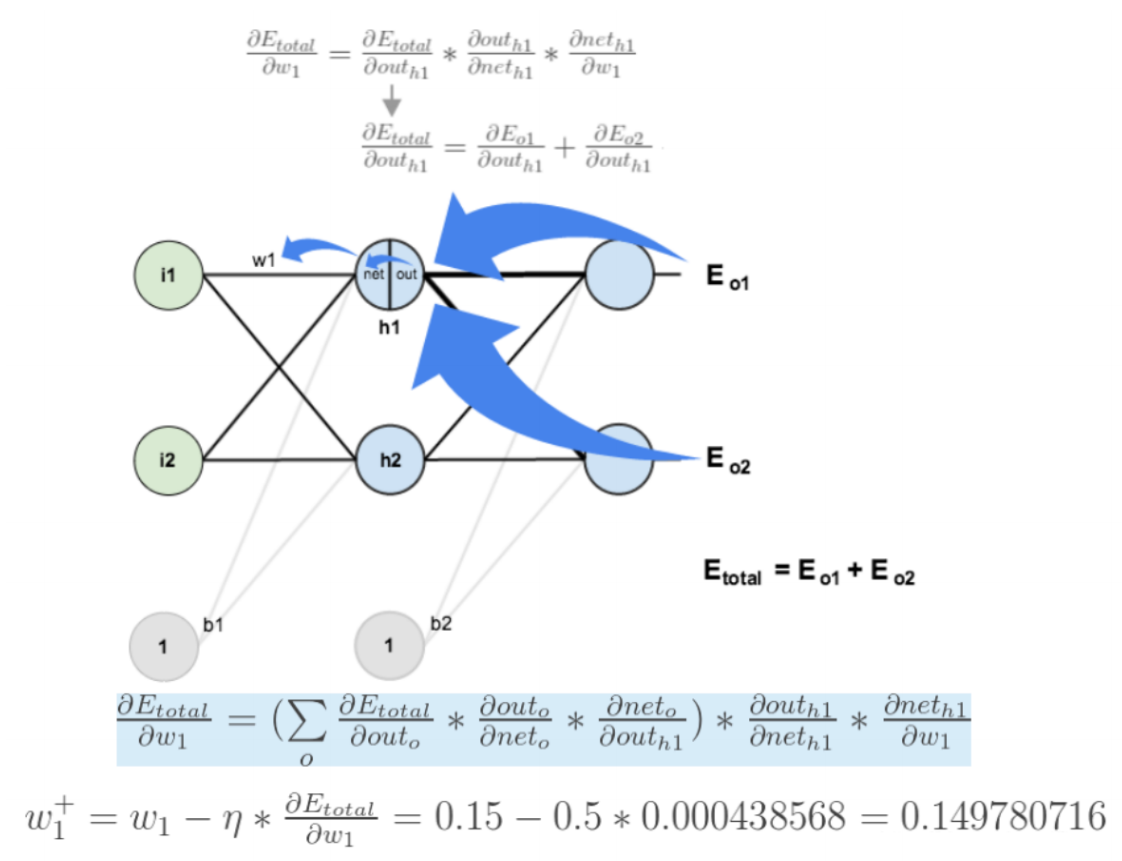
2.反向传播算法(BP算法)
2.1 前向传播与反向传播
2.2 链式法则
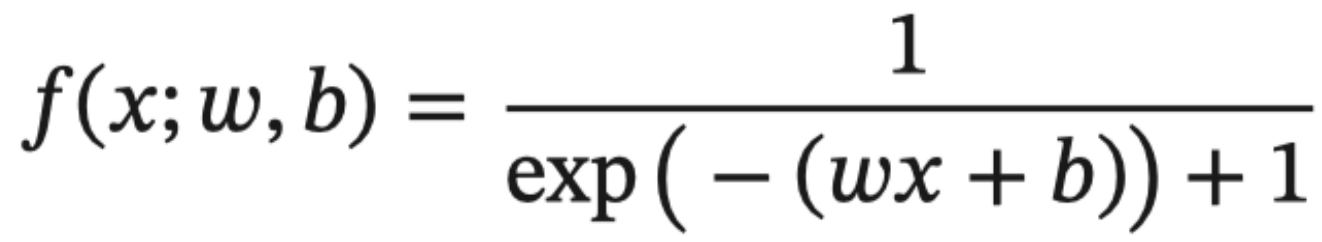

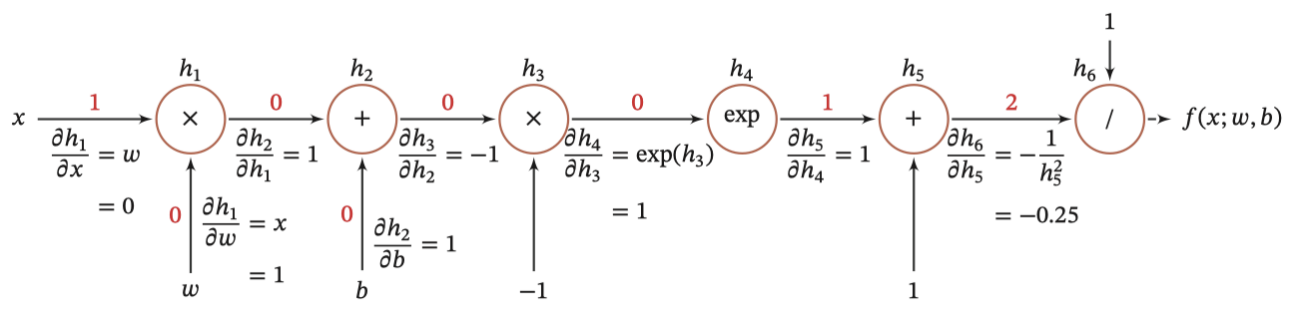
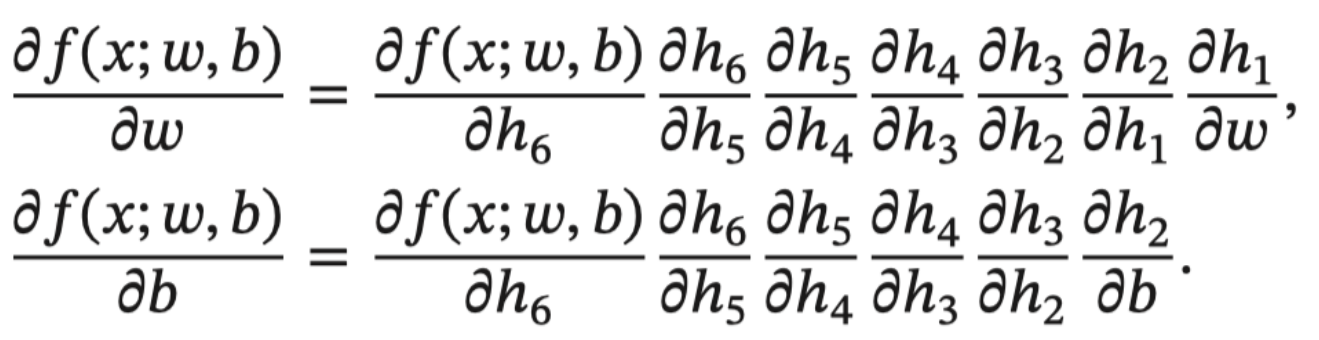
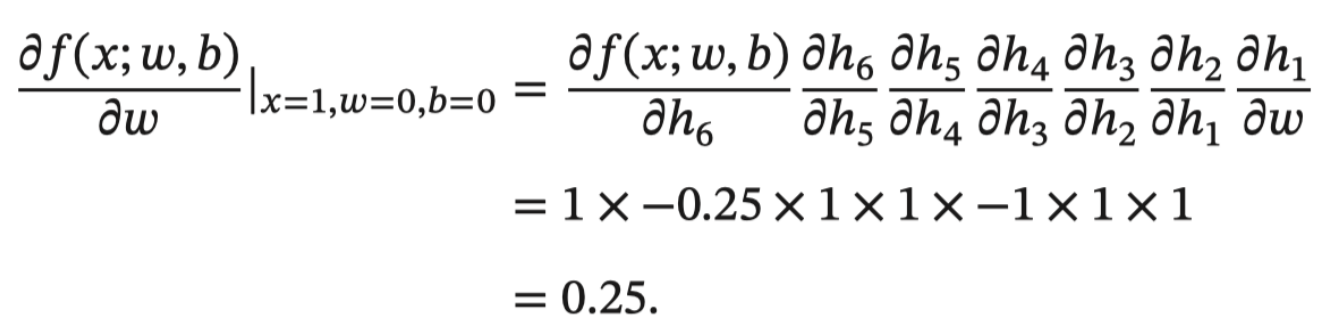

2.3 反向传播算法
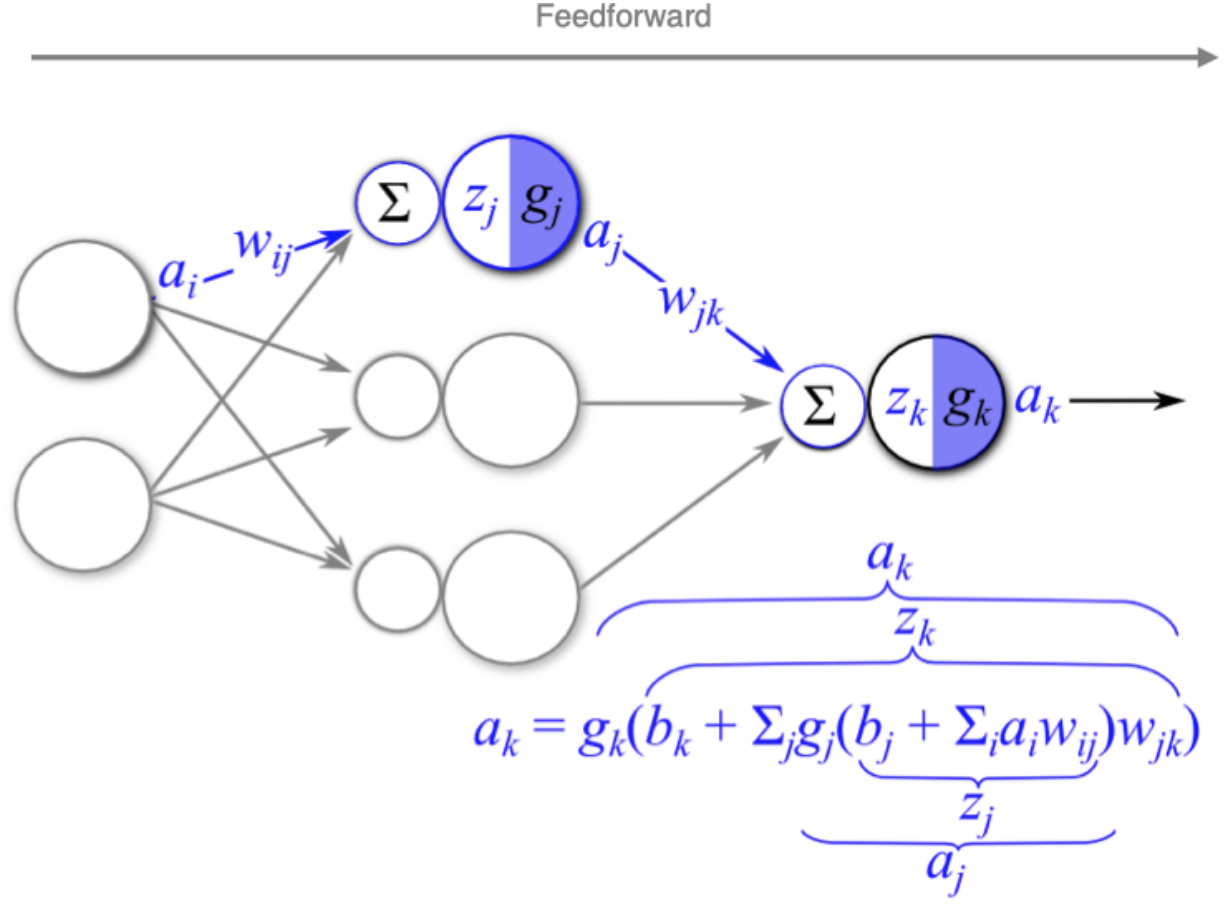
- 计算损失函数,并进⾏反向传播:
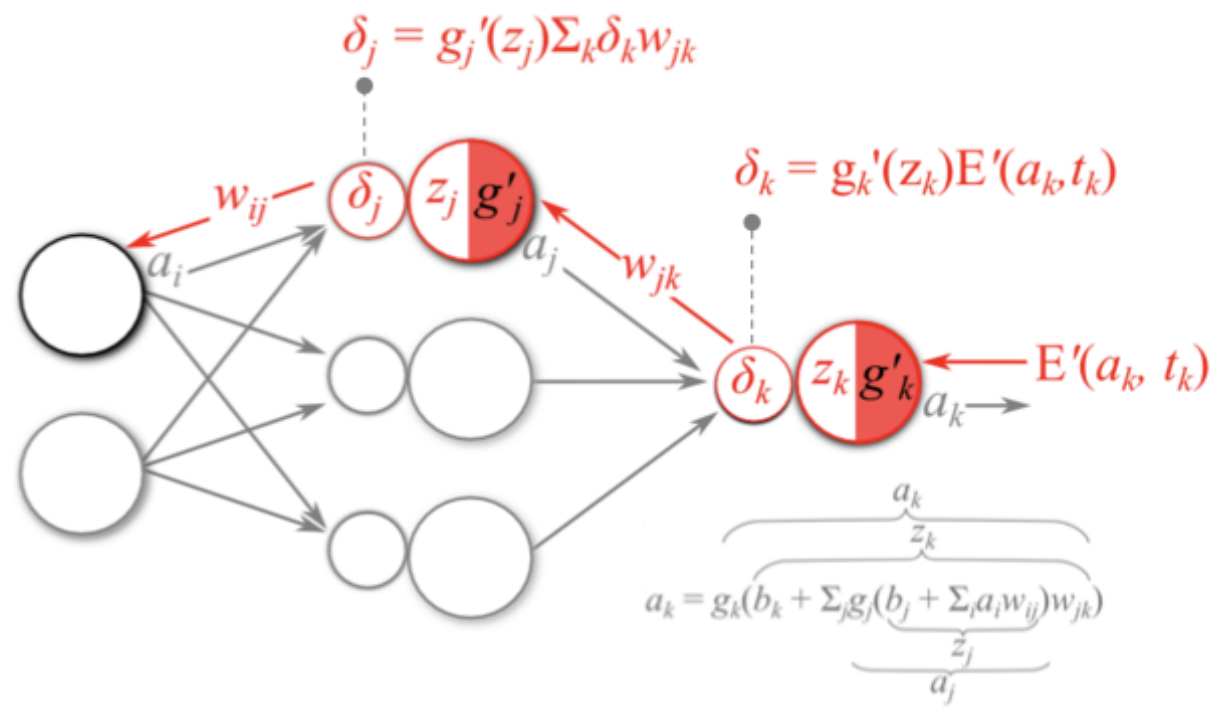
- 计算梯度值:
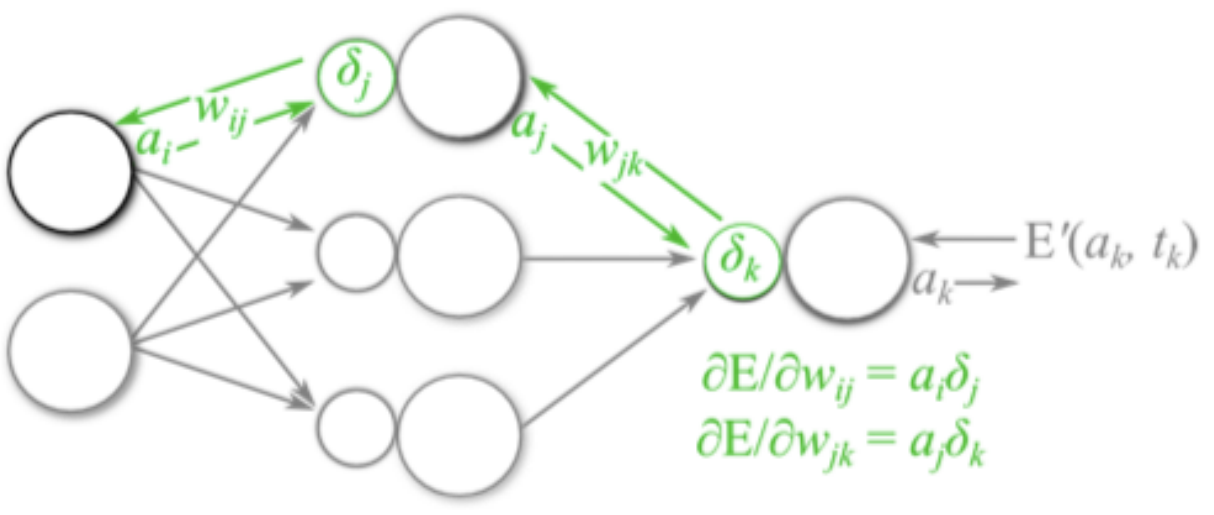
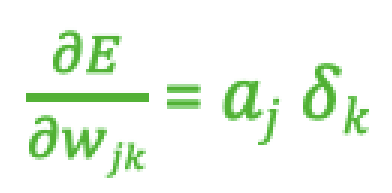
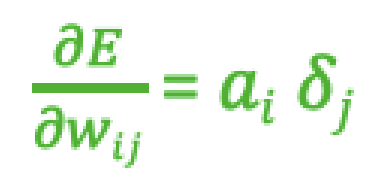
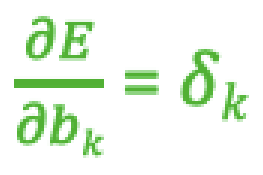
- 参数更新:
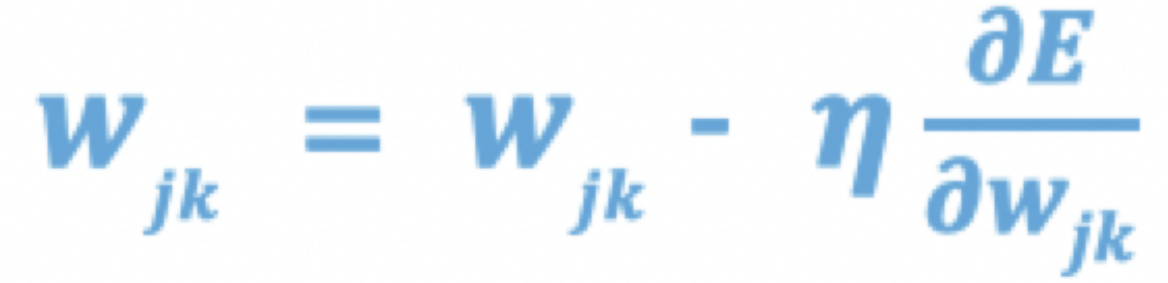
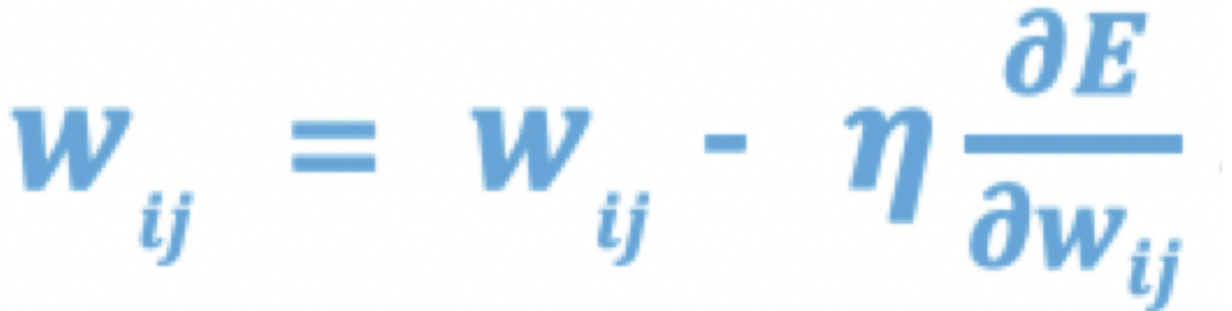
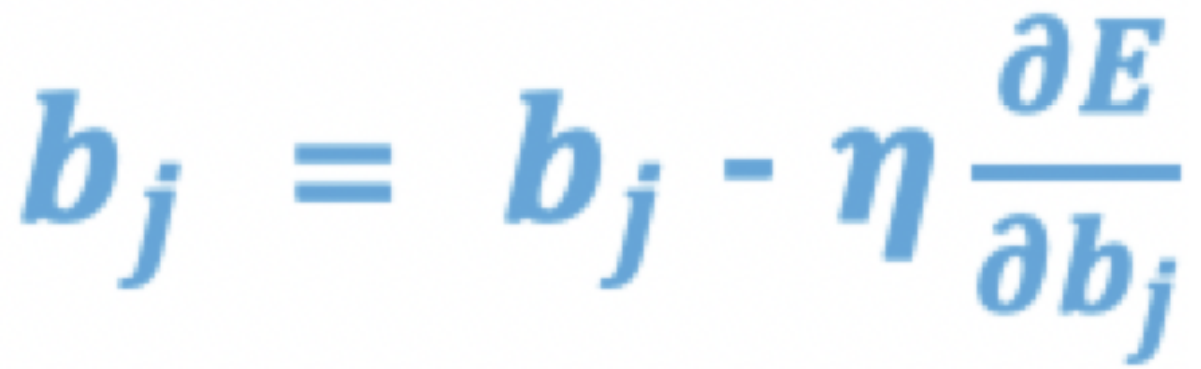




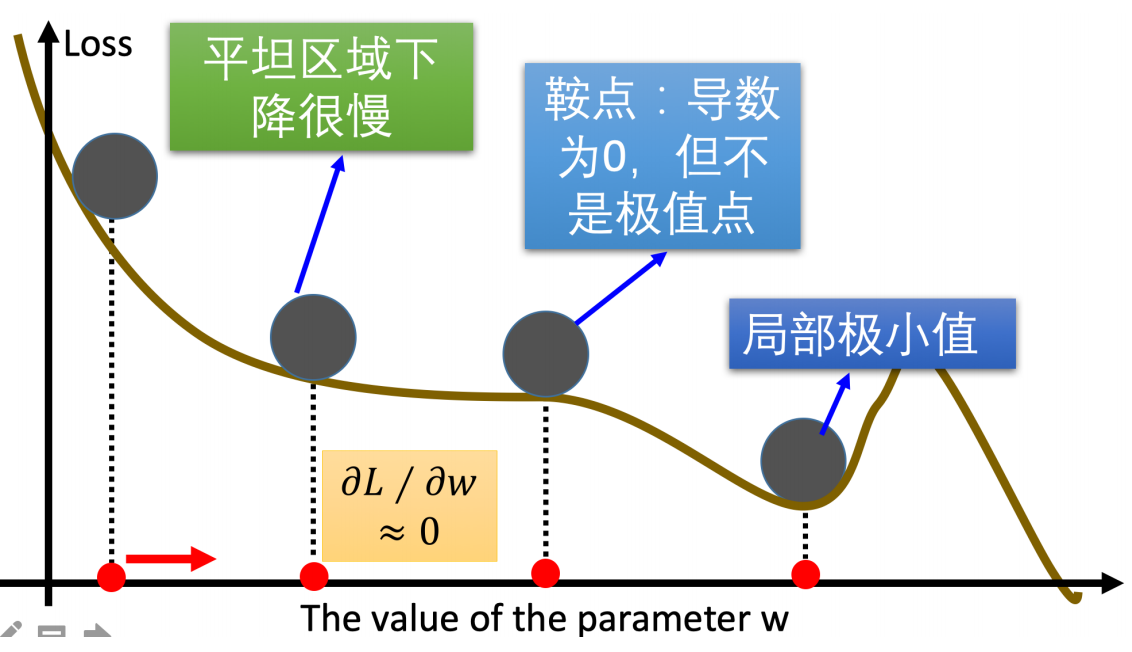
3.梯度下降优化⽅法
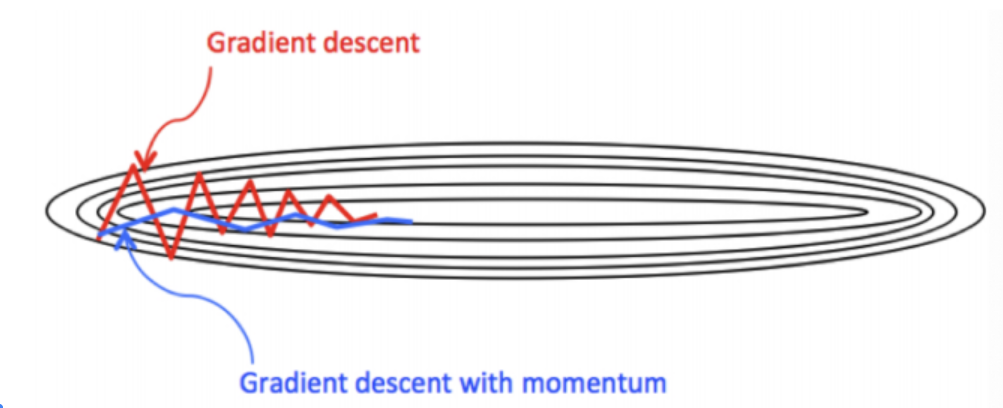
3.1 动量算法(Momentum)
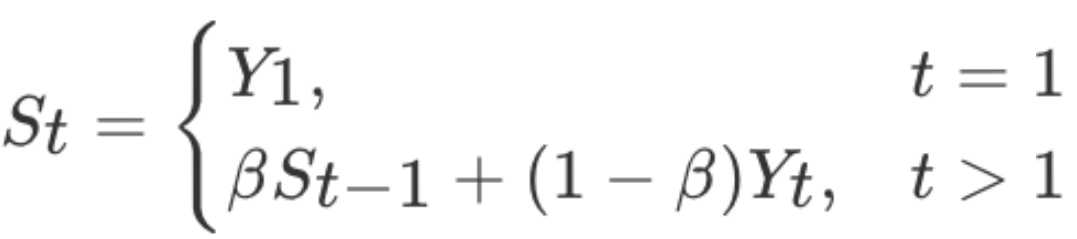
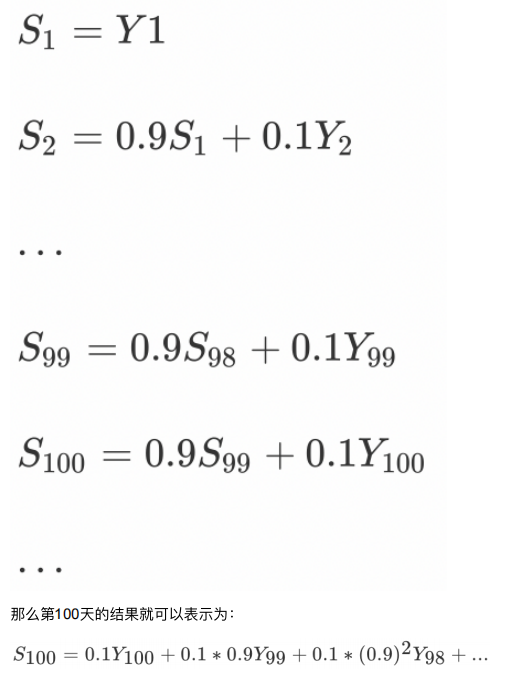
import torch
import matplotlib.pyplot as plt
ELEMENT_NUMBER = 30
#1. 实际平均温度
def test01():# 固定随机数种子torch.manual_seed(0)# 产生30天的随机温度temperature = torch.randn(size=[ELEMENT_NUMBER,]) * 10print(temperature)# 绘制平均温度days = torch.arange(1, ELEMENT_NUMBER + 1, 1)plt.plot(days, temperature, color='r')plt.scatter(days, temperature)plt.show()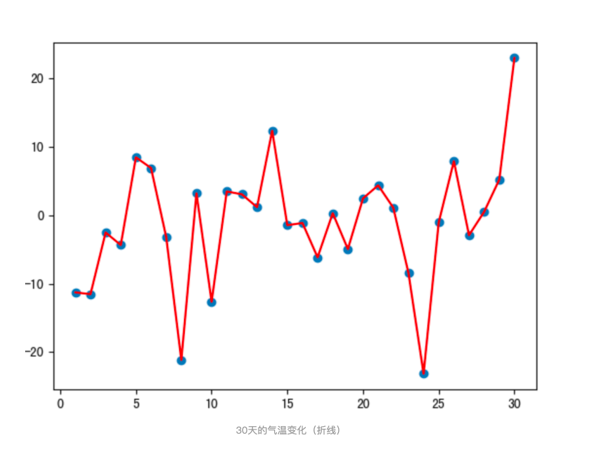
#2. 指数加权平均温度
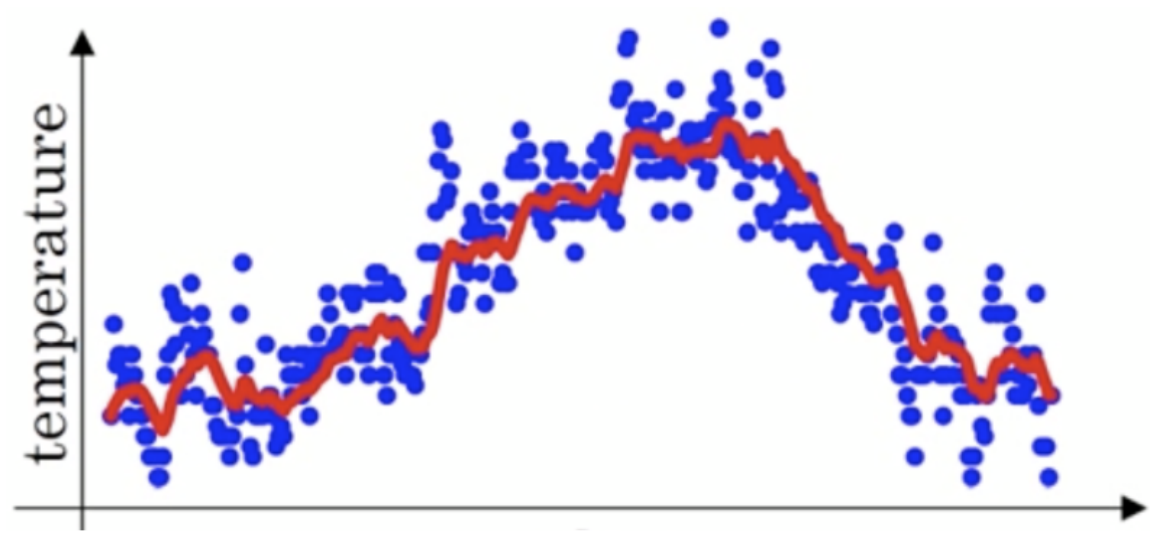
def test02(beta=0.9):# 固定随机数种子torch.manual_seed(0)# 产生30天的随机温度temperature = torch.randn(size=[ELEMENT_NUMBER,]) * 10print(temperature)exp_weight_avg = []# idx从1开始for idx, temp in enumerate(temperature, 1):# 第一个元素的 EWA 值等于自身if idx == 1:exp_weight_avg.append(temp)continue# 第二个元素的 EWA 值等于上一个 EWA 乘以 β + 当前气温乘以 (1-β)# idx-2:2-2=0,exp_weight_avg列表中第一个值的下标值new_temp = exp_weight_avg[idx - 2] * beta + (1 - beta) * tempexp_weight_avg.append(new_temp)days = torch.arange(1, ELEMENT_NUMBER + 1, 1)plt.plot(days, exp_weight_avg, color='r')plt.scatter(days, temperature)plt.show()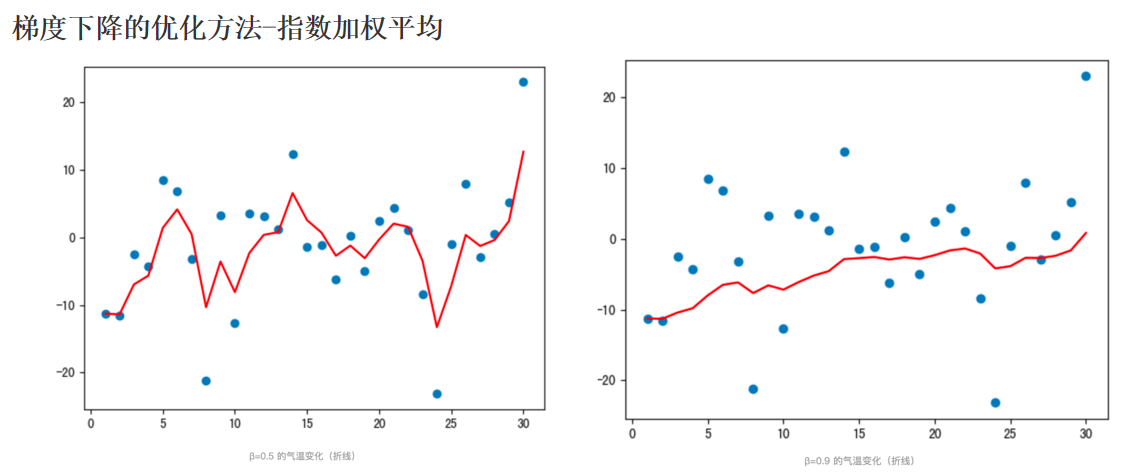
动量梯度下降算法
- s_t是当前时刻指数加权平均梯度值
- s_t-1是历史指数加权平均梯度值
- g_t是当前时刻的梯度值
- β 是调节权重系数,通常取 0.9 或 0.99
- η是学习率
- w_t是当前时刻模型权重参数
- w 表示初始梯度
- g 表示当前轮数计算出的梯度值
- s 表示历史梯度移动加权平均值
- Wt:当前时刻模型权重参数
- St:当前时刻指数加权平均梯度值
- η:学习率
api
def test01(): # 1 初始化权重参数 w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32) loss = ((w ** 2) / 2.0).sum() # 2 实例化优化方法:SGD 指定参数beta=0.9 (momentum指定加权的权数)# 创建优化器,将 w 放在一个列表中optimizer = torch.optim.SGD([w], lr=0.01, momentum=0.9) # 3 第1次更新 计算梯度,并对参数进行更新 optimizer.zero_grad() loss.backward() optimizer.step() print('第1次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy())) # 4 第2次更新 计算梯度,并对参数进行更新 # 使用更新后的参数机选输出结果 loss = ((w ** 2) / 2.0).sum() optimizer.zero_grad() loss.backward() optimizer.step() print('第2次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))
3.2 AdaGrad
- 初始化学习率 η、初始化参数w、小常数 σ = 1e-10
- 初始化梯度累计变量 s = 0
- 从训练集中采样 m 个样本的小批量,计算梯度gt
- 累积平方梯度: st = s(t-1) + gt ⊙ gt,⊙ 表示各个分量相乘
- 学习率 η 的计算公式如下:

- 权重参数更新公式如下:
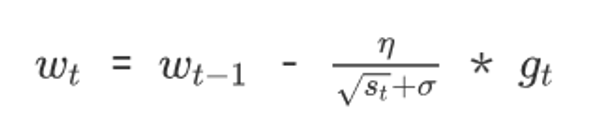
- 重复 3-7 步骤
- 优点
- 自适应学习率,适合稀疏数据。
- 不需要手动调整学习率。
- 缺点
- 学是可能会使得学习率过早、过量的降低,导致模型训练后期学习率太小,较难找到最优解。
- 需要存储历史梯度的平方,可能增加内存消耗
api:
| 参数名 | 参数解释 | 解释 |
| params | 需要优化的参数列表。可以是一个张量列表,例如 [w],或者通过模型的parameters() 方法获取的参数 | |
| lr | 学习率 | 默认值为 0.01。这是全局学习率,Adagrad 会根据参数的历史梯度动态调整每个参数的学习率。 |
| lr_decay | 学习率衰减 | 默认值为 0。用于控制学习率的衰减率。在每次参数更新后,学习率会按照lr / (1 + lr_decay * t) 的方式衰减,其中 t 是迭代次数。 |
| weight_decay | 权重衰减 | 默认值为 0。用于在损失函数中添加 L2 正则化项,防止模型过拟合。 |
| initial_accumulator_value | 初始累积器值 | 默认值为 0。用于初始化 Adagrad 的累积梯度值。在某些情况下,设置一个非零的初始值可以避免分母为零的问题。 |
| eps | 数值稳定性 | 默认值为 1e-10。这是一个小的常数,用于防止除零错误 |
import torch
import torch.nn as nn# 定义一个简单的模型
model = nn.Linear(10, 1)
# 初始化 Adagrad 优化器
optimizer = torch.optim.Adagrad(model.parameters(), lr=0.01, weight_decay=0.01)# 模拟训练过程
input_data = torch.randn(10, 10)
target = torch.randn(10, 1)
criterion = nn.MSELoss()for epoch in range(10):optimizer.zero_grad()output = model(input_data)loss = criterion(output, target)loss.backward()optimizer.step()print(f"Epoch {epoch+1}, Loss: {loss.item()}")def test02(): # 1 初始化权重参数 w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32) loss = ((w ** 2) / 2.0).sum() # 2 实例化优化方法:adagrad优化方法 optimizer = torch.optim.Adagrad ([w], lr=0.01) # 3 第1次更新 计算梯度,并对参数进行更新 optimizer.zero_grad() loss.backward() optimizer.step() print('第1次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy())) # 4 第2次更新 计算梯度,并对参数进行更新 # 使用更新后的参数机选输出结果 loss = ((w ** 2) / 2.0).sum() optimizer.zero_grad() loss.backward() optimizer.step() print('第2次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))

3.3 RMSprop
- 初始化学习率 η、初始化权重参数w、小常数 σ = 1e-10
- 初始化梯度累计变量 s = 0
- 从训练集中采样 m 个样本的小批量,计算梯度 g_t
- 使用指数加权平均累计历史梯度,⊙ 表示各个分量相乘,公式如下:
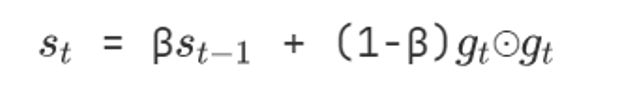
5.学习率 η 的计算公式如下:
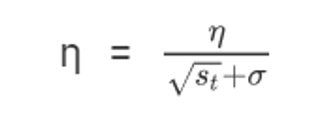
6.权重参数更新公式如下:
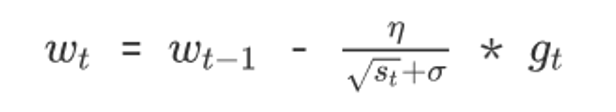
7.重复 3-7 步骤
- 优点
- 自适应学习率,适合处理稀疏数据。
- 避免了 Adagrad 中学习率过早衰减的问题。
- 适用场景
- 适合非凸优化问题。
- 常用于深度学习中的图像识别、自然语言处理等任务
api
| 参数名 | 参数解释 | 解释 |
| params | 待优化的参数列表,可以是一个包含张量的列表或字典。 | |
| lr | 学习率 | 默认值为 0.01。全局学习率,用于控制参数更新的步长。 |
| alpha | 平滑常数 | 默认值为 0.99。用于计算梯度平方的指数加权移动平均值,值越接近 1,历史梯度的影响越大。 |
| eps | 数值稳定性 | 默认值为 1e-08。为了避免分母为零而添加的小常数。 |
| weight_decay | 权重衰减 | 默认值为 0。用于 L2 正则化,防止模型过拟合。 |
| momentum | 动量因子 | 默认值为 0。如果设置为非零值,RMSprop 会结合动量法加速收敛。 |
| centered | 是否中心化 | 默认值为 False。如果为 True,会计算中心化的RMSprop,即对梯度进行归一化 |
- 如果模型在训练集上表现良好,但在验证集上表现较差(过拟合),可以尝试增加 weight_decay 的值。
- 如果模型在训练集上表现不佳,可能是由于 weight_decay 设置过高导致的欠拟合,此时应适当降低其值。
def test03(): # 1 初始化权重参数 w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32) loss = ((w ** 2) / 2.0).sum() # 2 实例化优化方法:RMSprop算法,其中alpha对应这beta optimizer = torch.optim.RMSprop([w], lr=0.01, alpha=0.9) # 3 第1次更新 计算梯度,并对参数进行更新 optimizer.zero_grad() loss.backward() optimizer.step() print('第1次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy())) # 4 第2次更新 计算梯度,并对参数进行更新 # 使用更新后的参数机选输出结果 loss = ((w ** 2) / 2.0).sum() optimizer.zero_grad() loss.backward() optimizer.step() print('第2次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))

3.4 Adam
- 修正梯度: 使⽤梯度的指数加权平均
- 修正学习率: 使⽤梯度平⽅的指数加权平均
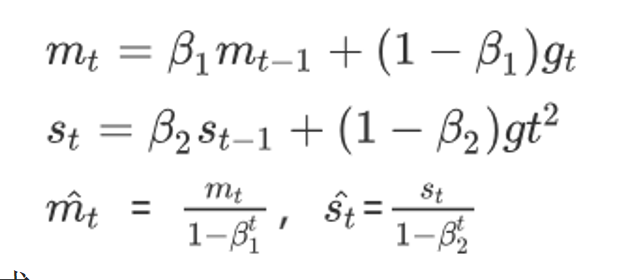
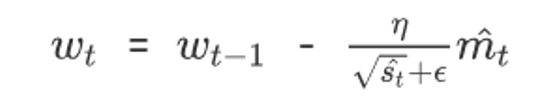
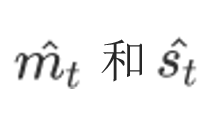
api
| 参数名 | 参数解释 | 解释 |
| params | 待优化的参数列表,可以是一个包含张量的列表或字典。例如 [w] 或 model.parameters()。 | |
| lr | 学习率 | 默认值为 0.001。全局学习率,用于控制参数更新的步长。Adam 优化器会根据梯度的一阶矩和二阶矩动态调整每个参数的学习率,但学习率的初始值仍然很重要。 |
| betas | 衰减率 | 默认值为 (0.9, 0.999)。这是一个包含两个值的元组(beta1, beta2),分别用于计算梯度的一阶矩(均值)和二阶矩(未中心化的方差)的指数加权移动平均。 beta1:用于一阶矩估计的衰减率(通常设置为 0.9)。 beta2:用于二阶矩估计的衰减率(通常设置为 0.999)。 这两个值越接近 1,历史梯度的影响越大。 |
| eps | 数值稳定性 | 默认值为 1e-08。这是一个小的常数,用于防止分母为零的情况。在 Adam 的更新公式中,分母是二阶矩的平方根,eps 确保分母不会为零。 |
| weight_decay | 权重衰减 | 默认值为 0。用于 L2 正则化,防止模型过拟合。权重衰减会将权重的平方值添加到损失函数中。 |
| amsgrad | AMSGrad | 默认值为 False。如果设置为 True,则启用 AMSGrad 算法,这是对 Adam 的一种改进,用于解决某些情况下 Adam 可能导致收敛问题的情况。 |
def test04(): # 1 初始化权重参数 w = torch.tensor([1.0], requires_grad=True) loss = ((w ** 2) / 2.0).sum() # 2 实例化优化方法:Adam算法,其中betas是指数加权的系数 optimizer = torch.optim.Adam([w], lr=0.01,betas=[0.9,0.99]) # 3 第1次更新 计算梯度,并对参数进行更新 optimizer.zero_grad() loss.backward() optimizer.step() print('第1次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy())) # 4 第2次更新 计算梯度,并对参数进行更新 # 使用更新后的参数机选输出结果 loss = ((w ** 2) / 2.0).sum() optimizer.zero_grad() loss.backward() optimizer.step() print('第2次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))

4.学习率退⽕
4.1 为什么要进行学习率优化
import torch
import matplotlib.pyplot as plt
import numpy as npplt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体为黑体
plt.rcParams['axes.unicode_minus'] = False
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"# 定义函数 y = 4x^2
def func(x_t):return torch.pow(2 * x_t, 2)# 测试梯度下降过程
def aaaa():lr_list = [0.01, 0.1, 0.125, 0.2, 0.3] # 学习率列表max_iteration = 4 # 最大迭代次数for lr in lr_list:x = torch.tensor([2.], requires_grad=True) # 每次循环重新初始化 xiter_rec, loss_rec, x_rec = list(), list(), list() # 每次循环清空记录列表for i in range(max_iteration):y = func(x) # 计算损失值y.backward() # 计算梯度print(f"LR:{lr}, Iter:{i}, X:{x.item():.4f}, X.grad:{x.grad.item():.4f}, Loss:{y.item():.4f}")x_rec.append(x.item()) # 记录权重值loss_rec.append(y.item()) # 记录损失值iter_rec.append(i) # 记录迭代次数# 更新参数x.data.sub_(lr * x.grad) # x = x - lr * x.gradx.grad.zero_() # 清空梯度# 创建一个新的图形窗口plt.figure(figsize=(12, 5))# 绘制损失值ax1 = plt.subplot(121)ax1.plot(iter_rec, loss_rec, '-ro')ax1.grid()ax1.set_xlabel("Iteration")ax1.set_ylabel("Loss value")ax1.set_title(f"Loss vs Iteration (lr={lr})")# 绘制函数曲线和梯度下降路径ax2 = plt.subplot(122)x_t = torch.linspace(-3, 3, 100)y_t = func(x_t)ax2.plot(x_t.numpy(), y_t.numpy(), label="y = 4x^2", color='black')ax2.plot(x_rec, [func(torch.tensor(x)).item() for x in x_rec], '-ro', label=f"Gradient Descent Path (lr={lr})")ax2.grid()ax2.legend()ax2.set_title(f"Function Curve and Descent Path (lr={lr})")# 显示当前学习率的图像plt.tight_layout()plt.show()# 运行测试
aaaa()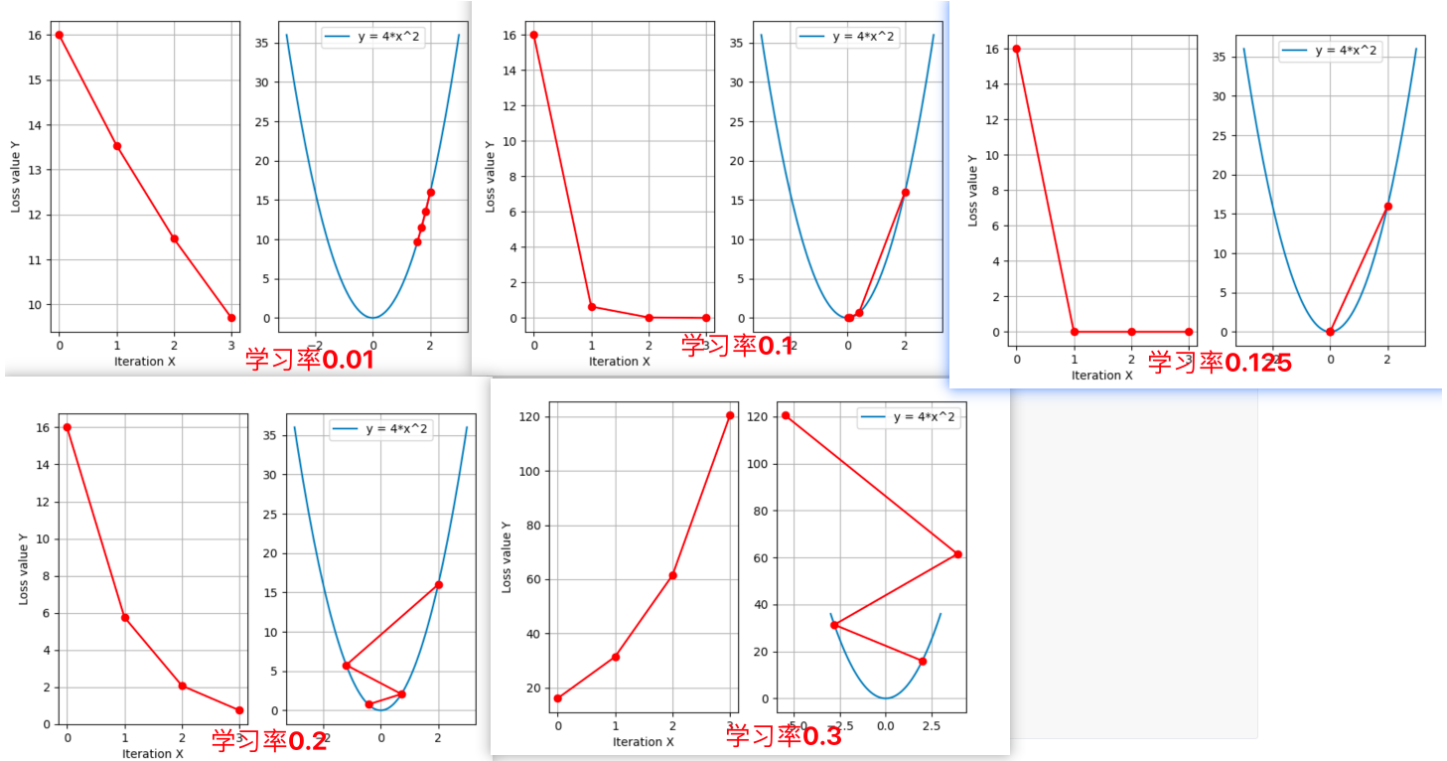
4.2 等间隔学习率衰减
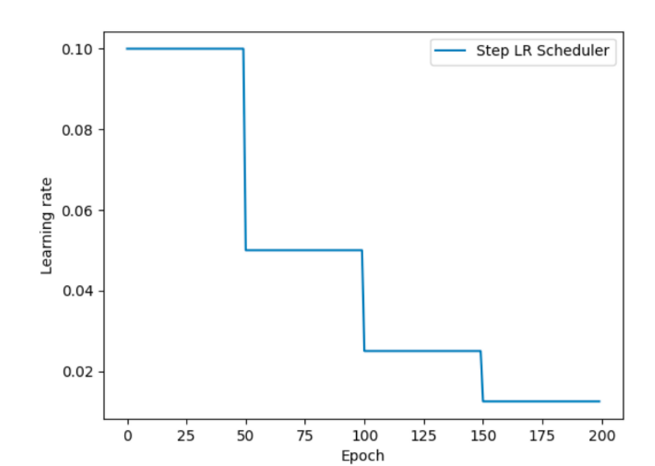
api
| 参数名 | 参数解释 | 解释 |
| optimizer | 包装的优化器,例如 torch.optim.Adam 或 torch.optim.SGD。调度器会根据优化器的当前学习率进行调整。 | |
| step_size | int | 学习率衰减的周期。每隔 step_size 个 epoch,学习率会被乘以 gamma。例如,step_size=50 表示每 50 个 epoch 衰减一次。 |
| gamma | float | 学习率衰减的乘法因子。默认值为 0.1,但可以根据需要调整。例如,gamma=0.5 表示每次衰减时学习率会减半。 |
| last_epoch | int | 最后一个 epoch 的索引,默认值为 -1,表示从头开始。如果需要从某个特定的 epoch 开始调整学习率,可以设置此参数。 |
| get_last_lr() | 获取当前学习率。 |
import torch
import torch.optim as optim
import torch.nn as nn# 定义一个简单的模型
model = nn.Linear(10, 1)
optimizer = optim.Adam(model.parameters(), lr=0.01)# 定义学习率调度器
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.5)# 训练过程
for epoch in range(100):# 训练模型optimizer.zero_grad()output = model(torch.randn(1, 10))loss = nn.MSELoss()(output, torch.randn(1, 1))loss.backward()optimizer.step()# 更新学习率scheduler.step()# 打印当前学习率if epoch % 10 == 0:print(f"Epoch {epoch}, Current LR: {scheduler.get_last_lr()[0]:.6f}")import torch
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optimdef aa_StepLR():# 0. 参数初始化LR = 0.1 # 设置学习率初始值为 0.1iteration = 10max_epoch = 200# 1. 初始化参数y_true = torch.tensor([0.0], requires_grad=False)x = torch.tensor([1.0], requires_grad=False)w = torch.tensor([1.0], requires_grad=True)# 2. 定义优化器optimizer = optim.SGD([w], lr=LR, momentum=0.9)# 3. 设置学习率下降策略scheduler_lr = optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.5)# StepLR是一种简单但常用的学习率调度器,适用于训练过程中需要逐步降低学习率的场景。# 参数 step_size 表示每隔多少个 epoch 调整一次学习率。# 参数 gamma 是学习率的衰减因子,表示每次调整时学习率乘以的系数。# 4. 获取学习率的值和当前的 epochlr_list, epoch_list = list(), list()for epoch in range(max_epoch):lr_list.append(optimizer.param_groups[0]['lr']) # 获取当前学习率epoch_list.append(epoch) # 记录当前的 epochfor i in range(iteration): # 遍历每一个 batch 数据loss = ((w * x - y_true) ** 2) / 2.0 # 目标函数optimizer.zero_grad() # 清空梯度loss.backward() # 反向传播optimizer.step() # 更新参数# 更新下一个 epoch 的学习率scheduler_lr.step()# 5. 绘制学习率变化的曲线plt.plot(epoch_list, lr_list, label="Step LR Scheduler")plt.xlabel("Epoch")plt.ylabel("Learning rate")plt.legend()plt.title("Learning Rate Schedule")plt.show()# 调用函数
aa_StepLR()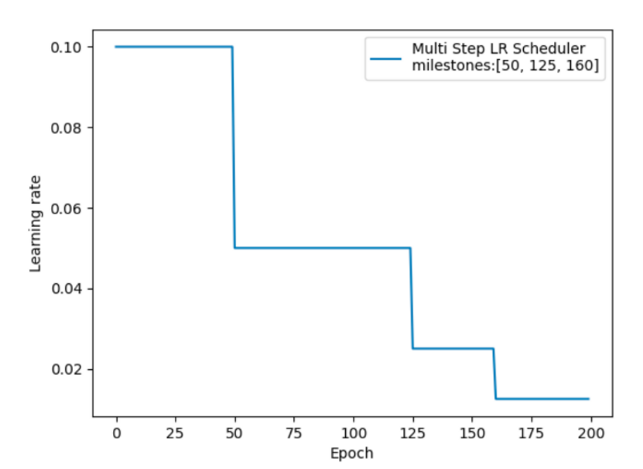
4.3 指定间隔学习率衰减
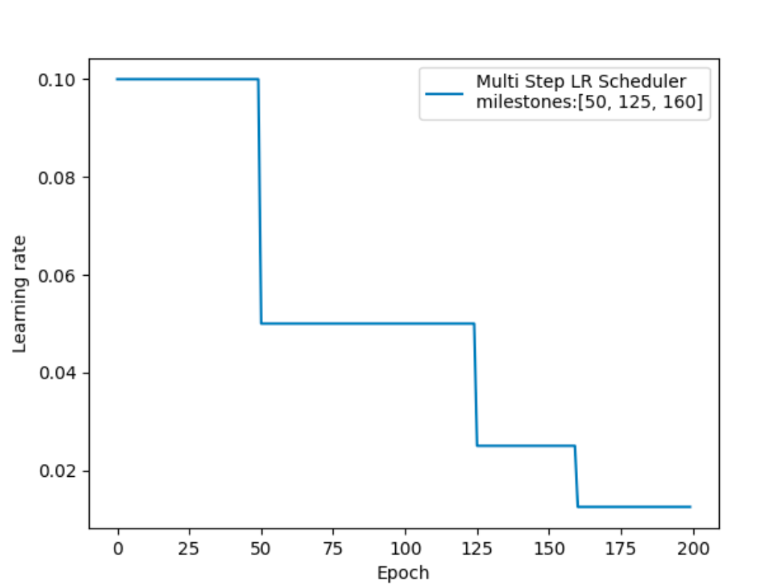

api
| 参数名 | 参数解释 | 解释 |
| optimizer | 被调度的优化器实例,例如 torch.optim.SGD 或 torch.optim.Adam。 | |
| milestones | 一个包含整数的列表,表示在这些 epoch 后调整学习率。这些整数必须是非递减的,例如 [30, 80]。 | |
| gamma | float | 每次在里程碑处,学习率乘以的衰减因子。通常是一个小于 1 的数(例如 0.1),默认值为 0.1。 |
| last_epoch | int | 训练的最后一个 epoch 数。如果是从头开始训练,则设置为 -1。在从某个中断点恢复训练时非常有用。 |
| get_last_lr() | 获取当前学习率。 |
import torch
import torch.optim as optim
import torch.nn as nn# 定义一个简单的模型
model = nn.Linear(2, 1)
optimizer = optim.SGD(model.parameters(), lr=0.1)# 创建 MultiStepLR 调度器,在第 30 和第 80 个 epoch 时调整学习率
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[30, 80], gamma=0.1)# 模拟训练过程
num_epochs = 100
for epoch in range(num_epochs):optimizer.zero_grad()output = model(torch.randn(1, 2))loss = (output - torch.randn(1)).pow(2).sum()loss.backward()optimizer.step()# 调度器步进scheduler.step()# 打印当前学习率current_lr = optimizer.param_groups[0]['lr']print(f'Epoch {epoch+1}, Learning Rate {current_lr}')import torch
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optimdef aa_MultiStepLR():# 0. 参数初始化LR = 0.1 # 设置学习率初始值为 0.1iteration = 10max_epoch = 200# 1. 初始化参数y_true = torch.tensor([0.0], requires_grad=False)x = torch.tensor([1.0], requires_grad=False)w = torch.tensor([1.0], requires_grad=True)# 2. 定义优化器optimizer = optim.SGD([w], lr=LR, momentum=0.9)# 设定调整时刻数milestones = [50, 125, 160]# 3. 设置学习率下降策略scheduler_lr = optim.lr_scheduler.MultiStepLR(optimizer, milestones=milestones, gamma=0.5)# StepLR是一种简单但常用的学习率调度器,适用于训练过程中需要逐步降低学习率的场景。# 参数 step_size 表示每隔多少个 epoch 调整一次学习率。# 参数 gamma 是学习率的衰减因子,表示每次调整时学习率乘以的系数。# 4. 获取学习率的值和当前的 epochlr_list, epoch_list = list(), list()for epoch in range(max_epoch):lr_list.append(optimizer.param_groups[0]['lr']) # 获取当前学习率epoch_list.append(epoch) # 记录当前的 epochfor i in range(iteration): # 遍历每一个 batch 数据loss = ((w * x - y_true) ** 2) / 2.0 # 目标函数optimizer.zero_grad() # 清空梯度loss.backward() # 反向传播optimizer.step() # 更新参数# 更新下一个 epoch 的学习率scheduler_lr.step()# 5. 绘制学习率变化的曲线plt.plot(epoch_list, lr_list, label="Step LR Scheduler")plt.xlabel("Epoch")plt.ylabel("Learning rate")plt.legend()plt.title("Learning Rate Schedule")plt.show()# 调用函数
aa_MultiStepLR()
4.5 指数衰减
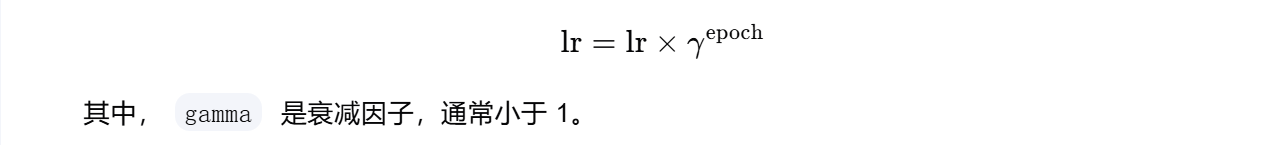
api
| 参数名 | 参数解释 | 解释 |
| optimizer | 包装的优化器,例如 torch.optim.Adam 或 torch.optim.SGD。调度器会根据优化器的当前学习率进行调整。 | |
| gamma | float | 学习率衰减的乘法因子。默认值为 0.1,但可以根据需要调整。例如,gamma=0.5 表示每次衰减时学习率会减半。 |
| last_epoch | int | 最后一个 epoch 的索引,默认值为 -1,表示从头开始。如果需要从某个特定的 epoch 开始调整学习率,可以设置此参数。 |
| get_last_lr() | 获取当前学习率。 |
import torch
import torch.optim as optim
import matplotlib.pyplot as plt# 定义一个简单的模型
model = torch.nn.Linear(2, 1)
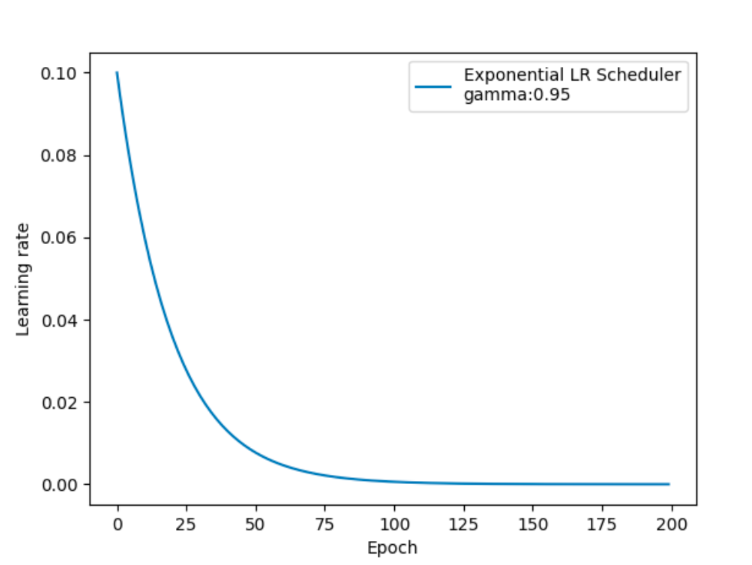
optimizer = optim.SGD(model.parameters(), lr=0.1)# 创建 ExponentialLR 调度器
scheduler = optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.95)# 模拟训练过程
learning_rates = []
num_epochs = 100
for epoch in range(num_epochs):optimizer.step()scheduler.step()current_lr = optimizer.param_groups[0]['lr']learning_rates.append(current_lr)print(f"Epoch {epoch + 1}, Learning Rate: {current_lr:.6f}")# 绘制学习率变化曲线
plt.plot(range(1, num_epochs + 1), learning_rates, label="Exponential Decay")
plt.xlabel("Epoch")
plt.ylabel("Learning Rate")
plt.title("ExponentialLR Scheduler")
plt.legend()
plt.grid(True)
plt.show()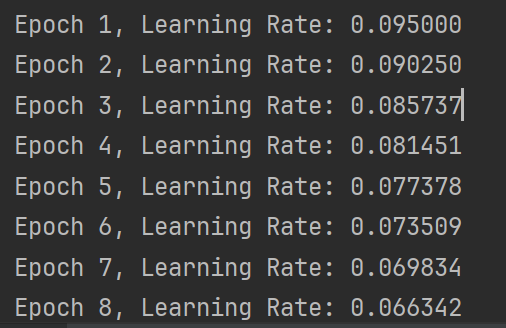
import torch
import matplotlib.pyplot as plt
import numpy as np
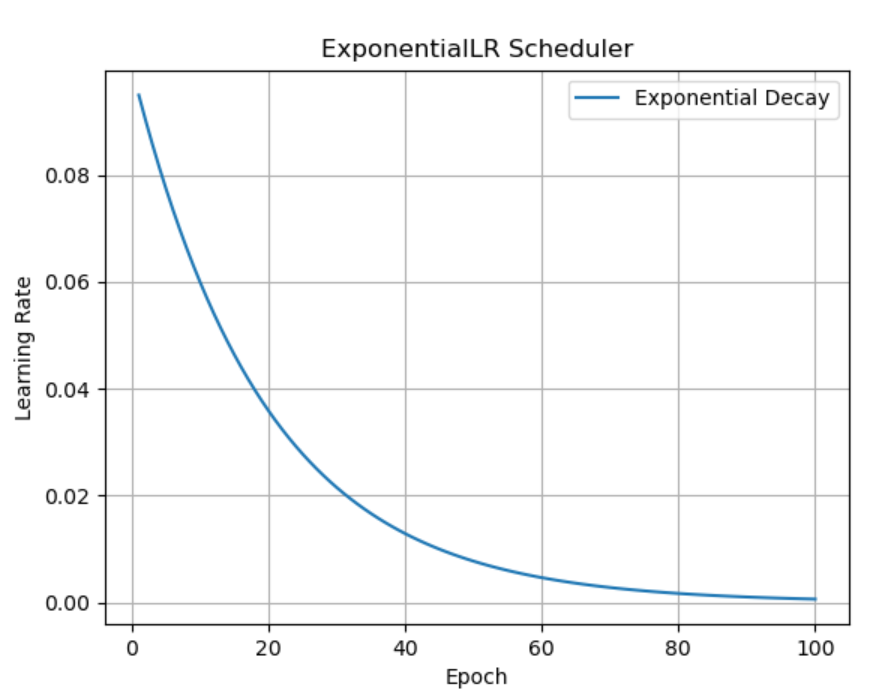
import torch.optim as optimdef aa_ExponentialLR():# 0. 参数初始化LR = 0.1 # 设置学习率初始值为 0.1iteration = 10max_epoch = 200# 1. 初始化参数y_true = torch.tensor([0.0], requires_grad=False)x = torch.tensor([1.0], requires_grad=False)w = torch.tensor([1.0], requires_grad=True)# 2. 定义优化器optimizer = optim.SGD([w], lr=LR, momentum=0.9)# 3.设置学习率下降策略gamma = 0.95scheduler_lr = optim.lr_scheduler.ExponentialLR(optimizer, gamma=gamma)# 4. 获取学习率的值和当前的 epochlr_list, epoch_list = list(), list()for epoch in range(max_epoch):lr_list.append(optimizer.param_groups[0]['lr']) # 获取当前学习率epoch_list.append(epoch) # 记录当前的 epochfor i in range(iteration): # 遍历每一个 batch 数据loss = ((w * x - y_true) ** 2) / 2.0 # 目标函数optimizer.zero_grad() # 清空梯度loss.backward() # 反向传播optimizer.step() # 更新参数# 更新下一个 epoch 的学习率scheduler_lr.step()# 5. 绘制学习率变化的曲线plt.plot(epoch_list, lr_list, label="Step LR Scheduler")plt.xlabel("Epoch")plt.ylabel("Learning rate")plt.legend()plt.title("Learning Rate Schedule")plt.show()# 调用函数
aa_ExponentialLR()4.7 总结
| 方法 | 等间隔学习率衰减 (Step Decay) | 指定间隔学习率衰减 (Exponential Decay) | 指数学习率衰减 (Exponential Moving Average Decay) |
| 衰减方式 | 固定步长衰减 | 指定步长衰减 | 平滑指数衰减,历史平均考虑 |
| 实现难度 | 简单易实现 | 相对简单,容易调整 | 需要额外历史计算,较复杂 |
| 适用场景 | 大型数据集、较为简单的任务 | 对训练平稳性要求较高的任务 | 高精度训练,避免过快收敛 |
| 优点 | 直观,易于调试,适用于大批量数据 | 易于调试,稳定训练过程 | 平滑且考虑历史更新,收敛稳定性较强 |
| 缺点 | 学习率变化较大,可能跳过最优点 | 在某些情况下可能衰减过快,导致优化提前停滞 | 超参数调节较为复杂,可能需要更多的计算资源 |
总结
| 优化算法 | 优点 | 缺点 | 适用场景 |
| SGD | 简单、容易实现。 | 收敛速度较慢,容易震荡,特别是在复杂问题中。 | 用于简单任务,或者当数据特征分布相对稳定时。 |
| Momentum | 可以加速收敛,减少震荡,特别是在高曲率区域。 | 需要手动调整动量超参数,可能会在小步长训练中过度更新。 | 用于非平稳优化问题,尤其是深度学习中的应用。 |
| AdaGrad | 自适应调整学习率,适用于稀疏数据。 | 学习率会在训练过程中逐渐衰减,可能导致早期停滞。 | 适合稀疏数据,如 NLP 或推荐系统中的特征。 |
| RMSProp | 解决了 AdaGrad 学习率过早衰减的问题,适应性强。 | 需要选择合适的超参数,更新可能会过于激进。 | 适用于动态问题、非平稳目标函数,如深度学习训练。 |
| Adam | 结合了 Momentum 和 RMSProp 的优点,适应性强且稳定。 | 需要调节更多的超参数,训练过程中可能会产生较大波动。 | 广泛适用于各种深度学习任务,特别是非平稳和复杂问题。 |
- 简单任务和较小的模型:SGD 或 Momentum
- 复杂任务或有大量数据:Adam 是最常用的选择,因其在大部分任务上都表现优秀
- 需要处理稀疏数据或文本数据:Adagrad 或 RMSProp
- 知道梯度下降算法
- 理解神经⽹络的链式法则
- 掌握反向传播算法(BP算法)
- 知道梯度下降算法的优化⽅法
- 了解学习率退⽕