LangChain4j(18)——通过Xinference调用Rerank模型
Rerank模型介绍
也称为重排序模型,它从搜索中获取初始结果集,并重新评估它们,以确保它们更紧密地符合用户的意图。 它超越了术语的表面匹配,考虑了搜索查询和文档内容之间更深层次的交互。
比如为了提高RAG的召回率和准确率,我们可以先使用RAG进行检索,针对检索后的数据,再通过Rerank模型进行重排,然后将重排后的数据交给大模型,使大模型返回更准确的信息。
LangChain4j支持的Rerank模型如下:

其中通过onnx调用需要将模型转为onnx后调用,占用内存较多。Cohere、Jina等模型需要收费。本例采用Xinference方式调用。
通过Xinference安装模型
Xorbits Inference (Xinference) 是一个开源平台,用于简化各种 AI 模型的运行和集成。借助 Xinference,您可以使用任何开源 LLM、嵌入模型和多模态模型在云端或本地环境中运行推理,并创建强大的 AI 应用。
支持的模型的类型如下:

安装Xinference
本例使用docker进行安装,可以参考如下文档:Docker 镜像 — Xinference
安装命令如下:
docker run -e XINFERENCE_MODEL_SRC=modelscope -p 9997:9997 xprobe/xinference:latest-cpu xinference-local -H 0.0.0.0 --log-level debug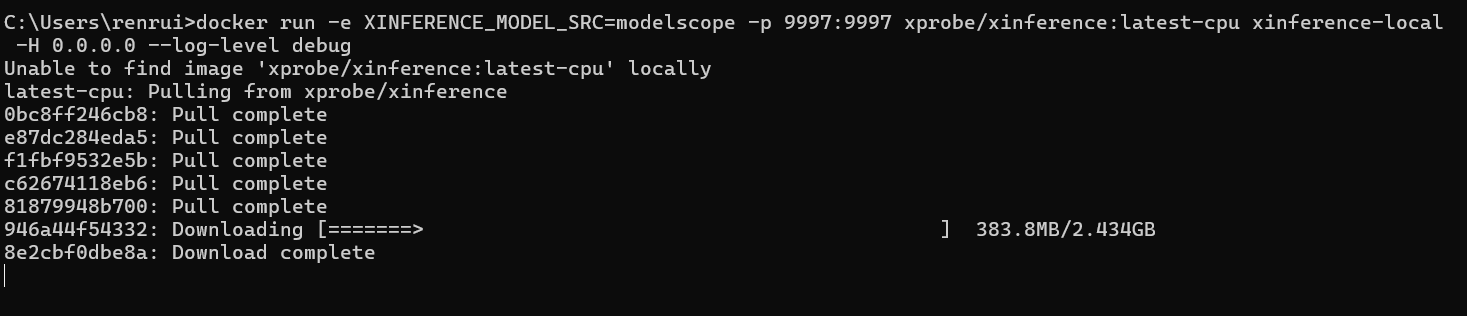
运行Xinference
http://127.0.0.1:9997
安装Rerank模型
Launch Model选项表示Xinference支持的内置模型。
本例选择bge-reranker-base模型安装。
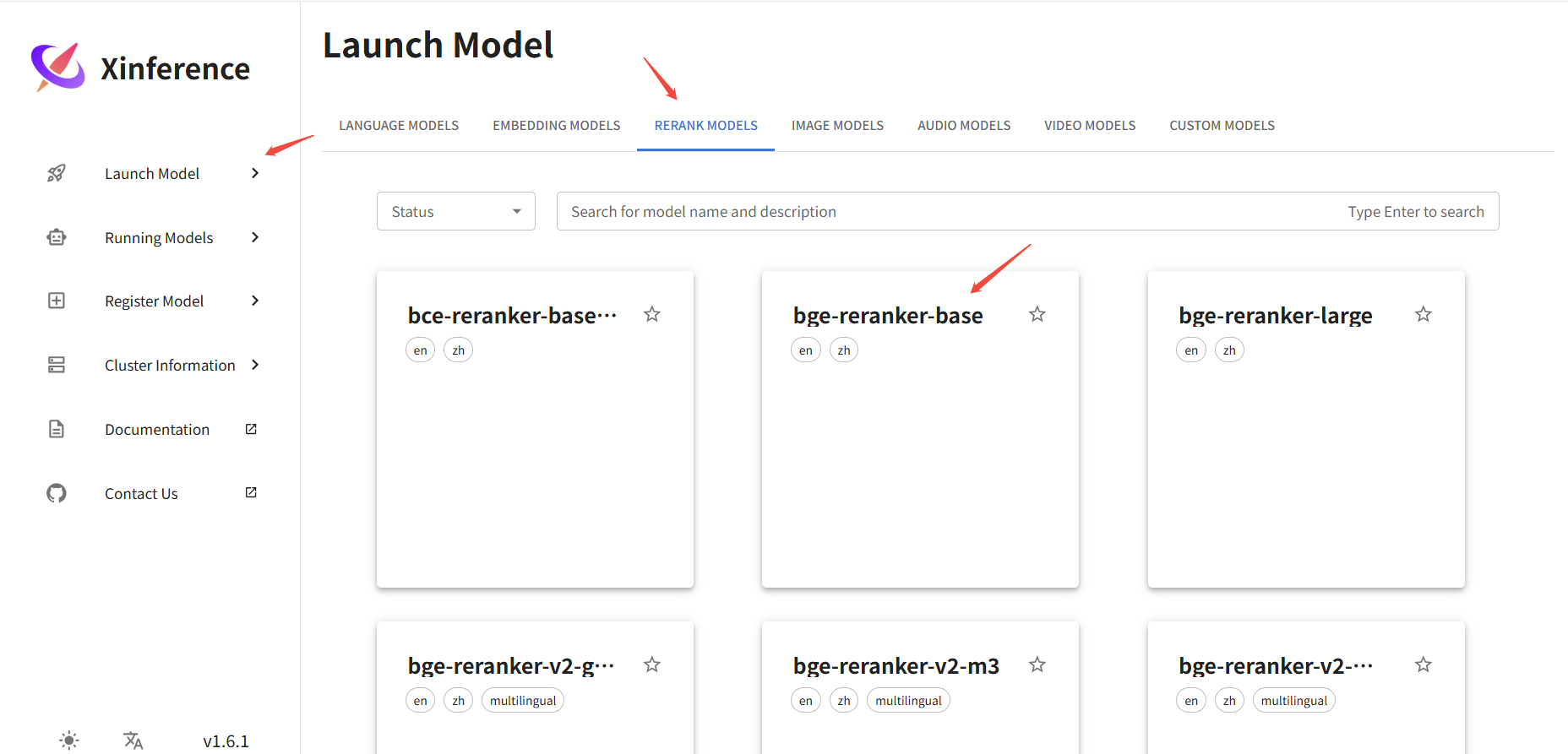
点击“小火箭”图标进行安装。
安装完成后,在Running Models中可以看到正在运行的model。

LangChain4j调用Rerank模型
导入jar
<dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-community-xinference</artifactId><version>1.0.0-beta3</version></dependency>测试代码
package com.renr.langchain4jnew.app5;import dev.langchain4j.community.model.xinference.XinferenceScoringModel;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.model.scoring.ScoringModel;import java.time.Duration;
import java.util.List;/*** @Classname RerankTest* @Description TODO* @Date 2025-06-09 22:22* @Created by 老任与码*/
public class RerankTest {public static void main(String[] args) {ScoringModel model = XinferenceScoringModel.builder().baseUrl("http://127.0.0.1:9997").modelName("bge-reranker-base").timeout(Duration.ofSeconds(60)).maxRetries(1)
// .logRequests(true)
// .logResponses(true).build();String text ="北京市(Beijing),简称“京”,古称燕京、北平,是中华人民共和国首都、直辖市、国家中心城市、超大城市, [185]国务院批复确定的中国政治中心、文化中心、国际交往中心、科技创新中心, [1]中国历史文化名城和古都之一,世界一线城市。 [3] [142] [188]截至2023年10月,北京市下辖16个区,总面积16410.54平方千米。 [82] [193] [195]2023年末,北京市常住人口2185.8万人。 [214-215]";String query = "中国首都是哪座城市";// 根据查询的内容,对一个初始数据进行打分Response<Double> response = model.score(text, query);System.out.println(response.content());TextSegment segment1 = TextSegment.from("上海市(Shanghai),简称“沪”,别名“申”,是中华人民共和国直辖市, [38]位于中国东部,地处长江入海口, [175]境域北界长江,东濒东海,南临杭州湾,西接江苏省和浙江省,总面积6340.5平方千米, [38]下辖16个区。 [37]截至2022年末,全市常住人口2475.89万人, [204]上海话属吴语方言太湖片。 [159]市政府驻地上海市黄浦区人民大道200号。 [173]");TextSegment segment2 = TextSegment.from("北京市(Beijing),简称“京”,古称燕京、北平,是中华人民共和国首都、直辖市、国家中心城市、超大城市, [185]国务院批复确定的中国政治中心、文化中心、国际交往中心、科技创新中心, [1]中国历史文化名城和古都之一,世界一线城市。 [3] [142] [188]截至2023年10月,北京市下辖16个区,总面积16410.54平方千米。 [82] [193] [195]2023年末,北京市常住人口2185.8万人。 [214-215]");List<TextSegment> segments = List.of(segment1, segment2);String query2 = "中国首都是哪座城市";// 对多个数据进行打分Response<List<Double>> response2 = model.scoreAll(segments, query);List<Double> scores = response2.content();System.out.println(scores);}
}
执行结果

返回指定个数的score
设置topN参数,根据分数降序,返回指定个数的分数。
package com.renr.langchain4jnew.app5;import dev.langchain4j.community.model.xinference.XinferenceScoringModel;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.model.scoring.ScoringModel;import java.time.Duration;
import java.util.List;/*** @Classname RerankTest* @Description TODO* @Date 2025-06-09 22:22* @Created by 老任与码*/
public class RerankTest {public static void main(String[] args) {ScoringModel model = XinferenceScoringModel.builder().baseUrl("http://127.0.0.1:9997")// .apiKey(apiKey()).modelName("bge-reranker-base").timeout(Duration.ofSeconds(60)).maxRetries(1).topN(1) // 根据分数降序,返回指定个数的分数
// .logRequests(true)
// .logResponses(true).build();TextSegment segment1 = TextSegment.from("上海市(Shanghai),简称“沪”,别名“申”,是中华人民共和国直辖市, [38]位于中国东部,地处长江入海口, [175]境域北界长江,东濒东海,南临杭州湾,西接江苏省和浙江省,总面积6340.5平方千米, [38]下辖16个区。 [37]截至2022年末,全市常住人口2475.89万人, [204]上海话属吴语方言太湖片。 [159]市政府驻地上海市黄浦区人民大道200号。 [173]");TextSegment segment2 = TextSegment.from("北京市(Beijing),简称“京”,古称燕京、北平,是中华人民共和国首都、直辖市、国家中心城市、超大城市, [185]国务院批复确定的中国政治中心、文化中心、国际交往中心、科技创新中心, [1]中国历史文化名城和古都之一,世界一线城市。 [3] [142] [188]截至2023年10月,北京市下辖16个区,总面积16410.54平方千米。 [82] [193] [195]2023年末,北京市常住人口2185.8万人。 [214-215]");List<TextSegment> segments = List.of(segment1, segment2);String query2 = "中国首都是哪座城市";// 对多个数据进行打分Response<List<Double>> response2 = model.scoreAll(segments, query);List<Double> scores = response2.content();System.out.println(scores);}
}
![]()