2020年IS SCI2区,多样本和遗忘能力粒子群算法XPSO,深度解析+性能实测
目录
- 1.摘要
- 2.粒子群算法PSO原理
- 3.扩展粒子群算法(XPSO)
- 4.结果展示
- 5.参考文献
- 6.代码获取
- 7.算法辅导·应用定制·读者交流

1.摘要
在人类社会与生物系统中,普遍存在两种认知机制:一是通过多个范例获取更优学习能力,二是通过遗忘未用或无效信息来促进新知识的编码与巩固。受此启发,本文提出了一种扩展粒子群算法(XPSO),将多范例学习与遗忘机制引入PSO。XPSO将每个粒子同时从局部最优和全局最优两个范例中学习,增强信息获取能力;为不同粒子分配差异化的遗忘能力,模拟人类遗忘行为;并引入自适应加速度系数更新机制与种群拓扑的重新选择策略,以进一步提升算法性能。
2.粒子群算法PSO原理
【智能算法】粒子群算法(PSO)原理及实现
3.扩展粒子群算法(XPSO)
社会学习多范例机制
在传统PSO中,粒子社会学习部分通常仅依赖单一范例进行学习。在人类社会中,个体往往倾向于从多个信息源中获取知识,这种多范例学习方式被广泛认为更有助于提升学习能力。在 CLPSO 算法中,一个粒子从不同粒子的历史最优信息中选择其学习范例;在 FIPSO 算法中,一个粒子会受到其邻居表现影响的程度不同,从而决定学习的权重。XPSO选择 G B GB GB(全局最优)和 L B i LB_i LBi(个体局部最优)作为第 i i i粒子在社会学习部分的两个学习范例。
遗忘能力
遗忘是一种普遍存在的生物现象,长期以来受到生物学和神经科学领域的广泛关注。作为大脑记忆管理系统的重要组成部分,遗忘通过清除未使用或无用的信息,在新旧记忆之间建立起平衡,有助于信息的高效编码与巩固。本文将遗忘机制移植至PSO中,提出了一种基于个体特征的遗忘策略。在速度更新过程中,每个粒子根据自身特性对社会学习部分的信息进行有选择的遗忘,以提升种群的多样性和行为复杂性。同时,引入基于种群历史知识的加速度系数调整机制,以进一步增强算法的自适应能力。
速度更新公式:
v i , j t + 1 = w ⋅ v i , j t + c p i ⋅ r 1 , j ⋅ ( p b i , j t − x i , j t ) + c l i ⋅ r 2 , j ⋅ ( ( 1 − f i , j ) ⋅ l b i , j t − x i , j t ) + c g i ⋅ r 3 , j ⋅ ( ( 1 − f i , j ) ⋅ g b j t − x i , j t ) v_{i,j}^{t+1}=w\cdot v_{i,j}^{t}+cp_{i}\cdot r_{1,j}\cdot(pb_{i,j}^{t}-x_{i,j}^{t})+cl_{i}\cdot r_{2,j}\cdot((1-f_{i,j})\cdot lb_{i,j}^{t}-x_{i,j}^{t})+cg_{i}\cdot r_{3,j}\cdot((1-f_{i,j})\cdot gb_{j}^{t}-x_{i,j}^{t}) vi,jt+1=w⋅vi,jt+cpi⋅r1,j⋅(pbi,jt−xi,jt)+cli⋅r2,j⋅((1−fi,j)⋅lbi,jt−xi,jt)+cgi⋅r3,j⋅((1−fi,j)⋅gbjt−xi,jt)
XPSO中的遗忘能力设计依赖于粒子之间的距离,在XPSO中,粒子之间距离越大,表示熟悉度越低,相应的遗忘程度也越强。
d i s t i = ∑ j = 1 D ( x i , j − g b j ) 2 dist_i=\sqrt{\sum_{j=1}^D(x_{i,j}-gb_j)^2} disti=j=1∑D(xi,j−gbj)2
为增强个体间的差异性与算法的自适应能力,XPSO引入了三个独立的加速度系数,分别对应粒子从自身最优解、局部范例和全局范例的学习强度。这些加速度系数基于历史精英个体的统计特征动态生成,其中均值会根据精英个体在演化过程中的历史表现自适应更新,从而实现对种群整体学习趋势的引导与调节。
μ k ← ( 1 − η ) ⋅ μ k + η ⋅ a v g ( < μ k e l i t e > ) , 1 ≤ k ≤ 3 \mu_k\leftarrow(1-\eta)\cdot\mu_k+\eta\cdot avg(<\mu_k^{elite}>),1\leq k\leq3 μk←(1−η)⋅μk+η⋅avg(<μkelite>),1≤k≤3

4.结果展示
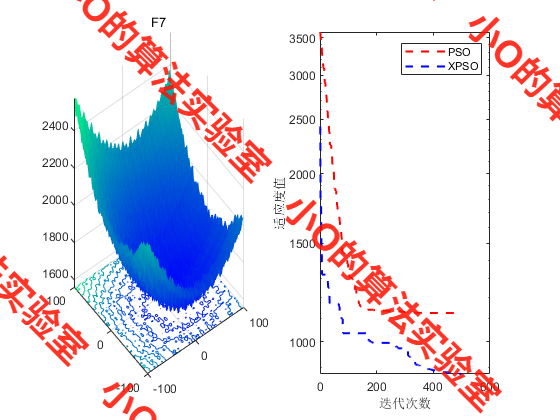
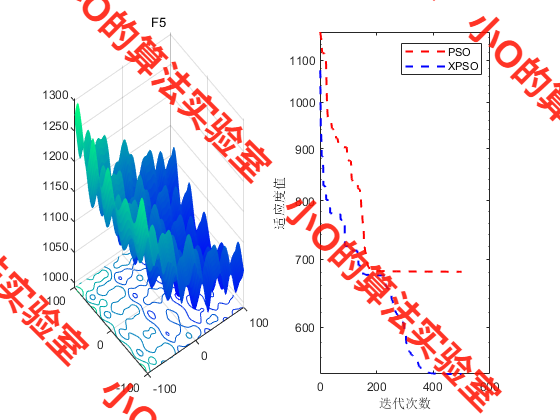
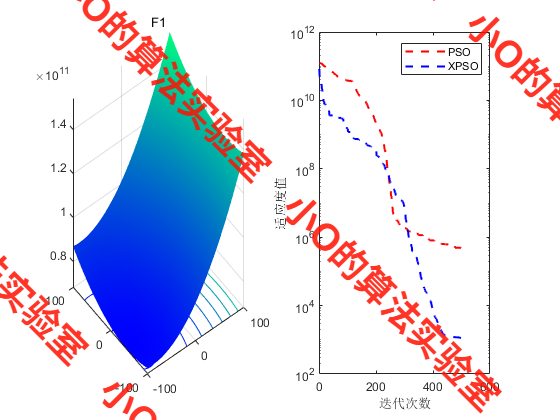
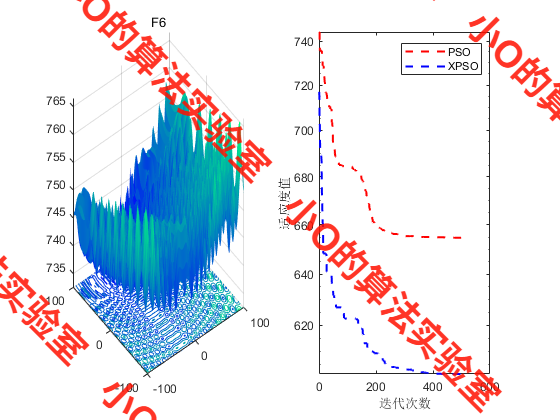
5.参考文献
[1] Xia X, Gui L, He G, et al. An expanded particle swarm optimization based on multi-exemplar and forgetting ability[J]. Information Sciences, 2020, 508: 105-120.
6.代码获取
xx