CAU人工智能class7 迁移学习
深度学习自2012年的AlexNet发展以来已经从早期的各自为战,发展到现在的预训练大模型+大小联调(迁移学习)。
迁移学习
那么在神经网络的训练上,是否也有这种现象呢?
答案是肯定的,目前CNN领域一般在一个已经训练好的预训练模型上根据具体任务再进行微调。
迁移学习放宽了训练数据必须与测试数据独立同分布的假设
因为这种方法侧重的是知识迁移和领域适应,并不依赖于数据的统计特性。
优势

实现
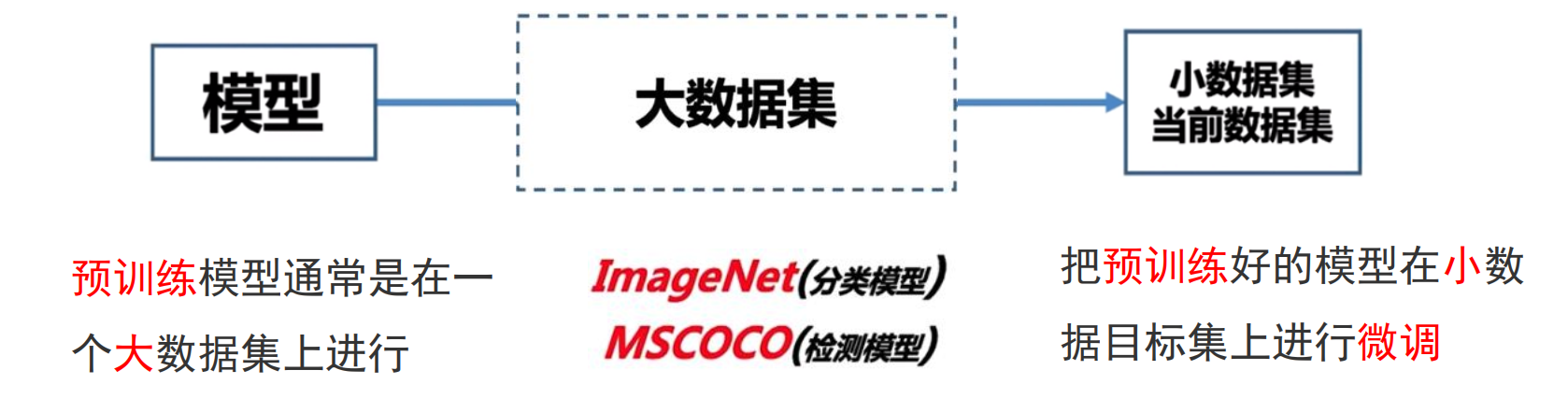
微调
微调的核心思想是利用在大规模数据集上预训练一个模型,然后在基于少量的目标域训练样本上对预训练模型的参数进行微调。这种方法在解决小样本应用场景中展现出巨大的潜力。
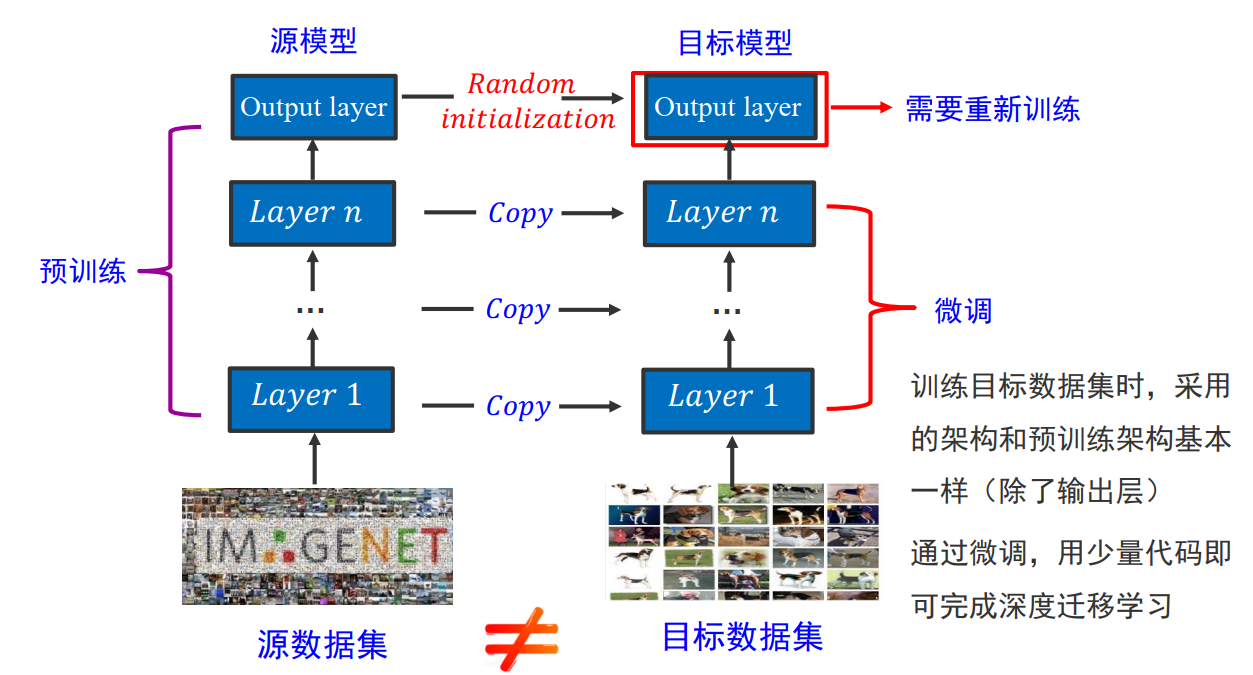
在VGG中就有过类似的使用:
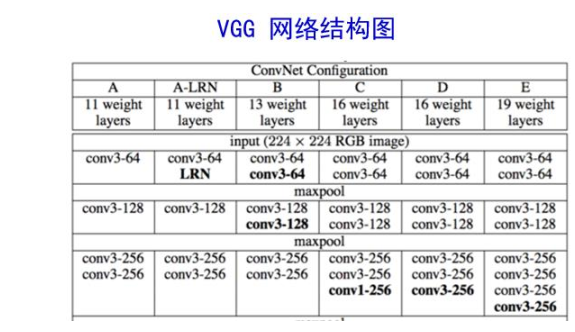
浅层的A层作为预训练,初始化其他模型的参数
微调的几种方式
- 载入预训练模型后,微调训练所有层的参数
- 载入预训练模型后, 固定(冻结)前面的卷积层,只训练最后几个全连接层的参数
- 载入预训练模型后,微调后面的卷积层 + 全连接层
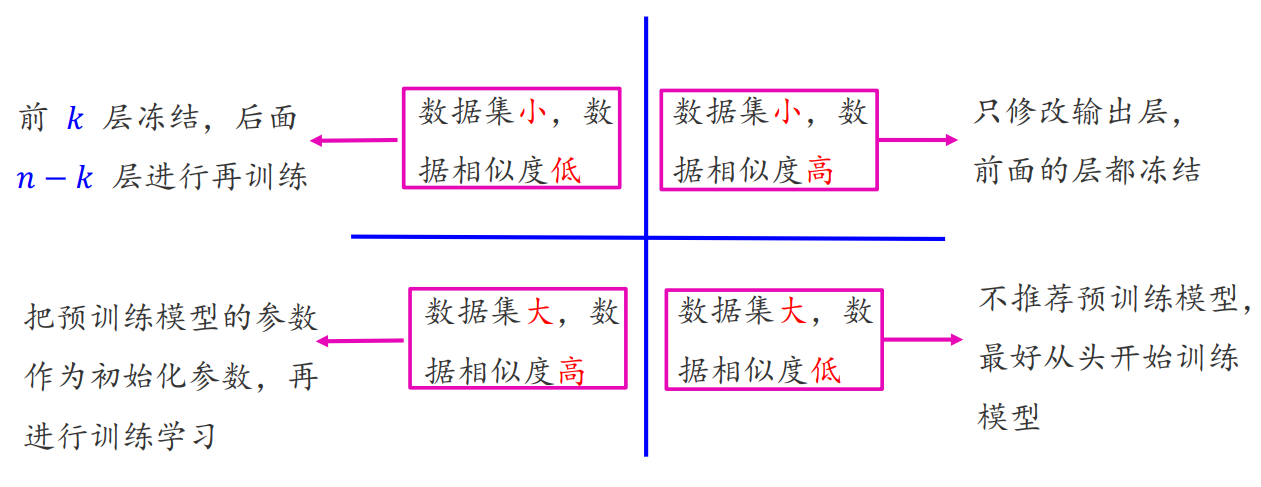
微调 (fine-tuning) 应用场景
知识蒸馏
让小模型获得大模型的智慧
小模型有部署简单,资源消耗小等优点。
什么是知识蒸馏
将大模型的知识迁移到小模型当中,让小模型模仿大模型
实现
使用软标签
什么是软标签?

软标签可以保留更多信息,适合作为小模型学习的材料
损失函数
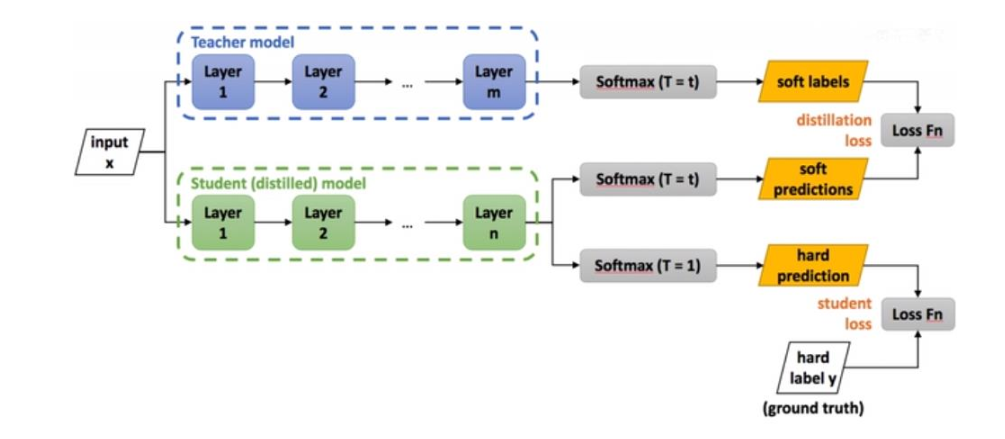
教师在将“知识”传递给学生的过程中,会有一些损失,称为蒸馏损失
因此,学生模型的损失由两部分构成:
总损失 = 蒸馏损失 + 自身模型损失 的加权和
过程
温度控制

在softmax中会将占比大的类别会更大,占比小的会更小。也就是说softmax会增大个个选项之间的差距。
而在指数函数中自变量越小,增长的幅度越小,因此可以增大温度来控制各个选项的差距。
