【Redis】通用命令
通用命令
- 一. get 和 set
- 二. keys
- 三. exists
- 四. del
- 五. expire
- 六. ttl
- 七. 过期策略的实现原理
- 八. 定时器的实现原理
- 九. type
- 十. 总结
通过 redis-cli 客户端和 Redis 服务器交互,涉及到很多的 Redis 的命令,需要掌握常用命令,学会使用 Redis 的文档。阅读文档是程序员的基操,任何一个工具软件,去找相关资料,一定是官方网站。虽然 Redis 这种知名的软件,都是有中文文档的,但是阅读英文文档是非常重要的,工作的过程中,可能会用到一些不太知名的软件/库,很可能是没有中文文档的,但是一定有英文文档。
redis 官方文档:https://redis.io/
一. get 和 set
Redis 是按照 “键值对” 的方式进行数据存储的,必须要通过 redis-cli 命令,进入 Redis 客户端,才能输入 Redis 命令。
- get:根据 key 来获取 value,语法:
get key - set:把 key 和 value 存储进去,语法:
set key value
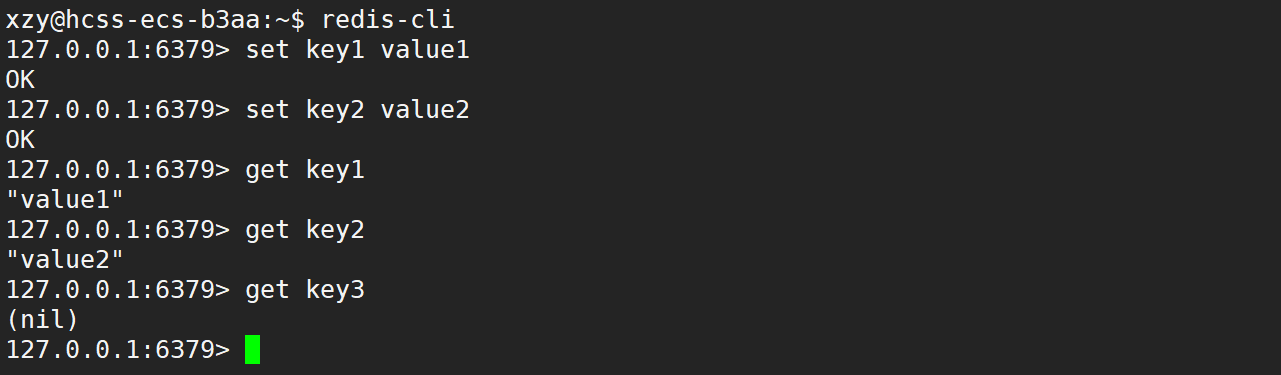
- 对于上述的 key 和 value,不需要加上引号,就是表示字符串类型,如果要是给 key 和 value 加上引号 (单引号/双引号),也是可以的,且 Redis 不区分大小写。
- get 命令直接输入 key 就能得到 value,如果当前 key 不存在,会返回 nil,和 null/NULL 是一个意思,get 和 set 使用简单,学习成本低。
二. keys
Redis 支持很多种数据结构,整体上来说,Redis 是 “键值对” 结构,key 固定就是字符串,value 实际上会有很多种类型,例如:字符串、哈希表、列表、集合、有序集合。操作不同的数据结构就会有不同的命令,其中 Redis 全局命令:能够搭配任意一个数据结构来使用的命令。
keys:用来查询当前服务器上匹配的 key,通过一些特殊符号 (通配符) 来描述 key 的摸样,匹配上述摸样的 key 就能被查询出来。语法:keys pattern
- ?:匹配任意一个字符。
- *:匹配 0 个或者多个任意字符。
- [abcde]:只能匹配到 a、b、c、d、e,别的不行,相当于给出固定的选项了。
- [^e]:排除 e,只有 e 匹配不了,其它的都能匹配。
- [a-e]:匹配 a ~ e 范围内的字符,包含两侧边界。
先设置一些 “键值对”,最为实例方便演示,如下:
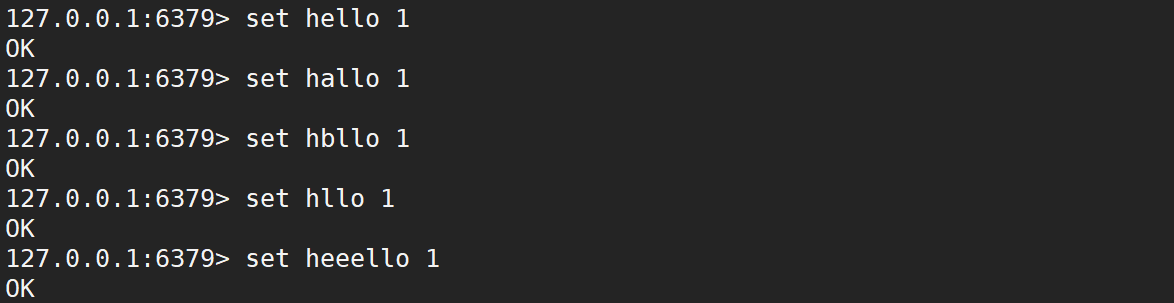
使用 keys,开始匹配,如下:
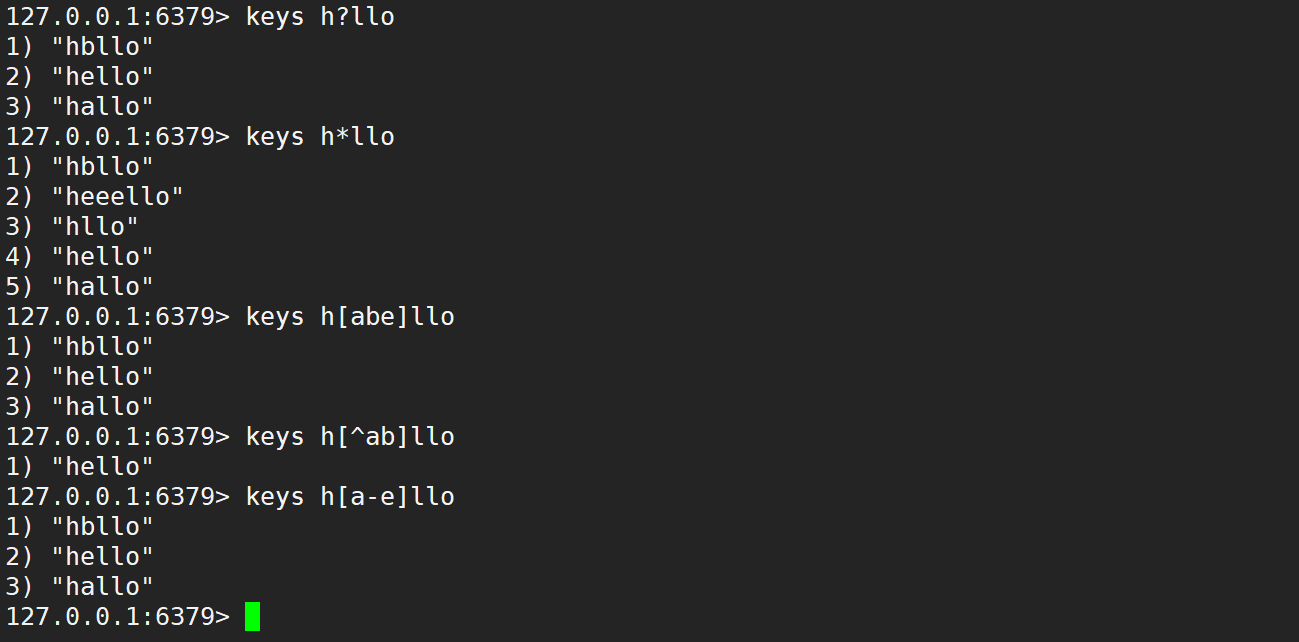
注意事项:keys 命令的时间复杂度是 O(N)
- 所以在生产环境上,一般都会禁止使用 keys 命令,尤其是大杀器 keys *,来查询 Redis 中所有的 key!
- 生产环境上的 key 可能会非常多,而 Redis 是一个单线程的服务器,执行 keys * 的时间非常长,就是 Redis 服务器被阻塞了,无法给其他客户提供服务,这样的后果可能是灾难性的。
- Redis 经常会用于缓存,挡在 MySQL 前面,替 MySQL 负重前行的人,万一 Redis 被一个 key * 阻塞住了,此时其他的查询 Redis 操作就超时了,此时这些请求就会直接查询数据库,突然一大波请求过来了,MySQL 措手不及,就容易挂了,整个系统就基本瘫痪了,如果你要是没能及时发现,及时恢复的话,年终奖妥妥的就没了,更严重的话工作就没了。
未来在工作中会涉及到几个环境:
- 办公环境:入职公司之后,公司会给你发的环境。
- 例如:笔记本 (Windows、mac)、台式机,现在的办公电脑,一般为 8 core、内存 16G、硬盘 512 G
- 开发环境:有的时候开发环境和办公环境是一个,也有的时候开发环境是单独的服务器。
- 做前端/做客户端,一般来说,开发环境就是办公环境。
- 做后端,很可能就是单独的服务器,一般为 28 core,内存 128G、硬盘 4T
- 后端程序会比较复杂,C++ 编译一次的时间特别久 (#include),需要使用高新能的服务器进行编译。
- 有的程序一启动要消耗很多的 CPU 和内存资源,办公环境难以支撑,例如:商业搜索服务器启动起来要吃 100G 的内存。
- 有的程序比较依赖 Linux,在 Windows 环境搭建不起来。
- 测试环境:测试工程师使用的,跟后端开发环境类似,一般为 28 core,内存 128G、硬盘 4T
- 生产环境 (线上环境):外界用户能够访问到的,一但生产环境上出现问题,一定会对于用户的使用产生影响,直接影响到公司的营收。很多公司的营收都是靠广告,广告一般是按照 展示/点击 次数来计费的。
- 办公环境、开发环境、测试环境,也称为线下环境,外界用户无法访问到的。
未来去操作线上环境的任何一个设备/程序,都要怀着 12 分的谨慎,那以后不操作生产环境行不行,肯定是不行的。把一个程序 “上线” 才算是把活干完了,上线也可以认为是程序员的一个重要的考核指标,衡量一个实习生能不能转正留用,就是看上线次数,一个月基本才上线一次,基本凉凉,如果一周能上线两三次,基本稳了。
三. exists
exists:判定 key 是否存在,若存在返回 key 存在的个数。语法:exists key [key ...]

判定单个 key,时间复杂度是 O(1),返回 key 存在的个数,针对多个 key 来说是非常有用的。Redis 自身的这些 “键值对” 是通过哈希表的方式来组织的,Redis 的键 key 只能是字符串类型,Redis 的值 value 支持很多种数据结构。
上述分一次判定和分两次判定的区别?
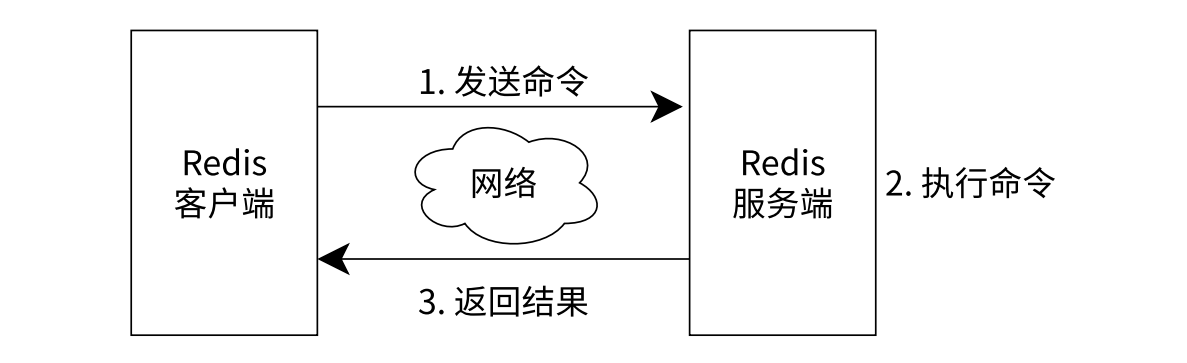
Redis 是一个客户端服务器结构的程序,客户端和服务器之间通过网络来进行通信,分两次判定,将会产生更多轮次的网络通信,成本比较高,效率比较低 (与直接操作内存比)
- 进行网络通信的时候,发送方发送一个数据,这个数据就要从应用层到物理层层层封装 (每一层协议都要加上报头),接收方接收一个数据,这个数据就要从物理层到应用层层层分用 (每一层协议都要移除报头)
- 网卡是 IO 设备,效率与内存相比,效率低的不是一星半点,更何况客户端和服务器不一定在同一个主机上,中间可能相隔万水千山。
Redis 自身也非常清楚上述的问题,Redis 的很多命令都是支持一次就能操作多个 key 的多种操作。
四. del
del:删除指定的 key。语法:del key [key ...]

删除单个 key,时间复杂度是 O(1),返回删除掉的 key 的个数。
- 在 MySQL 中,删除的操作类似 drop database、drop table、delete from … 都是非常危险的操作,一但删除之后,数据就没了,此时的影响是很大的。
- 在 Redis 中,主要的应用场景是作为缓存,此时 Redis 里存储的是一些热点数据,全量数据是在 MySQL 数据库中,此时如果把 Redis 中的 key 删除几个,一般来说影响不大。但是将一大半数据,甚至所有的数据都删除没了,这种的影响会很大 (本来 Redis 是帮 MySQL 负重前行的,若 Redis 没数据了,大部分的请求就直接打给 MySQL,然后就容易将 MySQL 搞挂)
- 如果是把 Redis 作为数据库,此时误删除数据的影响就很大了。如果是把 Redis 作为消息队列,此时误删除数据的影响是否很大,就需要具体场景具体分析。
归根结底还是不要乱删数据为好,万一删除了重要的数据,可能年终奖就没了。
五. expire
expire:给指定的 key 设置过期时间,key 存活时间超出这个指定的值,就会被自动删除。语法:expire key seconds 的单位是秒。另外 pexpire key milliseconds 的单位是毫秒。

此处的设定过期时间,必须是 key 已经存在的 key 设置的,设置成功返回 1,失败返回 0,时间复杂度是 O(1)
很多业务场景,是有时间限制的,例如:手机验证码,外卖优惠卷、基于 Redis 实现分布式锁,为了避免出现不能解锁的情况,通常都会在加锁的时候设置一些过期时间,时间到了,锁就会自动释放 (所谓的使用 Redis 作为分布式锁,就是给 Redis 写一个特殊的 key value,将 key 自动删除掉,就相当于解锁了)
六. ttl
ttl:查看当前 key 的过期时间还剩多少。语法:ttl key 的单位是秒。另外 pttl key 的单位是毫秒。
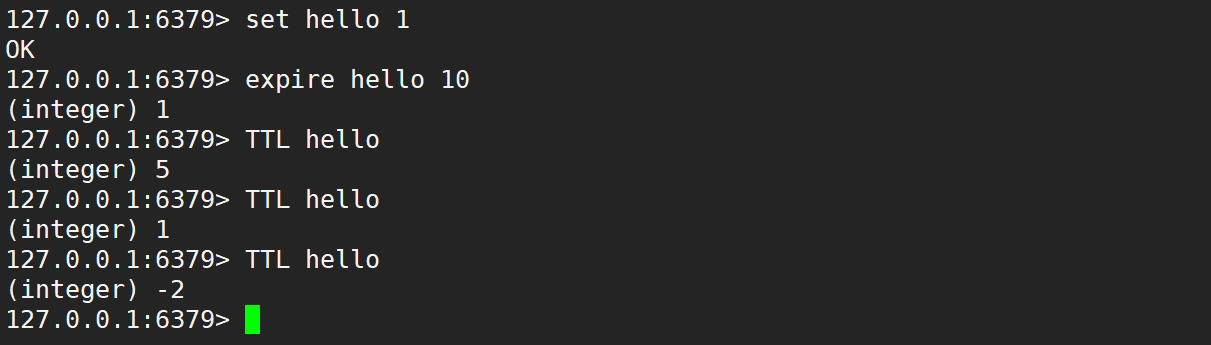
返回剩余过期时间,若返回 -1 表示没有关联过期时间,返回 -2 表示 key 不存在,时间复杂度是 O(1)
网络原理中的 IP 协议报头中就存在一个字段 TTL 表示报文在网络上的最大存活时间,每经过一个路由器,该值减 1,当 TTL 值减为 0 时,数据包会被丢弃。
七. 过期策略的实现原理
一个 Redis 中可能同时存在很多的 key,这些 key 中可能有很大一部分都有过期时间,此时 Redis 服务器怎么知道哪些 key 已经过期要被删除,哪些 key 没有过期呢?
经典面试题:Redis 的 key 过期策略是怎么实现的?
- 如果直接遍历所有的 key,显然效率非常低,是行不通的。
- Redis 的整体删除策略:定期删除 + 惰性删除。
- 定期删除:每次抽取一部分进行验证过期时间,保证这个抽取检查的过程足够快。
- 惰性删除:假设这个 key 已经到过期时间了,但是暂时还没删除,key 还存在,紧接着后面又一次访问,正好用到了这个 key,于是这次访问就会让 Redis 服务器触发删除 key 的操作,同时再返回一个 nil
- 为什么这里对于定期删除的时间,有明确的要求呢?
- 因为 Redis 是单线程的程序,主要的任务是处理命令,如果扫描过期的 key 消耗的时间太多了,就可能导致正常处理请求的命令就被阻塞了,产生了类似 keys * 这样的效果。
虽然我们有了上述两种策略结合,但是整体的效果一般,仍然可能会有很多的 key 被残留了,没有及时的删除,Redis 为了对上述进行补充,还提供了一系列的内存淘汰策略。
Redis 并没有采用 “定时器” 的方式来实现过期 key 删除。
- 如果有多个 key 过期,也可以通过一个定时器 (优先级队列或时间轮实现) 来高效/节省 CPU 的前提下来处理多个 key
- 为什么没有采取 “定时器” 实现过期 key 删除呢,可能就是:基于定时器实现,势必要引入多线程,而早起 Redis 版本就是奠定了单线程的基调,引入多线程就打破了作者的初衷。
八. 定时器的实现原理
定时器:这某个时间到达之后,执行指定的任务。
- 基于 “优先级队列/堆” 实现定时器:
- 正常的队列是先进先出。
- 优先级队列则是按照指定的优先级,先出。
- 在 Redis 过期 key 的场景中,就可以通过 “过期时间越早,优先级越高”。
- 现在假定有很多 key 设置了过期时间,就可以把这些 key 加入到一个优先级队列中,指定优先级规则是过期时间早的,先出队列,队首元素就是最早的要过期的 key,此时定时器中只要分配一个线程,让这个线程去检查队首元素,看是否过期即可,如果队首元素还没过期,后续元素就一定不可能过期,此时扫描不需要遍历所有 key,只需要盯住这一个队首元素即可。另外在扫描线程检查队首元素过期时间,也不能检查的太频繁,此时的做法就是可以根据当前时刻和队首元素的过期时间,设置一个等待事件,当事件到了,系统再唤醒这个线程,此时扫描线程不需要高频扫描队首元素,把 CPU 的开销也节省下来了,万一在线程休眠的时候,来了一个新的任务,可以在新任务添加的时候,唤醒一下刚才的线程,重新检查一下队首元素,再根据时间差距重新调整线程阻塞的时间即可。
- 基于 “时间轮” 实现定时器:
- 把时间划分成很多小段,划分的力度,看实际需求,这里假设为 100ms
- 每个小段上都挂着一个链表,每个链表节点都代表要执行的任务 (函数指针)
- 假设需要添加一个 key,这个 key 在 300ms 后过期,那么这个 key 将放在当前指针往后数的第三个格子中,此时这个指针,就会每隔 100ms 走到下一个格子中,每次走到下一个格子,就会把这个格子上链表的任务尝试执行一下 (假设指定的过期时间特别长 3000 ms,无法放在格子中,如果没到过期时间,则在下面几轮中再次判断)
- 对于时间轮来说,每个格子是多少时间,一共多少个格子,都是需要根据实际场景,灵活调配的。
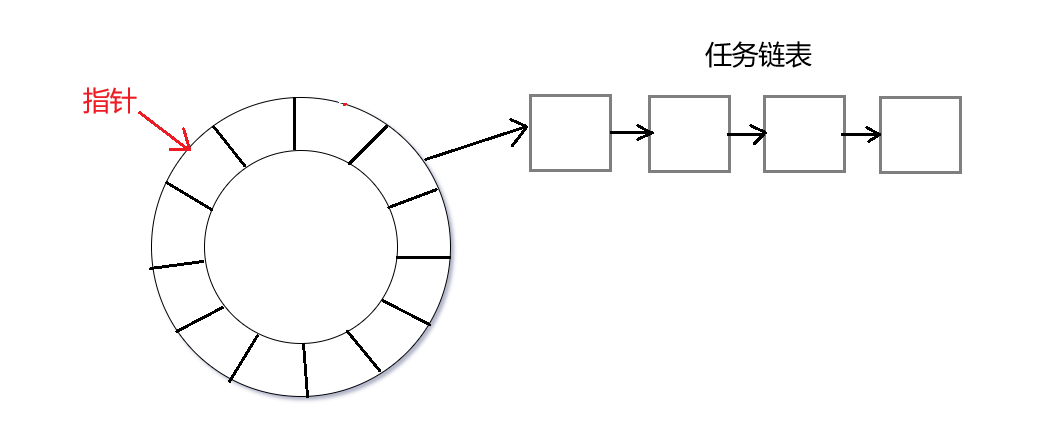
需要注意的是:Redis 并没有采取上面的方案,但是这两种方案都是属于高效的定时器的实现方式,很多场景可能都会用到。在 Redis 源码中,有一个比较核心的机制是事件循环。
九. type
type:返回 key 对应的 value 的类型。语法:type key
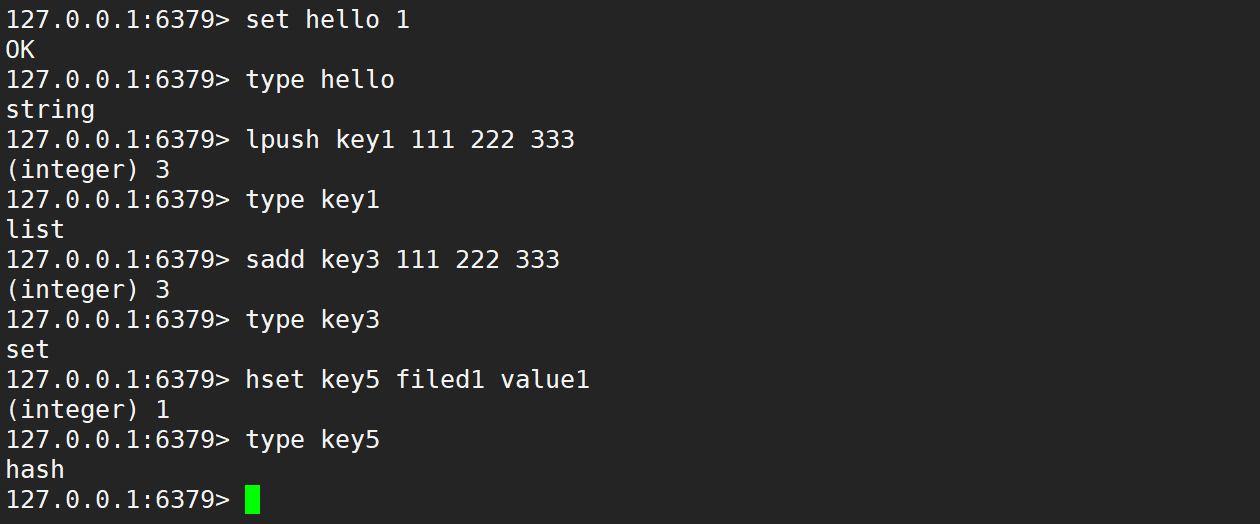
时间复杂度是 O(1),此处 Redis 所有的 key 都是字符串,key 对应的 value 可能会存在多种类型,例如:none、string、list、set、zset、hash 等等。在 Redis 中,上述类型的操作方式差别很大,使用的命令都是完全不同的。
十. 总结
当前已经学习了 Redis 中几个常见的全局命令。
- keys:用来查看匹配规则的 key
- exists:用来判断指定 key 是否存在。
- del:删除指定的 key
- expire:给 key 设置过期时间。
- ttl:查询 key 还剩的过期时间。
- type:查询 key 对应的 value 类型。
使用 key * 和 del 的风险,Redis key 过期策略如何实现,定时器的实现思路。