并发的产生及对应的解决方案之实例举证
一、什么是并发
在Web系统的性能评估中,QPS(每秒查询数)是一个核心指标。特别是在高并发场景下,每秒处理请求数的多少直接反映了系统的处理能力。
而在现实中,对于后端api服务来说,他的QPS是由每个页面的接口请求数来决定的(处理指令)。而服务器的最大连接数主要是由硬件资源、操作系统默认设置、网络配置来决定的(我定义为接收指令)。
二、并发的产生
前提是服务器的带宽只有1M,操作系统的默认连接数是1024个,1个进程给php工作。
实例1,1个接口请求的平均处理时间为100毫秒且1个接口请求大小为1kb,那么一秒能处理多少个请求?
首先计算秒并发问题。1(s)*1000(ms)/100(ms) = 10个
然后要考虑连接数问题(带宽是否充足)。链接数的计算方式为1(M带宽)*1024(kb)/1(kb) = 1024个
最后得出理论,1s中处理的请求数没有超过连接数,证明带宽能释放那么多的活跃请求进来。也就是说不用考虑连接数问题,也就是说这台服务器当下能做到秒并10个。
实例2,1个接口请求的平均处理时间为100毫秒且1个接口请求大小为1m,那么一秒能处理多少个请求?
首先计算秒并发问题。1(s)*1000(ms)/100(ms) = 10个
然后要考虑连接数问题(带宽是否充足)。链接数的计算方式为1(M带宽)*1024(kb)/1024(kb) = 1个
最后得出理论,1s中处理的请求数虽然没有超过连接数,但是同样也证明了1秒中只能有一个活跃请求进来。也就是这台服务器当下能做到秒并1个。
三、解决方案
以实例1为例,如果要一秒解决10000个请求,那么需要多少带宽、连接数及服务器
带宽=10000*1(kb)/1024=9.77M(也就是10M)
连接数=10(M带宽)*1024(kb)/1(kb) = 10240个
服务器数量=10000/10 = 1000台 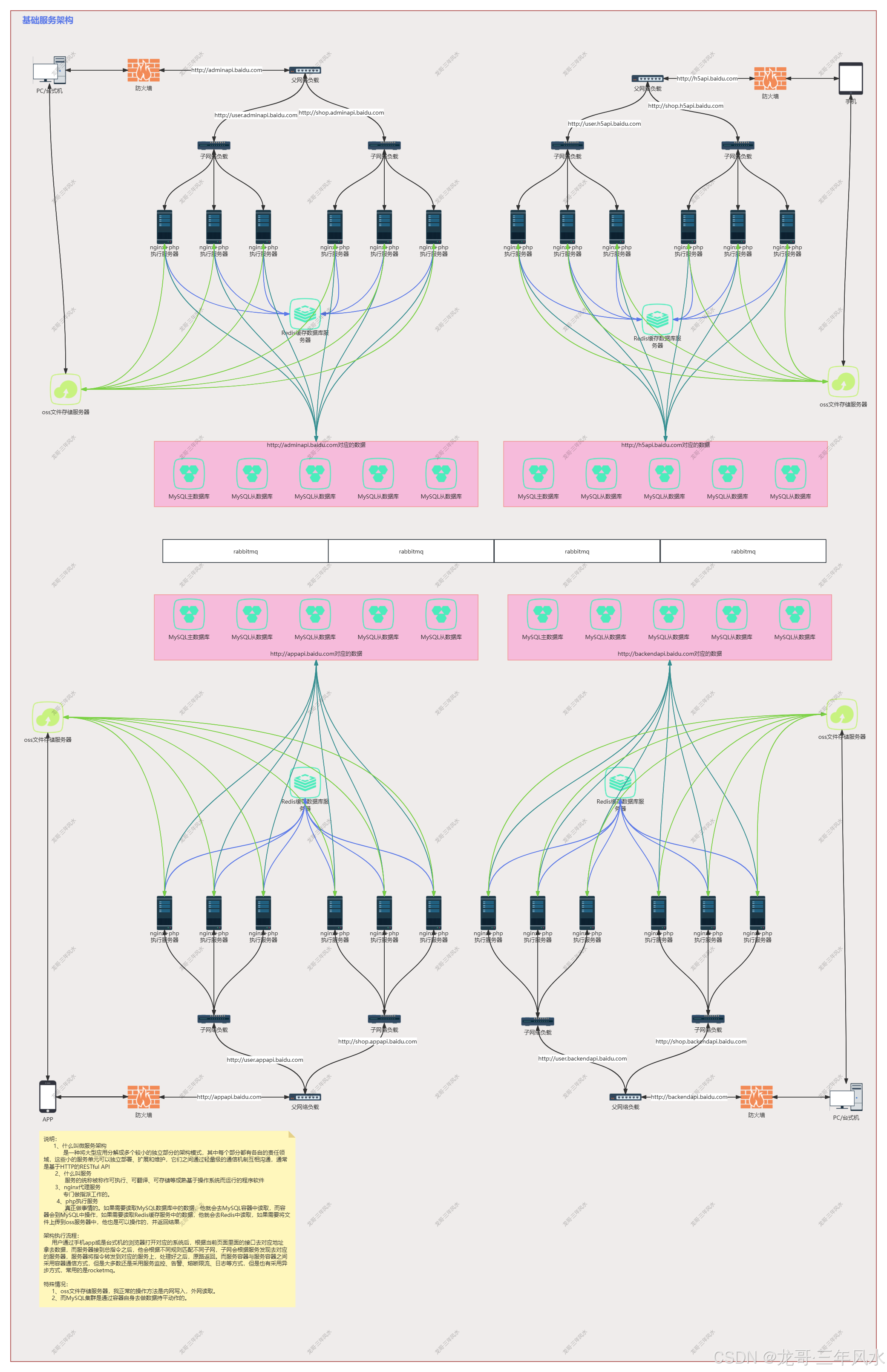
以上是时间成本最低,费用最高(也就是行业中常说的叫能力不够,服务来凑)。
在现实生活中,我的处理方式是优先会将1个接口请求的平均处理时间100ms优化为5ms,这样的话,一台服务器1秒1个进程能处理200个请求,紧接着就是将1个进程调整为10个进程,那么10000个请求就变成10000/(200*10) = 5台服务器。这样做的工作原理是快速接收指令及返回,异步通知请求处理结果(这就是分布式思想最牛叉的地方)。这样就必须用到集群架构。且不能靠普通的php框架,需要用到中间件如rabbitmq与websocket。rabbitmq是专门处理请求的,而websocket是专门通知前端rabbitmq处理的结果。而php框架只是把请求加入到rabbitmq里面后返回用户,快速结束本次请求及释放连接数。
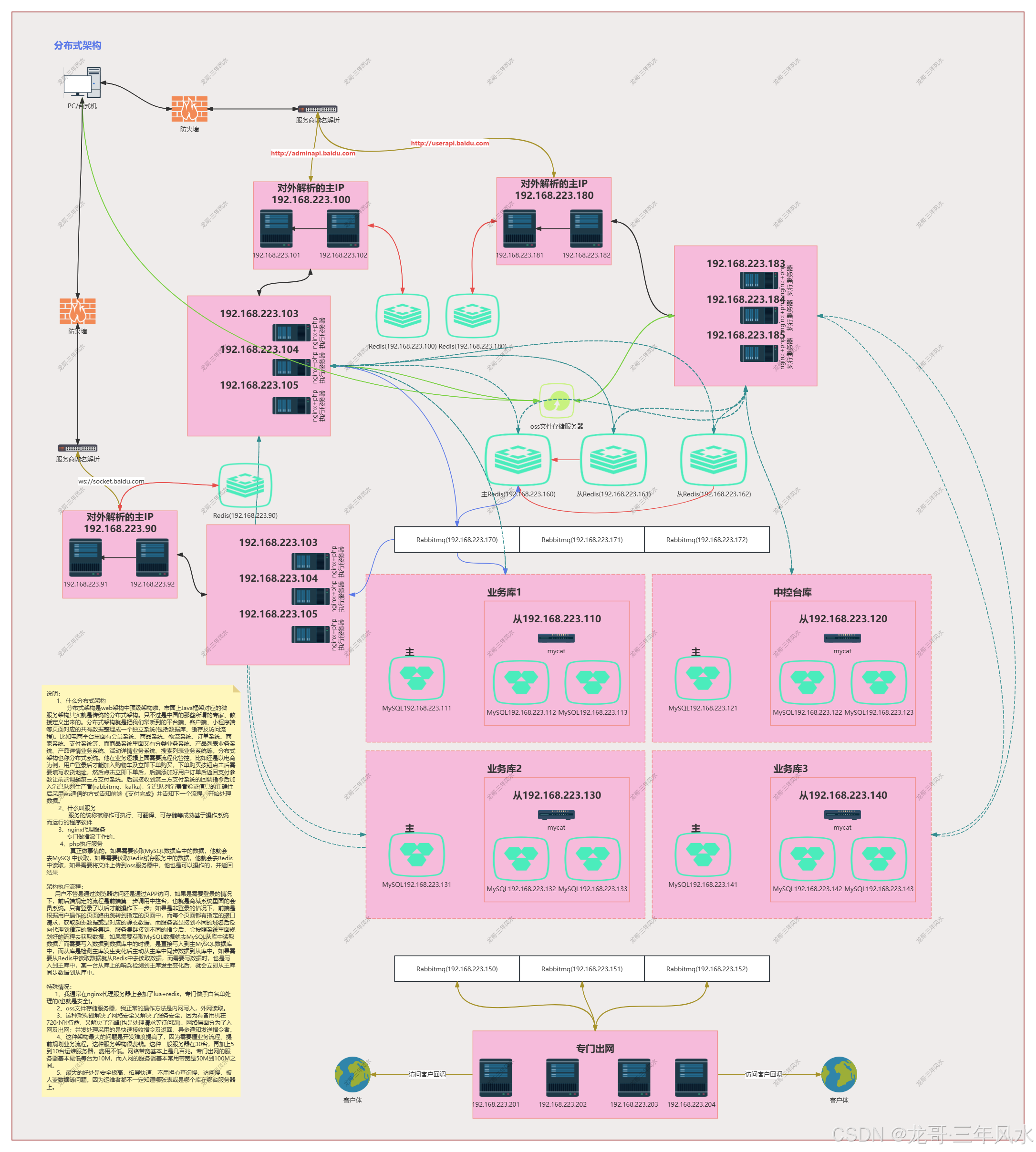
这种做法在时间成本上略高,单费用最低(这种极其考验技术自身的设计能力)
以实例2为例,如果要一秒解决10000个请求,那么需要多少带宽、连接数及服务器
带宽=10000*1(M) = 10000M(以阿里云为例,单个域名最高是200M,所以需要5个域名同时做同样的事情,而每台服务器每秒又只能处理10个请求,也就是说单个域名只能是10M,那么10000M真实的情况下,需要1000个域名)
连接数=10M/1(M) = 10个(每个主域名对应的连接数)
服务器数量=10000M/10M = 1000台
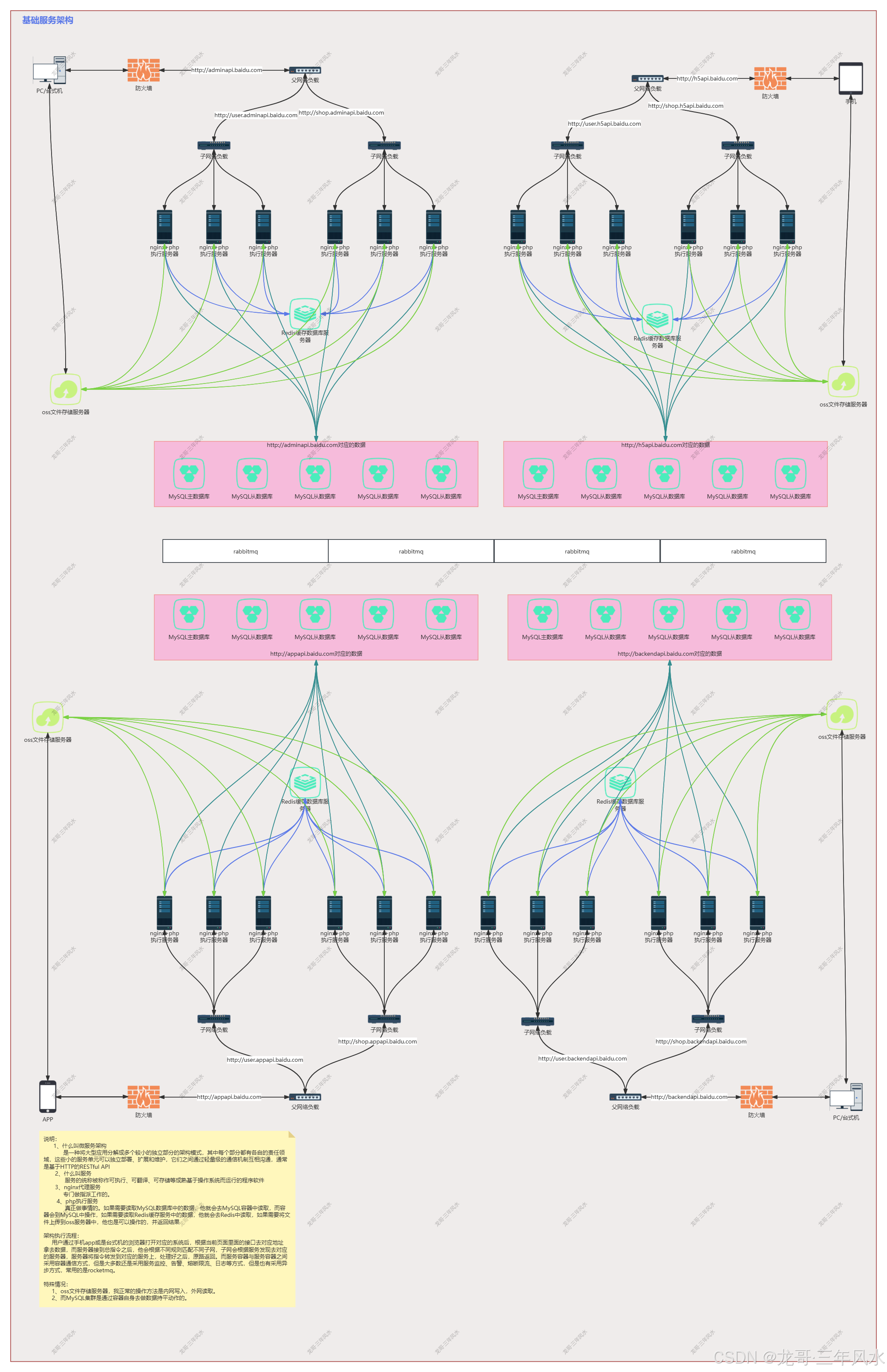
以上是时间成本最低,费用最高(也就是行业中常说的叫能力不够,服务来凑)。
在现实生活中,我的处理方式是优先将一个接口传输1m的数据改成小于100kb一个主请求及剩下的次请求,这样的话,10000个请求还是10000个请求,次请求可以放到下级页面或是额外页面里面去。这样的话,又改成了实例1同等做法。只不过在服务器与带宽上面会增加0.5倍做额外处理,而连接数却是按照(1m*1024kb/100kb*10000)这个公式去计算的。只不过这个场景比上面要多做一些前端页面的调整。这里就需要更改相对应的页面操作流程。 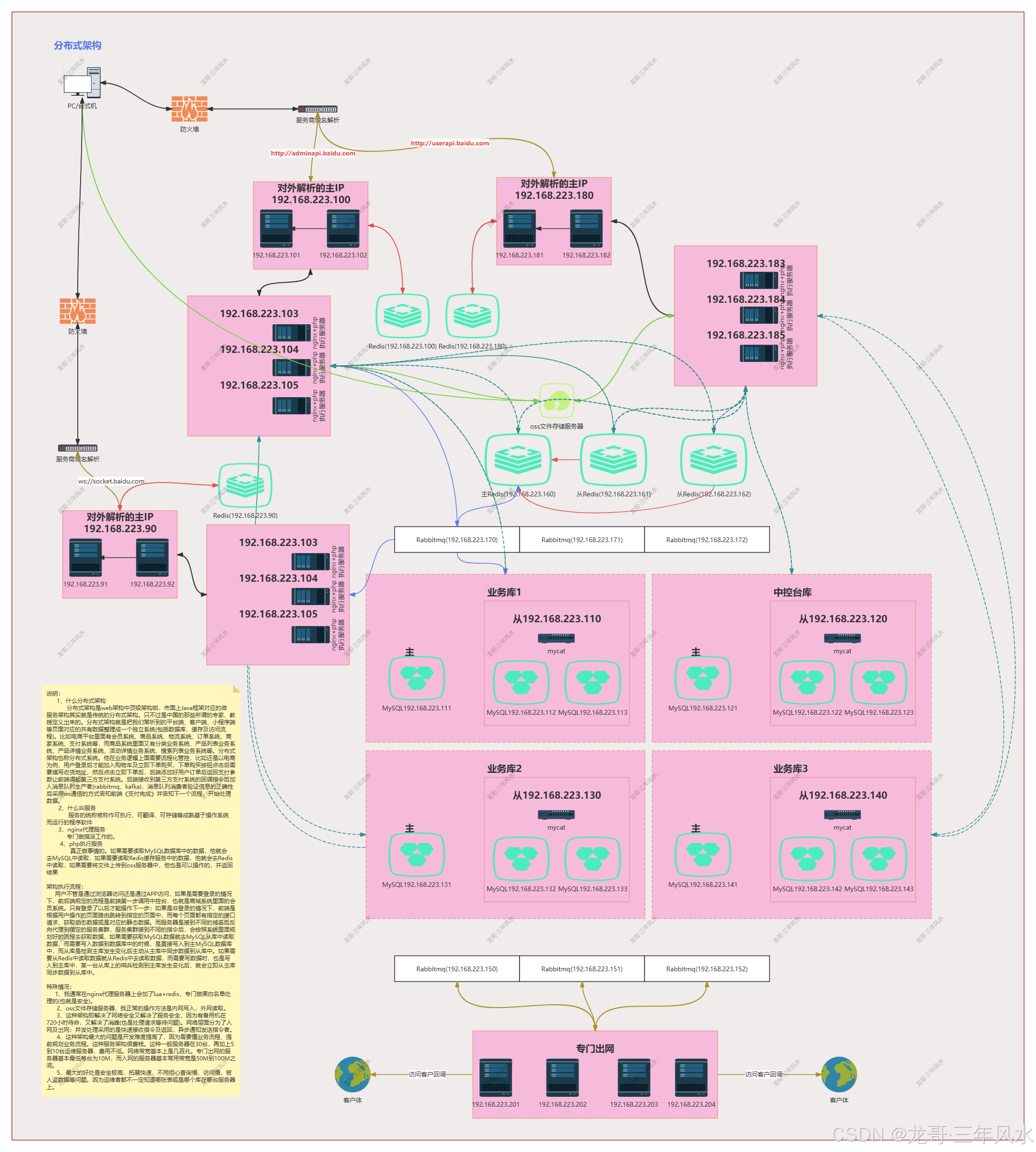
四、总结
通过实例1我能得到:首先要解决nginx负载均衡问题,其次要利用消息队列来实现处理请求的拆分及同步消息给前端,也就是最简单的进程开发。向这种请求量,还需要解决MySQL主从复制、读写分离及高可用问题。因主从复制有延迟问题,然后这里还要解决急时写急时读的问题,正常要用到Redis临时缓存来解决延迟问题或是开启主MySQL读功能。同样也有人会说,Redis单机的情况下,秒处理最低也能做到8万,这里可以不用MySQL主从复制、读写分离及高可用,也就不用解决延迟问题。这种说法我在生活中常常听到。
只是我站在业务架构师的角度来说的话,用Redis这种方案来实现,只能做临时解决问题方案,而不能做系统或是平台或是产品的长久方案。当数据量越来越大的情况下,Redis是无法承受的(内存不够用的原因),还会降低Redis自身性能。如果开启主MySQL读的功能,那样会大大降低MySQL写的能力。其次我还以为,解决问题要考虑长久,而不是这一次,要为后面的系统或是平台或是产品拓展铺路。如果只是一味的解决问题,那么后面会将问题复杂化,而不是简单化。
然后我站在部门管理的角度来说,不是每个公司都有这种场景及应用,员工能通过这种平台、系统、产品学习到有可能一辈子都验证不到的技术或是学不到这样的解决技术。很多技术不是自身不愿意去学,而是压根碰不到这样的场景或是应用,他只能通过网上等途径去听到或是看到这种解决方案,根本就没有机会去实现或是验证解决方案。
最后站在公司的角度来说,这样不仅让员工有了提升技术机会及认知,还能综合提高运营方向(比如系统的稳定性、用户体验感、用户视觉、综合运营方向)
如果是实例2的情况下,还能让前端学到解决并发理论及验证并发理论解决方案。同样也能让产品、设计等学到好的系统需要怎么设计。
综合上面而言,其实我的技术解决方案基本上都是依据队列的工作原理,只不过目前采用的是先进先出数据结构方式。队列的工作原理是只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出属性。而队列的话,一台服务器能启动多个队列;而队列的话,在需要精准锁库存的场景中,他是最安全的,也是最简单的。