2025年AIR SCI1区TOP,具有新变异策略和外部存档机制mLSHADE-SPACMA+数值优化与点云配准,深度解析+性能实测
目录
- 1.摘要
- 2.差分进化算法DE
- 3.LSHADE-SPACMA
- 4.mLSHADE-SPACMA
- 5.结果展示
- 6.参考文献
- 7.代码获取
- 8.读者交流

1.摘要
数值优化和点云配准是人工智能领域中的两个关键研究课题。差分进化算法是一种有效的解决方案,而 LSHADE-SPACMA(CEC2017冠军算法)是一个具有竞争力的差分进化变体。然而LSHADE-SPACMA 在应对这类问题时,其局部开发能力有时仍显不足。本文提出了一种改进LSHADE-SPACMA算法(mLSHADE-SPACMA),用于解决数值优化和点云配准问题。mLSHADE-SPACMA算法提出了一种精确的淘汰与生成机制,用来增强算法的局部开发能力;引入了一种基于改进半参数自适应策略和基于排序的选择压力的变异策略,用来提升算法的进化方向性;提出了一种基于精英个体的外部存档机制,该机制保证了外部种群的多样性,并可加快算法的收敛速度。
2.差分进化算法DE
差分进化(Differential Evolution,DE)是一种经典的基于种群的全局优化算法,适用于各类复杂的数值优化问题(Storn & Price, 1997),该算法通过模拟生物进化过程中的变异、交叉与选择机制,在连续空间中迭代搜索最优解。
变异机制通过种群中个体间的向量差分构造新解,常见5种变异策略:
v i = { x r 1 + F ⋅ ( x r 2 − x r 3 ) DE/rand/1 x best + F ⋅ ( x r 1 − x r 2 ) DE/best/1 x i + F ⋅ ( x r 1 − x i ) + F ⋅ ( x r 2 − x r 3 ) DE/current-to-best/1 x i + F ⋅ ( x r 1 − x r 2 ) + F ⋅ ( x r 3 − x r 4 ) DE/best/2 x r 1 + F ⋅ ( x r 2 − x r 3 ) + F ⋅ ( x r 4 − x r 5 ) DE/rand/2 v_i = \left\{ \begin{array}{ll} x_{r1} + F \cdot (x_{r2} - x_{r3}) & \text{DE/rand/1} \\ x_{\text{best}} + F \cdot (x_{r1} - x_{r2}) & \text{DE/best/1} \\ x_i + F \cdot (x_{r1} - x_i) + F \cdot (x_{r2} - x_{r3}) & \text{DE/current-to-best/1} \\ x_i + F \cdot (x_{r1} - x_{r2}) + F \cdot (x_{r3} - x_{r4}) & \text{DE/best/2} \\ x_{r1} + F \cdot (x_{r2} - x_{r3}) + F \cdot (x_{r4} - x_{r5}) & \text{DE/rand/2} \end{array} \right. vi=⎩ ⎨ ⎧xr1+F⋅(xr2−xr3)xbest+F⋅(xr1−xr2)xi+F⋅(xr1−xi)+F⋅(xr2−xr3)xi+F⋅(xr1−xr2)+F⋅(xr3−xr4)xr1+F⋅(xr2−xr3)+F⋅(xr4−xr5)DE/rand/1DE/best/1DE/current-to-best/1DE/best/2DE/rand/2
交叉机制将突变个体与原始个体组合生成新的候选解:
u i j = { v i j , if rand < C r or j = j rand x i j , otherwise u_i^j = \left\{ \begin{array}{ll} v_i^j, & \text{if } \text{rand} < Cr \text{ or } j = j_{\text{rand}} \\ x_i^j, & \text{otherwise} \end{array} \right. uij={vij,xij,if rand<Cr or j=jrandotherwise
选择机制通过适应度函数)对新产生的后代进行评价。后代中表现出较高适应性的个体,与亲代中最优秀的个体一起被选择形成下一代种群:
x i = { u i , if f ( u i ) ≤ f ( x i ) x i , otherwise x_i = \left\{ \begin{array}{ll} u_i, & \text{if } f(u_i) \leq f(x_i) \\ x_i, & \text{otherwise} \end{array} \right. xi={ui,xi,if f(ui)≤f(xi)otherwise
3.LSHADE-SPACMA
半参数自适应策略
参数配置在差分进化算法中具有决定性作用。研究表明,采用自适应参数策略可以显著提升算法性能,而算法效果的优劣与问题特性高度相关的参数设置密切相关(Das 等,2016)。不同的优化问题往往需要量身定制的参数组合,以实现更优的收敛速度与解质量。LSHADE-SPA 算法引入了一种半参数自适应机制,专门用于调整关键参数 F i F_i Fi和 C R i CR_i CRi,其中对 F i F_i Fi计算方式进行修改,评估次数前一半此策略:
F i = 0.45 + 0.1 ⋅ r a n d , F E s < max F E s / 2 F_i=0.45+0.1\cdot rand,FEs<\max FEs/2 Fi=0.45+0.1⋅rand,FEs<maxFEs/2
LSHADE-SPACMA框架
为提升优化效率,Mohamed 等(2017)提出了一种混合进化框架,将 LSHADE-SPA 与改进的 CMA-ES(协方差矩阵自适应进化策略) 相结合。该框架在 CMA-ES 中引入了交叉操作,以增强算法的全局探索能力。交叉过程在 CMA-ES 步骤后执行,并通过特定公式生成子代个体,从而提升解空间的多样性。
算法以一个统一种群 P P P为基础,其中每个个体可以通过 LSHADE 或 CMA-ES 生成新个体。算法选择是基于一个类别概率变量(FCP)进行的,该变量的取值随机选择自一个记忆槽 MFCP。随着进化的进行,MFCP 会根据各子算法的实际表现动态更新,从而逐步增加对表现更优算法的资源分配比例。记忆槽的更新仅在成功生成新个体的情况下才会触发,用来确保更新机制的有效性与稳定性。
M F C P , g + 1 = ( 1 − c ) ⋅ M F C P , g + c ⋅ Δ A l g 1 M_{FCP,g+1}=(1-c)\cdot M_{FCP,g}+c\cdot\Delta_{Alg1} MFCP,g+1=(1−c)⋅MFCP,g+c⋅ΔAlg1
在该更新机制中,变量向量 c c c用于调节每次更新的幅度。不同变异算子的改进率通过变量 Δ A l g 1 \Delta\mathrm{Alg}_{1} ΔAlg1,该变量衡量算法在相邻两代之间的性能提升情况:
Δ A l g 1 = m i n ( 0.8 , m a x ( 0.2 , ω A l g 1 / ( ω A l g 1 + ω A l g 2 ) ) ) \Delta_{Alg1}=min\left(0.8,max\left(0.2,\omega_{Alg1}/(\omega_{Alg1}+\omega_{Alg2})\right)\right) ΔAlg1=min(0.8,max(0.2,ωAlg1/(ωAlg1+ωAlg2)))
ω A l g 1 \omega\mathrm{Alg}_{1} ωAlg1表示算法 Δ A l g 1 \Delta\mathrm{Alg}_{1} ΔAlg1新旧适应度值之差的累积,作为评价每个个体在该算法下性能变化的指标:
ω A l g 1 = ∑ i = 1 n f ( x i ) − f ( u i ) \omega_{Alg1}=\sum_{i=1}^nf\left(\boldsymbol{x}_i\right)-f\left(\boldsymbol{u}_i\right) ωAlg1=i=1∑nf(xi)−f(ui)
PS:这里 Δ A l g 1 \Delta\mathrm{Alg}_{1} ΔAlg1可以看作反馈驱动的控制策略,类似RL中奖励信号。
4.mLSHADE-SPACMA
尽管 LSHADE-SPACMA 在多种优化任务中表现出色,但在面对复杂或多样化问题时仍存在一定的性能瓶颈。主要问题包括:种群信息利用不充分导致局部搜索能力不足,半参数自适应策略缺乏敏感性分析限制了算法的适应性,以及变异策略引导性较弱和外部存档机制存在随机性风险,可能误删优质个体,从而影响种群多样性与进化质量。mLSHADE-SPACMA引入更精确的个体淘汰与生成机制,提升局部开发能力;设计增强引导性的变异策略,优化搜索方向;优化外部存档更新机制,在保证多样性的同时加快收敛进程。
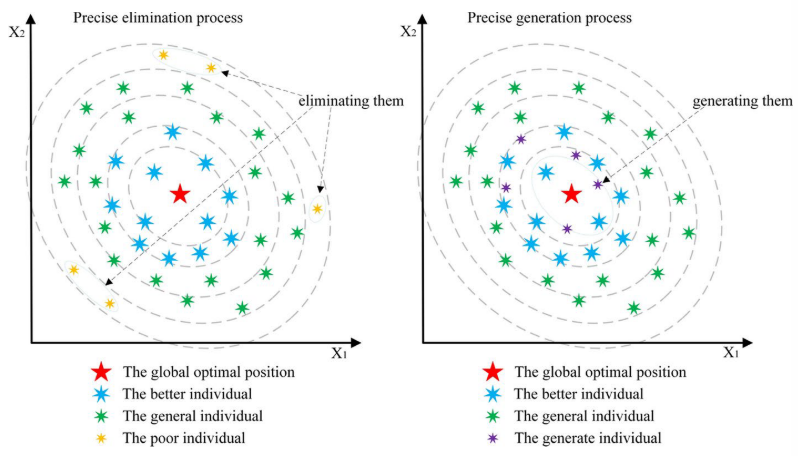
精确的淘汰与生成机制
淘汰种群中适应度最差的个体以及利用精英个体引导进化,已被广泛应用于提升算法性能,但这些方法多数缺乏精确性。在 mLSHADE-SPACMA 中,论文提出了一种精确的淘汰与生成机制,以确保解的高质量,该机制仅在评估过程的前半阶段启用:
P E m = c e i l ( ρ ⋅ N P ) , F E s < max F s / 2 PE_m=ceil\left(\rho\cdot NP\right),FEs<\max Fs/2 PEm=ceil(ρ⋅NP),FEs<maxFs/2
其中, P E m PE_m PEm表示需要淘汰的个体数量, ρ \rho ρ表示需要淘汰的个体占整个种群的百分比。
通过以下生成机制生成等量的新个体:
x i = x best1 + rand ⋅ ( x best1 − x best2 ) , i ∈ { 1 , 2 , … , P E m } , F E s < M a x F E s / 2 x_i = x_{\text{best1}} + \text{rand} \cdot (x_{\text{best1}} - x_{\text{best2}}), \quad i \in \{1, 2, \ldots, P_{Em}\}, \quad FEs < MaxFEs / 2 xi=xbest1+rand⋅(xbest1−xbest2),i∈{1,2,…,PEm},FEs<MaxFEs/2
其中, x b e s t 1 , x b e s t 2 x_{best1},x_{best2} xbest1,xbest2分别表示当前种群中排名第一和第二的优秀个体,该设计不仅使新生成的个体能够继承最强个体的特征,同时通过引入随机扰动因子增强了种群的多样性。
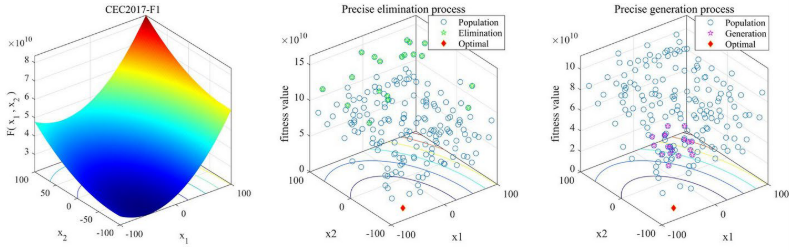
改进半参数自适应策略与RSP变异策略
本文提出了一种新的异策略,用来在保障种群多样性的同时,优化个体的进化方向:
F i = 0.5 + 0.1 ⋅ rand , F E s < M a x F E s / 2 F_i = 0.5 + 0.1 \cdot \text{rand}, \quad FEs < MaxFEs / 2 Fi=0.5+0.1⋅rand,FEs<MaxFEs/2
为提升 LSHADE-SPACMA 的局部开发能力,本文引入了 LSHADE-RSP 中的 RSP(Ranking-based Selective Pressure)策略,并在此基础上设计了新的变异机制:
v i = x i + F i ⋅ ( x pbest − x i ) + F i ⋅ ( x pr1 − x r 2 ) v_i = x_i + F_i \cdot (x_{\text{pbest}} - x_i) + F_i \cdot (x_{\text{pr1}} - x_{r2}) vi=xi+Fi⋅(xpbest−xi)+Fi⋅(xpr1−xr2)
精英存档机制
mLSHADE-SPACMA引入了一种精英存档机制,以确保外部存档中仅保留最优个体,用来优化算法性能,该机制旨在在整个优化过程中,同时保持存档的高质量与多样性,并避免低质量解的持续存在。

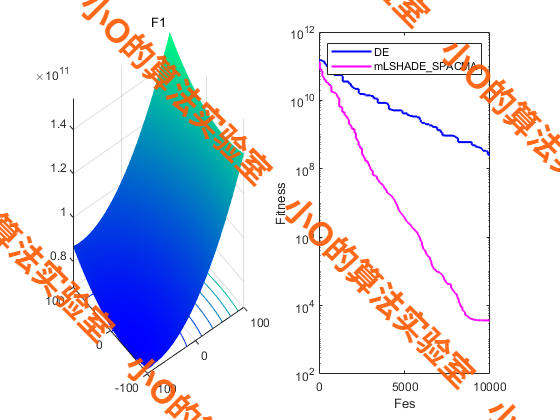
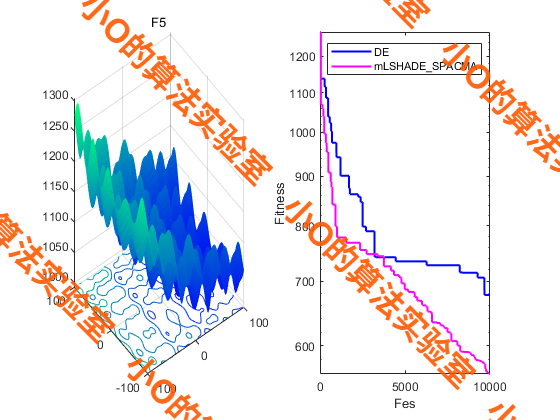
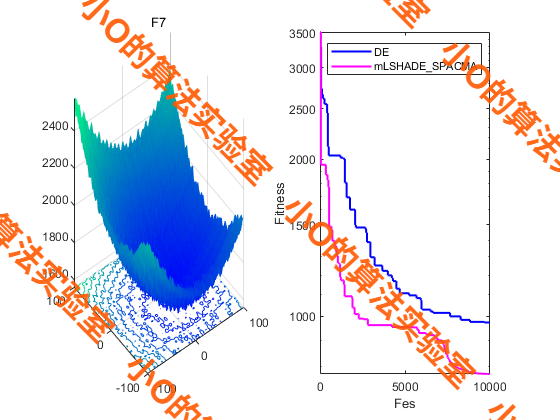
5.结果展示
6.参考文献
[1] Fu S, Ma C, Li K, et al. Modified LSHADE-SPACMA with new mutation strategy and external archive mechanism for numerical optimization and point cloud registration[J]. Artificial Intelligence Review, 2025, 58(3): 72.
7.代码获取
% Source codes demo version 1.0 using matlab2023b
%
% Author and programmer: Shengwei Fu e-Mail: shengwei_fu@163.com
%
% Paper : Modified LSHADE-SPACMA with new mutation strategy and external archive mechanism for numerical optimization and point cloud registration
%
% Journal : Artificial Intelligence Review
%_______________________________________________________________________________________________%%%%%%%%%%%%%%%%%%%
%% This package is a MATLAB/Octave source code of LSHADE-SPACMA which is an improved version of LSHADE.
%% Please see the following paper:
%% * Ali W. Mohamed, Anas A. Hadi, Anas M. Fattouh, and Kamal M. Jambi: L-SHADE with Semi Parameter Adaptation Approach for Solving CEC 2017 Benchmark Problems, Proc. IEEE Congress on Evolutionary Computation (CEC-2017), Spain, June, 2017%% About L-SHADE, please see following papers:
%% Ryoji Tanabe and Alex Fukunaga: Improving the Search Performance of SHADE Using Linear Population Size Reduction, Proc. IEEE Congress on Evolutionary Computation (CEC-2014), Beijing, July, 2014.
%% J. Zhang, A.C. Sanderson: JADE: Adaptive differential evolution with optional external archive,?IEEE Trans Evol Comput, vol. 13, no. 5, pp. 945?58, 2009%% Some code parts were used from:
%% Noor H. Awad, Mostafa Z. Ali, Ponnuthurai N. Suganthan and Robert G. Reynolds: An Ensemble Sinusoidal Parameter Adaptation incorporated with L-SHADE for Solving CEC2014 Benchmark Problems, Proc. IEEE Congress on Evolutionary Computation (CEC-2016), Canada, July, 2016
function [bsf_fit_var,bsf_solution,Conv] = mLSHADE_SPACMA(max_nfes,lb,ub,problem_size,fhd,func)% clc;
% clear all;
%
% format long;
% format compact;
Conv = zeros(1,max_nfes);
L_Rate= 0.80;
k1=3;
val_2_reach = 10^(-8);
% fhd=@cec17_func;
% num_prbs = 30;
% runs =51;
% RecordFEsFactor = ...
% [0.01, 0.02, 0.03, 0.05, 0.1, 0.2, 0.3, 0.4, ...
% 0.5, 0.6, 0.7, 0.8, 0.9, 1.0];
% progress = numel(RecordFEsFactor);% for problem_size = [10 30 50 100]% max_nfes = 10000 * problem_size;rand('seed', sum(100 * clock));% lu = [-100 * ones(1, problem_size); 100 * ones(1, problem_size)];lu = [lb * ones(1, problem_size); ub * ones(1, problem_size)];% fprintf('Running LSHADE-SPACMA algorithm\n')% for func = 1:30optimum = func * 100.0;%% Record the best resultsoutcome = [];% fprintf('\n-------------------------------------------------------\n')% fprintf('Function = %d, Dimension size = %d\n', func, problem_size)% allerrorvals = zeros(progress, runs);% for run_id = 1 : runsnfes = 0;run_funcvals = [];%% parameter settings for L-SHADEp_best_rate = 0.11; arc_rate = 1.4; memory_size = 5; pop_size = 18*problem_size;max_pop_size = pop_size;min_pop_size = 4.0;%% parameter settings for HybridizationFirst_calss_percentage=0.5;%% Initialize the main populationpopold = repmat(lu(1, :), pop_size, 1) + rand(pop_size, problem_size) .* (repmat(lu(2, :) - lu(1, :), pop_size, 1));pop = popold; % the old population becomes the current populationfitness = feval(fhd,pop',func);fitness = fitness';bsf_fit_var = 1e+30;bsf_index = 0;bsf_solution = zeros(1, problem_size);%%%%%%%%%%%%%%%%%%%%%%%% for outfor i = 1 : pop_sizenfes = nfes + 1;if (fitness(i) < bsf_fit_var && isreal(pop(i, :)) && sum(isnan(pop(i, :)))==0 && min(pop(i, :))>=-100 && max(pop(i, :))<=100)bsf_fit_var = fitness(i);bsf_solution = pop(i, :);bsf_index = i;endif nfes > max_nfes;break; endend%%%%%%%%%%%%%%%%%%%%%%%% for outrun_funcvals = [run_funcvals;ones(pop_size,1)*bsf_fit_var];memory_sf = 0.5 .* ones(memory_size, 1);memory_cr = 0.5 .* ones(memory_size, 1);memory_pos = 1;archive.NP = arc_rate * pop_size; % the maximum size of the archivearchive.pop = zeros(0, problem_size); % the solutions stored in te archivearchive.funvalues = zeros(0, 1); % the function value of the archived solutionsmemory_1st_class_percentage = First_calss_percentage.* ones(memory_size, 1); % Class#1 probability for Hybridization %% Initialize CMAES parameterssigma = 0.5; % coordinate wise standard deviation (step size)xmean = rand(problem_size,1); % objective variables initial pointmu = pop_size/2; % number of parents/points for recombinationweights = log(mu+1/2)-log(1:mu)'; % muXone array for weighted recombinationmu = floor(mu);weights = weights/sum(weights); % normalize recombination weights arraymueff=sum(weights)^2/sum(weights.^2); % variance-effectiveness of sum w_i x_i% Strategy parameter setting: Adaptationcc = (4 + mueff/problem_size) / (problem_size+4 + 2*mueff/problem_size); % time constant for cumulation for Ccs = (mueff+2) / (problem_size+mueff+5); % t-const for cumulation for sigma controlc1 = 2 / ((problem_size+1.3)^2+mueff); % learning rate for rank-one update of Ccmu = min(1-c1, 2 * (mueff-2+1/mueff) / ((problem_size+2)^2+mueff)); % and for rank-mu updatedamps = 1 + 2*max(0, sqrt((mueff-1)/(problem_size+1))-1) + cs; % damping for sigma usually close to 1% Initialize dynamic (internal) strategy parameters and constantspc = zeros(problem_size,1);ps = zeros(problem_size,1); % evolution paths for C and sigmaB = eye(problem_size,problem_size); % B defines the coordinate systemD = ones(problem_size,1); % diagonal D defines the scalingC = B * diag(D.^2) * B'; % covariance matrix CinvsqrtC = B * diag(D.^-1) * B'; % C^-1/2eigeneval = 0; % track update of B and DchiN=problem_size^0.5*(1-1/(4*problem_size)+1/(21*problem_size^2)); % expectation of%% main loopHybridization_flag=1; % Indicator flag if we need to Activate CMAES HybridizationConv(1,1:nfes) = min(bsf_fit_var);while nfes < max_nfespop = popold; % the old population becomes the current population[temp_fit, sorted_index] = sort(fitness, 'ascend');if nfes < max_nfes/2num = floor(0.99*pop_size); sorted_index1 = sorted_index(num:end);pop(sorted_index1,:) = repmat(pop(sorted_index(1)), pop_size-num+1, 1) + rand(pop_size-num+1, problem_size) .* (repmat(pop(sorted_index(1)) - pop(sorted_index(2)), pop_size-num+1, 1));endpop = boundConstraint(pop, popold, lb, ub);mem_rand_index = ceil(memory_size * rand(pop_size, 1));mu_sf = memory_sf(mem_rand_index);mu_cr = memory_cr(mem_rand_index);mem_rand_ratio = rand(pop_size, 1);%% for generating crossover ratecr = normrnd(mu_cr, 0.1);term_pos = find(mu_cr == -1);cr(term_pos) = 0;cr = min(cr, 1);cr = max(cr, 0);%% for generating scaling factorif(nfes <= 0.5*max_nfes)sf=0.5+.1*rand(pop_size, 1);pos = find(sf <= 0);while ~ isempty(pos)sf(pos)=0.5+0.1*rand(length(pos), 1);pos = find(sf <= 0);endelsesf = mu_sf + 0.1 * tan(pi * (rand(pop_size, 1) - 0.5));pos = find(sf <= 0);while ~ isempty(pos)sf(pos) = mu_sf(pos) + 0.1 * tan(pi * (rand(length(pos), 1) - 0.5));pos = find(sf <= 0);endendsf = min(sf, 1);%% for generating Hybridization Class probabilityClass_Select_Index=(memory_1st_class_percentage(mem_rand_index)>=mem_rand_ratio);if(Hybridization_flag==0)Class_Select_Index=or(Class_Select_Index,~Class_Select_Index);%All will be in class#1end%%r0 = [1 : pop_size];popAll = [pop; archive.pop];[r1, r2] = gnR1R2(pop_size, size(popAll, 1), r0);pNP = max(round(p_best_rate * pop_size), 2); %% choose at least two best solutionsrandindex = ceil(rand(1, pop_size) .* pNP); %% select from [1, 2, 3, ..., pNP]randindex = max(1, randindex); %% to avoid the problem that rand = 0 and thus ceil(rand) = 0pbest = pop(sorted_index(randindex), :); %% randomly choose one of the top 100p% solutionsRi1=1:pop_size;Rank1=k1*(pop_size-Ri1)+1;Pr1=Rank1./sum(Rank1);pop1 = [];r11 =randsample(pop_size,pop_size,true,Pr1); for j = 1:pop_size jj = r11(j) ;pop1(j,:) = pop(sorted_index(jj), :);endvi=[];temp=[];if(sum(Class_Select_Index)~=0)% vi(Class_Select_Index,:) = pop(Class_Select_Index,:) + sf(Class_Select_Index, ones(1, problem_size)) .* (pbest(Class_Select_Index,:) - pop(Class_Select_Index,:) + pop(r1(Class_Select_Index), :) - popAll(r2(Class_Select_Index), :));vi(Class_Select_Index,:) = pop(Class_Select_Index,:) + sf(Class_Select_Index, ones(1, problem_size)) .* (pbest(Class_Select_Index,:) - pop(Class_Select_Index,:) + pop1((Class_Select_Index), :) - popAll(r2(Class_Select_Index), :));endif(sum(~Class_Select_Index)~=0)for k=1:sum(~Class_Select_Index)temp(:,k) = xmean + sigma * B * (D .* randn(problem_size,1)); % m + sig * Normal(0,C)endvi(~Class_Select_Index,:) = temp';endif(~isreal(vi))Hybridization_flag=0;continue;end% vi = boundConstraint(vi, pop, lu);vi = boundConstraint(vi, pop, lb, ub);mask = rand(pop_size, problem_size) > cr(:, ones(1, problem_size)); % mask is used to indicate which elements of ui comes from the parentrows = (1 : pop_size)'; cols = floor(rand(pop_size, 1) * problem_size)+1; % choose one position where the element of ui doesn't come from the parentjrand = sub2ind([pop_size problem_size], rows, cols); mask(jrand) = false;ui = vi; ui(mask) = pop(mask);children_fitness = feval(fhd, ui', func);children_fitness = children_fitness';nfes1=nfes;%%%%%%%%%%%%%%%%%%%%%%%% for outfor i = 1 : pop_sizenfes = nfes + 1;if (children_fitness(i) < bsf_fit_var && isreal(ui(i, :)) && sum(isnan(ui(i, :)))==0 && min(ui(i, :))>=-100 && max(ui(i, :))<=100)bsf_fit_var = children_fitness(i);bsf_solution = ui(i, :);bsf_index = i;endif nfes > max_nfes;break;endendConv(1,nfes1:nfes) = bsf_fit_var;%%%%%%%%%%%%%%%%%%%%%%%% for outrun_funcvals = [run_funcvals;ones(pop_size,1)*bsf_fit_var];dif = abs(fitness - children_fitness);%% I == 1: the parent is better; I == 2: the offspring is betterChild_is_better_index = (fitness > children_fitness);goodCR = cr(Child_is_better_index == 1);goodF = sf(Child_is_better_index == 1);dif_val = dif(Child_is_better_index == 1);dif_val_Class_1 = dif(and(Child_is_better_index,Class_Select_Index) == 1);dif_val_Class_2 = dif(and(Child_is_better_index,~Class_Select_Index) == 1);archive = updateArchive(archive, popold(Child_is_better_index == 1, :), fitness(Child_is_better_index == 1));[fitness, Child_is_better_index] = min([fitness, children_fitness], [], 2);popold = pop;popold(Child_is_better_index == 2, :) = ui(Child_is_better_index == 2, :);num_success_params = numel(goodCR);if num_success_params > 0sum_dif = sum(dif_val);dif_val = dif_val / sum_dif;%% for updating the memory of scaling factormemory_sf(memory_pos) = (dif_val' * (goodF .^ 2)) / (dif_val' * goodF);%% for updating the memory of crossover rateif max(goodCR) == 0 || memory_cr(memory_pos) == -1memory_cr(memory_pos) = -1;elsememory_cr(memory_pos) = (dif_val' * (goodCR .^ 2)) / (dif_val' * goodCR);endif (Hybridization_flag==1)% if the Hybridization is activatedmemory_1st_class_percentage(memory_pos) = memory_1st_class_percentage(memory_pos)*L_Rate+ (1-L_Rate)*(sum(dif_val_Class_1) / (sum(dif_val_Class_1) + sum(dif_val_Class_2)));memory_1st_class_percentage(memory_pos)=min(memory_1st_class_percentage(memory_pos),0.8);memory_1st_class_percentage(memory_pos)=max(memory_1st_class_percentage(memory_pos),0.2);endmemory_pos = memory_pos + 1;if memory_pos > memory_size; memory_pos = 1; endend%% for resizing the population sizeplan_pop_size = round((((min_pop_size - max_pop_size) / max_nfes) * nfes) + max_pop_size);if pop_size > plan_pop_sizereduction_ind_num = pop_size - plan_pop_size;if pop_size - reduction_ind_num < min_pop_size; reduction_ind_num = pop_size - min_pop_size;endpop_size = pop_size - reduction_ind_num;for r = 1 : reduction_ind_num[valBest, indBest] = sort(fitness, 'ascend');worst_ind = indBest(end);popold(worst_ind,:) = [];pop(worst_ind,:) = [];fitness(worst_ind,:) = [];Child_is_better_index(worst_ind,:) = [];endarchive.NP = round(arc_rate * pop_size);if size(archive.pop, 1) > archive.NP% rndpos = randperm(size(archive.pop, 1));% rndpos = rndpos(1 : archive.NP);% archive.pop = archive.pop(rndpos, :);[~, sortIdx] = sort(archive.funvalues);bestIdx = sortIdx(1:archive.NP);archive.pop = popAll(bestIdx, :);archive.funvalues = archive.funvalues(bestIdx, :); end%% update CMA parametersmu = pop_size/2; % number of parents/points for recombination weights = log(mu+1/2)-log(1:mu)'; % muXone array for weighted recombinationmu = floor(mu);weights = weights/sum(weights); % normalize recombination weights arraymueff=sum(weights)^2/sum(weights.^2); % variance-effectiveness of sum w_i x_iend%% CMAES Adaptationif(Hybridization_flag==1)% Sort by fitness and compute weighted mean into xmean[~, popindex] = sort(fitness); % minimizationxold = xmean;xmean = popold(popindex(1:mu),:)' * weights; % recombination, new mean value% Cumulation: Update evolution pathsps = (1-cs) * ps ...+ sqrt(cs*(2-cs)*mueff) * invsqrtC * (xmean-xold) / sigma;hsig = sum(ps.^2)/(1-(1-cs)^(2*nfes/pop_size))/problem_size < 2 + 4/(problem_size+1);pc = (1-cc) * pc ...+ hsig * sqrt(cc*(2-cc)*mueff) * (xmean-xold) / sigma;% Adapt covariance matrix Cartmp = (1/sigma) * (popold(popindex(1:mu),:)' - repmat(xold,1,mu)); % mu difference vectorsC = (1-c1-cmu) * C ... % regard old matrix+ c1 * (pc * pc' ... % plus rank one update+ (1-hsig) * cc*(2-cc) * C) ... % minor correction if hsig==0+ cmu * artmp * diag(weights) * artmp'; % plus rank mu update% Adapt step size sigmasigma = sigma * exp((cs/damps)*(norm(ps)/chiN - 1));% Update B and D from Cif nfes - eigeneval > pop_size/(c1+cmu)/problem_size/10 % to achieve O(problem_size^2)eigeneval = nfes;C = triu(C) + triu(C,1)'; % enforce symmetryif(sum(sum(isnan(C)))>0 || sum(sum(~isfinite(C)))>0 || ~isreal(C))Hybridization_flag=0;continue;end[B,D] = eig(C); % eigen decomposition, B==normalized eigenvectorsD = sqrt(diag(D)); % D contains standard deviations nowinvsqrtC = B * diag(D.^-1) * B';endendend %%%%%%%%nfes%% Violation Checkingif(max(bsf_solution)>100)fprintf('%d th run, Above Max\n', run_id)endif(min(bsf_solution)<-100)fprintf('%d th run, Below Min\n', run_id)endif(~isreal(bsf_solution))fprintf('%d th run, Complix\n', run_id)endbsf_error_val = abs(bsf_fit_var - optimum);if bsf_error_val < val_2_reachbsf_error_val = 0;endif(sum(isnan(bsf_solution))>0)fprintf('%d th run, NaN\n', run_id)end% fprintf('%d th run, best-so-far error value = %1.8e\n', run_id , bsf_error_val)outcome = [outcome bsf_error_val];Conv = Conv(1,1:max_nfes); Conv(1,max_nfes) = bsf_fit_var;%% From Noor Code ( print files )% errorVals= [];% for w = 1 : progress% bestold = run_funcvals(RecordFEsFactor(w) * max_nfes) - optimum;% if abs(bestold)>1e-8% errorVals(w)= abs(bestold);% else% bestold=0;% errorVals(w)= bestold;% end% end% allerrorvals(:, run_id) = errorVals;% end %% end 1 run% fprintf('\n')% fprintf('min error value = %1.8e, max = %1.8e, median = %1.8e, mean = %1.8e, std = %1.8e\n', min(outcome), max(outcome), median(outcome), mean(outcome), std(outcome))% % % file_name=sprintf('Results\\LSHADE_SPACMA_CEC2017_Problem#%s_problemSize#%s',int2str(func),int2str(problem_size));% save(file_name,'outcome', 'allerrorvals');% % % file_name=sprintf('Results\\LSHADE_SPACMA_%s_%s.txt',int2str(func),int2str(problem_size));% save(file_name, 'allerrorvals', '-ascii');% end %% end 1 function run% end
endfunction [r1, r2] = gnR1R2(NP1, NP2, r0)% gnA1A2 generate two column vectors r1 and r2 of size NP1 & NP2, respectively
% r1's elements are choosen from {1, 2, ..., NP1} & r1(i) ~= r0(i)
% r2's elements are choosen from {1, 2, ..., NP2} & r2(i) ~= r1(i) & r2(i) ~= r0(i)
%
% Call:
% [r1 r2 ...] = gnA1A2(NP1) % r0 is set to be (1:NP1)'
% [r1 r2 ...] = gnA1A2(NP1, r0) % r0 should be of length NP1
%
% Version: 2.1 Date: 2008/07/01
% Written by Jingqiao Zhang (jingqiao@gmail.com)NP0 = length(r0);r1 = floor(rand(1, NP0) * NP1) + 1;
%for i = 1 : inf
for i = 1 : 99999999pos = (r1 == r0);if sum(pos) == 0break;else % regenerate r1 if it is equal to r0r1(pos) = floor(rand(1, sum(pos)) * NP1) + 1;endif i > 1000, % this has never happened so farerror('Can not genrate r1 in 1000 iterations');end
endr2 = floor(rand(1, NP0) * NP2) + 1;
%for i = 1 : inf
for i = 1 : 99999999pos = ((r2 == r1) | (r2 == r0));if sum(pos)==0break;else % regenerate r2 if it is equal to r0 or r1r2(pos) = floor(rand(1, sum(pos)) * NP2) + 1;endif i > 1000, % this has never happened so farerror('Can not genrate r2 in 1000 iterations');end
end
endfunction archive = updateArchive(archive, pop, funvalue)
% Update the archive with input solutions
% Step 1: Add new solution to the archive
% Step 2: Remove duplicate elements
% Step 3: If necessary, randomly remove some solutions to maintain the archive size
%
% Version: 1.1 Date: 2008/04/02
% Written by Jingqiao Zhang (jingqiao@gmail.com)if archive.NP == 0, return; endif size(pop, 1) ~= size(funvalue,1), error('check it'); end% Method 2: Remove duplicate elements
popAll = [archive.pop; pop ];
funvalues = [archive.funvalues; funvalue ];
[dummy IX]= unique(popAll, 'rows');
if length(IX) < size(popAll, 1) % There exist some duplicate solutionspopAll = popAll(IX, :);funvalues = funvalues(IX, :);
endif size(popAll, 1) <= archive.NP % add all new individualsarchive.pop = popAll;archive.funvalues = funvalues;
else % randomly remove some solutions% rndpos = randperm(size(popAll, 1)); % equivelent to "randperm";% rndpos = rndpos(1 : archive.NP);% % archive.pop = popAll (rndpos, :);% archive.funvalues = funvalues(rndpos, :);[~, sortIdx] = sort(funvalues);% Select the best NP solutions
bestIdx = sortIdx(1:archive.NP);% Update archive
archive.pop = popAll(bestIdx, :);
archive.funvalues = funvalues(bestIdx, :);end
endfunction vi = boundConstraint (vi, pop, lb,ub)% if the boundary constraint is violated, set the value to be the middle
% of the previous value and the bound
%
% Version: 1.1 Date: 11/20/2007
% Written by Jingqiao Zhang, jingqiao@gmail.com[NP, D] = size(pop); % the population size and the problem's dimension%% check the lower bound
% xl = repmat(lb, NP, 1);
% pos = vi < xl;
% vi(pos) = (pop(pos) + xl(pos)) / 2;for i = 1:NPfor j = 1:Dif vi(i,j) < lbvi(i,j) = (pop(i,j)+lb)/2;endend
end%% check the upper bound
% xu = repmat(ub, NP, 1);
% pos = vi > xu;
% vi(pos) = (pop(pos) + xu(pos)) / 2;for i = 1:NPfor j = 1:Dif vi(i,j) > ubvi(i,j) = (pop(i,j)+ub)/2;endend
end
end