初识Linux · 传输层协议TCP · 下
目录
前言:
滑动窗口和流量控制机制
流量控制
滑动窗口
1.滑动窗口如何移动
2.滑动窗口的大小如何变化的
3.如果发生了丢包如何解决(快重传)
拥塞控制
延迟应答
面向字节流
RST PSH URG
什么是 PSH?
什么是 URG?
那这俩标志会不会冲突?
对比表格:
RST 一般啥时候出现?
1. 你给了我一个莫名其妙的连接
2. 应用层拒绝服务
3. 半开连接或 zombie 连接清理
看到 RST 要不要慌?
前言:
前文我们从TCP的报头字段开始介绍,从最开始的首部长度,到16位的源端口号和目的端口号,然后逐渐从TCP的缓存管理机制开始理解TCP报头中的标志位ACK,并且顺便引出了32位的序号和确认序号,从中我们知道了TCP管理报文的时候是依赖的环形缓冲队列,并且报文是以sk_buff的结构体的形式管理起来的。
前文最后的大头是三次握手和四次挥手,从三次握手我们理解了标志位SYN,顺带理解了什么是超时重传和知道如果连接异常,那么标志位RST会设置为1,重新建立连接。从四次挥手,我们理解了FIN标志位,理解并且验证了三种状态TIME_WAIT,CLOSE_WAIT,LAST_ACK。
那么本文,介绍TCP的其他策略,如滑动窗口,快重传,流量控制,拥塞控制,TCP的异常情况,延迟应答,粘包问题和什么是面向字节流~
干货较多~我们直接进入主题吧!
滑动窗口和流量控制机制
流量控制
对于流量控制来说,在网络世界中,报文的发送是无时无刻的,那么报文的数量控制就成为了一个很重要的点,如果报文发送的数量控制不好,就会导致网络拥塞。
我们来只有两台主机的情况来说,对于主机A和主机B,主机A的接收缓冲区空间是有限的,如果主机B无限制的往主机A中发送报文,那么势必会导致主机B迟迟收不到多余报文的ACK报文,因为主机A处理不过来了,最后导致的结果就是主机B不停的触发超时重传机制,这对网络资源来说无疑是一种浪费,所以两台主机来说有一个很重要的工作就是确认双方的接收缓冲区的大小,那么在什么时候确认就成为了一个比较重要的问题。
实际中,在双方三次握手建立连接的时候,就会通过对方的ACK报文来确定对方的接收缓冲区的大小。
确定了对方的接收缓冲区的大小,就是如何进行报文传输控制了,那么对于流量控制来说,滑动窗口就是它的核心机制之一。
滑动窗口
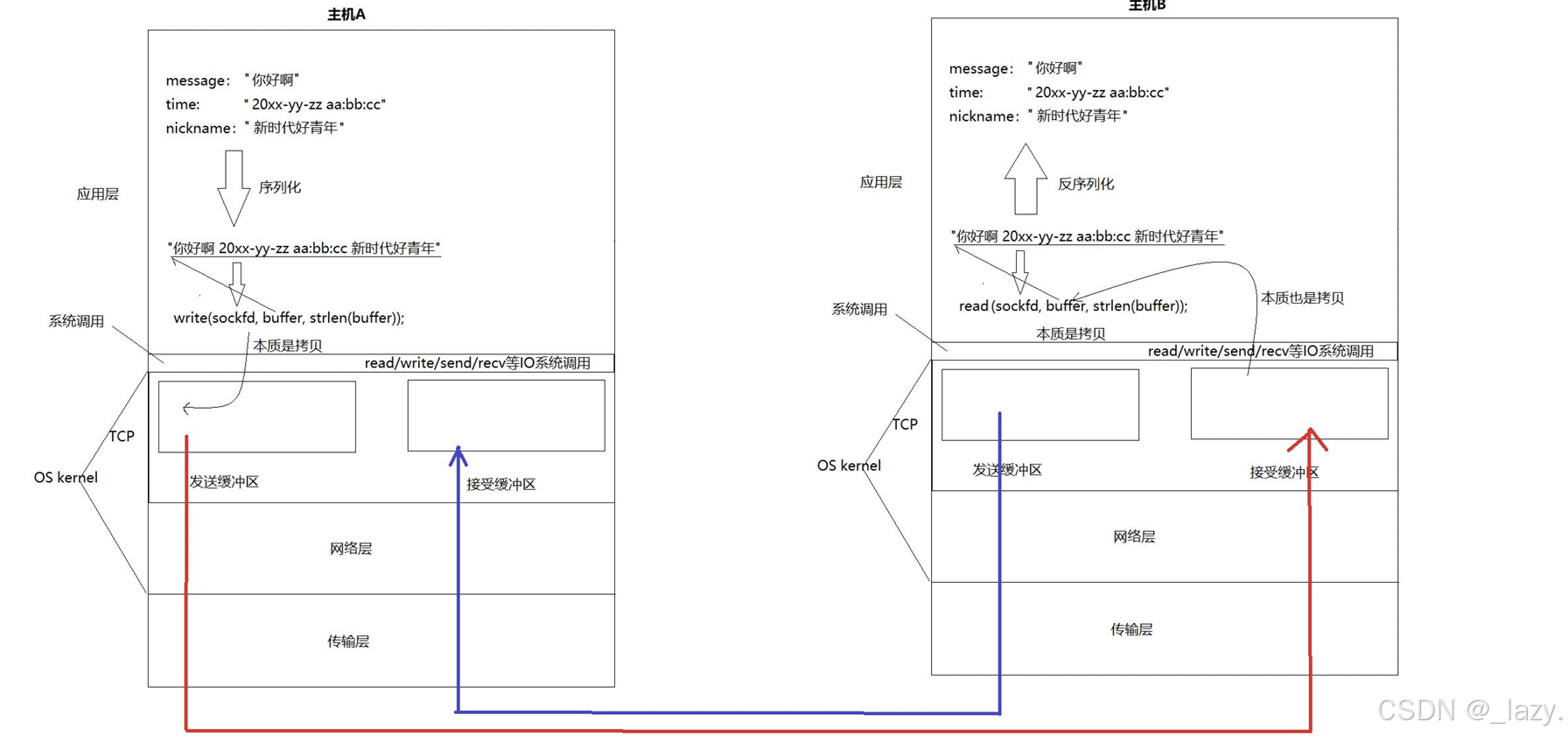
介绍滑动窗口之前,相信大家都有一个共同的认识就是在应用层调用read和write的接口的时候,实际上都是在内核中拷贝发送缓冲区和接收缓冲区中的数据,那么问题来了,我们前面不管是介绍确认应答机制还是捎带应答机制,都是基于对方接收缓冲区有足够的空间的情况,如果对方的接收缓冲区没有足够的空间,我们是否还能“无所畏惧”的发送报文?
所以从这里我们得出:发送报文之前,对方的接收能力如何?在后面我们介绍拥塞控制的时候,我们还会考虑到网络状况。
那么影响发送报文的大体可以分为:对方的接受能力和网络状况。
在前文我们也形象的描述了OS是如何组织报文的,一个环形队列,那么为了方便学习,我们可以给它简化为一个数组:
形象一点,我们把这里的滑动窗口理解为现实的一个窗口,直接套在了这个数组的上面。而这个滑动窗口套住的就是数据,我们发送缓冲区的数据分为三部分:滑动窗口左边的数据,是已发送已确认的,滑动窗口内部的数据是已发送暂时未确认的,滑动窗口右边的数据是未发送未确认的。
问题来了:滑动窗口的大小我们怎么确定呢?我们通过什么属性来确定呢?
对于滑动窗口的大小,我们在TCP的报头中看到过一个字段叫做16位的窗口大小,而每次发送报文的时候,TCP会在报文中实时更新这个属性的大小,那么,另一方接收到了报头,一看16位窗口大小,就知道自己应该发送多少数据了。
而我们在前文所说的,发送报文我们要考虑对方的接收能力,这个接收能力,难道不就是对方的接收缓冲区的大小吗?所以,滑动窗口的大小,依赖于对方的接收缓冲区的大小。
那么我们肯定不能光这么说,因为即便是对于抽象的连接来说,也是通过内核数据结构描述的,对于协议也是通过udphdr tcphdr进行描述的,对于滑动窗口的大小,我们暂时认为是对方同步给我们的接收缓冲区的大小。
目前对滑动窗口的理解,我们可以列出以下的问题:滑动窗口如何移动?滑动窗口的大小如何变化?滑动窗口可以为0吗?如果发生了丢包,如何解决?
1.滑动窗口如何移动
对于如何移动的问题,首先,我们规定滑动窗口是只能向左移动,不能向右移动,因为发送缓冲区中的数据都是明确规定了应答和发送的关系的,如果滑动窗口向右移动,势必就破坏了规定。
2.滑动窗口的大小如何变化的
滑动窗口的大小我们在逻辑上可以简单的使用win_start和win和win_end简单来代表窗口的起点,窗口大小,窗口结束位置,但是实际上,如果我们阅读源码,我们会发现TCP报头中的16位窗口大小和源码中的窗口大小属性对不上:
/** RFC793 variables by their proper names. This means you can* read the code and the spec side by side (and laugh ...)* See RFC793 and RFC1122. The RFC writes these in capitals.*/u32 rcv_nxt; /* What we want to receive next */u32 copied_seq; /* Head of yet unread data */u32 rcv_wup; /* rcv_nxt on last window update sent */u32 snd_nxt; /* Next sequence we send */u32 snd_una; /* First byte we want an ack for */u32 snd_sml; /* Last byte of the most recently transmitted small packet */u32 rcv_tstamp; /* timestamp of last received ACK (for keepalives) */u32 lsndtime; /* timestamp of last sent data packet (for restart window) */这是滑动窗口在Linux内核中的定义,版本为2.62.32,我们发现好像窗口的属性基本都是32位的,它们对不上的原因实际上是因为我们没有介绍TCP中的选项,选项里由一个叫做“窗口扩大因子”,这个扩大因子,就可以让窗口大小从65535一直到1GB左右,所以我们在源码中看到的实际上是32位。
当接收方收到了报文,并且给发送方返回报文,其中有确认序号,这个确认序号恰好代表了发送方在滑动窗口内的哪些数据被接收了,那么有了确认序号,也就是ack_seq,win_start = ack_seq, 更新窗口的起始位置,因为我们能通过确认序号确定之前的数据接收方都收到了,所以此时满足窗口左边的数据是已发送已确认的,然后win_end = win_start + win,通过对方的ACK报文,我们有它的窗口大小,那么我们已经确定了窗口的起始位置,所以可以通过对方的窗口大小确定,win_end的位置。
这是窗口的大小变化,那么有意思的来了,我们在第一个小问题中知道窗口是只能往右边移动的,那么移动的快慢,是取决于win_start, win_end的,那么如果,对方的返回的窗口大小为0,也处理了一定的报文,那么,它返回的确认序号是不是会更新?win_start就会更新,win_start更新了,但是win为0,那么win_start = win_end,此时窗口大小不就为0吗?
那么问题来了,滑动窗口的移动快慢,实际上看的不就是win_start++和win_end谁更新的更快,更多吗?
而在源码的角度来看,win_start和win_end实际上就是序号之间的加法而已,所以源码中的属性基本都是和序号有关的,当然有时间戳变量我们暂时先不管。
3.如果发生了丢包如何解决(快重传)
这个问题才是滑动窗口中问题的重中之重了,对于发送缓冲区的数据,我们可以分为滑动窗口左边的数据,滑动窗口内部的数据,滑动窗口右边的数据,那么实际要发送的数据是滑动窗口内部的报文,对于内部的报文,我们可以这样排序,最左侧的报文,中间的报文,最右侧的报文,我们从三个角度来考虑,如果发生了丢包,我们如何解决?
对于最左侧的报文丢失:
假设发送2001 3001 4001 5001,而实际情况是2001-3000的报文收到,3001到4000的报文收到,4001到5000的报文收到,1001到2000的报文丢失了,此时会返回三个报文的确认序号不会是3001 4001 5001,因为1001到2000的报文丢失,在前文我们已经介绍了确认序号要保证的是TCP的可靠性,这个可靠性实际上是保证的历史报文能被收到,所以实际上三个ACK报文的确认序号是1001,因为1-1001的报文是已经发送,并且已经确定了,对于1001-2000的报文没有收到,为了可靠性,所以确认序号应该为1001。
此时,因为三个ACK报文的确认序号都是1001,OS就知道1001-2000的报文没有收到,所以此时就触发高速重发机制,即快重传,那么快重传的触发条件也很明显,OS连续收到三个同样确认序号的报文,就会根据实际情况看是否触发快重传了。
那么有意思来了,我们前文学习过超时重传机制,超时重传机制和快重传的机制有什么区别呢?或者说它们的应用场景有什么不同。
我们不妨把超时重传机制理解为兜底的机制,同样都是重传,因为超时重传机制等待的时间较久,在系统中配置了对应的超时时间,过了这个时间没收到应答在重传,而快重传是连续收到多个一样的确认序号,此时直接重传,不用等待那么久的超时时间。那么它在一定程度上提高了重传的效率,主要是因为它提前判断,响应的更快了。
在TCP中结合了这两个机制,在提高重传效率的同时,也有保底机制,极大程度上保证了TCP的效率和可靠性。
对于丢包还有一个小小的问题,如果是ACK丢失了呢?也就是说返回的是2001 3001 5001,其中丢了某个应答,是完全没有关系的,因为TCP的可靠传输。
好了,视角放到中间报文丢失和右侧报文丢失,不管了哪一侧报文丢失,左侧的数据成功发送并应答,那么滑动窗口就会通过确认序号更新,测试win_start变为新的确认序号,此时问题就演化为了最左侧的报文丢失应该怎么办?就和我们上面的问题形成了完美闭环!
那么问题来了,丢失的报文,我们放在哪儿?已发送已确认的报文,我们怎么处理?
首先对于第一个问题,丢失的报文,我们放在哪儿?当一个报文段丢失时,TCP 不会立刻把它移出窗口,而是将它保留在发送窗口区间内,等待超时重传或者重传就可以了嘛。
对于第二个问题,已经被接收方确认(ACK)的数据,就说明这段数据已经“安全送达”了。此时 TCP 会将它从发送缓存中移除,释放内存。而用于发送的缓冲区通常是一个环形缓冲区,指针会不断向前推进,旧位置的数据会被新数据覆盖。
这就像写磁带一样,头部已经播放完的内容,可以被下一段录音覆盖,节省空间又高效。
TCP 的滑动窗口不仅用于控制发送速率,还承担了“数据暂存与重发控制”的职责。
拥塞控制
前文我们说暂时认为滑动窗口的大小是对方的接收缓冲区的大小,但是实际情况上,我们考虑了双方主机的通信能力,却忘记了网络的状态,比如网络拥塞怎么办,网络波动了怎么办?
对于滑动窗口的介绍,我们都是基于网络状况良好的情况下,现在局域网内存在多台主机,而网络资源是有效的,比如网络带宽,所以势必会存在一种情况为:多台主机共享网络资源,导致主机之间通信速度变慢。
所以我们需要合理的策略来解决拥塞的问题,就像堵车的马路上会引入交警这个角色一样,来解决拥堵的问题。
首先,在多台主机通信之前,都会获取窗口大小来了对方的接收缓冲区,但是实际上,滑动窗口的大小并不是完全取决于对方的接收缓冲区的,因为要考虑网络资源,所以引入了拥塞窗口的概念,同样,在tcp_sock中描述了滑动窗口的,也描述了拥塞窗口:
/** Slow start and congestion control (see also Nagle, and Karn & Partridge)*/u32 snd_ssthresh; /* Slow start size threshold */u32 snd_cwnd; /* Sending congestion window */u32 snd_cwnd_cnt; /* Linear increase counter */u32 snd_cwnd_clamp; /* Do not allow snd_cwnd to grow above this */u32 snd_cwnd_used;u32 snd_cwnd_stamp;
其中cwnd代表的就是拥塞的意思。
其中snd_ssthresh代表的是慢启动门限值,snd_cwnd代表的是当前拥塞窗口的大小,snd_swnd_cnt代表的是每次收到ACK就+1,到了一定的程度就会进行线性增长。snd_cwnd_clamp代表的是拥塞窗口的最大值。
同学们也注意到了,对于以上的字段,都是用来描述拥塞窗口的,并且引入了慢启动算法,我们以下面的图介绍拥塞避免: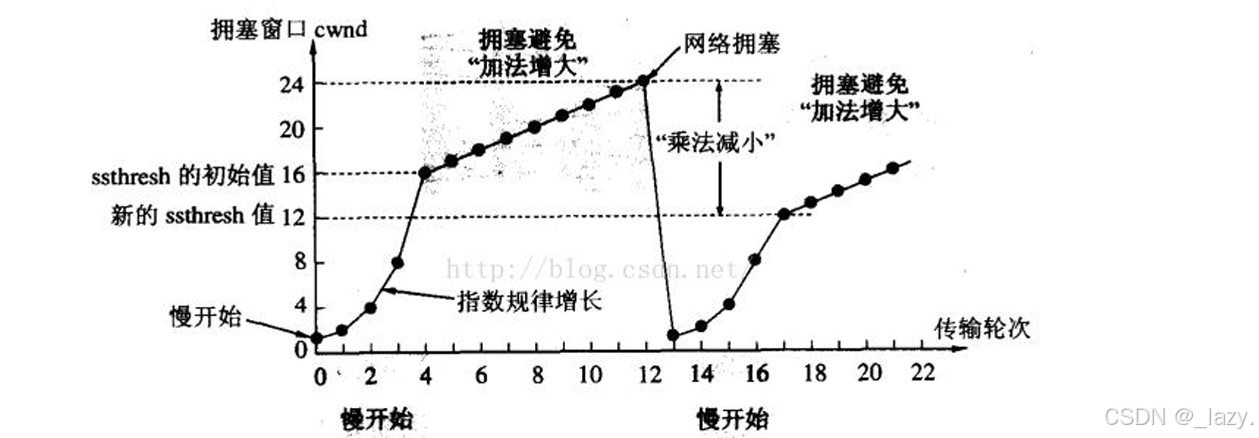
首先我们清楚滑动窗口大小=min(对方接收能力,拥塞窗口),那么在通信初期,对方的接收能力可以说是杠杠的,因为初期的报文积攒并不多,所以可以说接收空间非常大。
但是可以很负责任的说,不考虑拥塞窗口的传输都是耍流氓,你别看别人的接受能力那么强你就使劲发报文,比如两个地点,中间有一条马路,A点可以放100辆车,那么你难道就知道整100辆车过去吗?显然不能,因为马路不足以支撑100辆车,而实际上也有别的车要通过,所以我们初期需要发报文探测实际能通过多少车。
网络也是如此,初期从1个报文开始发送,然后按照指数级别增长,为什么不线性增长呢?因为通信的时候,我们虽然要考虑拥塞的问题,但是同时也要兼顾效率,所以前期,是按照指数增长的。那么增长到了ssthresh的时候,就开始按照线性增长了,因为再double一下,就超出了拥塞窗口的范围了。线性增长的过程我们叫做加法增大。
而一直加大的过程,总会碰到网络拥塞的时候,此时直接跌到1,重新探测网络状态,并且设置了新的临界值,跌到1的这个过程我们称为乘法减小。
以上的图我们看到的是拥塞避免算法AIMD的核心框架,实际上最后拥塞窗口的值会处于一个带宽的某个极限值震荡,以保证通信的稳定传输。
有个问题就是,我们如何确认是网络拥塞了呢?对于少量的丢包,我们可以认为是网络波动,并且采取超时重传或者是快重传的方式解决,但是如果是大量丢包,我们就有理由认为是网络拥塞了。
延迟应答
延迟应答指的是对方发送报文之后,接收方等会儿再给应答。
对于初学TCP的同学对于延迟应答大概会感觉有点怪,我明明可以快速应答它,为啥还要延迟呢?因为有一种情况是,上层应用处理报文的速度极快,如果接收方收到了报文,马上应答,那么窗口大小是接收大小-该报文的大小。
但是当报文以极快的速度处理了之后,接收方再应答,此时窗口的大小就是接收缓冲区的大小了。并且我们在学习Redis的时候我,就像 Redis 推出的 mset 是为了减少多次 set 带来的网络开销,TCP 的延迟应答机制也是为了减少不必要的 ACK 报文数量。与其频繁确认,不如一次性“捎带”更多信息,提高效率。
这里也是一样的,我能一次接收多个报文,为什么要马上应答,然后接收少数的报文呢?
延迟应答也是有一定的配置的,主要是最大延迟时间和数量限制。一般设置的是延迟2个包和延迟时间设置为200ms,当然了不同的系统有不同的配置。
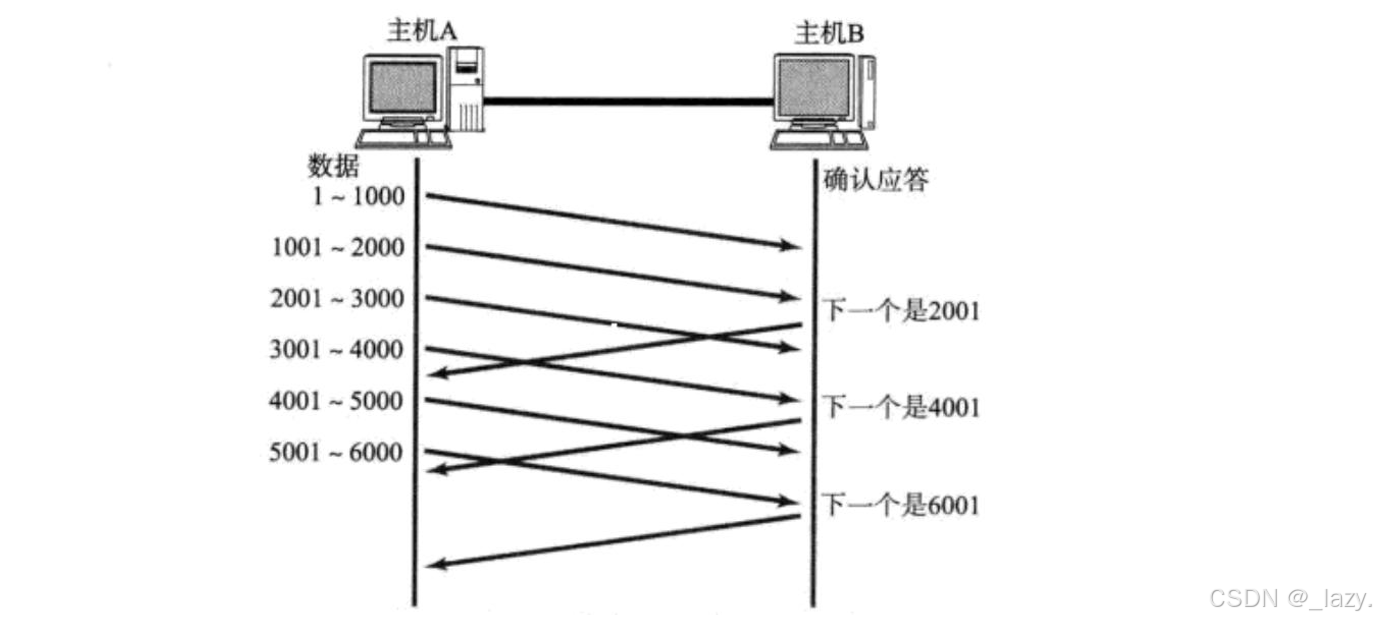
如图这样。
面向字节流
TCP的特点是面向字节流,学习到了这里,我们也能对于UDP的面向数据报和TCP的面向字节流有了一个较为清晰的分辨了。
首先,UDP的面向数据报特点主要是因为UDP发送数据的时候,是直接把整个数据打包发送的,接收方只能一次性全部接受,并且不会存在数据需要拼接的问题,一次性就接收了,那么丢包了无所谓,反正不是我UDP的事儿。
其次,TCP的面向字节流主要是因为TCP的数据是放在缓冲区之后,根据序号发送,而序号的本质是数据在缓冲区按照字节单位编排出来的,而经过TCP的层层封包之后,不同数据包按照序号可能被分配到一个报文里面,那么这个过程是没有人关心哪个数据是哪个包的,我们以一个统一的视角来看待报文,就是基本单位字节,没人关心里面的数据是谁的,我只知道这个数据的基本单位是字节。
那么在C语言阶段学习的文件操作,同样,也是面向字节流的,这里的面向字节流,和TCP的面向字节流是完全一样的,所以在文件操作的时候会用大量的时间去学习,主要就是因为面向字节流我们当时并不理解。
到了这里,我们已经了解了面向字节流,而以字节的统一视角去看待问题就会有其他问题,比如粘包问题,因为不同的数据包的数据按照字节,进到了同一个报文里面,我们如何将不同的数据拆出来呢?
记得我们之前写的HTTP服务器吗?
对于粘包问题我们简单的总结:对于定长数据包,我们按照固定长度来接收,对于变长数据包,我们可以引入一个特殊分隔符,标识数据包的结尾,我们也可以引入一个字段标识数据包的长度。
像这样:
uint32_t len;
recv(sock, &len, 4); // 读取消息长度
len = ntohl(len); // 网络字节序转本地
recv(sock, buf, len); // 按长度读取完整消息
RST PSH URG
在 TCP 报头里,大家最熟的无非就是 SYN、ACK、FIN 这些字段,用来建立连接、确认、断开连接。但除了这些“明星字段”,还有两个小透明字段:PSH(Push) 和 URG(Urgent)。大多数人学 TCP 都直接跳过它们,觉得用不到,其实这俩字段还是有点意思的。
什么是 PSH?
PSH 的意思是:“我发的这些数据你就别等了,快点扔给上层应用吧。”
我们知道,TCP 是一个带缓冲的协议,它可能接收了一点数据,但不会立刻交给上层应用,而是等攒多一点再交。但是有些时候,我们希望这个过程别拖了,比如下面这些场景:
-
你在远程终端(比如 SSH)打了一个字母,对方应该立刻看到结果。
-
聊天程序,你敲一句“在吗?”,当然希望对方立即看到。
-
实时指令,比如发送一个“退出”、“取消”命令,不能等。
这些时候就需要 PSH 上场。它的作用就是:告诉对方 TCP 栈,别攒包了,赶紧把这些数据交上去。
什么是 URG?
URG 这个就更冷门一点,叫 Urgent,意思是“这里有段数据是紧急的,你优先处理”。
这个字段配合一个 **紧急指针(urgent pointer)**使用,告诉接收方:从某个偏移量开始,有一段字节很重要,你先把它捞出来处理。
举个例子:
-
Telnet 协议早期就用 URG 实现“中断”功能,比如你敲 Ctrl+C,它就发一个带 URG 标志的包,中断对方的执行。
但说实话,URG 现在用得非常非常少,很多系统对它支持也不统一,甚至直接忽略。像我们现在熟悉的 Redis、HTTP、gRPC 等现代协议,根本用不到它。
那这俩标志会不会冲突?
其实不会。
-
PSH 是说:“别等了,我发的这段你马上处理。”
-
URG 是说:“我发的这一部分,特别重要,你先处理这段。”
它们的粒度不一样。PSH 是报文整体行为的建议;URG 是精确到字节范围的优先级提示。而且 URG 需要配合指针使用,PSH 是隐式的,很多时候系统自己会帮你处理。
对比表格:
| 对比项 | PSH(Push) | URG(Urgent) |
|---|---|---|
| 功能 | 请求立即将数据交给应用层 | 指定某段数据优先处理(紧急数据) |
| 使用目的 | 提高实时性,减少等待 | 中断、控制信号等特定用途 |
| 影响范围 | 整个报文 | 报文中的一段数据(由 urgent pointer 定位) |
| 典型场景 | SSH、Telnet 交互、实时通信 | Telnet 中断(Ctrl+C) |
| 现代系统支持 | ✅ 自动处理,常见 | ❌ 多数协议/语言已不支持 |
| 应用层是否处理 | 不需要显式处理,系统会交给应用 | 应用需读取“紧急数据”,处理逻辑更复杂 |
| 是否常用 | ✅ 常用(甚至自动设置) | ❌ 非常少用,基本淘汰 |
说白了,RST 就是 TCP 协议里的“出事了,赶紧断开”按钮。
我们平时连接断开不是都有一个优雅的四次挥手吗?你 FIN,我 ACK,我 FIN,你 ACK……然后大家礼貌说再见。但 RST 可不管那么多,它直接说:“不玩了,掀桌子!”——连接不正常,直接重置。
RST 一般啥时候出现?
1. 你给了我一个莫名其妙的连接
比如你这边给我发了个 ACK,但是我根本没这个连接(也许我重启了),我一脸懵逼,干脆发个 RST 给你,告诉你“这连接别用了”。
2. 应用层拒绝服务
有些服务端一看你这连接不合法,比如权限问题、校验失败,它就用 RST 告诉你:“你走吧,我不收。”
3. 半开连接或 zombie 连接清理
有些时候,一方掉线了,另一方还傻傻等着。这个时候,系统探测之后可能会用一个 RST 来直接清理。
看到 RST 要不要慌?
不用慌,但要注意。
-
如果你自己在开发应用,一不小心被 RST 了,那得排查:
-
是不是你用错了端口?
-
是不是连接早就断了你还在用?
-
是不是服务器主动踢你了?
-
-
如果你只是用现成软件,偶尔看到 RST,其实也正常,比如连接被负载均衡打断啥的,不用太紧张。
| 项目 | RST 标志说明 |
|---|---|
| 全称 | Reset |
| 触发时机 | 异常连接请求、资源不存在、主动拒绝等 |
| 行为 | 立即断开连接,不走四次挥手 |
| 应用层能看到吗 | 能看到 socket 报错,通常是 connection reset |
| 常见场景 | 服务端拒绝连接、半开连接清理、端口未监听 |
| 是否正常现象 | 有时是预期行为,有时是 bug,需结合上下文分析 |
以上就是TCP传输层协议的所有内容~
感谢阅读!