Dense 与 MoE 系列模型架构的全面对比与应用策略
0. 简介
人工智能领域正经历着一场架构革命,从传统的密集连接模型(Dense)向混合专家模型(Mixture of Experts, MoE)的转变。本文将全面剖析这两种模型架构的本质差异、各自优势与挑战,并提供战略性的选择框架,帮助读者在实际应用中做出明智决策。
1. 大模型演进背景与技术动因
过去十年,自然语言处理领域经历了从统计语言模型到大型语言模型(LLMs)的飞速发展。早期的统计模型为后续的神经语言模型奠定基础,预训练语言模型的出现进一步推动了该领域发展,最终催生了如今具备处理、理解和生成人类水平文本能力的大语言模型。
这一演进历程背后是计算能力的显著提升,尤其是图形处理器(GPUs)的广泛应用,以及海量互联网数据的涌现。模型规模的持续扩大,参数数量和训练数据的增加,确实带来了性能的显著提升,但也面临着严峻挑战。仅仅依靠增加模型参数数量来提升性能的策略长期来看难以持续,根本原因在于不断攀升的计算和能源消耗,以及模型性能提升幅度逐渐减小的边际效应。
在这样的背景下,Dense模型和MoE模型作为两种关键架构范式应运而生。Dense模型以其全连接特性构成了早期及部分现代大型语言模型的基础,而MoE模型则提供了一种新思路,采用稀疏激活方式,根据输入不同,动态选择激活部分专家进行处理。
2. Dense模型:架构与应用解析
2.1 核心技术:Dense连接与全激活模式
Dense模型采用全激活计算模式,所有参数在每次前向传播中都参与计算。以GPT-4为代表的Dense架构核心特点包括:
- 结构简洁:模型内部连接密集,计算流程清晰直观
- 训练稳定:全激活模式下梯度传播路径确定,优化过程相对稳定
- 部署成熟:硬件加速技术(如CUDA、TPU)对Dense矩阵计算支持完善
- 推理延迟低:单一计算路径使延迟较为稳定,适合实时交互场景
Dense模型的核心在于其密集连接的特性。在这种网络中,每一层的每个神经元都与下一层的每个神经元直接相连,形成完全互联结构。这种连接方式使信息能在网络层间充分流动。
在推理时,对于每个输入数据点,网络中的所有参数(包括连接权重和神经元偏置项)都会被激活并参与计算。一个典型的Dense层中神经元的输出计算过程是:首先对所有输入进行加权求和,然后加上偏置项,最后将结果通过非线性激活函数转换。
2.2 优势:成熟的生态、可靠性与稳定性
Dense模型受益于数十年发展形成的成熟生态系统,包括:
- 易用的训练和推理框架(TensorFlow、PyTorch)
- 充分理解的优化技术(反向传播、梯度下降)
- 强大的硬件支持(主流芯片厂商提供的加速方案)
其推理过程表现出高度确定性和稳定性。对相同输入,训练良好的Dense模型会始终产生相同输出,因为计算使用相同的完整参数集。这种可预测性在对一致性和可靠性要求极高的应用中至关重要,如安全关键系统。
全连接特性使Dense架构在拥有足够大且具代表性的训练数据集情况下,具备强大的复杂数据模式学习能力,适用于需要捕获输入特征间细微关系的任务。
2.3 商业价值与各行业理想用例
由于其可预测的推理延迟(特别是针对特定硬件优化后),Dense模型通常适合:
- 实时交互应用:虚拟现实(VR)、增强现实(AR)、物联网设备
- 移动设备部署:通过模型压缩和优化技术(剪枝、量化)
- 高频决策系统:量化交易、金融决策系统等需要极快响应的场景
- 监管严格行业:金融、医疗、法律等对模型输出可追溯性和解释性有强要求的领域
3. 混合专家模型 (MoE):通过专业化实现扩展
MoE,全称Mixture of Experts,混合专家模型,是一种基于"术业有专攻"设计思路的大模型架构。**与作为"通才"的Dense模型相对,MoE模型将任务分门别类交给多个"专家"解决。**一个通才能处理多种任务,但一群专家能更高效、更专业地解决多个问题。
3.1 核心技术要素:稀疏激活、动态路由与门控网络
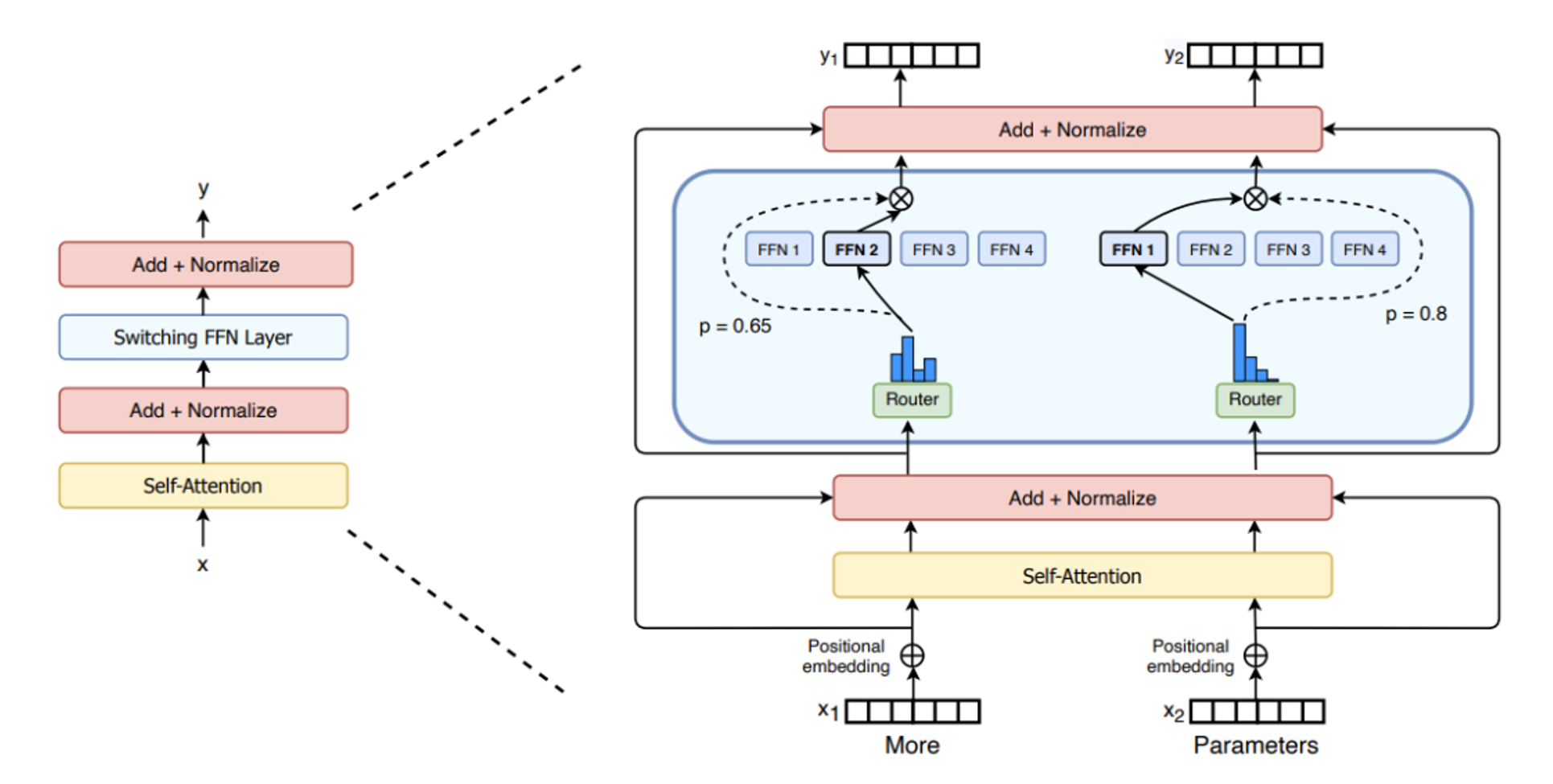
MoE模型的基本特征是稀疏激活的使用。对任何输入,只有模型总参数的一小部分(少数几个"专家"子网络)会被激活并参与计算,与Dense模型形成鲜明对比。
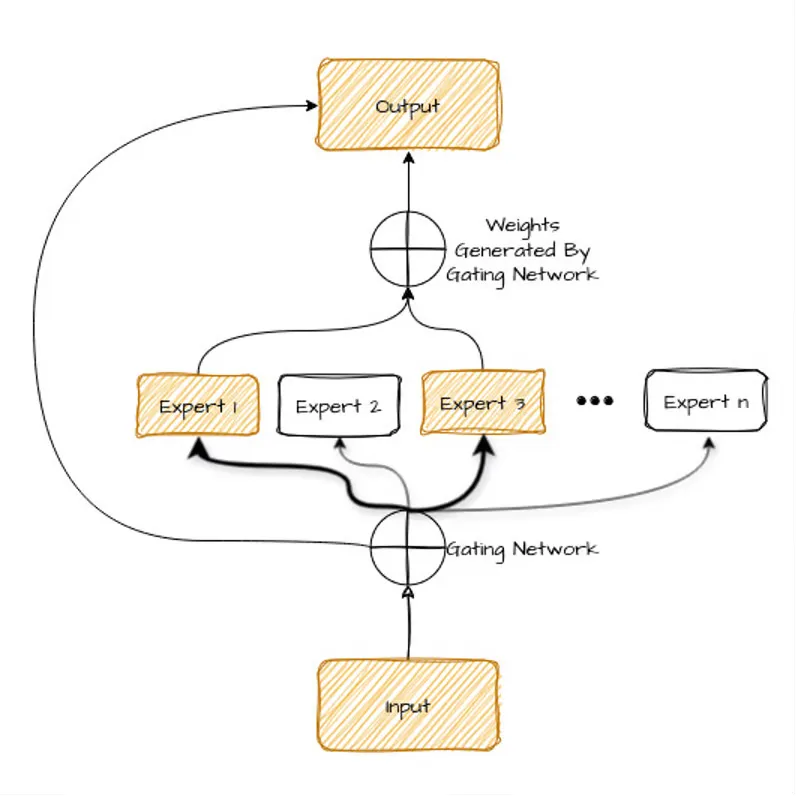
实现这种稀疏激活的关键是动态路由。MoE架构包含一个门控网络(路由器或开关),它基于输入特征,动态确定应由哪些专家处理每个输入标记。常见路由策略有:
- "top-k"路由:门控网络选择与输入最相关的k个专家
- "专家选择"路由:专家自身选择最适合处理的标记
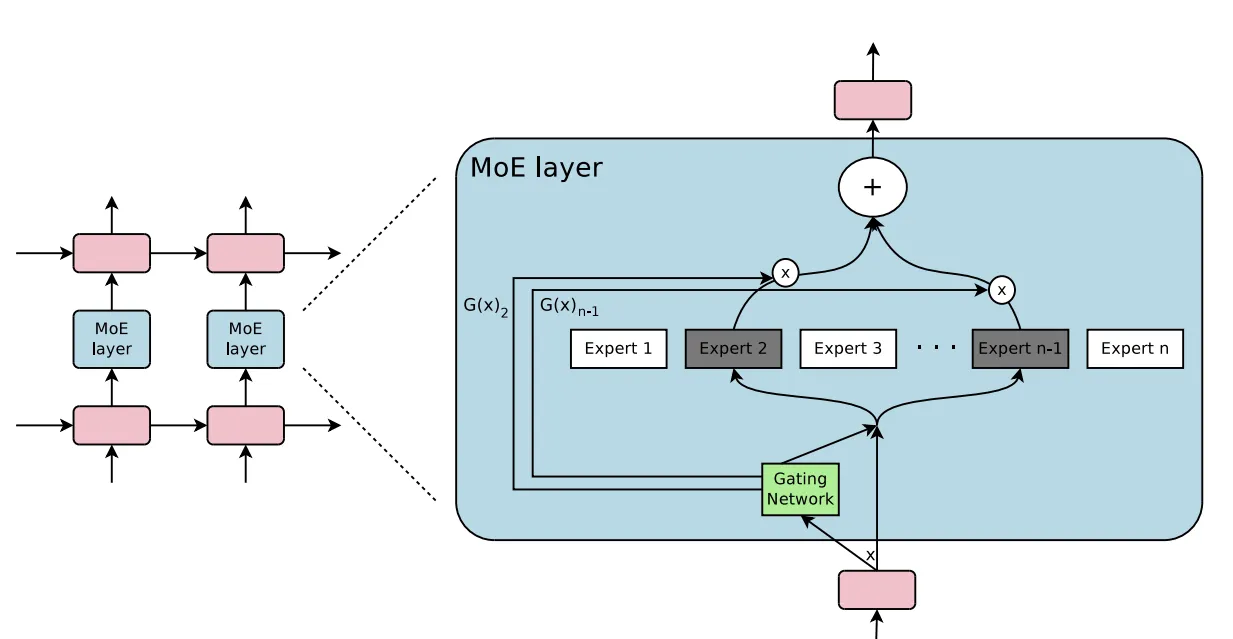
每个"专家"通常是独立的神经网络,一般是较小的全连接网络(FFN),专门处理输入空间特定区域或特定类型子任务。理念是通过多个专门的专家,整体模型能比计算成本相似的单一网络实现更高性能,更有效处理广泛输入。
3.2 MoE的设计流程
MoE架构设计通常包括以下步骤:
-
专家模型的选择与训练:
- 针对特定任务或数据训练专家模型
- 基于任务需求或数据特征选择专家
-
门控机制设计:
- 引入决定数据路由的门控网络
- 可选软门控(权重分配)或硬门控(直接选择)策略
-
专家模型的组合与输出:
- 根据门控选择组合专家输出
- 可采用简单加权或复杂融合策略
-
优化与训练策略:
- 设计特定优化方法,可能分阶段训练
- 考虑专家间协同与竞争关系
3.3 优势:参数效率、容量提升与专业化
MoE模型具备将总参数数量扩展到Dense架构难以企及水平的能力,通常可达数万亿,同时由于专家的稀疏激活,仍保持可管理的计算成本。这使它们能存储和处理明显更多信息。
MoE结构(划分为专门专家)使模型能更有效处理广泛任务和输入领域。每个专家专注于学习特定模式或特征,提高整体准确性和适应性。
在相同计算预算下,MoE模型在预训练阶段比同等规模Dense模型展现出更快达到相同质量水平的潜力,表明对某些任务,MoE学习过程可能更高效。
3.4 挑战:训练复杂性、推理开销与基础设施需求
与Dense模型相比,MoE训练过程更复杂,需要协调门控网络学习和多个专家学习,确保路由机制正确分配输入,每个专家适当专业化而不过度专注或使用不足。专家间实现均衡工作负载分配是MoE训练中持续挑战。
虽然MoE通过仅激活部分专家实现计算效率,但仍存在路由输入和选择专家相关的开销。所有专家的完整参数集通常需要加载到内存,可能增加推理过程总体内存占用。
由于涉及多个专家网络,MoE模型通常比同等活动参数量的Dense模型有更大总体尺寸,导致训练和推理需要大量内存,对资源受限环境构成部署挑战。高效训练和部署大型MoE模型通常需要专门AI基础设施,包括稀疏计算专用硬件和高带宽、低延迟网络互连。
3.5 Hybrid MoE 架构
专家混合(Mixture of Experts, MoE)选择的专家越多,质量越高,但由于高 all-to-all 通信开销,效率较低。混合专家(Hybrid-MoE)通过将残差 MoE 与密集型 Transformer 结合,重叠这种通信,从而加快训练速度。
对于批量大小为 1 的典型 MoE,仅读取活跃参数就可能产生足够的延迟。相比之下,混合专家(Hybrid-MoE)可以比等效的普通 MoE 或密集型 Transformer 更高效。此外,混合专家(Hybrid-MoE)还能够处理更大的批量大小,从而实现更快的推理速度。
4. MOE、Dense和Hybrid MoE模型对比
| 指标 | Dense架构 | MoE架构 | Hybrid MoE架构 |
|---|---|---|---|
| 基本原理 | 传统Transformer,所有参数全部激活 | 稀疏激活的专家模型集合 | Dense与MoE的战略性结合 |
| 模型结构 | 所有参数和激活单元参与每次计算 | 由多个专家组成,每次计算只激活部分专家 | 结合Dense基础模型与MoE专家层 |
| 参数规模 | 参数量固定,全部都需要计算 | 可扩展到更大规模,但每次只使用一部分 | 可达到MoE级别的总参数量,激活参数介于两者之间 |
| 计算效率 | 计算量和内存需求随参数规模线性增长 | 激活部分专家,计算量和内存需求较少 | 比普通MoE更高效,计算与通信可重叠 |
| 训练速度 | 训练过程相对稳定简单 | 训练复杂,需要负载均衡策略 | 比标准MoE训练更快,通信开销降低 |
| 性能表现 | 性能稳定,但需要大量计算资源 | 可在高效计算同时达到与大型Dense模型相似性能 | 在同等计算成本下可实现比Dense更好的性能 |
| 推理时延 | 需要加载所有参数,时延较高 | 仅加载部分激活专家,时延较低 | 比纯MoE更低的通信延迟,整体延迟优化 |
| 批处理能力 | 可处理较大批量 | 大批量处理受到通信开销限制 | 能够处理更大的批量大小,推理速度更快 |
| 内存占用 | 内存需求固定,完全由模型大小决定 | 需要存储所有专家,但计算只用部分 | 内存占用介于Dense和纯MoE之间,更优化 |
| 通信开销 | 通信开销较低 | 高all-to-all通信开销 | 通过设计使通信与计算重叠,降低开销 |
| 模型扩展性 | 扩展受计算资源限制明显 | 扩展性强,可通过增加专家数量实现 | 良好扩展性,同时保持计算效率 |
| 应用场景 | 适用于需要稳定性能且资源充足的任务 | 适用于需高效处理并发查询的任务 | 适用于需要平衡性能和计算效率的企业级应用 |
| 部署复杂性 | 部署相对简单 | 部署复杂,需要特殊硬件支持 | 部署复杂度介于两者之间 |
4.1 Dense架构
Dense Transformer是"Attention is all you need"论文中描述的原始架构。其特点是:
- 全参数激活:每个forward pass中所有参数都参与计算
- 统一处理:所有token经过相同的计算路径
- 二次复杂度:多头注意力机制带来的计算复杂性随序列长度呈二次增长
- 内存密集:需要在推理过程中加载全部参数到内存
当增加模型规模时,Dense架构的计算成本和内存需求线性增长,这限制了它的最大可行规模。
4.2 MoE架构
MoE (Mixture of Experts) Transformer引入了稀疏计算的概念:
- 专家机制:由多个子网络(专家)组成,每个专家专注于特定类型的输入
- 稀疏激活:每个token只激活前k个最相关的专家(通常k=1或2)
- 动态路由:门控网络决定将输入token分配给哪些专家
- 参数效率:无论总专家数量多少,计算成本主要由激活的专家数量决定
MoE可以扩展到非常大的参数规模而不会显著增加计算成本,因为每次计算只使用总参数的一小部分。
4.3 Hybrid MoE架构
Hybrid MoE是一种创新架构,旨在结合Dense和MoE的优势:
- 结构融合:将残差MoE层与Dense Transformer层战略性结合
- 通信优化:通过计算与通信重叠设计,减少all-to-all通信开销
- 批处理增强:能够有效处理更大的批量,提高总体吞吐量
- 平衡取舍:在模型容量、计算效率和推理速度之间取得更好平衡
对于批量大小为1的场景,Hybrid MoE比等效的普通MoE或Dense Transformer更高效,展现出在企业级应用中的显著潜力。
4.4 计算效率与性能对比
| 架构类型 | 参数效率 | 计算成本 | 规模扩展性 | 推理速度 |
|---|---|---|---|---|
| Dense | 低 (所有参数参与计算) | 高 (与参数量成正比) | 有限 (受计算资源约束) | 中等 (固定延迟) |
| MoE | 高 (只有k个专家激活) | 低 (与激活专家数成正比) | 极高 (可扩展到万亿参数) | 快 (对并发查询) |
| Hybrid MoE | 中-高 (部分Dense+部分MoE) | 中 (优于纯MoE) | 高 (保持计算效率) | 快 (通信优化) |