基于CNN与SHAP可解释性分析的神经网络回归预测模型【MATLAB】
基于CNN与SHAP可解释性分析的神经网络回归预测模型【MATLAB】
一、引言
在当今数据驱动的时代,机器学习和深度学习技术被广泛应用于各类预测任务中。其中,卷积神经网络(CNN)因其在处理具有空间结构的数据方面表现出色,常用于图像识别、时间序列预测等领域。而回归预测作为一类基础问题,也越来越多地借助CNN来提取特征并进行建模。
然而,随着模型复杂度的提升,模型“黑箱”特性日益明显,使得其决策过程难以理解。为此,引入**SHAP(SHapley Additive exPlanations)**方法对模型进行可解释性分析,能够帮助我们更好地理解输入变量对输出结果的影响机制。
本文将以MATLAB为平台,围绕一个基于CNN与SHAP结合的回归预测模型,从原理角度出发,探讨其构建逻辑与解释思路,而不涉及具体公式与代码实现。
二、CNN在回归预测中的应用
2.1 CNN的基本思想
卷积神经网络的核心在于卷积层,它通过滑动窗口的方式提取局部特征,并利用权重共享和局部连接的策略降低参数数量,从而提高模型效率。这种结构特别适合处理具有空间或时序相关性的数据,例如时间序列、图像信号等。
2.2 CNN在回归任务中的角色
在回归预测任务中,CNN的主要作用是:
- 自动提取输入数据中的关键特征:无需手动设计特征,模型能通过训练捕捉到数据中潜在的模式。
- 处理高维输入:如多通道时间序列或二维图像数据,CNN能有效压缩信息维度,保留重要结构。
- 非线性建模能力:通过堆叠多个卷积层与激活函数,CNN具备强大的非线性拟合能力,适用于复杂的回归关系。
因此,在诸如空气质量预测、金融数据分析、设备故障预测等任务中,CNN都展现出了良好的性能。
三、模型的可解释性需求
尽管CNN在预测精度上表现优异,但其“黑箱”性质限制了其在某些关键领域的应用,例如医疗诊断、金融风控等对透明性要求较高的场景。这就催生了对模型可解释性的研究需求。
3.1 SHAP的基本理念
SHAP是一种基于博弈论的特征重要性解释方法,其核心思想是:
每个特征对模型输出的贡献值可以看作是该特征在所有可能特征组合下的平均边际贡献。
SHAP值反映了每个输入变量对最终预测结果的具体影响方向(正向或负向)与大小,具有良好的理论保证与直观解释力。
3.2 SHAP在CNN模型中的应用
虽然SHAP最初主要应用于树模型(如XGBoost、LightGBM),但其思想同样可以扩展至神经网络。在CNN模型中使用SHAP:
- 可以量化每个输入变量(如时间点、像素点)对预测值的影响;
- 能够揭示哪些区域或时间段对模型判断最为关键;
- 提供可视化手段辅助用户理解模型行为,增强信任感。
四、CNN+SHAP联合建模流程概览
以下是一个典型的基于CNN与SHAP的回归预测模型的工作流程:
4.1 数据准备阶段
- 收集具有时空结构的原始数据(如多传感器采集的时间序列);
- 对数据进行标准化、归一化等预处理;
- 构造输入样本与目标输出标签,形成训练集与测试集。
4.2 CNN建模阶段
- 构建包含卷积层、池化层与全连接层的神经网络结构;
- 使用训练数据训练模型,使其学会从输入中提取有效特征并输出预测值;
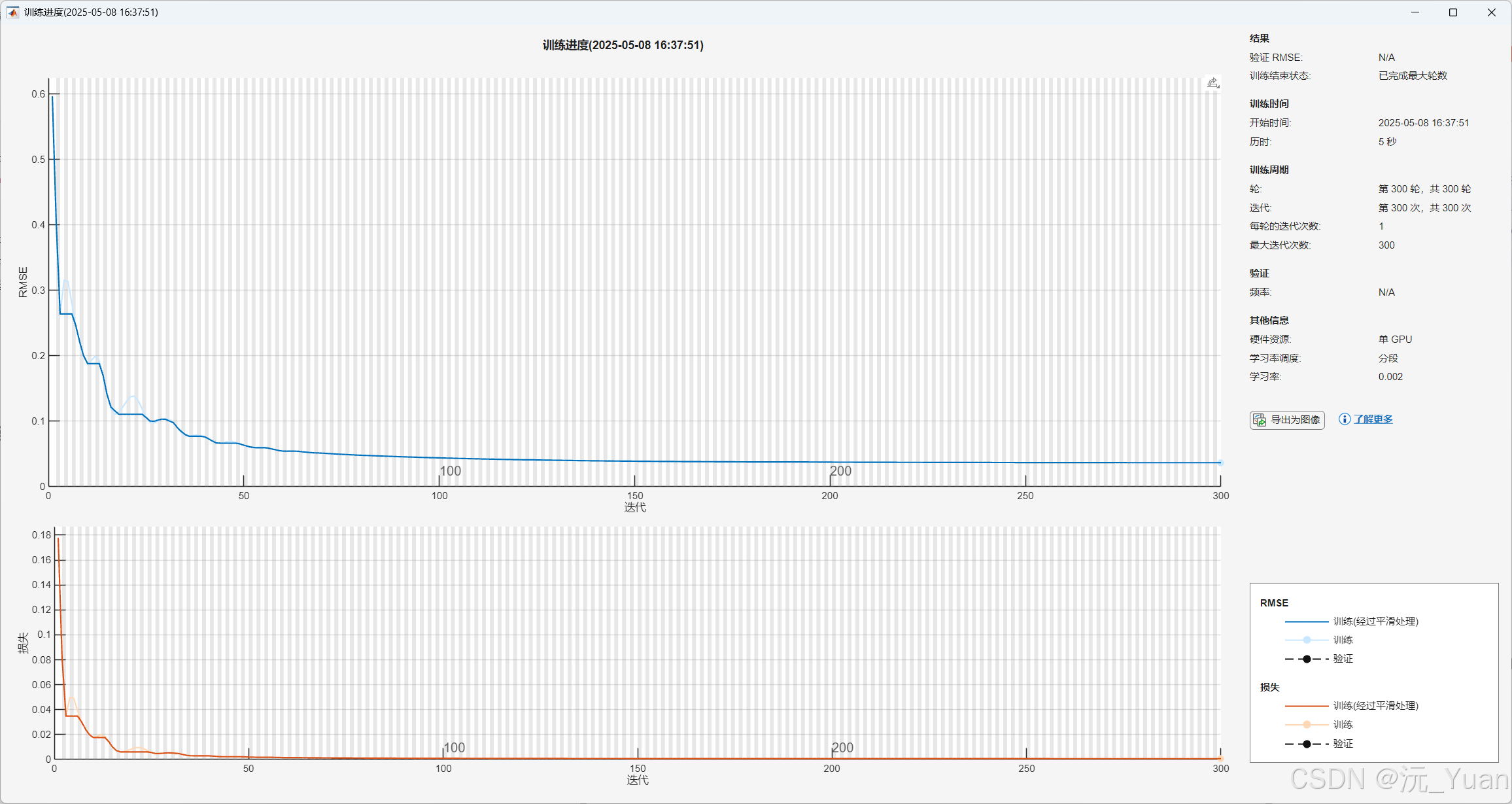
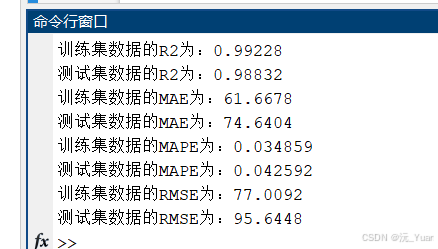
- 在验证集上评估模型性能,调整超参数优化效果。
4.3 SHAP解释阶段
- 利用训练好的CNN模型生成SHAP值;
- 分析不同输入变量对预测结果的贡献程度;
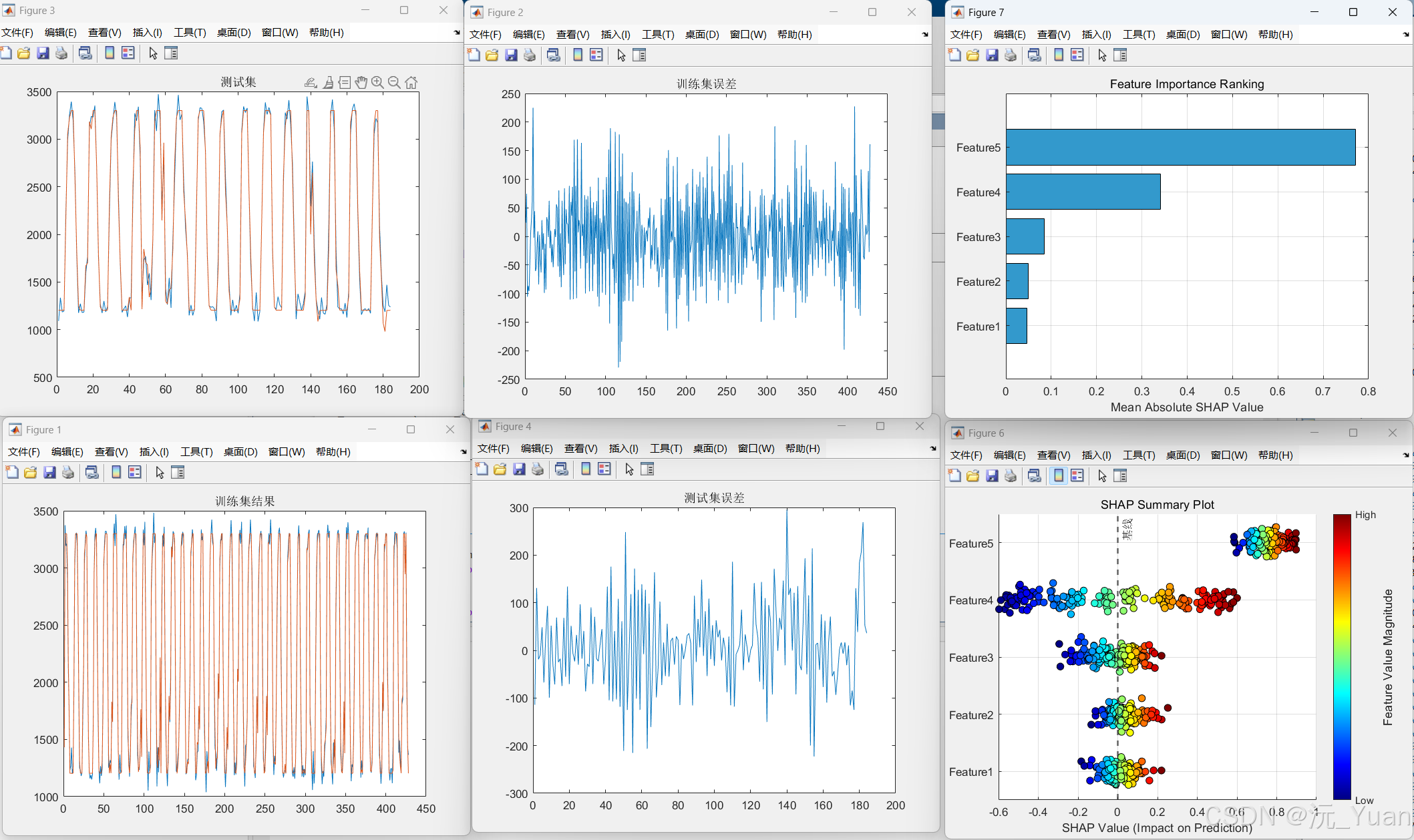
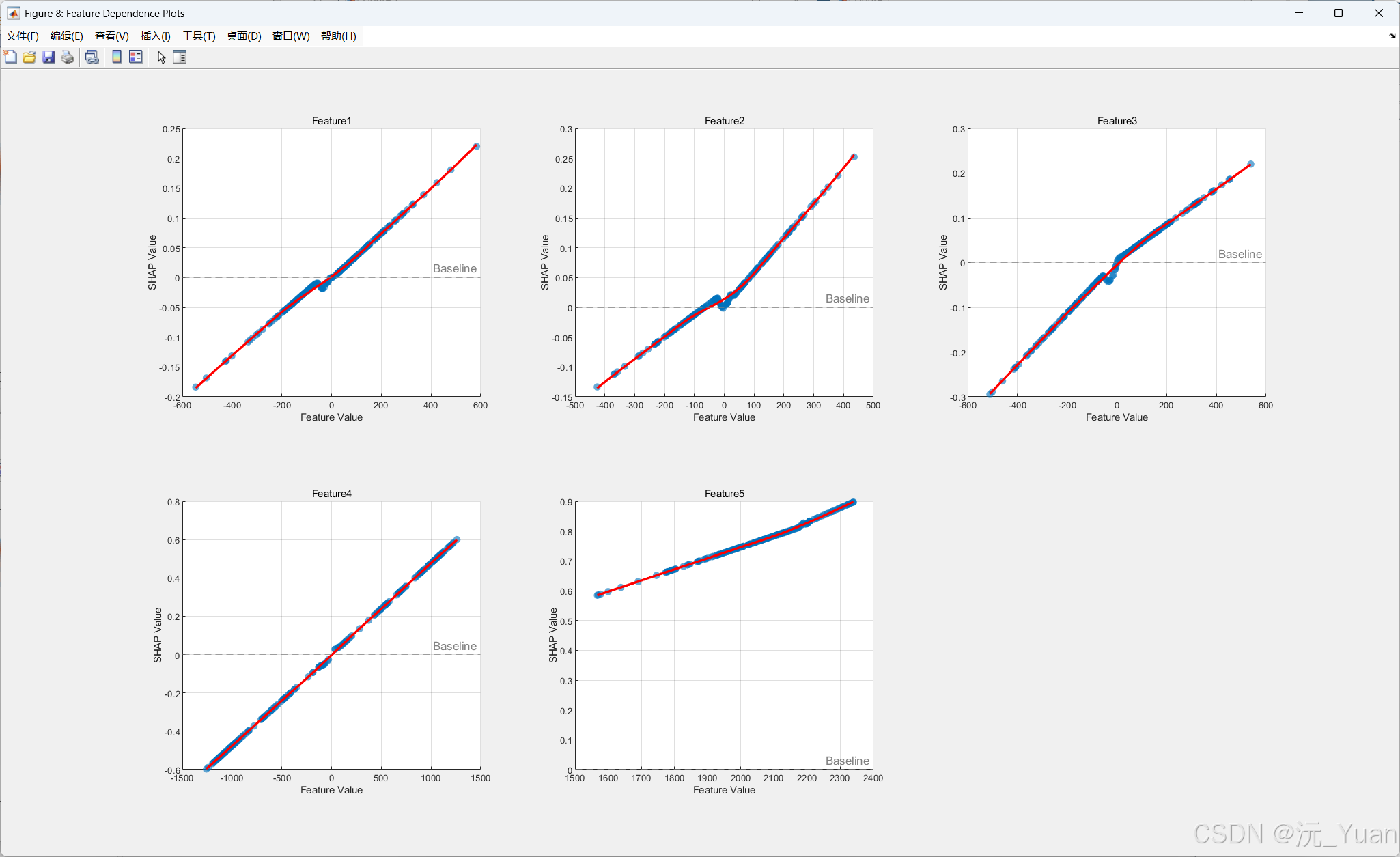
- 结合热图、条形图等形式展示特征重要性与影响方向;
- 根据解释结果优化模型结构或数据采集方式。
五、总结与展望
将CNN与SHAP相结合,构建具有可解释性的神经网络回归预测模型,是当前人工智能发展的一个重要方向。这种方法既保留了深度学习强大的表达能力,又增强了模型的透明度与可解释性,有助于推动AI技术在更多高风险、高敏感领域的落地应用。
未来,我们可以进一步探索更高效的SHAP计算方法,或将该框架拓展至其他类型的深度学习模型(如RNN、Transformer)中,构建更加全面、智能的可解释系统。
六、部分代码实现
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
rng('default');
%% 导入数据
res = xlsread('data.xlsx');
%% 数据分析
num_size = 0.7; % 训练集占数据集比例
outdim = 1; % 最后一列为输出
num_samples = size(res, 1); % 样本个数
% res = res(randperm(num_samples), :); % 打乱数据集(不希望打乱时,注释该行)
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);L = size(P_train, 1);%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test1 = mapminmax('apply', P_test, ps_input);[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test1 = mapminmax('apply', T_test, ps_output);%% 数据平铺
% 将数据平铺成1维数据只是一种处理方式
% 也可以平铺成2维数据,以及3维数据,需要修改对应模型结构
% 但是应该始终和输入层数据结构保持一致
p_train = reshape(p_train, L, 1, 1, M);
p_test = reshape(p_test1 , L, 1, 1, N);
t_train = double(t_train)';
t_test = double(t_test1 )';
七、运行结果
八、代码下载
https://mbd.pub/o/bread/aZ6cl5tw