【NLP】 31. Retrieval-Augmented Generation(RAG):KNN-LM, RAG、REALM、RETRO、FLARE
💡 给语言模型插上知识之翼:Retrieval-Augmented Generation(RAG)
一、封闭 vs 开放:为什么语言模型需要“记忆增强”?
传统语言模型如 GPT-3、PaLM 是 参数化记忆系统:
- 所有知识“写死”在训练权重中;
- 无法实时更新,信息易过时;
- 容易出现幻觉和事实错误。
二、动机场景(全部替换):
| 问题类型 | 原始回答(LLM) | 现实期待 |
|---|---|---|
| 🕰️ 过时知识 | Q: Who won the 2023 Nobel Prize in Physics? | |
| A: Albert Einstein. ❌ | ||
| Q: Who is Australia’s current education minister? | ||
| A: Dan Tehan. ❌(已卸任) | ||
| 🎯 特定事实 | Q: What type of fuel does the Airbus A350 use? | |
| A: Jet fuel, same as cars. ❌ | 需要准确调用领域知识 | |
| 🎨 冷门作品 | Q: Who painted “The Sky Beneath”? | |
| A: Unknown. ❌ | 来自近期画展的真实画家信息 |
三、解决思路:非参数记忆(Non-Parametric Memory)
模型通过外部数据库查询信息,不再“闭门造车”。
| 类型 | 描述 |
|---|---|
| 参数化 | 知识嵌入模型权重,训练时确定 |
| 非参数化 | 知识存储在外部文档,可更新 |
四、三种“检索 + 生成”结构(来源图示)
1️⃣ 并行式(Parallel)
- 检索器先找 Top-K 文档 → 与输入拼接 → “对每个文档单独生成答案”,再后融合
🔧 应用于:KNN-LM
2️⃣ 单步顺序式(Sequential)
- 检索器输出结果后,模型一次性阅读生成答案
- 无后续反馈环节
🔧 应用于:RAG、REALM、RETRO
3️⃣ 多轮交互式(Multiple Rounds)
- 模型边生成边判断何时“去查一下”
- 发出子问题 → 检索器返回 → 继续生成
🔧 应用于:FLARE
五、向量检索:Retriever 是如何找“相关内容”的?
| 步骤 | 举例(新场景) |
|---|---|
| 1️⃣ 建立文档向量库 | 将 10,000 篇自然科学论文转换为向量 |
| 2️⃣ 用户输入编码为向量 | “What is the difference between RNA and DNA?” |
| 3️⃣ 计算向量相似度 | 返回距离最小的 Top-3 文档段落 |
→ 类似 KNN,但是在嵌入空间中操作。
六、RAG:检索-生成基础架构(Facebook, 2020)
核心思想: RAG结合了预训练的生成模型(如BART)和非参数化的知识库,通过检索相关文档并将其与查询一起输入到生成模型中,从而增强生成结果的准确性和相关性。
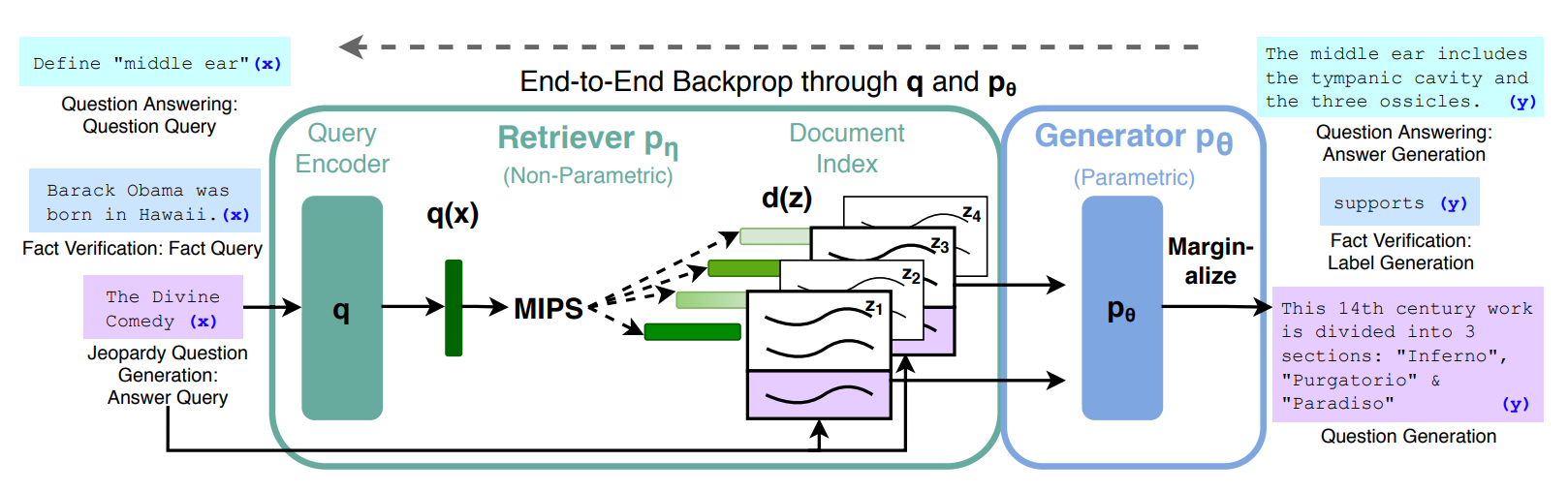
架构与机制:
- Retriever: 使用预训练的密集向量检索器,从知识库中检索与查询相关的文档。
- Generator: 将查询与每个检索到的文档拼接,输入到生成模型中,生成候选答案。
- 融合机制: 对多个候选答案进行加权融合,生成最终输出。
流程:
- 给定问题
x - 检索器查找文档 Top-K
- 模型将文档拼接入输入中生成答案
🧪 示例:
Q: When was the James Webb Space Telescope launched?检索返回:
- "...launched by NASA on December 25, 2021..."
- "...successor to Hubble..."输出:
The James Webb Telescope was launched on December 25, 2021.
创新点:
将检索和生成模块解耦,便于替换和扩展。
支持多文档融合生成,提高了生成结果的丰富性和准确性。
优缺点:
优点: 结构灵活,易于集成不同的检索器和生成模型。
缺点: 原始设计中,检索器不可训练,可能导致生成模型过度依赖无关文档。
应用场景: 知识密集型任务,如问答、摘要生成等
七、REALM:融合检索到训练阶段(Google, 2020)
REALM通过引入可训练的检索器,使语言模型能够在预训练、微调和推理阶段,从大规模语料库(如Wikipedia)中检索相关文档,并结合这些文档进行语言建模,从而以更模块化和可解释的方式捕捉知识。
架构与机制:
Retriever: 使用可训练的密集向量检索器,将查询映射到向量空间,并从语料库中检索相关文档。
Reader: 将检索到的文档与原始查询一起输入到语言模型中,进行预测。
训练方式: 通过掩码语言建模(Masked Language Modeling)任务进行训练,允许梯度通过检索步骤反向传播,从而实现端到端训练。
创新点:
首次实现了可训练的检索器与语言模型的联合训练。
在预训练阶段引入了检索机制,使模型能够访问外部知识。
优缺点:
优点: 提高了模型的可解释性和模块化,能够处理开放域问答等任务。
缺点: 检索器的训练和更新成本较高,检索速度可能慢于传统的稀疏方法。
应用场景: 开放域问答、需要外部知识支持的自然语言处理任务。
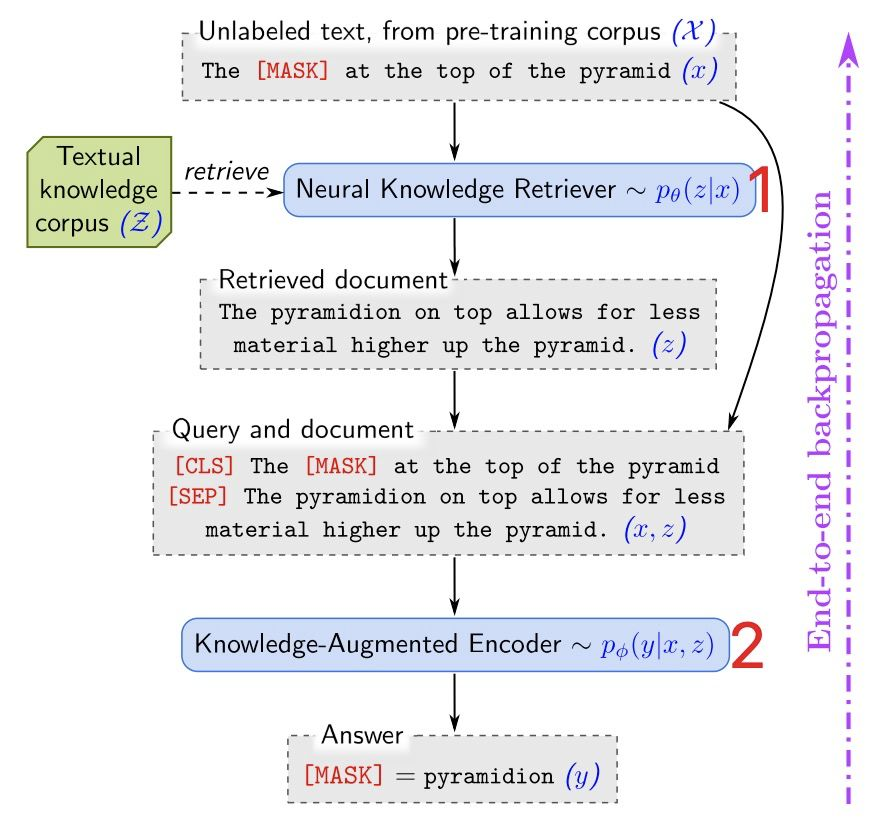
与 RAG 区别:
- 检索器内嵌在 encoder 层
- 在预训练时引入检索 → 表示更鲁棒
🧪 示例替换:
Q: What is the primary role of myelin in neurons?检索内容:“…myelin insulates axons, speeding up signal transmission…”→ 输出:Myelin increases neural signal transmission speed.
八、RETRO:训练时的 token-level 检索(DeepMind, 2022)
RETRO在Transformer模型的每一层中引入检索机制,使模型能够在生成过程中访问外部知识,从而增强其长期记忆能力。
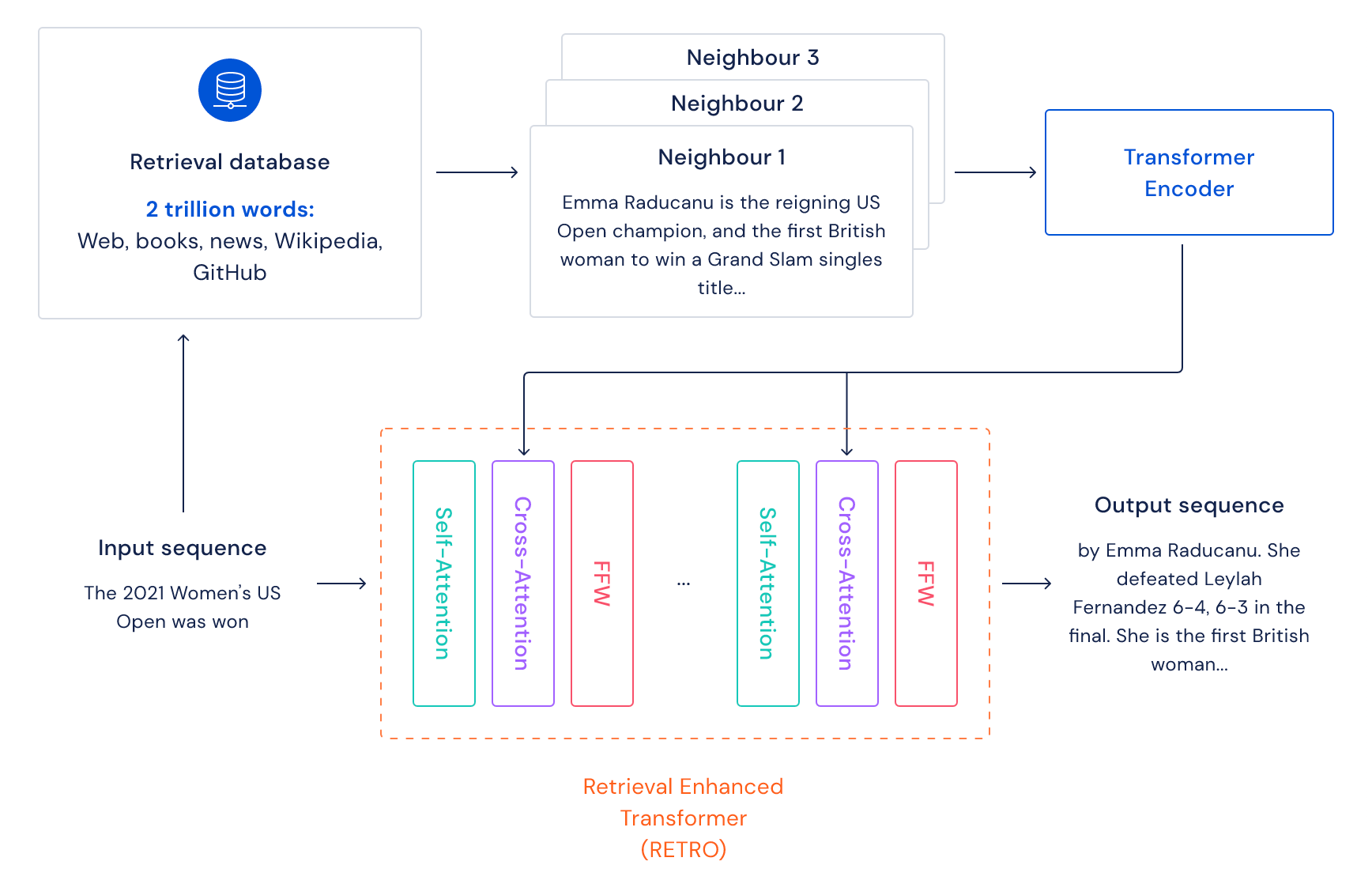
架构与机制:
检索机制: 将输入文本划分为多个块(chunk),并为每个块检索相关的文档块。
集成方式: 在Transformer的每一层中,通过交叉注意力机制,将检索到的文档块与当前块的表示进行融合。
创新点:
在模型结构中深度集成检索机制,实现了显式的长期记忆。
使用冻结的BERT模型作为检索器,降低了训练复杂度。
优缺点:
优点: 在参数数量较少的情况下,性能可与大型模型(如GPT-3)相媲美。
缺点: 训练和索引过程复杂,对计算资源要求高。
应用场景: 需要长期记忆和外部知识支持的生成任务。
模型解码每个 token 时,都可参考检索结果。
🧪 示例:
生成中间片段:
"The invention of penicillin was by..."→ 检索:“Alexander Fleming discovered penicillin in 1928...”→ 模型补全:“...Alexander Fleming in 1928.”
九、FLARE:模型自己发问,自己查(Meta, 2023)
模型生成时识别不确定部分,主动提出子问题并检索。
核心思想: FLARE在生成过程中动态判断是否需要检索外部信息,并在必要时进行检索,从而提高生成内容的准确性和相关性。
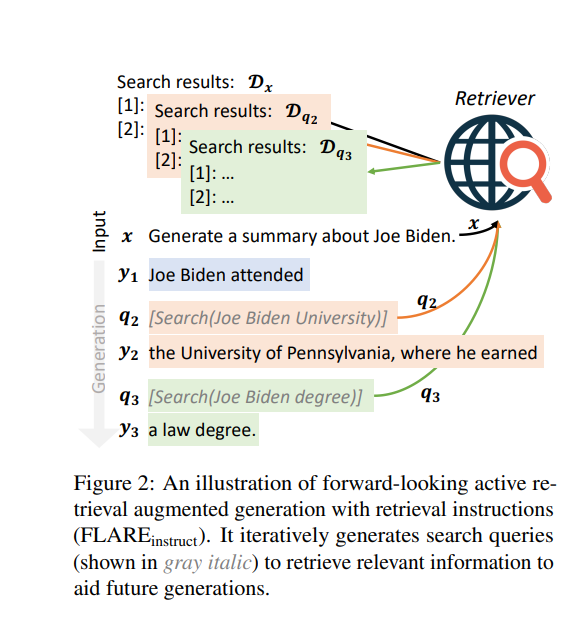
架构与机制:
预测机制: 在生成每个句子之前,预测下一个句子的内容,并判断是否包含低置信度的词。
检索机制: 如果预测的句子包含低置信度的词,则使用该句子作为查询,检索相关文档,并重新生成句子。
创新点:
引入了主动检索机制,使模型能够在生成过程中动态获取外部信息。
提高了生成内容的准确性,减少了幻觉现象。
优缺点:
优点: 更节省资源,避免一开始就检索大量冗余文档。
缺点: 控制策略的训练复杂,对流式生成模型结构有一定要求。
应用场景: 长文本生成、任务规划等需要动态获取外部信息的任务。
🧪 示例:
任务:写一个介绍马达加斯加地理环境的段落。模型中途发现空白:“The island features ... climate zones.”子问题 → 检索:“What climates exist in Madagascar?”文档:“... includes tropical rainforest, dry deciduous, and subhumid zones.”最终补全:
“The island features tropical rainforest, dry deciduous, and subhumid climate zones.”
🔚 全面对比
| 方法 | 检索方式 | 亮点 | 应用推荐 |
|---|---|---|---|
| RAG | 提前检索 | 架构清晰、效果稳定 | 文档问答、客服系统 |
| REALM | 训练中检索 | 深融合表示、可泛化 | 专业领域阅读理解 |
| RETRO | 解码时检索 | 支持长上下文、训练友好 | 大型对话、多文档生成 |
| FLARE | 交互式检索 | 主动发问、自适应推理 | 智能写作、规划代理 |