表征(Representations)、嵌入(Embeddings)及潜空间(Latent space)
文章目录
- 1. 表征 (Representations)
- 2. 嵌入 (Embeddings)
- 3. 潜空间 (Latent Space)
- 4. 关系总结
- 5. 学习思考
1. 表征 (Representations)
- 定义: 表征是指数据的一种编码或描述形式。在机器学习和深度学习中,它特指模型在处理数据时,将原始输入数据转换成的某种(通常是数值)形式,以便于模型理解和执行任务。
- 目的: 找到一种能够捕捉数据关键特征、模式或结构的表征,这种表征对于模型完成特定任务(如分类、回归、生成等)是有用的。
- 广泛性: 这是一个非常广泛的概念。
- 输入本身就是一种表征(例如,图像的像素值、文本的原始字符序列)。
- 模型每一层的输出都可以看作是该层对输入数据的一种新的、通常更抽象的表征。
- 最终的输出(如分类概率)也是一种表征。
- 好坏: 一个好的表征应该能够简化后续任务。例如,对于图像分类,一个好的表征可能使得不同类别的图像在表征空间中是线性可分的或易于区分的。神经网络通过逐层学习,试图将原始输入转换为越来越好的、对任务更有用的表征。
- 例子:
- 图像的原始像素值。
- 卷积神经网络(CNN)中某一卷积层的激活图(activation map),它可能表征了图像的边缘、纹理等低级特征。
- 循环神经网络(RNN)在处理完一个句子后的隐藏状态(hidden state),它可能表征了该句子的语义概要。
- 词袋模型(Bag-of-Words)向量是文本的一种稀疏表征。
2. 嵌入 (Embeddings)
- 定义: 嵌入是一种特定类型的表征。它特指将离散的、高维稀疏的类别型变量(如单词、用户ID、商品ID、图节点)映射到一个连续的、低维稠密的向量空间中的过程或结果。这个低维稠密向量就是该类别变量的嵌入向量。
- 目的:
- 降维: 将通常非常高维(如 one-hot 编码后的词汇表大小)的稀疏表示转换为低维表示,提高计算效率和存储效率。
- 捕捉语义/关系: 嵌入向量是学习得到的,目标是让相似或相关的离散项在嵌入空间中具有相近的向量表示(例如,通过向量的余弦相似度或欧氏距离来衡量)。这使得模型能够利用项与项之间的潜在关系。
- 适配神经网络: 神经网络更擅长处理连续、稠密的数值输入。
- 关键特征:
- 稠密 (Dense): 向量中的大部分元素都是非零的,与 one-hot 编码(只有一个 1,其余都是 0)形成对比。
- 低维 (Lower-dimensional): 嵌入向量的维度通常远小于原始离散空间的基数(例如,词汇表大小可能有几万,但词嵌入维度通常是几十到几百)。
- 学习得到 (Learned): 嵌入向量的值是在模型训练过程中,根据任务目标(如预测下一个词、进行分类、推荐等)自动学习和调整的。
- 例子:
- 词嵌入 (Word Embeddings): 如
Word2Vec,GloVe,FastText,或在神经网络(如Transformer,RNN)的Embedding层学习到的向量,将每个单词映射到一个向量,使得语义相近的词(如 “king” 和 “queen”)在向量空间中距离较近。 - 用户/物品嵌入 (User/Item Embeddings): 在推荐系统中,将每个用户和物品映射到一个向量,用于预测用户对物品的偏好。
- 节点嵌入 (Node Embeddings): 在图神经网络中,将图的每个节点映射到一个向量,捕捉节点的结构和属性信息。
- 词嵌入 (Word Embeddings): 如
3. 潜空间 (Latent Space)
- 定义: 潜空间是一个抽象的、多维的向量空间,数据的表征(尤其是嵌入向量或经过压缩的表征)就“存在”于这个空间中。它通常是低维的,并且其维度(坐标轴)可能不具有直接、明确的物理或现实意义,但这些维度共同捕捉了数据的潜在结构、变异性或核心特征。
- 目的:
- 理解数据结构: 通过将数据点映射到潜空间,可以可视化数据(如果维度降到2或3维),观察聚类、流形结构、相似性关系等。
- 特征提取/降维: 潜空间通常是通过降维技术(如
PCA、t-SNE)或模型(如自动编码器Autoencoder的瓶颈层、嵌入层)学习得到的,它代表了数据的压缩或核心信息。 - 数据生成: 在生成模型(如
VAE,GAN)中,可以从潜空间中采样一个点(向量),然后通过模型的解码器将其映射回原始数据空间,从而生成新的、与训练数据类似的数据。潜空间的结构(如平滑性)对生成质量至关重要。
- 关键特征:
- 抽象: 空间的维度不一定对应于可直接解释的特征。
- 低维 (Often): 相对于原始数据空间,潜空间通常维度较低。
- 结构化 (Ideally): 一个好的潜空间应该是有意义的结构,例如相似的数据点聚集在一起,或者沿着某个方向移动会对应数据某种属性的平滑变化。
- 例子:
- 词嵌入向量所在的 N 维空间就是一个潜空间。
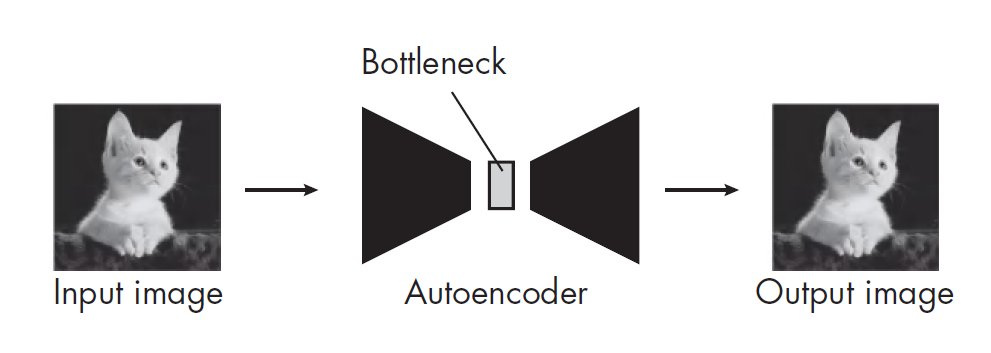
- 自动编码器(
Autoencoder)的瓶颈层(bottleneck layer)输出的向量所在的那个低维空间。 - 变分自编码器(
VAE)中,编码器输出的均值和方差定义的那个概率分布所在的参数空间,以及从中采样得到的z向量所在的那个空间。 PCA降维后,主成分定义的那个低维空间。
自动编码器可以对输入图像进行重建,从而学习这些特征:
4. 关系总结
- 表征 是最广泛的概念,指数据的任何编码形式。
- 嵌入 是一种特定类型的表征,用于将离散高维数据映射为连续低维稠密向量,并捕捉其潜在关系。所有嵌入都是表征,但并非所有表征都是嵌入。
- 潜空间 是这些表征(尤其是嵌入或压缩表征)所处的抽象向量空间。表征向量是潜空间中的点。
5. 学习思考
有哪些不属于嵌入表征的输入形式?
以下是一些常见的不属于典型“嵌入表征”定义的输入形式(尽管它们也是一种表征):
- 原始像素值 (Raw Pixel Values): 图像的像素值是连续的(或离散的整数),并且是高维、结构化的,但它们不是通过学习将离散项映射到低维稠密空间得到的。它们是数据的原始、直接表征。
- 直方图: 直方图提供了数字图像中色调分布的图形表示,捕获了像素的强度分布。
- One-Hot 编码向量 (One-Hot Encoded Vectors): 这是将离散类别变量转换为向量的一种方式,但它是高维、极其稀疏的,并且是固定映射而非学习得到的。它通常是输入给嵌入层以获取嵌入向量的原始形式。
- 词袋模型 (Bag-of-Words, BoW) 向量: 计算文档中每个词出现的次数(或频率)。这也是一种表征,但通常是高维、稀疏的,并且是基于简单计数规则生成的,而非通过神经网络端到端学习得到的稠密语义向量。
- TF-IDF 向量: 词频-逆文档频率向量,是对 BoW 的改进,考虑了词的重要性。它仍然是高维、稀疏的,并且是基于统计规则计算的。
- 原始数值特征 (Raw Numerical Features): 例如,一个人的年龄、身高、体重,或者传感器的温度、湿度读数。这些已经是连续(或离散)的数值,可以直接(或经过标准化后)输入模型。它们不是从离散类别映射来的低维稠密向量。
- 时间序列数据 (Raw Time Series Data): 例如,股票价格随时间的变化、音频信号的波形。这些是连续的序列数据,是原始输入,而非学习到的低维稠密嵌入。
关键区别在于嵌入通常是从离散/类别型数据出发,通过学习得到的一个低维、稠密、连续的向量表示,目的是捕捉项与项之间的潜在关系或语义。上述例子要么是原始数据,要么是稀疏表示,要么是基于规则生成的,或者本身就是连续数值,不符合嵌入的核心定义。