大模型Rag - embedding
一.什么是Embedding
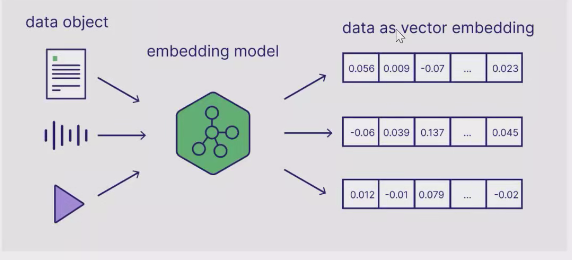
Embedding模型是一种将各种形式的数据对象(如文本、音频、视频等)转换为固定长度的连续数值向量的技术。这种转换过程可以形象地理解为将复杂数据"嵌入"到一个高维的数学空间中。
关键特性:
- 固定维度:无论输入数据的大小如何,输出向量长度固定(通常几百到几千维)
- 语义保留:在向量空间中,语义相似的对象距离更近
- 连续表示:使用连续的数值而非离散符号表示数据
Embedding的工作原理
- 输入处理:原始数据(如文本)经过预处理(分词、归一化等)
- 特征提取:模型捕捉数据的深层语义特征
- 向量映射:将提取的特征压缩为固定维度的密集向量
以文本为例:"机器学习"和"深度学习"这两个短语的embedding向量在空间中会比它们与"篮球比赛"的向量更接近。
二.Embedding在RAG中的关键作用
RAG(Retrieval-Augmented Generation)系统依赖embedding实现高效的知识检索:
检索阶段:
- 将用户问题转换为问题embedding
- 计算它与知识库中所有文档embedding的相似度
- 返回最相似的几个文档作为上下文
质量影响:
- 优秀的embedding模型能准确反映语义关系
- 低质量的embedding会导致检索无关内容,进而影响最终生成效果
三.如何挑选 Embedding
挑选模型的核心维度
1.明确你的任务类型
信息检索:建议选择在 retrieval 任务中表现优秀的模型。
文本分类/聚类:关注模型在 classification 或 clustering 的表现。
语义搜索:优先考虑兼顾 recall 和 precision 的模型。
任务目标决定了你对 embedding 质量和结构的要求。
2. 语言支持情况
处理中文数据时,建议选择多语言模型,尤其是对中英文都优化过的模型(如 m3e、bge-m3)。
单语任务也可以优先考虑单语优化模型,效果更纯粹。
3. 模型测试得分(Benchmarks)
可参考 MTEB 等公开评测。
重点关注表现靠前的模型,但不要迷信排名 —— 模型机构的可信度也很关键。
4. 模型大小(参数量)
大模型 ≠ 更强效果。尤其是经过微调的小模型,实际表现差距并不明显。
优先选择在计算资源允许范围内表现较优的小模型,部署更轻松,响应更快速。
5. 嵌入维度(embedding size)
常见维度:512 或 1024。
高维嵌入 捕捉更丰富语义,但计算和存储成本高。
低维嵌入 效率高,适合大规模数据场景。
建议权衡性能与成本,默认优先考虑 512。
6. 输入 token 限制
不同模型对最大输入长度(token)支持不同,常见范围为 512~8192。
如果文本较长,选择 token 支持大的模型,避免信息截断影响表达。
筛选模型的方法论
1. 初步筛选
基于上述六大维度,结合模型发布机构的背景和过往口碑,选出一批备选模型,作为 baseline。
2. 数据集测试与模型调整
构建符合自己业务的数据集,测试 baseline 模型在实际任务上的表现。
若效果不理想,可逐步迭代模型,微调参数或更换模型架构。
3. 多角度评估模型可靠性
虽然 MTEB 提供了统一 benchmark,但因测试集公开,部分模型可能过拟合评测任务。
建议结合业务数据评测、社区反馈和论文发布质量等综合判断。
四.实战
待续…
五.术语
1.retrieval(检索)
利用 Embedding 模型将文本/数据转换为向量后,通过向量相似度搜索(如余弦相似度)从大规模数据中找出与查询最相关的结果。
典型应用:
- 搜索引擎(语义搜索)
- 问答系统(匹配问题与答案)
- 推荐系统(用户兴趣与内容匹配)
2.classification(分类)
利用Embedding作为特征输入,训练分类器(如SVM、神经网络)对文本/数据进行类别预测。
典型应用:
- 情感分析(正面/负面评论)
- 垃圾邮件检测
- 意图识别(客服对话分类)
3.clustering(聚类)
在无监督学习中,将语义相似的Embedding向量自动分组(如K-Means、DBSCAN)。
典型应用:
- 用户画像分组
- 新闻话题发现
- 异常检测
4.recall(召回率)& precision(精确率)
在Embedding任务中,这两个指标通常用于评估检索/分类效果:

Recall(召回率)
**定义:**系统找到的相关结果占所有真实相关结果的比例

定义:系统返回的结果中真正相关的比例
