Token-Budget-Aware LLM Reasoning


作者发现,当给大模型输入的提示词内,加入思考不超过xxx个token,可以很好的控制模型思考的长度,并且给出正确的答案,但是同时也存在问题。如上图所示:当不断压缩这个上限的时候,模型开始不遵守这个上限,因此我们需要找到一个:模型可以遵守并且可以得到正确答案的思考上限。

最简单的方法就是二分法,将原始CoT作为右边界,不断的二分,取中点,如果回答正确,并且思维链长度被压缩,就继续下一个二分,直到:模型无法正确回答,或者思维链长度已经不被压缩。
但是问题就在于,这个方法太耗时间,每次都要二分,二分到一个最小上限,作者提出了两种方法:1. TALE- EP和2. TALE- PT
- 使用大模型预估问题的思考token上限,然后插入prompt
- 用上述二分法构建出来的数据集,微调模型,SFT或者DPO。
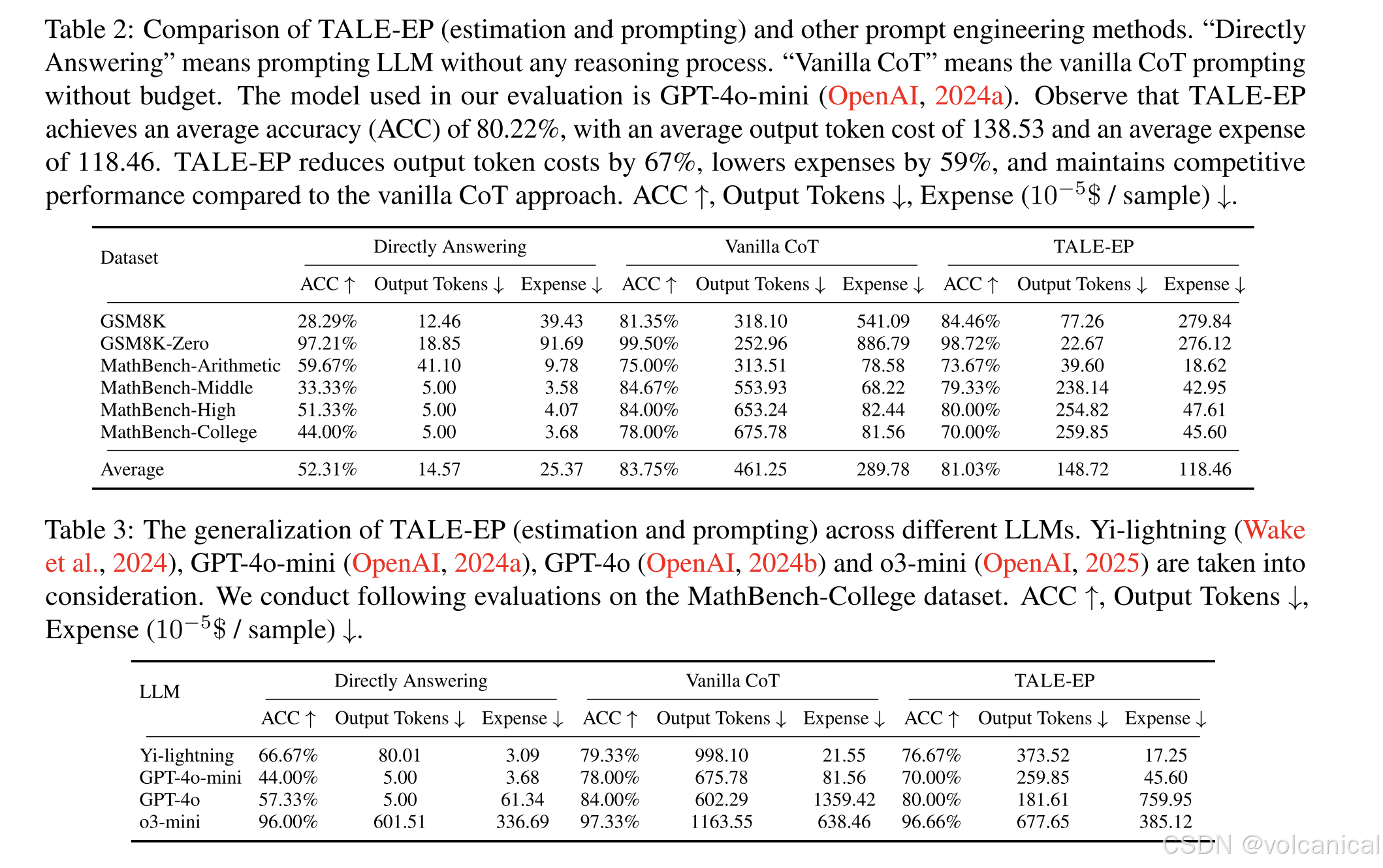
结果: