多模态知识图谱与大模型 图解合集(干中学ing)
CLIP: 2021
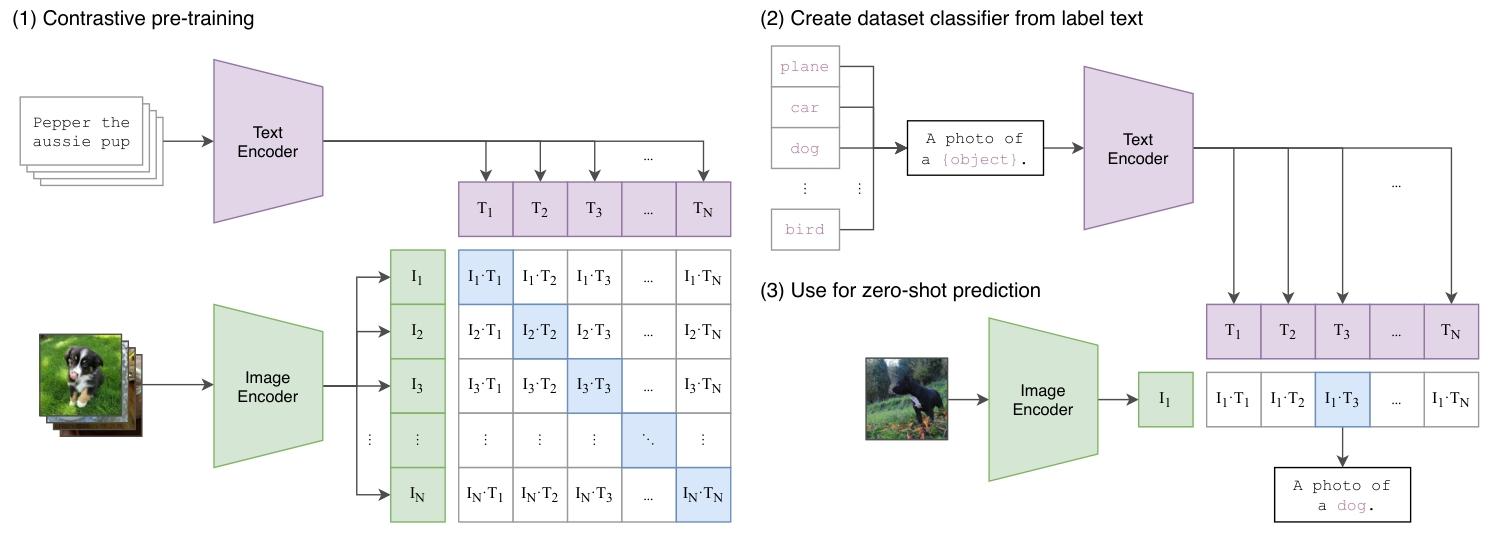
(1)Contrastive pre - training(对比预训练)
- 输入:左侧上方输入文本数据(如“Pepper the aussie pup” ),左侧下方输入图像数据(如一张小狗的图片 )。
- 编码器:文本数据进入“Text Encoder”(文本编码器),图像数据进入“Image Encoder”(图像编码器) 。文本编码器和图像编码器可以采用不同架构,比如文本编码器可以是基于Transformer的结构,图像编码器可以是ResNet或Vision Transformer等。
- 特征提取与对比学习:
- 文本编码器将文本编码为特征向量,得到T1,T2,T3,…,TNT1,T2,T3,…,TN ,这里NN表示文本数量。
- 图像编码器将图像编码为特征向量,得到I1,I2,I3,…,INI1,I2,I3,…,IN ,这里NN表示图像数量。
- 随后计算图像特征向量和文本特征向量之间的点积(如图中的I1⋅T1I1⋅T1 ,I1⋅T2I1⋅T2 等 )。在对比学习中,目标是让正确配对(即原本对应的图像和文本 )的特征向量点积尽可能大,错误配对的点积尽可能小。通过这种方式,模型学习到图像和文本之间的关联表示。