《Learning Langchain》阅读笔记11-RAG(7)索引优化:RAPTOR方法和ColBERT方法
在上一节中我们为了提升索引阶段的准确性和性能,选取了MultiVectorRetriever这种优化策略。
让我们来回顾一下MultiVectorRetriever(如图2-5):

例如,对于包含表格的文档,我们可以首先生成一个“表格内容的摘要 summary”(简短概括),把这个摘要生成向量并存入到vector store。但是我们要确保每个摘要中包含一个指向完整原始表格的 ID 引用。summary里藏着:“我对应的是 Table-123”,到时候真要用的时候,可以根据 ID 找回原表格!接下来,我们将这些原始表格单独存储在一个独立的docstore中。最后,当用户查询检索到某个表格摘要时,我们会将完整的原始表格作为上下文传递给 LLM,用于最终的答案生成(answer synthesis)。这种方法使我们能够为模型提供回答问题所需的完整信息上下文。
RAPTOR:用于树状检索的递归抽象处理
那么这节我们来讲讲RAPTOR:用于树状检索的递归抽象处理。
RAPTOR最早在ICLR 2024提出,下面是
-
文章Arxiv链接
-
官方的github仓库
RAG 系统既要能应对那种只涉及单个文档中某个具体事实的“低层次”问题,也要能处理那种需要从多份文档中提炼出核心观点的“高层次”问题。而仅仅依靠对文档切片做典型的 k 近邻(k-NN)检索,很难同时兼顾这两类问题。
递归抽象处理用于树状检索(Recursive abstractive processing for tree-organized retrieval,简称 RAPTOR)是一种有效策略,其流程包括:
- 创建文档摘要,捕捉文档中的高层次概念;
- 对这些摘要进行嵌入和聚类,将语义相近的摘要归为一类;
- 对每个聚类再次生成摘要,以递归方式不断提炼出更高层次的概念,最终构建出一个由多级摘要组成的树状结构。
然后,将这些层级摘要与最初的文档一起建立索引,从而能够覆盖从“低层次”到“高层次”的各类用户查询,见图 2-6 。
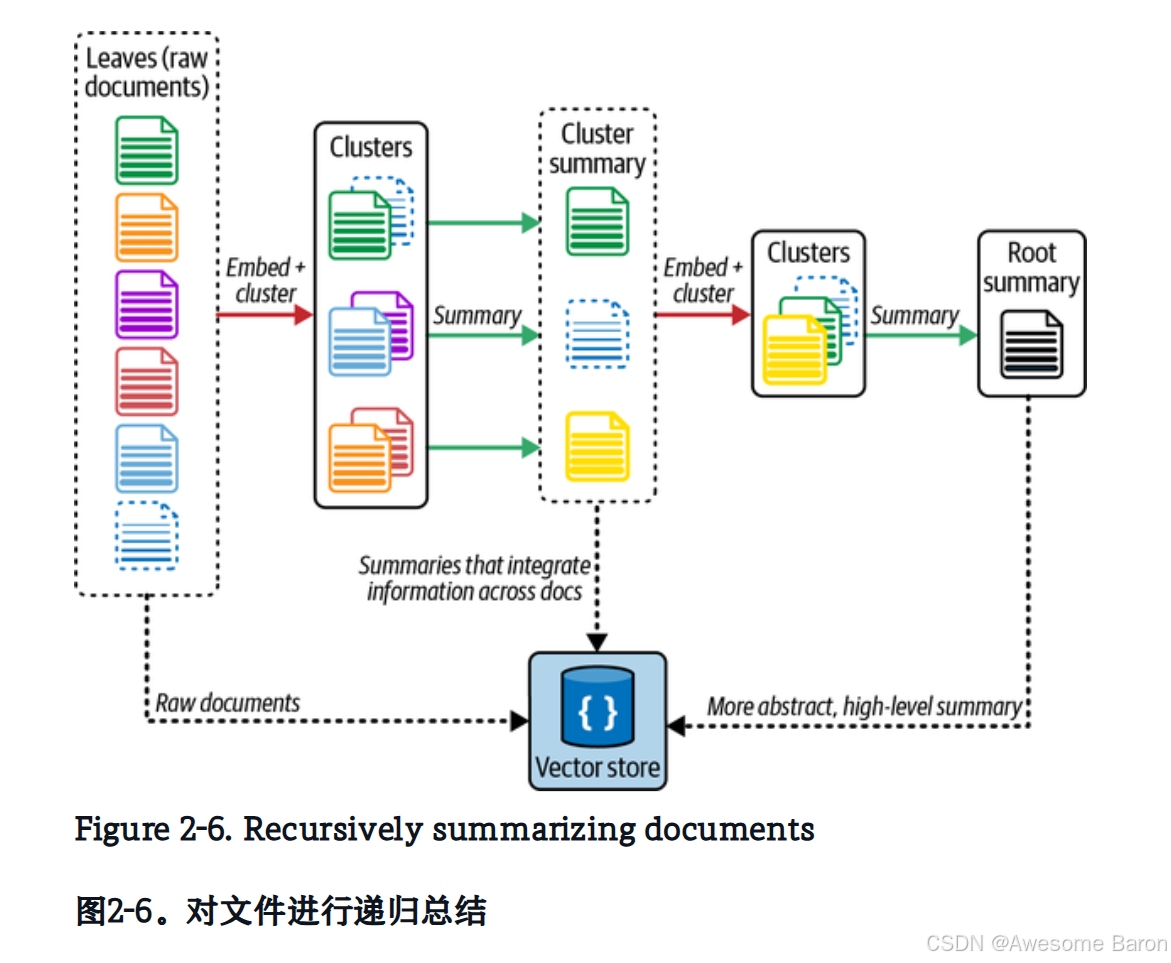
比MultiVectorRetriever方法多了聚类的步骤,相当于不断提取更高层次的summary,对文件进行了递归总结。
《Learning Langchain》中并没有给出这部分代码,但我们可以尝试自己写一份!
LangChain 暂时还没有一个开箱即用的 RAPTOR 类,但我们完全可以用它的基础组件手写一套递归抽象(RAPTOR)流程。下面给出一个最简示例,演示如何对一批文档:
-
叶子层
文档直接入向量库
-
中间层
文档嵌入+聚类 →对每个聚类生成更高层次摘要 → 入向量库
-
根层
将中间层所有聚类摘要嵌入+聚类 → 再次摘要,得到根摘要 → 入向量库
import os
import requestsos.environ['HTTP_PROXY'] = 'http://127.0.0.1:7890'
os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:7890'r = requests.get("https://www.google.com")
print(r.status_code) # 能返回 200 就说明代理成功了
200
import getpass
import osif "GOOGLE_API_KEY" not in os.environ:os.environ["GOOGLE_API_KEY"] = getpass.getpass("Enter your Google AI API key: ")
Enter your Google AI API key: ········
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_huggingface import HuggingFaceEmbeddings
from langchain.vectorstores.pgvector import PGVector
from langchain_core.documents import Document
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_google_genai import ChatGoogleGenerativeAI
from sklearn.cluster import KMeans
from tqdm import tqdm
import uuid# ————————————
# 1. 通用配置
# ————————————# 文档加载与切分
loader = TextLoader("./test.txt", encoding="utf-8")
raw_docs = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = splitter.split_documents(raw_docs) # List[Document]# LLM 摘要链
prompt = ChatPromptTemplate.from_template("Summarize the following text:\n\n{doc}")
llm = ChatGoogleGenerativeAI(model="gemini-2.0-flash-001", temperature=0)
summarize_chain = {"doc": lambda x: x.page_content} | prompt | llm | StrOutputParser()# Embeddings 模型(多语 + 归一化)
embeddings_model = HuggingFaceEmbeddings(model_name="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",model_kwargs={"device": "cuda"},encode_kwargs={"normalize_embeddings": True},
)# PostgreSQL 连接串
DB_CONN = "postgresql+psycopg2://langchain:langchain@localhost:6024/langchain"# ————————————
# 2. 叶子层:切片直接入向量库(带进度条)
# ————————————leaf_collection = "raptor_leafs"
leaf_vs = PGVector(connection_string=DB_CONN,collection_name=leaf_collection,embedding_function=embeddings_model,use_jsonb=True,distance_strategy="cosine",
)print(f"索引叶子层:向量库 `{leaf_collection}` 共 {len(chunks)} 条切片…")
leaf_batch_size = 64
for i in tqdm(range(0, len(chunks), leaf_batch_size), desc="Indexing leaf chunks"):batch = chunks[i : i + leaf_batch_size]leaf_vs.add_documents(batch)# ————————————
# 3. 中间层:对叶子切片聚类→摘要→入向量库(带进度条)
# ————————————# 3.1 嵌入所有叶子切片
texts = [doc.page_content for doc in chunks]
embs = embeddings_model.embed_documents(texts)# 3.2 KMeans 聚类
n_mid_clusters = 5
mid_labels = KMeans(n_clusters=n_mid_clusters, random_state=42).fit_predict(embs)# 3.3 为每个簇生成摘要
clustered = {}
for lbl, doc in zip(mid_labels, chunks):clustered.setdefault(int(lbl), []).append(doc)mid_summaries = []
for lbl, docs_in_cluster in tqdm(clustered.items(), desc="Generating mid-layer summaries"):merged_text = "\n\n".join(d.page_content for d in docs_in_cluster)tmp_doc = Document(page_content=merged_text, metadata={"cluster": int(lbl)})summ_text = summarize_chain.invoke(tmp_doc)mid_summaries.append(Document(page_content=summ_text,metadata={"cluster": int(lbl), "id": str(uuid.uuid4())},))# 3.4 入向量库
mid_collection = "raptor_middle"
mid_vs = PGVector(connection_string=DB_CONN,collection_name=mid_collection,embedding_function=embeddings_model,use_jsonb=True,distance_strategy="cosine",
)
print(f"索引中间层:向量库 `{mid_collection}` 共 {len(mid_summaries)} 条摘要…")
mid_batch_size = 16
for i in tqdm(range(0, len(mid_summaries), mid_batch_size), desc="Indexing mid summaries"):batch = mid_summaries[i : i + mid_batch_size]mid_vs.add_documents(batch)# ————————————
# 4. 根层:合并中间层摘要→聚类→生成根层聚类摘要→入向量库(带进度条)
# ————————————# 4.1 嵌入中间层摘要
mid_texts = [doc.page_content for doc in mid_summaries]
mid_embs = embeddings_model.embed_documents(mid_texts)# 4.2 聚类
n_root_clusters = 2
root_labels = KMeans(n_clusters=n_root_clusters, random_state=42).fit_predict(mid_embs)# 4.3 生成根层聚类摘要
root_clustered = {}
for lbl, doc in zip(root_labels, mid_summaries):root_clustered.setdefault(int(lbl), []).append(doc)root_summaries = []
for lbl, docs_in_root in tqdm(root_clustered.items(), desc="Generating root-layer summaries"):merged = "\n\n".join(d.page_content for d in docs_in_root)tmp = Document(page_content=merged, metadata={"root_cluster": int(lbl)})summ = summarize_chain.invoke(tmp)root_summaries.append(Document(page_content=summ,metadata={"root_cluster": int(lbl), "id": str(uuid.uuid4())},))# 4.4 入向量库
root_collection = "raptor_root_level"
root_vs = PGVector(connection_string=DB_CONN,collection_name=root_collection,embedding_function=embeddings_model,use_jsonb=True,distance_strategy="cosine",
)
print(f"索引根层:向量库 `{root_collection}` 共 {len(root_summaries)} 条聚类摘要…")
root_batch_size = 8
for i in tqdm(range(0, len(root_summaries), root_batch_size), desc="Indexing root summaries"):batch = root_summaries[i : i + root_batch_size]root_vs.add_documents(batch)# ————————————
# 5. 查询示例
# ————————————query = "这个文档集合的整体主题是什么?"
results = root_vs.similarity_search(query, k=2)
print("\n=== 根层检索示例 ===")
for i, doc in enumerate(results, start=1):print(f"\n第 {i} 条结果:\n{doc.page_content}")索引叶子层:向量库 `raptor_leafs` 共 8 条切片…Indexing leaf chunks: 100%|██████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 10.17it/s]
Generating mid-layer summaries: 100%|████████████████████████████████████████████████████| 5/5 [00:09<00:00, 1.97s/it]索引中间层:向量库 `raptor_middle` 共 5 条摘要…Indexing mid summaries: 100%|████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 17.34it/s]
Generating root-layer summaries: 100%|███████████████████████████████████████████████████| 2/2 [00:02<00:00, 1.45s/it]索引根层:向量库 `raptor_root_level` 共 2 条聚类摘要…Indexing root summaries: 100%|███████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 48.40it/s]=== 根层检索示例 ===第 1 条结果:
This text explains the limitations of LLMs, specifically their inability to effectively handle information outside their training data or exceeding their "context window." While the previous chapter introduced a basic chatbot, it highlights the need for a method to filter and provide relevant context to the LLM, especially when dealing with large datasets or information beyond the model's knowledge cutoff. The context window limitation stems from resource constraints, the quadratic complexity of the Transformer architecture's attention mechanism, and the fixed-length context windows used during training. This limitation restricts the amount of "recent information" the model can effectively process. The following chapters will focus on addressing this information filtering process to build more effective LLM applications.第 2 条结果:
The text explains Retrieval Augmented Generation (RAG) as a solution for feeding large amounts of data to Large Language Models (LLMs) that exceed their token limits. RAG involves two key steps: indexing and retrieval. Indexing pre-processes documents by extracting text, splitting it into chunks, converting it into numerical embeddings, and storing these embeddings in a vector store. Retrieval then uses this index to find relevant data to provide context for the LLM's output. The text focuses on the indexing step, specifically using LangChain's document loaders to convert various document types (e.g., .txt, .csv, .pdf, web pages) into a format suitable for LLMs. It also introduces the concept of embeddings, vector stores, and the need for document splitting due to LLM context window limitations.
芜湖!我们在根层打印出了与查询相关的两条结果。
但是我想同时看一下中间层和叶子层的检索效果:
# 5. 多层检索示例
query = "这个文档集合的整体主题是什么?"# 把各层的向量库对象和名称都放到一个列表里
layers = [("叶子层", leaf_vs),("中间层", mid_vs),("根层", root_vs),
]for name, vs in layers:print(f"\n=== {name} 检索(top-2)===\n")results = vs.similarity_search(query, k=2)for i, doc in enumerate(results, start=1):print(f"{name} 第 {i} 条结果:\n{doc.page_content}\n")=== 叶子层 检索(top-2)===叶子层 第 1 条结果:
## Converting Your Documents into Text:将文档转换为文本正如本章开头提到的,预处理文档的第一步是将其转换为文本。为了实现这一点,你需要构建逻辑来解析并提取文档内容,同时尽可能减少信息损失。幸运的是,LangChain 提供了名为 document loaders(文档加载器) 的工具,它们可以处理解析逻辑,并使你能够从各种数据源中“加载”数据,转换为一个 Document 类对象,该对象包含文本及其相关的元数据metadata。举例:一个简单的.txt文件,我们可以简单地导入LangChain TextLoader类来提取文本,如下所示:```python
from langchain_community.document_loaders import TextLoaderloader = TextLoader("./test.txt")
loader.load()
```
输出为:ModuleNotFoundError: No module named 'langchain_community'看到报错了,原因是:你使用了 from langchain_community.document_loaders import TextLoader,但你的环境里 没有安装名为 langchain_community 的模块。这个模块是 LangChain 0.1.13(2024年初)之后的新结构,把一些组件拆分到了子模块中(比如 loaders、tools 等),所以要单独安装。运行以下命令:```python
pip install -U langchain-community
```现在我们来试试:
```python
from langchain_community.document_loaders import TextLoaderloader = TextLoader("./test.txt", encoding="utf-8")
loader.load()
```
输出为:叶子层 第 2 条结果:
## Converting Your Documents into Text:将文档转换为文本正如本章开头提到的,预处理文档的第一步是将其转换为文本。为了实现这一点,你需要构建逻辑来解析并提取文档内容,同时尽可能减少信息损失。幸运的是,LangChain 提供了名为 document loaders(文档加载器) 的工具,它们可以处理解析逻辑,并使你能够从各种数据源中“加载”数据,转换为一个 Document 类对象,该对象包含文本及其相关的元数据metadata。举例:一个简单的.txt文件,我们可以简单地导入LangChain TextLoader类来提取文本,如下所示:```python
from langchain_community.document_loaders import TextLoaderloader = TextLoader("./test.txt")
loader.load()
```
输出为:ModuleNotFoundError: No module named 'langchain_community'看到报错了,原因是:你使用了 from langchain_community.document_loaders import TextLoader,但你的环境里 没有安装名为 langchain_community 的模块。这个模块是 LangChain 0.1.13(2024年初)之后的新结构,把一些组件拆分到了子模块中(比如 loaders、tools 等),所以要单独安装。运行以下命令:```python
pip install -U langchain-community
```现在我们来试试:
```python
from langchain_community.document_loaders import TextLoaderloader = TextLoader("./test.txt", encoding="utf-8")
loader.load()
```
输出为:=== 中间层 检索(top-2)===中间层 第 1 条结果:
This text introduces LangChain's document loaders, explaining how to load various document types into a format suitable for use with Large Language Models (LLMs). It covers:* **Basic Usage:** Demonstrates loading a `.txt` file using `TextLoader` and highlights the common pattern for using LangChain document loaders: choosing a loader, instantiating it with file path or URL, and calling `load()` to get a list of `Document` objects.
* **Different Loaders:** Mentions loaders for `.csv`, `.json`, and Markdown files, as well as integrations with platforms like Slack and Notion.
* **Web Loading:** Shows how to load and parse HTML content from a webpage using `WebBaseLoader` and `beautifulsoup4`.
* **PDF Loading:** Explains how to extract text from PDF documents using `PyPDFLoader`.
* **Document Splitting:** Introduces the problem of large documents exceeding LLM context windows and the need to split documents into smaller chunks for processing.
* **Context Windows and Tokens:** Briefly explains the concept of context windows in LLMs and embedding models, measured in tokens, and their limitations on input and output size.中间层 第 2 条结果:
The text discusses the challenge of providing large amounts of data to Large Language Models (LLMs) that exceed their token limits. The solution presented is **Retrieval Augmented Generation (RAG)**, a technique that involves two main steps:1. **Indexing:** Pre-processing documents to make them easily searchable for relevant information. This involves:* Extracting text from documents.* Splitting the text into manageable chunks.* Converting the text into numerical representations (embeddings) that computers can understand.* Storing these embeddings in a vector store for efficient retrieval. This process is called "ingestion."
2. **Retrieval:** Retrieving the most relevant external data from the index and using it as context for the LLM to generate accurate outputs.The text then focuses on the indexing step, specifically how to convert documents into text using LangChain's document loaders. It provides an example of using the `TextLoader` to load text from a `.txt` file and addresses a common error related to the `langchain_community` module, providing the solution to install it.=== 根层 检索(top-2)===根层 第 1 条结果:
This text explains the limitations of LLMs, specifically their inability to effectively handle information outside their training data or exceeding their "context window." While the previous chapter introduced a basic chatbot, it highlights the need for a method to filter and provide relevant context to the LLM, especially when dealing with large datasets or information beyond the model's knowledge cutoff. The context window limitation stems from resource constraints, the quadratic complexity of the Transformer architecture's attention mechanism, and the fixed-length context windows used during training. This limitation restricts the amount of "recent information" the model can effectively process. The following chapters will focus on addressing this information filtering process to build more effective LLM applications.根层 第 2 条结果:
The text explains Retrieval Augmented Generation (RAG) as a solution for feeding large amounts of data to Large Language Models (LLMs) that exceed their token limits. RAG involves two key steps: indexing and retrieval. Indexing pre-processes documents by extracting text, splitting it into chunks, converting it into numerical embeddings, and storing these embeddings in a vector store. Retrieval then uses this index to find relevant data to provide context for the LLM's output. The text focuses on the indexing step, specifically using LangChain's document loaders to convert various document types (e.g., .txt, .csv, .pdf, web pages) into a format suitable for LLMs. It also introduces the concept of embeddings, vector stores, and the need for document splitting due to LLM context window limitations.
通过这个方式,文档被递归地总结再总结,得到我们查询的结果,这实在是太酷了。
但我认为这个用于树状检索的递归抽象处理RAPTOR方案,确实更擅长处理多个文档、甚至是非常大的文档集合(但我这里只有一个文档),当你希望能同时回答
-
“某个具体事实在哪份文档里?”(低层次检索)
-
“整体来看,这个主题跨文档有哪些共同观点?”(高层次检索)
时,RAPTOR 能把海量文档切片 → 聚类 → 逐层抽象,最终在“叶子层”、“中间层”、“根层”建立多级索引,既能做精细的跨文档匹配,也能快速定位到全局概览。
ColBERT:优化嵌入
使用embedding模型在索引阶段时面临的一个挑战是,它们会将文本压缩成固定长度的向量表示,以捕捉文档的语义内容。虽然这种压缩对检索很有帮助,但如果把无关或冗余的内容也一起嵌入,就可能导致最终大模型输出中的“幻觉”现象。
要解决这个问题,可以采取以下措施:
-
为文档和query中的每个 token 生成上下文相关的嵌入(contextual embeddings)。
-
计算并对每个查询 token 与所有文档 token 之间的相似度进行评分。
-
对每个query embedding,取其与任意文档 embedding 的最高相似度分值,然后将这些最高分相加,得到每个文档的总分。
这种方式能提供一种更细粒度且高效的嵌入检索方法。幸运的是,一个名为 ColBERT 的embedding模型正是解决该问题的最佳方案。
下面介绍如何利用 ColBERT 来对我们的数据进行最优嵌入:
逐 Token 匹配方法详解
下面解释 ColBERT 中“逐 token”匹配的三步核心思路,并给出数学公式。
1. 对每个 token 生成上下文相关的嵌入(Contextual Embeddings)
- Token
- 文本被拆分成若干“词”或“子词”(token),如
"context window"可能分成["context", "window"]。
- 文本被拆分成若干“词”或“子词”(token),如
- Contextual Embeddings
- 传统的静态词向量(word2vec、fastText)给每个词一个固定 embedding,不管它在句中出现在哪儿都是一样的。但 ColBERT 用的是 Transformer LLM 输出的每个 token 在其上下文下的向量(即 contextual embeddings),同一个词在不同句子里的语义差异也能体现出来。
- 使用 Transformer LLM(如 BERT/ColBERT)对每个 token 在其上下文下生成向量:
D = [ d 1 , d 2 , … , d m ] (文档 tokens) D = [d_1, d_2, \dots, d_m] \quad\text{(文档 tokens)} D=[d1,d2,…,dm](文档 tokens)
Q = [ q 1 , q 2 , … , q n ] (查询 tokens) Q = [q_1, q_2, \dots, q_n] \quad\text{(查询 tokens)} Q=[q1,q2,…,qn](查询 tokens) - 同一个词在不同句子里会产生不同的向量,更好地捕捉语义差异。
2. 计算并对每个查询 token 与所有文档 token 之间的相似度
- 两两相似度
-
对文档向量集 (D) 和查询向量集 (Q),计算所有相似度分值:
sim ( q i , d j ) ∀ i = 1 … n , j = 1 … m \text{sim}(q_i, d_j) \quad\forall\,i=1\ldots n,\;j=1\ldots m sim(qi,dj)∀i=1…n,j=1…m -
常用余弦相似度(cosine similarity)来衡量:
cos ( θ ) = q i ⋅ d j ∥ q i ∥ 2 ∥ d j ∥ 2 \cos(\theta) = \frac{q_i \cdot d_j}{\|q_i\|_2\,\|d_j\|_2} cos(θ)=∥qi∥2∥dj∥2qi⋅dj -
这样就能知道查询中的每个 token(比如 “上下文”、“窗口”)分别和文档中哪一个 token 最相似。它比把全文压缩成一个整体向量要“粒度更细”,能捕捉到文档里哪一句、哪一段最对应查询中的哪个关键词。
-
3. 最大池化(Max Pooling)与求和(Sum)
- 最大池化 max pooling
对每个查询 token (q_i),取其与所有文档 token 相似度的最大值:
max j sim ( q i , d j ) \max_{j}\,\text{sim}(q_i, d_j) jmaxsim(qi,dj) - 求和
将所有查询 token 的最大分值相加,得到最终文档得分:
Score ( Q , D ) = ∑ i = 1 n max j sim ( q i , d j ) \text{Score}(Q, D) = \sum_{i=1}^{n} \max_{j}\,\text{sim}(q_i, d_j) Score(Q,D)=i=1∑njmaxsim(qi,dj) - 意义
- 细粒度匹配:每个查询 token 都能在文档中找到最佳对应;
- 高效聚合:只保留每个 token 的最大分值,避免存储或计算所有 (n \times m) 对相似度;
- 语义覆盖:确保查询中所有关键词都对得分有贡献。
为什么效果更好?
- 存储:索引时不仅保存整句向量,还保存了每个 token 的向量。
- 检索:查询时同样生成 token 向量,再用“最大池化+求和”策略,兼顾了准确性和效率。
- 跨语言/多场景:对多语言、多样本都能进行精细匹配,减少“整体句向量”带来的信息丢失与歧义。
得到该文档的最终得分意义是什么?
最终得分 Score(Q,D) 就是一个把“查询中每个 token 匹配度”汇总成单一标量的方式,用来量化文档与查询在“关键词级别”上的整体相关性,常用于对检索结果进行排序和筛选。
-
用于排序和筛选
-
在检索系统里,我们会拿到所有候选文档的Score(Q,D) 然后按从高到低排序,把最相关的 N 篇返回给用户。
-
也可以设定一个阈值——只有分数超过某个值的文档才算“足够相关”,才能进一步给下游的 LLM 做阅读和生成。
-
-
偏好度量
由于是累加形式,文档越长、信息越多(尤其是全都和查询相关),分数也会相应更高。这一点和普通句向量的“长度归一化”评分(只看角度)略有不同,更像是在奖励“覆盖越全面、对应越紧密”的文档。
# RAGatouille is a library that makes it simple to use ColBERT
#! pip install -U ragatouille# 这里的代码是因为报错:ImportError: cannot import name 'AdamW' from 'transformers'
# 你安装的 transformers 版本是 5.x 以上,而从 v5.0 开始,AdamW 和 get_linear_schedule_with_warmup 等优化器接口已经不再暴露在顶层命名空间里,
# 而 Ragatouille(以及它依赖的 ColBERT 包)还在用老写法
# —— 1. Monkey‐patch transformers ——
import transformers
import torch.optim
from transformers import get_scheduler# 1.1 顶层挂回 AdamW,直接用 PyTorch 的实现
transformers.AdamW = torch.optim.AdamW# 1.2 顶层挂回 get_linear_schedule_with_warmup,
# 内部调用 get_scheduler(name="linear", …) 保证签名兼容
def get_linear_schedule_with_warmup(optimizer, num_warmup_steps, num_training_steps, **kwargs
):return get_scheduler(name="linear",optimizer=optimizer,num_warmup_steps=num_warmup_steps,num_training_steps=num_training_steps,**kwargs,)transformers.get_linear_schedule_with_warmup = get_linear_schedule_with_warmup# 加载一个预训练好的 ColBERT v2.0 模型(在 Hugging Face Hub 上的模型标识符)。
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")import requests# 获取维基百科页面文本
def get_wikipedia_page(title: str):"""Retrieve the full text content of a Wikipedia page.:param title: str - Title of the Wikipedia page.:return: str - Full text content of the page as raw string."""# Wikipedia API endpointURL = "https://en.wikipedia.org/w/api.php"# Parameters for the API requestparams = {"action": "query","format": "json","titles": title,"prop": "extracts","explaintext": True,}# Custom User-Agent header to comply with Wikipedia's best practicesheaders = {"User-Agent": "RAGatouille_tutorial/0.0.1"}response = requests.get(URL, params=params, headers=headers)data = response.json()# Extracting page contentpage = next(iter(data["query"]["pages"].values()))return page["extract"] if "extract" in page else None# 调用上面的函数,拿到宫崎骏的整页文本,存入 full_document 字符串。
full_document = get_wikipedia_page("Hayao_Miyazaki")# 创建索引(Indexing)
RAG.index(collection=[full_document],index_name="Miyazaki-123",max_document_length=180,split_documents=True,use_faiss=True, # 强制切换到 FAISS
)# query
# 在刚刚建立好的索引上做检索,把查询句子分词、产生每个 token 的向量、执行 ColBERT 的 “late interaction” 机制。
results = RAG.search(query="What animation studio did Miyazaki found?", k=3)
results
ImportError: DLL load failed while importing decompress_residuals_cpp: 找不到指定的模块。
重试以下办法:
from ragatouille import RAGPretrainedModel
import transformers, torch, requests, shutil, os# ---- 1. 依旧的 transformers monkey-patch ----
transformers.AdamW = torch.optim.AdamW
transformers.get_linear_schedule_with_warmup = (lambda o, w, t, **kw: transformers.get_scheduler("linear", o, w, t, **kw)
)# ---- 2. 载入 ColBERT-RAG ----
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")# ---- 3. 把分区数统一设成 2 ----
cfg = RAG.model.config
for attr in ("n_partitions", "num_partitions", "partitions", "npartitions"):if hasattr(cfg, attr):setattr(cfg, attr, 2) # ← 关键信息# ---- 4. 只有一篇短文档做演示 ----
doc = "Hayao Miyazaki co-founded Studio Ghibli in 1985 together with Isao Takahata."# ---- 5. 建索引:用全新名字或覆盖旧索引 ----
RAG.index(collection=[doc],index_name="demo_2partitions", # ← 换个新名字最省事overwrite_index=True, # 若想重用旧名字就加这一行
# split_documents=False,max_document_length=len(doc),use_faiss=True # 留着也没问题
)# ---- 6. 检索验证 ----
print(RAG.search("Which studio did Miyazaki found?", k=3))________________________________________________________________________________
WARNING! You have a GPU available, but only `faiss-cpu` is currently installed.This means that indexing will be slow. To make use of your GPU.
Please install `faiss-gpu` by running:
pip uninstall --y faiss-cpu & pip install faiss-gpu________________________________________________________________________________
Will continue with CPU indexing in 5 seconds...RuntimeError: Error in void __cdecl faiss::Clustering::train_encoded(idx_t, const uint8_t *, const Index *, Index &, const float *) at D:\a\faiss-wheels\faiss-wheels\faiss\faiss\Clustering.cpp:295: Error: 'nx >= k' failed: Number of training points (23) should be at least as large as number of clusters (64)
# 转为 LangChain Retriever
# 把 RAGatouille 的索引器,包装成与 LangChain 接口兼容的 Retriever
retriever = RAG.as_langchain_retriever(k=3)
retriever.invoke("What animation studio did Miyazaki found?")# 打印所有返回的 Document
for i, doc in enumerate(results, start=1):print(f"\n=== Result {i} ===")print("内容:")print(doc.page_content)print("元数据:")print(doc.metadata)
我尽力了,我这里只有一个文档,无法满足这个程序的要求,这个程序适用于大规模文档的情况下,所以一直报错。
报错:
RuntimeError: Error in void __cdecl faiss::Clustering::train_encoded(idx_t, const uint8_t *, const Index *, Index &, const float *) at D:\a\faiss-wheels\faiss-wheels\faiss\faiss\Clustering.cpp:295: Error: 'nx >= k' failed: Number of training points (22) should be at least as large as number of clusters (64)
语料只产生 22 条嵌入,却要求分成 64 个聚类;
FAISS 不允许 “簇数 > 样本数”,所以抛出 “nx ≥ k failed” 的错误。
整体流程小结:
-
加载预训练 ColBERT:
from_pretrained(...) -
获取原始文本:调用 Wikipedia API
-
建立索引:
RAG.index(...),自动分片并生成向量索引 -
直接检索:
RAG.search(...)得到片段级答案 -
与 LangChain 集成:as_langchain_retriever 并在 Pipeline 中 invoke 使用
总结
总结一下,本节我们学习了两种方法:
-
RAPTOR:用于树状检索的递归抽象处理
-
ColBERT:优化嵌入
这两种方法都更适用于多个文档检索的情况,尤其是第二个ColBERT方法。