【读论文】美团开源MOE大模型LongCat-Flash
1. 引言:MoE模型的效率与智能的平衡
MoE(混合专家)架构通过在每个Transformer层中设置多个“专家”(通常是FFN块),并让每个token只被路由到少数几个专家进行计算,实现了在保持巨大总参数量的同时,大幅降低单个token前向传播的计算成本。这使得训练和部署数千亿甚至万亿参数的模型成为可能。
LongCat-Flash正是建立在MoE的这一核心优势之上,并从两个协同方向上推进了LLM的前沿:
- 计算效率 (Computational Efficiency):通过创新的架构设计和底层优化,实现更大规模、更高吞吐、更低延迟的训练和推理。
- 智能体能力 (Agentic Capability):通过精心设计的多阶段训练管线和高质量合成数据,系统性地培养模型解决真实世界复杂任务的能力。
2. LongCat-Flash架构创新:为效率而生的MoE新范式
LongCat-Flash的核心架构采用了带有两项关键创新的新型MoE。
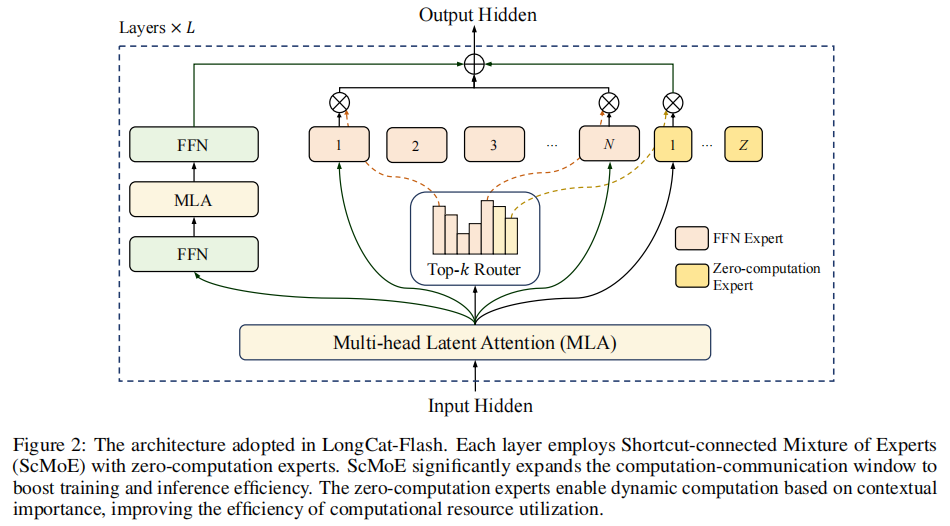
(LongCat-Flash的MoE层架构。输入经过第一个MLA块后,其输出通过一个快捷方式连接(shortcut connection)直接与MoE块的输出相加。同时,M