犀牛派A1上使用Faster Whisper完成音频转文字
项目介绍:Faster Whisper 是一个基于 CTranslate2 的 OpenAI Whisper 模型的高效实现。它是一个快速推理引擎,用于 Transformer 模型,相比 OpenAI 的 Whisper 模型,速度提升了 4 倍。该项目支持 Windows、Linux 和 macOS 平台,并且提供了多种优化选项,如 FP16 和 INT8 计算类型,以适应不同的硬件环境。
硬件:犀牛派A1
平台:QCS6490
一、环境准备
打开终端,在命令行界面中输入如下命令来安装Faster Whisper
sudo apt update && sudo apt install -y python3-pip ffmpeg
#因为这里使用CPU进行推理,安装 CPU 优化的 CTranslate2 和 Faster-Whisper
pip install faster-whisper
pip install ctranslate2 --no-deps # 确保不安装 GPU 相关依赖
pip install faster-whisper
二、准备推理脚本
编写或拉取一个脚本,可命名为 test.py
from faster_whisper import WhisperModel
import sys
import time
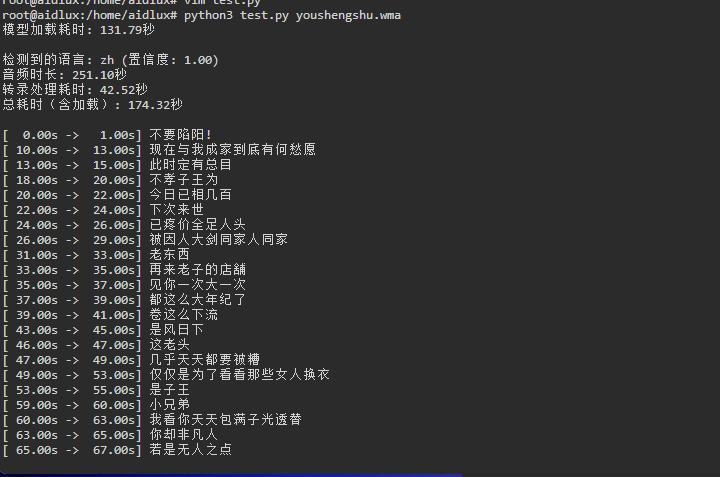
def main():# 获取音频文件名if len(sys.argv) > 1:filename = sys.argv[1]else:filename = input("请输入要转录的音频文件名:")# 选择模型大小,例如 "base", "small", "medium", "large-v3"model_size = "small"# 加载模型并统计加载时间load_start = time.perf_counter()model = WhisperModel(model_size,device="cpu",compute_type="int8")load_duration = time.perf_counter() - load_startprint(f"模型加载耗时: {load_duration:.2f}秒")# 开始转录计时transcribe_start = time.perf_counter()# 自动检测语言转录segments, info = model.transcribe(filename, beam_size=5)# 立即处理所有分段以确保准确计时segments = list(segments)# 结束计时transcribe_duration = time.perf_counter() - transcribe_start# 输出结果print(f"\n检测到的语言: {info.language} (置信度: {info.language_probability:.2f})")print(f"音频时长: {info.duration:.2f}秒")print(f"转录处理耗时: {transcribe_duration:.2f}秒")print(f"总耗时(含加载): {load_duration + transcribe_duration:.2f}秒\n")# 输出逐句转录结果for segment in segments:print(f"[{segment.start:6.2f}s -> {segment.end:6.2f}s] {segment.text.strip()}")if __name__ == "__main__":main()三、运行测试
可在浏览器上任意下载一个音频文件
将音频放入测试脚本的同级目录进行测试,脚本可自动检测语言
python3 test.py youshengshu.wma