CVPR 2025 | 哈工大港大DeCLIP:解耦CLIP注意力实现开放词汇感知!
密集视觉感知任务长期受限于预定义类别,而视觉语言模型(Vision-Language Models, VLMs)(如CLIP)虽具备开放词汇能力,但直接应用于密集任务时,其局部特征表达能力不足导致性能不佳。本文通过分析发现,CLIP的深层图像令牌(token)未能有效关注语义相关区域,导致特征缺乏局部判别性(local discriminability)和空间一致性(spatial consistency)。
为解决此问题,本文提出DeCLIP,一个通过解耦学习(decoupled learning)增强CLIP局部表示的无监督微调框架。DeCLIP将自注意力模块分解为“内容(content)”特征与**“上下文(context)”特征。其中,上下文特征通过联合蒸馏视觉基础模型(Vision Foundation Models, VFMs)的语义相关性和扩散模型(diffusion models)的对象完整性线索来增强空间一致性;内容特征则通过与图像裁切块的[CLS]表示对齐,并受VFM的区域相关性约束,来提升局部判别性。DeCLIP旨在成为一个通用的开放词汇(Open-Vocabulary, OV)密集感知**基础模型,并在多项任务中取得显著成效。
我整理了CVPR 2025计算机视觉相关论文+源码,感兴趣的自取!
论文这里
一、论文基本信息

基本信息
- 论文标题:Generalized Decoupled Learning for Enhancing Open-Vocabulary Dense Perception
- 作者:Junjie Wang, Keyu Chen, Yulin Li, Bin Chen, Hengshuang Zhao, Xiaojuan Qi, Zhuotao Tian
- 作者单位:哈尔滨工业大学(深圳)、香港大学
- 代码链接:https://github.com/xiaomoguhz/DeCLIP
- 论文链接:https://arxiv.org/pdf/2508.11256v1
摘要精炼

本文旨在解决CLIP等VLMs在应用于OV密集感知任务(如检测、分割)时,因局部特征质量不佳而导致的性能瓶颈问题。通过分析,论文指出CLIP深层图像令牌的注意力会异常集中于少数“代理令牌”,而非语义相关区域,从而损害了其密集感知能力。
为解决该问题,论文提出了DeCLIP框架,其核心技术贡献是解耦自注意力模块,将特征分离为“内容”与“上下文”两部分并进行独立优化。“上下文”特征通过蒸馏VFM的语义相关性(由扩散模型的注意力图增强)来提升空间一致性;“内容”特征则通过自蒸馏(与图像块的[CLS]对齐)并引入VFM的**区域相关性约束(Region Correlation Constraint, RCC)**来增强局部判别性。
实验表明,DeCLIP作为一个基础模型,在2D/3D检测与分割、视频实例分割及6D位姿估计等六项密集感知任务上均取得SOTA性能。
二、研究背景与相关工作
研究背景
密集感知任务(如目标检测、图像分割)是计算机视觉的核心,但传统方法通常局限于封闭的、预定义的类别集,这极大地限制了它们在视觉概念无界的真实世界中的应用。OV密集感知旨在利用自然语言描述来检测和分割任意类别的对象,从而打破这一限制。VLMs,特别是CLIP,因其强大的零样本识别能力成为实现OV感知的关键。
然而,CLIP为图像级分类设计,将其直接用于需要像素级或区域级理解的密集感知任务时,会出现明显的性能下降。根本原因在于其提取的密集特征在局部判别性和空间一致性上存在固有缺陷,未能有效捕捉细粒度的视觉信息。
相关工作
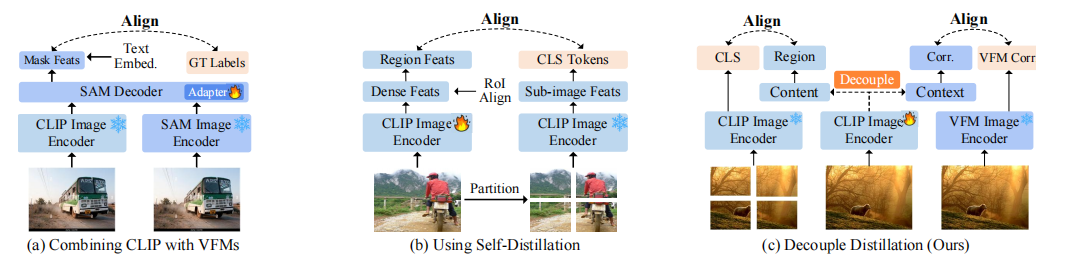
现有工作主要从三方面尝试将CLIP适配于密集感知任务:
- 联合微调(Joint Fine-Tuning):在训练下游任务(如分割)时,同步微调CLIP。这类方法通常任务或模型特定,且依赖昂贵的密集标注数据。
- 预微调(Pre-Fine-Tuning):通过自监督或伪标签等低成本方式先对CLIP进行微调,再用于下游任务。例如,CLIPSelf通过对齐区域特征与图像块的[CLS]特征来增强区域级表示,但对需要像素级细节的分割任务提升有限。
- 融合CLIP与VFM:将CLIP的语义理解能力与SAM等VFM强大的分割能力结合。这类方法如图4(a)所示,侧重于系统集成而非增强CLIP自身。
相较之下,DeCLIP如图4©所示,提出了一种新颖的解耦蒸馏策略,专注于从根本上增强CLIP自身的密集特征质量,使其成为更通用的OV密集感知基础模型。
三、主要贡献与创新
- 揭示CLIP密集感知瓶颈:通过可视化对比分析,首次明确指出CLIP深层图像令牌的注意力会异常集中于少数“代理令牌”而非语义相关区域,这是其密集感知性能不佳的根本原因。
- 提出解耦学习框架DeCLIP:设计了一个创新的无监督微调框架,通过解耦自注意力模块,将特征优化目标分离为“内容”(局部判别性)和“上下文”(空间一致性),从而有效解决了二者之间的优化冲突。
- 多教师模型协同蒸馏:创造性地融合了多种基础模型的优势。利用VFM(如DINOv2)提供语义相关性,并引入扩散模型(Stable Diffusion)的自注意力图来增强对象边界和完整性,为上下文特征提供高质量的监督信号。
- 通用OV密集感知基础模型:实验证明DeCLIP可作为一个即插即用的基础模型,显著提升了包括2D/3D/视频检测与分割、6D位姿估计在内的多种OV密集感知任务的性能,展示了其广泛的适用性和有效性。
四、研究方法与原理
总体框架与核心思想
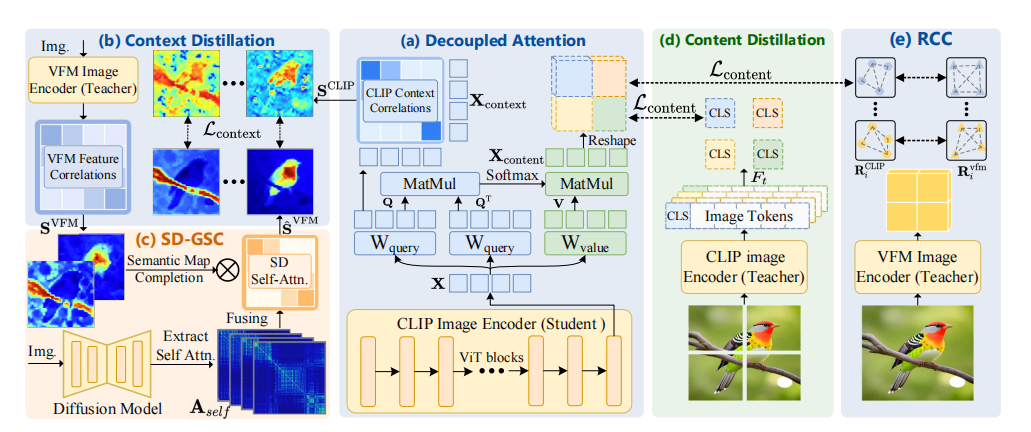
DeCLIP的核心思想是通过解耦特征并进行多源蒸馏,协同提升CLIP密集特征的局部判别性与空间一致性。其设计哲学是“分而治之”,即识别出CLIP在统一架构中优化两个冲突目标(V-L对齐与空间相关性)的困难,并将其分解。
如图5(a)所示,框架的核心在于对CLIP最后一个注意力块进行修改,将其分解为两个并行分支:
- 上下文(Context)分支:专注于学习像素/区域间的空间与语义关联,其输出
X_context用于提升空间一致性。 - 内容(Content)分支:专注于学习每个像素/区域独立的、与语言对齐的语义信息,其输出
X_content用于提升局部判别性。
通过这种解耦,两个分支可以从不同的“教师”模型处接收无冲突的指导信号,从而在统一架构内实现双重目标的优化。
关键实现与评估原理
关键实现细节:
-
解耦注意力(Decoupled Attention):将标准自注意力的输出ZZZ分解。上下文特征XcontextX_{\text{context}}Xcontext直接取自Query projecion,而内容特征XcontentX_{\text{content}}Xcontent由Value在XcontextX_{\text{context}}Xcontext的自注意力引导下加权得到。
Xcontext=Projq(X),V=Projv(X)X_{\text{context}} = \text{Proj}_q(X), \quad V = \text{Proj}_v(X) Xcontext=Projq(X),V=Projv(X)
Xcontent=Proj(Attncontext⋅V)X_{\text{content}} = \text{Proj}(\text{Attn}_{\text{context}} \cdot V) Xcontent=Proj(Attncontext⋅V)
其中,Attncontext=SoftMax(XcontextXcontextT/d)\text{Attn}_{\text{context}} = \text{SoftMax}(X_{\text{context}} X_{\text{context}}^T / \sqrt{d})Attncontext=SoftMax(XcontextXcontextT/d)。 -
上下文特征蒸馏:
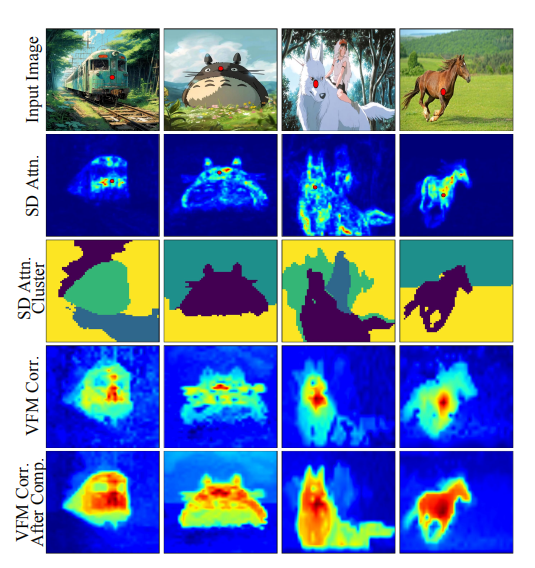
- SD引导的语义补全(SD-Guided Semantic Completion, SD-GSC):由于VFM的语义亲和力图(SVFMS_{\text{VFM}}SVFM)边界模糊,本文利用SD模型的自注意力图(A^self\hat{A}_{\text{self}}A^self)来增强其对象完整性,得到更优的监督信号S^VFM\hat{S}_{\text{VFM}}S^VFM。如图6所示,补全后的亲和力图对象边界更清晰。
S^VFM=A^self×SVFM\hat{S}_{\text{VFM}} = \hat{A}_{\text{self}} \times S_{\text{VFM}} S^VFM=A^self×SVFM - 上下文损失:使用KL散度约束学生模型CLIP的上下文特征相关性矩阵SCLIPS_{\text{CLIP}}SCLIP与教师信号S^VFM\hat{S}_{\text{VFM}}S^VFM对齐。
Lcontext=1HW∑i=1HWKL(S^VFMi,:,SCLIPi,:)\mathcal{L}_{\text{context}} = \frac{1}{HW} \sum_{i=1}^{HW} \text{KL}(\hat{S}_{\text{VFM}_{i,:}}, S_{\text{CLIP}_{i,:}}) Lcontext=HW1i=1∑HWKL(S^VFMi,:,SCLIPi,:)
-
内容特征蒸馏:
- 自蒸馏:如文中图5(d)所示,将图像划分为多个子区域,强制学生模型在这些区域上提取的特征(fˉsi\bar{f}_s^ifˉsi)与教师模型(即CLIP自身)对相应裁切图像生成的[CLS]令牌(ftif_t^ifti)保持一致。
Lcontent1=1k∑i=1k1−cos(fˉsi,fti)\mathcal{L}_{\text{content}_1} = \frac{1}{k} \sum_{i=1}^{k} 1 - \text{cos}(\bar{f}_s^i, f_t^i) Lcontent1=k1i=1∑k1−cos(fˉsi,fti) - 区域相关性约束(Region Correlation Constraint, RCC):为防止上述自蒸馏过程破坏特征的空间相关性,额外引入一个约束,要求学生模型在区域内的相关性RCLIPiR_{\text{CLIP}}^iRCLIPi与VFM特征在同一区域内的相关性RvfmiR_{\text{vfm}}^iRvfmi对齐。
Lcontent2=KL(Rvfmi,RCLIPi)\mathcal{L}_{\text{content}_2} = \text{KL}(R_{\text{vfm}}^i, R_{\text{CLIP}}^i) Lcontent2=KL(Rvfmi,RCLIPi)
最终内容损失为两者之和。
- 自蒸馏:如文中图5(d)所示,将图像划分为多个子区域,强制学生模型在这些区域上提取的特征(fˉsi\bar{f}_s^ifˉsi)与教师模型(即CLIP自身)对相应裁切图像生成的[CLS]令牌(ftif_t^ifti)保持一致。
-
总损失:
Ltotal=Lcontent+λLcontext\mathcal{L}_{\text{total}} = \mathcal{L}_{\text{content}} + \lambda \mathcal{L}_{\text{context}} Ltotal=Lcontent+λLcontext
其中λ\lambdaλ是平衡超参数,默认设为0.25。
核心评估原理与指标:
- 评估指标:根据不同任务采用标准指标,主要包括:
- 目标检测:AP, mAP (mean Average Precision)。
- 图像分割:mIoU (mean Intersection over Union)。
- 3D分割/位姿估计:AP, AR (Average Recall)。
五、实验结果与分析
实验设置
- 数据集:训练于COCO 2017训练集。在超过10个OV密集感知基准上进行评估,涵盖2D(OV-COCO, OV-LVIS, ADE20K等)、3D(ScanNet200)、视频(LV-VIS, YTVIS)和6D位姿(REAL275, TOYL)等多种场景。
- 评估指标:mAP, mIoU, AP, AR等。
- 对比基线:与各任务领域的SOTA方法进行对比,如Open3DIS (3D分割), CLIP-VIS (视频分割), Oryon (6D位姿), F-ViT, CAT-Seg (2D检测与分割)等。
- 关键超参:VLM基线为EVA-CLIP,VFM教师模型为DINOv2,SD模型为Stable Diffusion v2.1,损失权重λ=0.25\lambda=0.25λ=0.25。
核心实验与结论
【核心实验:OV 3D实例分割 - Table 2】
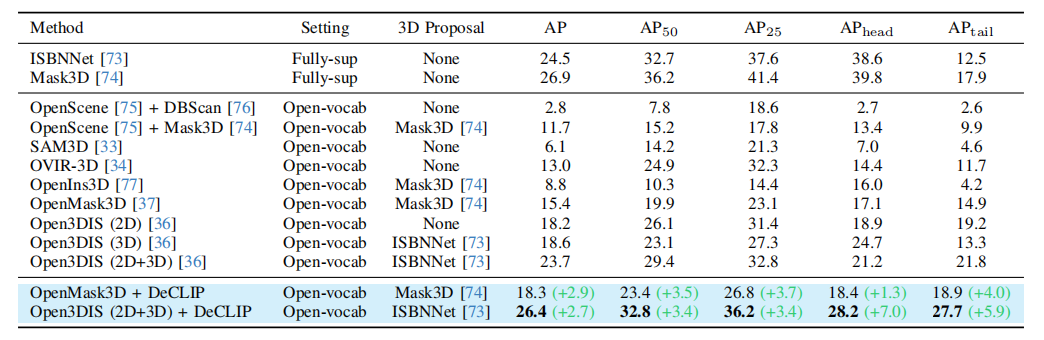
- 实验目的: 该实验旨在验证DeCLIP作为基础模型,能否提升现有复杂3D场景理解方法的性能。3D实例分割任务对特征的局部判别性(区分不同物体)和空间一致性(保持物体内部完整)要求极高,是检验DeCLIP能力的绝佳场景。
- 关键结果: 如表2所示,将现有SOTA方法OpenMask3D和Open3DIS的CLIP骨干网络替换为DeCLIP后,性能得到显著提升。以更具挑战性的长尾类别指标为例,OpenMask3D在ScanNet200上的APtailAP_{tail}APtail从14.9提升至18.9 (+4.0),Open3DIS的APtailAP_{tail}APtail从21.8提升至27.7 (+5.9)。新模型在整体AP、AP50/25等指标上也全面超越了所有基线方法。如图8所示,定性结果也表明DeCLIP能实现更精确的3D实例分割。

- 作者结论: 结果表明,DeCLIP提供的密集特征质量远高于原始CLIP,能够作为一个即插即用的强大骨干,有效赋能现有的OV密集感知模型,特别是在具有挑战性的3D场景和长尾类别上。这有力地证明了DeCLIP作为OV密集感知基础模型的潜力。
六、论文结论与启示
总结
本文通过深入分析CLIP的注意力机制,揭示了其在密集感知任务中表现不佳的根源——深层图像令牌丧失了对语义相关区域的有效关注。基于此,论文提出了DeCLIP,一个新颖的、通过解耦学习进行无监督微调的框架。
DeCLIP巧妙地将特征优化分解为“内容”和“上下文”两个正交目标,并分别从VFM和扩散模型中蒸馏知识,成功地增强了CLIP密集特征的局部判ěbié性和空间一致性。在横跨2D、3D和视频的六大类OV密集感知任务上的广泛实验,均一致性地证明了DeCLIP作为通用基础模型的卓越性能和巨大潜力。
展望
论文本身未明确提出未来展望,但其工作揭示了以下潜在方向:
- 探索更优的教师模型组合:可以研究融合更多类型的基础模型(如更多样的VFM或生成模型)作为教师,以提供更丰富、更精确的监督信号。
- 扩展至更多模态:目前DeCLIP专注于视觉特征增强,未来可探索将其解耦思想扩展至多模态密集感知任务,如音视频分割。
- 更高效的蒸馏框架:虽然DeCLIP是无监督微调,但仍涉及多个大型模型。研究更轻量化或更高效的蒸馏方法将是重要的优化方向。