[大模型微调]基于llama_factory用 LoRA 高效微调 Qwen3 医疗大模型:从原理到实现
在大模型落地医疗场景时,直接使用通用预训练模型往往存在 “医疗知识精准度不足”“临床场景适配性差” 等问题,而全量微调又面临 “显存占用高、训练成本高、部署难度大” 的痛点。此时,LoRA(Low-Rank Adaptation,低秩适应) 技术成为解决这一矛盾的最优解之一。本文将先解析 LoRA 的核心逻辑,再带大家一步步完成基于 LoRA 的 Qwen3 医疗大模型微调,最终实现医疗场景下的精准推理。

【如果你对人工智能的学习有兴趣可以看看我的其他博客,对新手很友好!!!】
【本猿定期无偿分享学习成果,欢迎关注一起学习!!!】
一、LoRA:大模型高效微调的 “轻量级方案”
1.1 为什么需要 LoRA?

1.2 LoRA 的核心原理

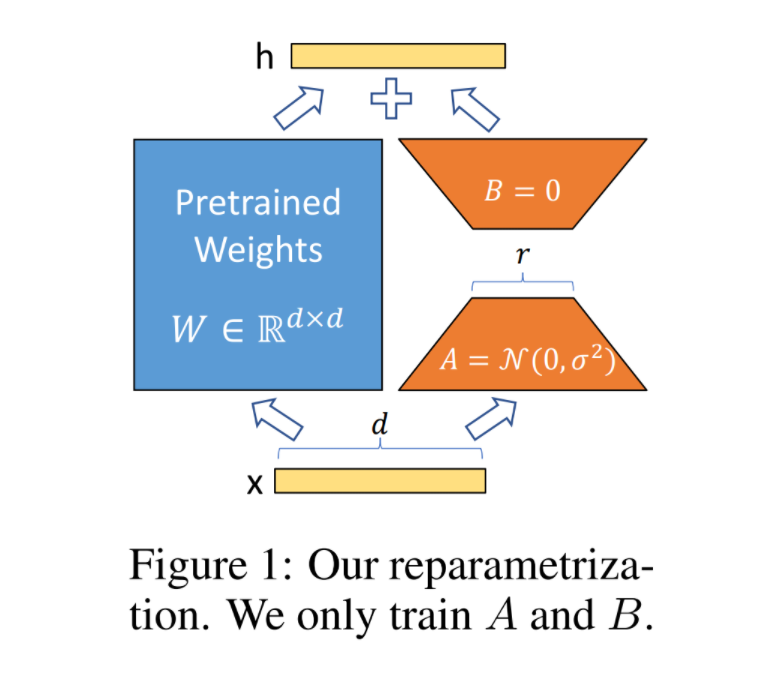
1.3 LoRA 在医疗微调中的优势

二、环境搭建:从 conda 环境到 PyTorch 配置
微调前需先搭建稳定的开发环境,核心包括 Python 环境、LLaMA-Factory 工具库、PyTorch(含 CUDA 支持),以下是分步操作指南。
2.1 创建 conda 虚拟环境
LLaMA-Factory 是一款功能强大的大模型微调工具,支持 LoRA、QLoRA 等多种微调方式,建议单独创建 conda 环境避免依赖冲突:
(1)创建conda环境
打开 Anaconda Prompt,执行以下命令创建名为llama_factory的虚拟环境,指定 Python 版本为 3.11(兼容性最优):
conda create -n llama_factory python=3.11 -y(2)激活环境
conda activate llama_factory2.2 LLaMA-Factory 的下载与配置
去GitHub上下载zip并解压
GitHub - hiyouga/LLaMA-Factory: Unified Efficient Fine-Tuning of 100+ LLMs & VLMs (ACL 2024)
下载 LLaMA-Factory 工具包至D:\bigmodel_change\LLaMA-Factory-main,通过以下命令切换至该目录:
# 切换至D盘(根据实际路径调整)
D:
# 进入LLaMA-Factory主目录
cd D:\bigmodel_change\LLaMA-Factory-main\然后执行命令安装依赖(目录下要有requirements.txt):
pip install -r requirements.txt2.3 安装 PyTorch 与依赖库
微调需依赖 PyTorch(需支持 CUDA,否则无法利用 GPU 加速)、transformers 等库,其中 PyTorch 的 CUDA 版本需与本地显卡匹配:
若未安装,可参考我的往期博客:
纯干货,无废话CUDA、cuDNN、 PyTorch 环境搭建教程_深度学习环境搭建之cuda、cudnn以及pytorch和torchvision的whl文件安装方法-CSDN博客
三、数据与模型准备:医疗数据集 + Qwen3 模型
3.1 下载 Qwen3 预训练模型
Qwen3 是阿里云推出的大模型,支持多语言与复杂任务,需从官方平台下载:
-
国内用户:优先选择 ModelScope,地址:https://modelscope.cn/,搜索 “Qwen3”,根据需求下载对应规模(如 Qwen3-7B、Qwen3-14B)的模型;
-
国际用户:选择 Hugging Face,地址:https://huggingface.co/,搜索 “Qwen/Qwen3-7B”,通过git lfs工具下载。
下载完成后,在 LLaMA-Factory 主目录下新建models文件夹。
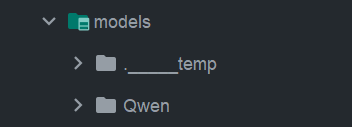
将 Qwen3 模型文件(含config.json、pytorch_model.bin等)复制到models目录中,路径示例:D:\bigmodel_change\LLaMA-Factory-main\models\Qwen3-7B
不会下载模型的同学这边看(还有调用和部署教程哦!):
大模型云端调用与本地部署?看这一篇就够了!-CSDN博客
3.2 准备医疗数据集
医疗微调的核心是 “高质量数据集”,需选择标注规范、覆盖临床场景的数据集,推荐从 Hugging Face 获取:
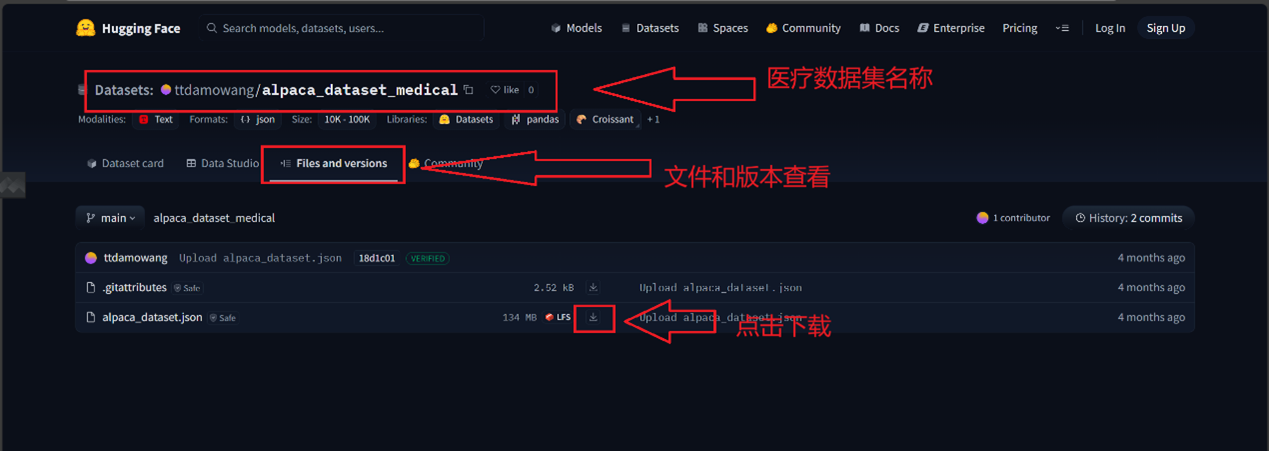
-
进入 Hugging Face 数据集页面(https://huggingface.co/datasets),搜索关键词 “medical”“clinical”“healthcare”,推荐数据集:
-
medalpaca/medical_meadow_medqa:包含数千条医疗问答数据;
-
tatsu-lab/alpaca_medical:Alpaca 格式的医疗数据集,适配 LLaMA-Factory;
-
下载数据集(以 Alpaca 格式为例),获取alpaca_dataset.json文件;
-
将alpaca_dataset.json复制到 LLaMA-Factory 的data目录下,路径:D:\bigmodel_change\LLaMA-Factory-main\data\alpaca_dataset.json。
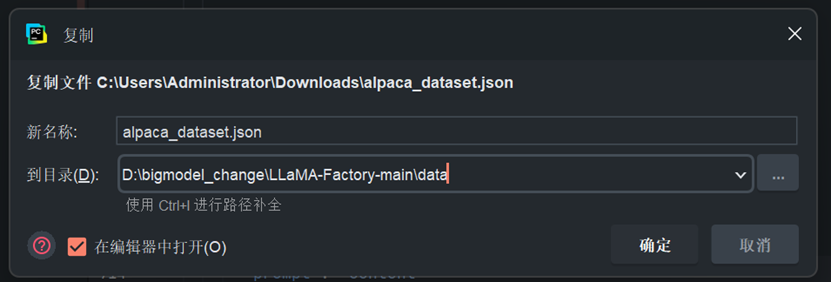
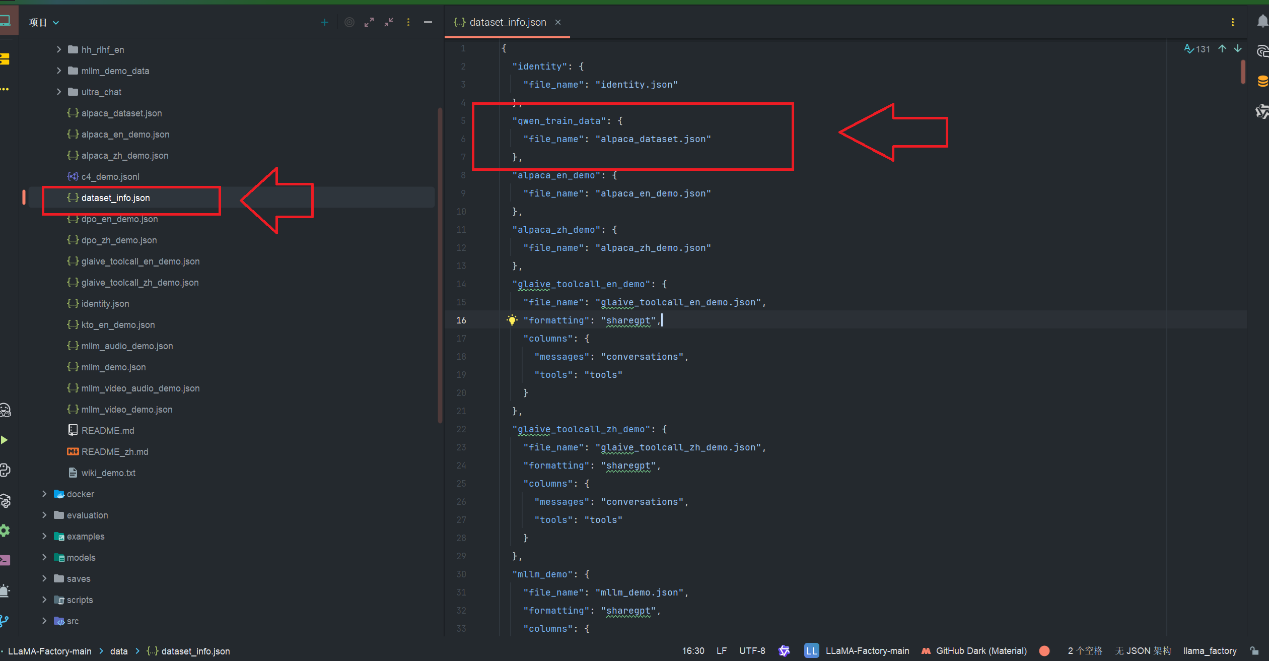
3.3 配置数据集信息
需修改data目录下的dataset_info.json文件,让 LLaMA-Factory 识别新的医疗数据集。
四、LoRA 微调:基于 WebUI 的可视化操作
LLaMA-Factory 提供 WebUI 界面,无需手动编写大量代码,即可完成 LoRA 微调参数配置与训练启动。
4.1 启动 WebUI
在 LLaMA-Factory 主目录的终端(PyCharm 终端或 Anaconda Prompt)中,执行以下命令启动 WebUI:
python -m llamafactory.cli webui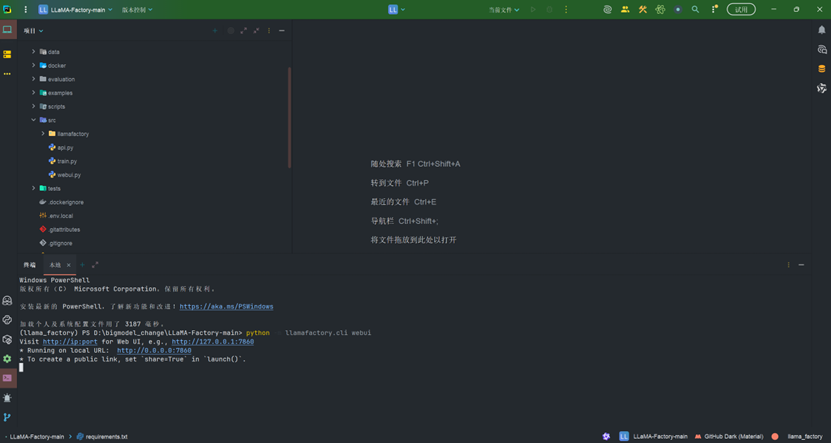
4.2 关键参数配置
注意跑大模型的算力要求很高,哪怕是lora
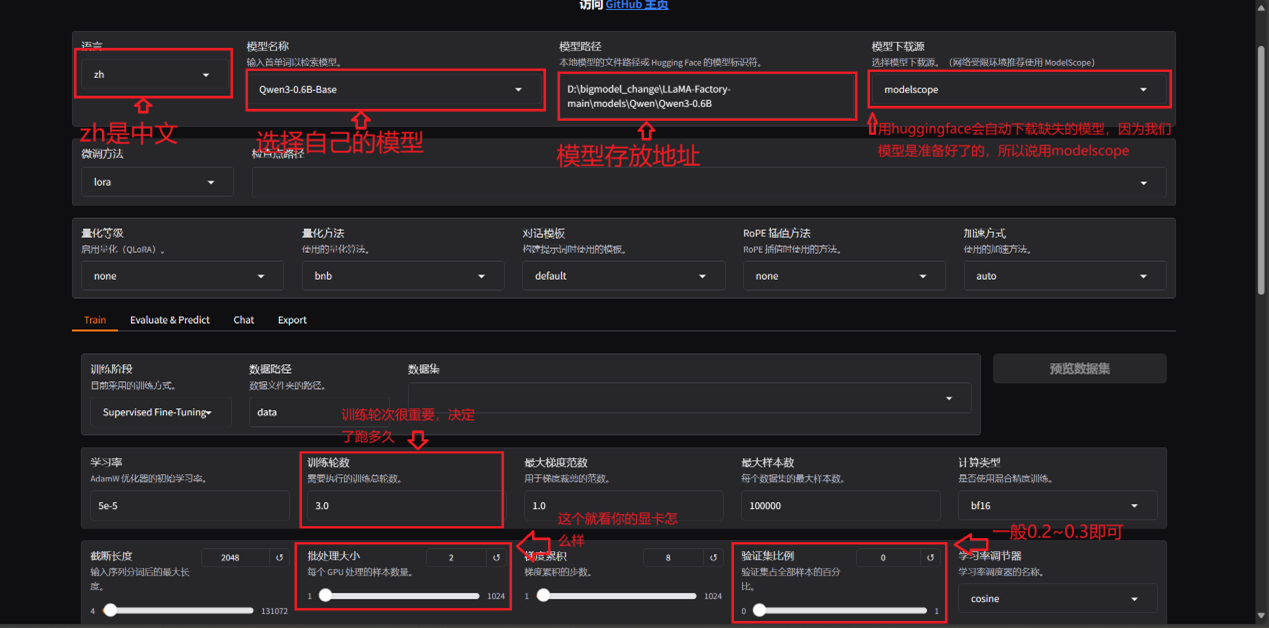
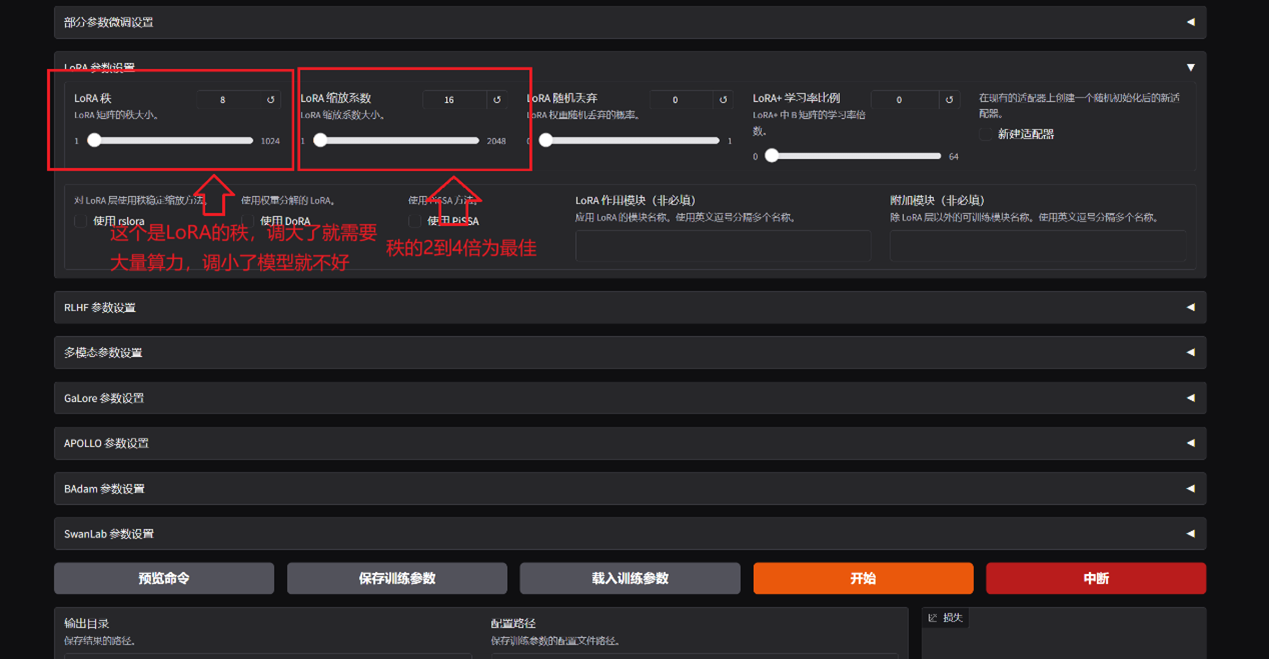
其他参数按需设置
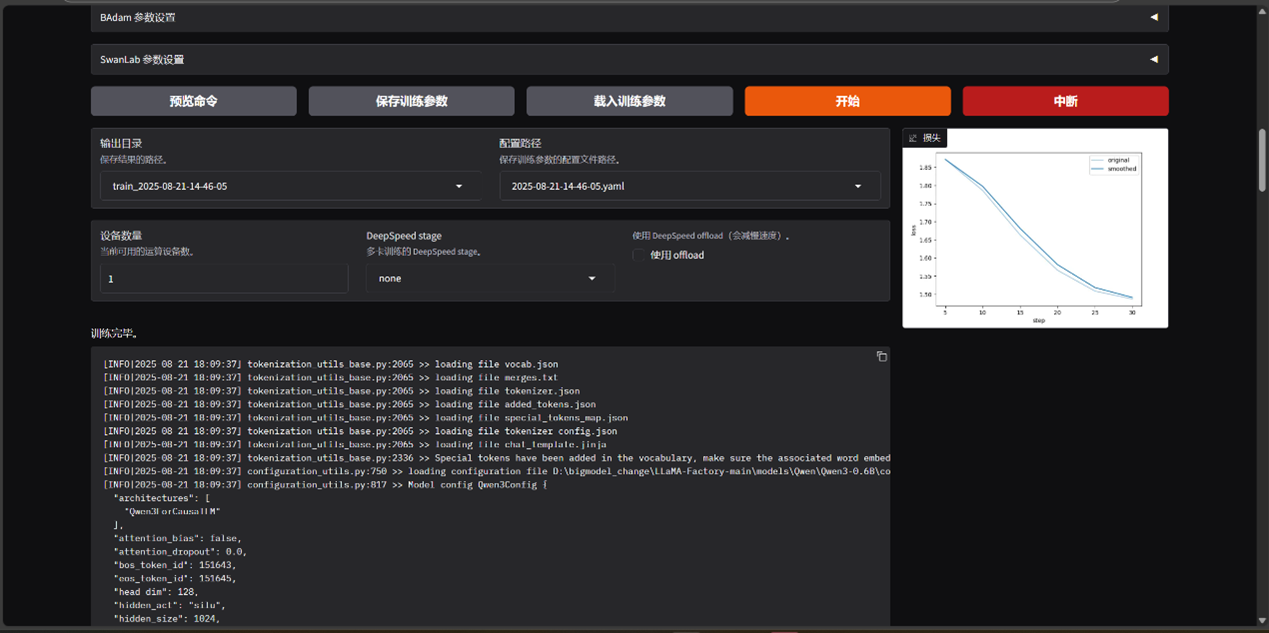
4.3 启动训练与监控
配置好之后运行即可!
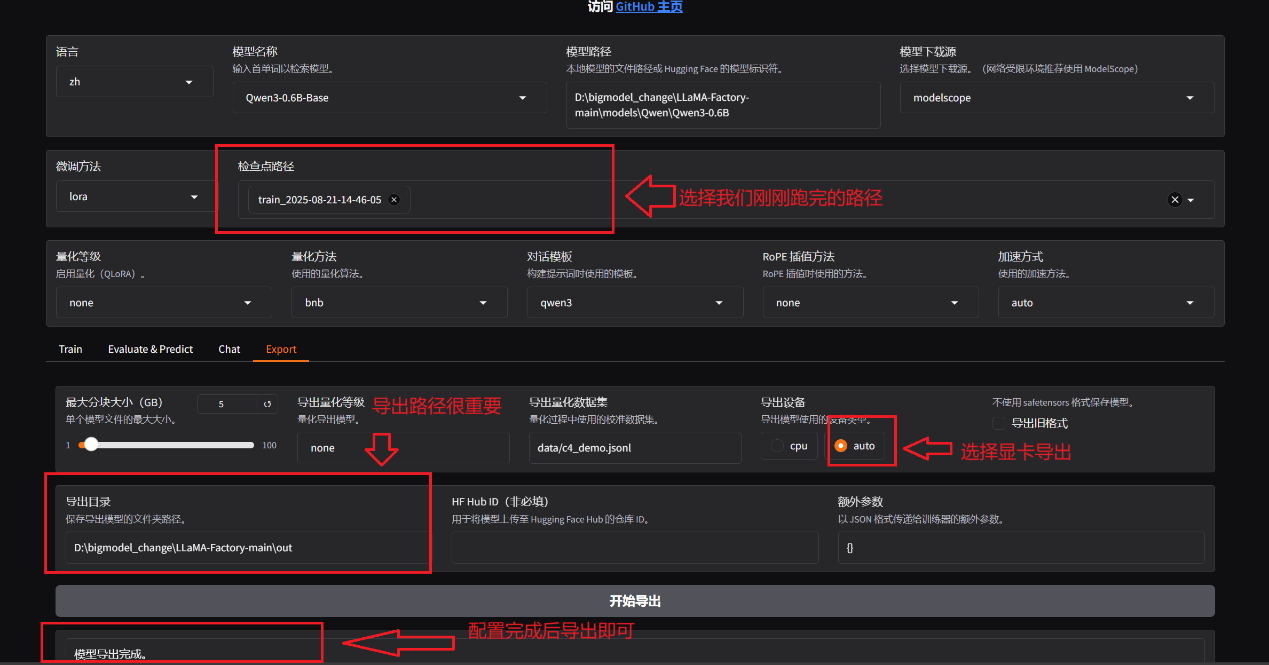
4.4 导出模型
跑完之后在LLaMA-Factory-main目录下
创建一个out文件夹以导出
五、模型推理:医疗场景下的精准问答验证
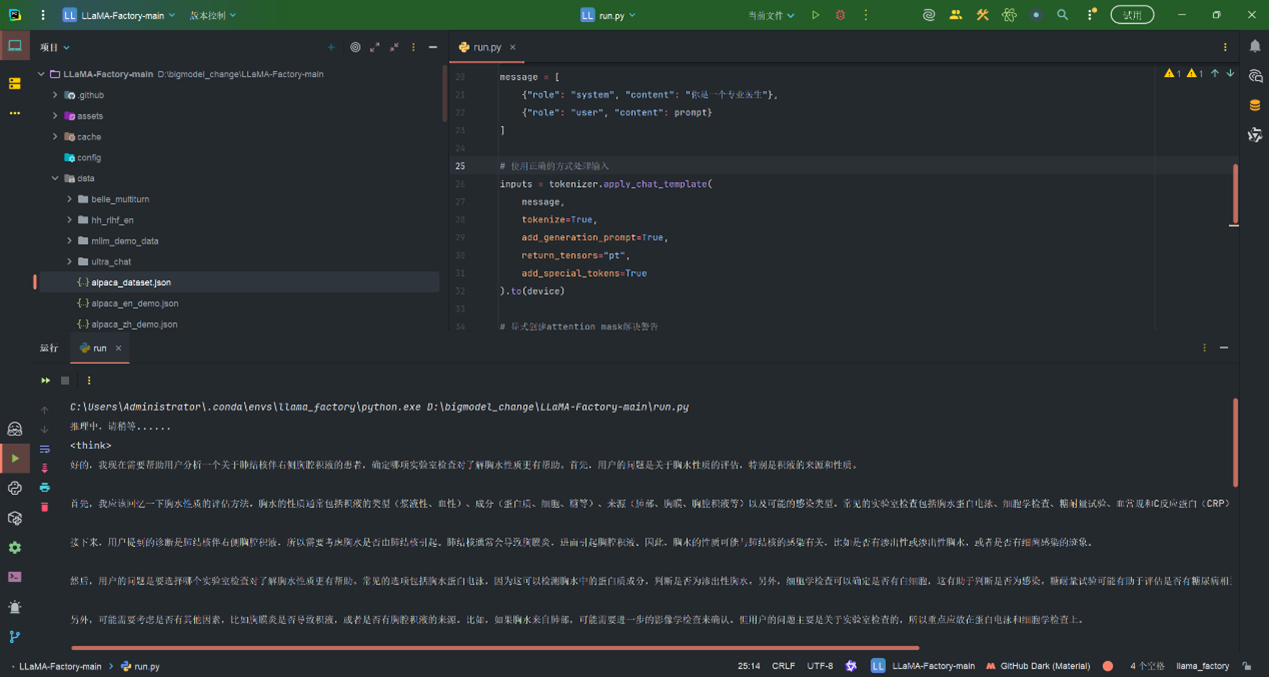
5.1 推理代码(含关键注释)
import torch
from transformers import AutoModelForCausalLM, AutoTokenizermodels_path = "out"#导出的路径# 模型加载
model = AutoModelForCausalLM.from_pretrained(models_path, torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained(models_path)# 确保设置了pad_token
if tokenizer.pad_token is None:tokenizer.pad_token = tokenizer.eos_tokendevice = "cuda" if torch.cuda.is_available() else "cpu"
model = model.to(device)print("推理中,请稍等......")
# 数据输入
prompt = "对于一名60岁男性患者,出现右侧胸疼并在X线检查中显示右侧肋膈角消失,诊断为肺结核伴右侧胸腔积液,请问哪一项实验室检查对了解胸水的性质更有帮助?"
message = [{"role": "system", "content": "你是一个专业医生"},{"role": "user", "content": prompt}
]# 使用正确的方式处理输入
inputs = tokenizer.apply_chat_template(message,tokenize=True,add_generation_prompt=True,return_tensors="pt",add_special_tokens=True
).to(device)# 显式创建attention mask解决警告
attention_mask = (inputs != tokenizer.pad_token_id).long().to(device)# 推理参数
gen_kwargs = dict(do_sample=True,top_k=10,top_p=0.8,temperature=0.6,max_length=1000,attention_mask=attention_mask # 添加attention_mask参数
)with torch.no_grad():outputs = model.generate(inputs, **gen_kwargs)# 解码输出
input_length = inputs.shape[1]
new_length = outputs[0][input_length:]
response = tokenizer.decode(new_length, skip_special_tokens=True)
print(response)
5.2 推理结果示例