【架构师干货】数据库管理系统
1. 数据库系统
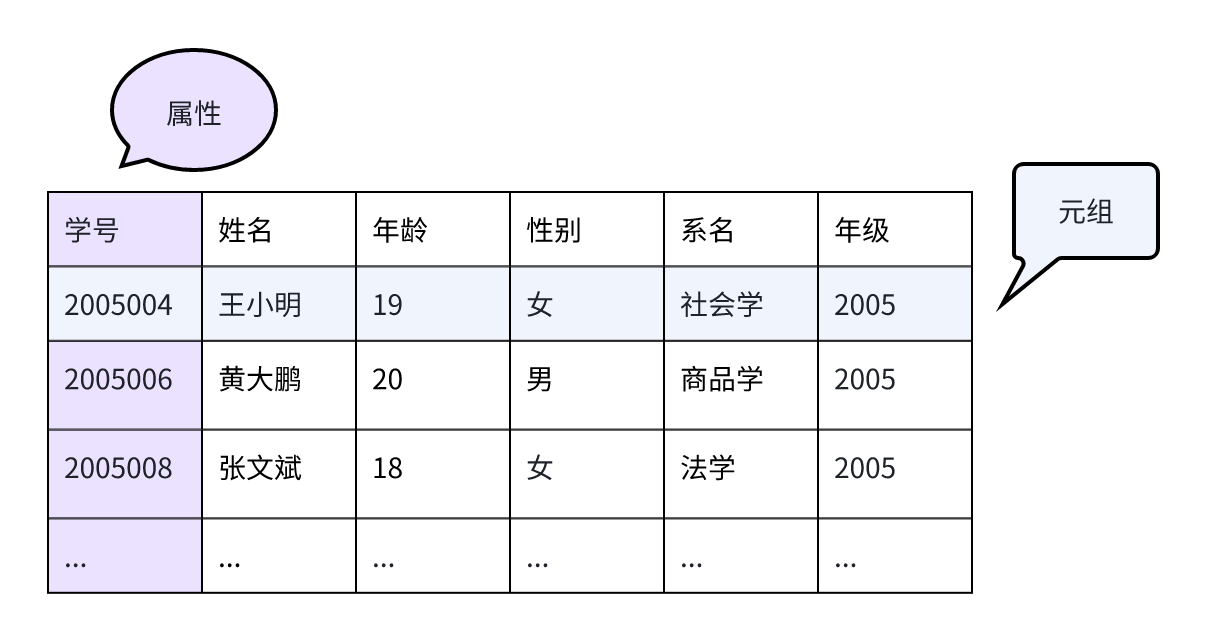
- 数据:是数据库中存储的基本对象,是描述事物的符号记录。数据的种类:文本、图形、图像、音频、视频、学生的档案记录、货物的运输情况等。
- 数据库DB:是长期存储在计算机内、有组织的、可共享的大量数据的集合。
- 数据库的基本特征:
- 数据按一定的数据模型组织、描述和存储;可为各种用户共享;
- 冗余度较小;
- 数据独立性较高;
- 易扩展。
- 数据库系统DBS:是一个采用了数据库技术,有组织地、动态地存储大量相关数据,方便多用户访问的计算机系统。其由下面四个部分组成:
- 数据库(统一管理、长期存储在计算机内的,有组织的相关数据的集合)
- 硬件(构成计算机系统包括存储数据所需的外部设备)
- 软件(操作系统、数据库管理系统及应用程序)
- 人员(系统分析和数据库设计人员、应用程序员、最终用户、数据库管理员DBA)
- 数据库管理系统DBMS的功能
- 实现对共享数据有效的组织、管理和存取。
- 包括数据定义、数据库操作、数据库运行管理、数据的存储管理、数据库的建立和维护等。
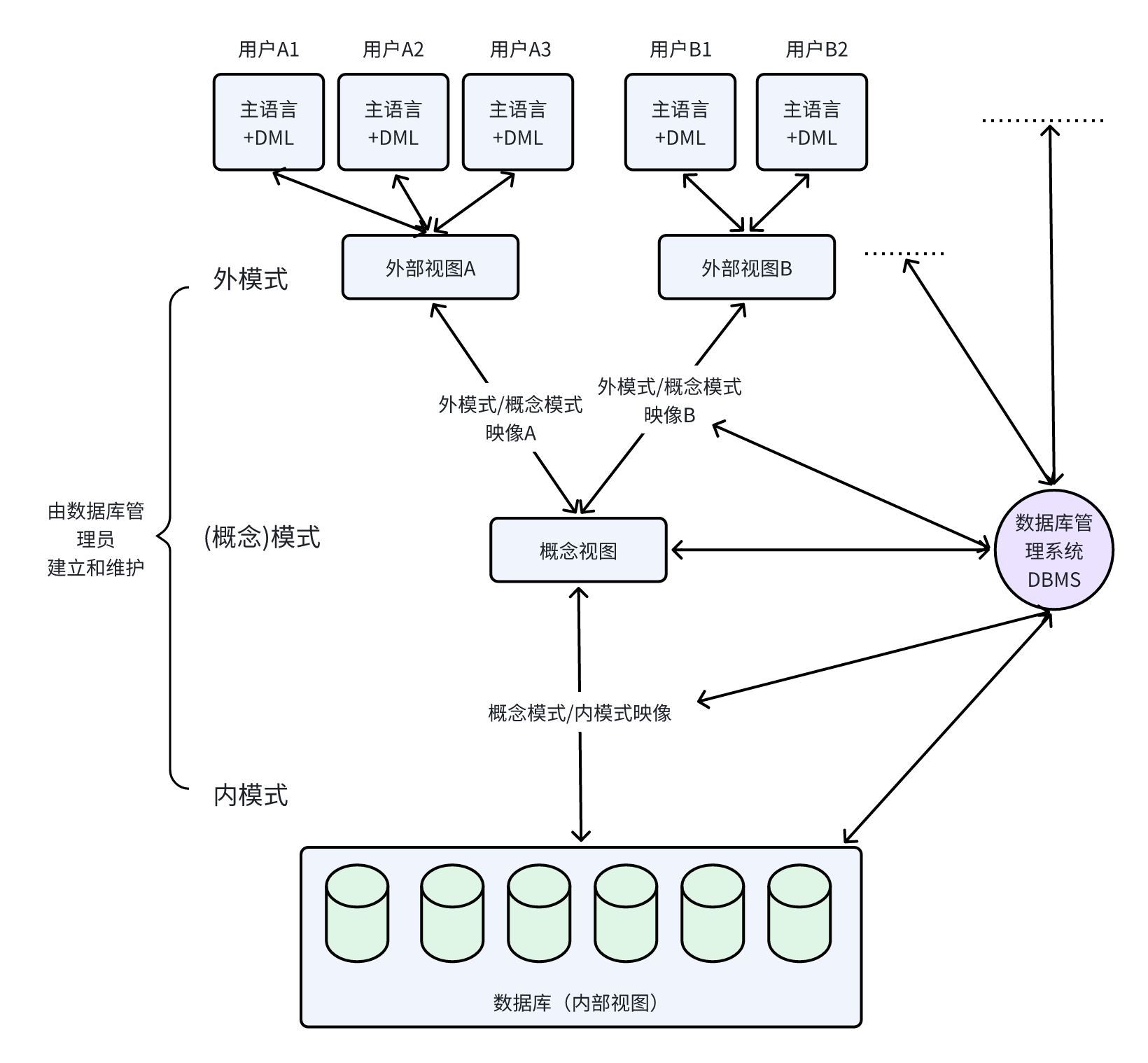
2. 三级模式-两级映像
- 内模式:管理如何存储物理的数据,对应具体物理存储文件。
- 模式:又称为概念模式,就是我们通常使用的基本表,根据应用、需求将物理数据划分成一张张表。
- 外模式:对应数据库中的视图这个级别,将表进行一定的处理后再提供给用户使用
- 外模式一模式映像:是表和视图之间的映射,存在于概念级和外部级之间,若表中数据发生了修改,只需要修改此映射,而无需修改应用程序。
- 模式一内模式映像:是表和数据的物理存储之间的映射,存在于概念级和内部级之间,若修改了数据存储方式,只需要修改此映射,而不需要去修改应用程序。
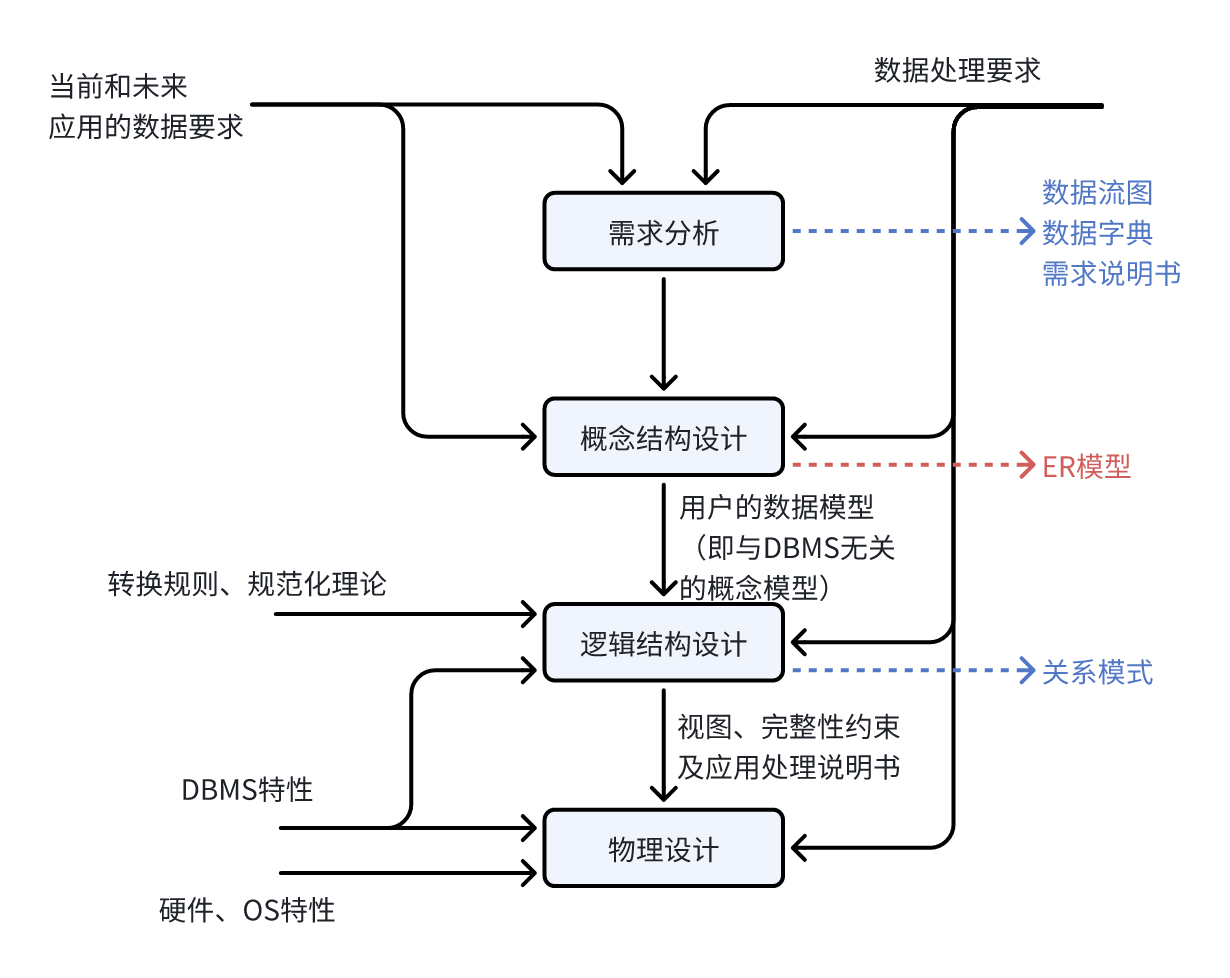
3. 数据库设计
- 需求分析:即分析数据存储的要求,产出物有数据流图、数据字典、需求说明书。获得用户对系统的三个要求:信息要求、处理要求、系统要求。
- 概念结构设计:就是设计E-R图,也即实体-联系图。工作步骤包括:选择局部应用、逐一设计分E-R图、E-R图合并。分E-R 图进行合并时,它们之间存在的冲突主要有以下3类:
- 属性冲突。同一属性可能会存在于不同的分E-R 图中。
- 命名冲突。相同意义的属性,在不同的分E-R 图上有着不同的命名.或是名称相同的属性在不同的分E-R 图中代表着不同的意义。
- 结构冲突。同一实体在不同的分E-R图中有不同的属性,同一对象在某一分E-R 图中被抽象为实体而在另一分E-R 图中又被抽象为属性。
- 逻辑结构设计:将E-R图,转换成关系模式。工作步骤包括:确定数据模型、将E-R 图转换成为指定的数据模型、确定完整性约束和确定用户视图。
- 物理设计:步骤包括确定数据分布、存储结构和访问方式,
- 数据库实施阶段。根据逻辑设计和物理设计阶段的结果建立数据库,编制与调试应用程序,组织数据入库,并进行试运行。
- 数据库运行和维护阶段。数据库应用系统经过试运行即可投入运行,但该阶段需要不断地对系统进行评价、调整与修改。
4. 数据模型
- 关系模型是二维表的形式表示的实体-联系模型,是将实体-联系模型转换而来的,经过开发人员设计的;
- 概念模型是从用户的角度进行建模的,是现实世界到信息世界的第一抽象是真正的实体-联系模型。
- 网状模型表示实体类型及其实体之间的联系,一个事物和另外几个都有联系,形成一张网。
- 面向对象模型是采用面向对象的方法设计数据库,以对象为单位,每个对象包括属性和方法,具有类和继承等特点。
- 数据模型三要素:数据结构(所研究的对象类型的集合)、数据操作(对数据库中各种对象的实例允许执行的操作的集合)、数据的约束条件(一组完整性规则的集合)。
- 用E-R图来描述概念数据模型,世界是由一组称作实体的基本对象和这些对象之间的联系构成的。
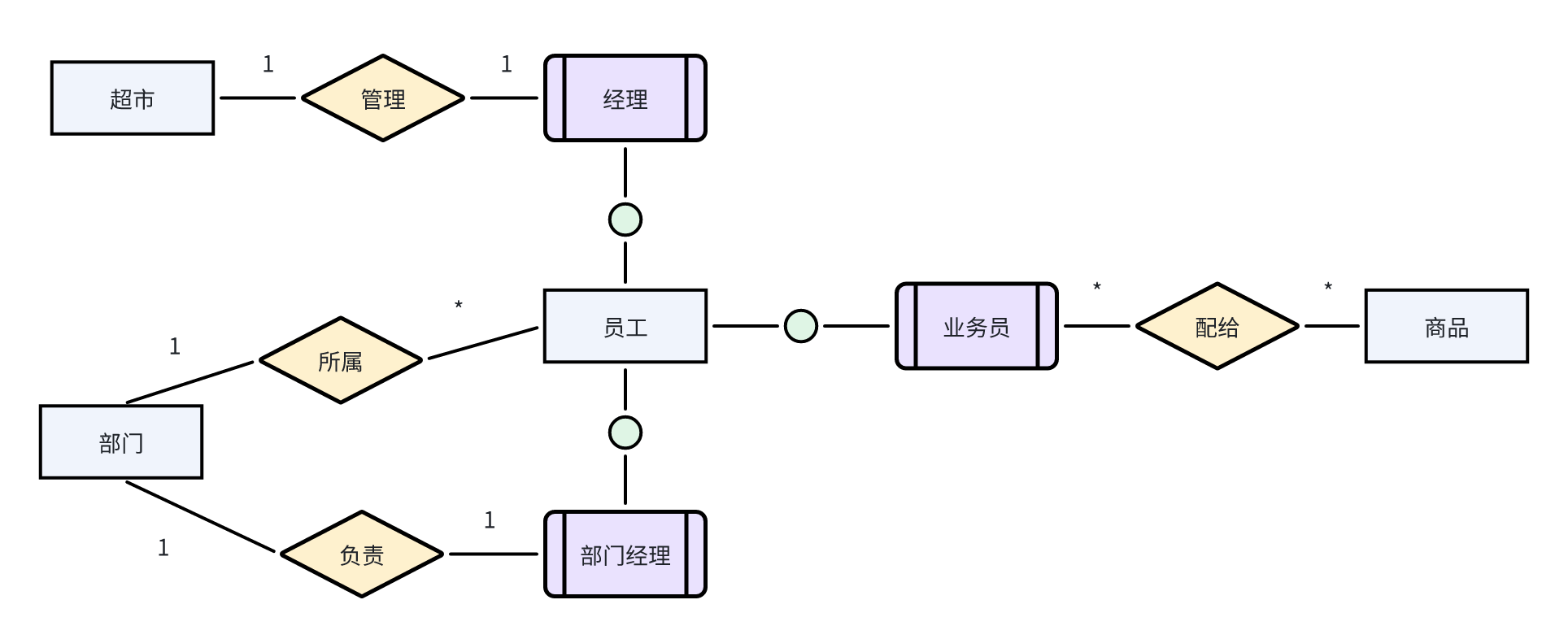
- 在E-R模型中,使用椭圆表示属性(一般没有)、长方形表示实体、姜形表示联系,联系的两端要填写联系类型,示例如下图:
- 实体:客观存在并可相互区别的事物。可以是具体的人、事、物或抽象概念如人、汽车、图书、账户、贷款。
- 弱实体和强实体:弱实体依赖于强实体的存在而存在。
- 实体集:具有相同类型和共享相同属性的实体的集合,如学生、课程。
- 属性:实体所具有的特性。
- 属性分类:简单属性和复合属性;单值属性和多值属性;NULL属性;派生属性。
- 域:属性的取值范围称为该属性的域。
- 码(key):唯一标识实体的属性集。
- 联系:现实世界中事物内部以及事物之间的联系,在E-R图中反映为实体内部的联系和实体之间的联系。
- 联系类型:一对一1:1、一对多1:N、多对多M:N。
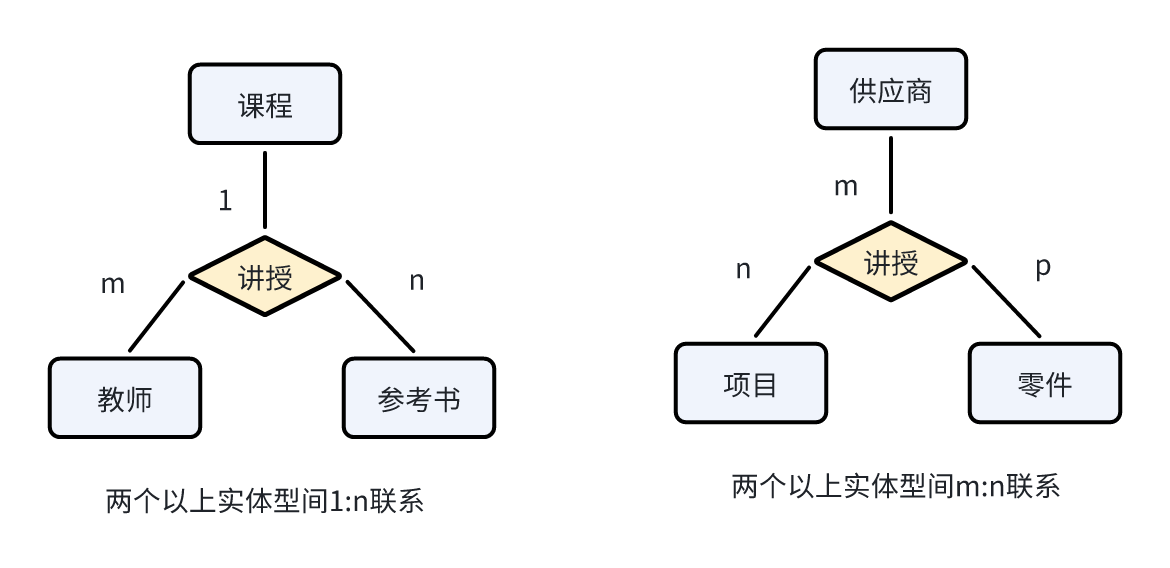
- 两个以上实体型的联系:
- 关系模型中数据的逻辑结构是一张二维表,由行列组成。用表格结构表达实体集,用外键标识实体间的联系。如下图:
- 优点:建立在严格的数学概念基础上;概念单一、结构简单、清晰,用户易懂易用;存取路径对用户透明,从而数据独立性、安全性好,简化数据库开发工作。
- 缺点:由于存取路径透明,查询效率往往不如非关系数据模型。
- E-R模型转换为关系模型:每个实体都对应一个关系模式;联系分为三种:
- 1:1联系中,联系可以放到任意的两端实体中,作为一个属性(要保证1:1的两端关联),也可以转换为一个单独的关系模式;
- 1:N的联系中,联系可以单独作为一个关系模式,也可以在N端中加入1端实体的主键;
- M:N的联系中,联系必须作为一个单独的关系模式,其主键是M和N端的联合主键。
5. 关系代数
- 并∪\cup∪:结果是两张表中所有记录数合并,相同记录只显示一次。
- 交∩\cap∩:结果是两张表中相同的记录。
- 差−-−:S1−S2S1-S2S1−S2,结果是S1表中有而S2表中没有的那些记录。
表1:关系S1S1S1
| Sno | Sname | Sdept |
|---|---|---|
| No0001 | Mary | IS |
| No0003 | Candy | IS |
| No0004 | Jam | IS |
表2:关系S2S2S2
| Sno | Sname | Sdept |
|---|---|---|
| No0001 | Mary | IS |
| No0008 | Katter | IS |
| No0021 | Tom | IS |
表3:S1∩S2S1 \cap S2S1∩S2(交)
| Sno | Sname | Sdept |
|---|---|---|
| No0001 | Mary | IS |
表4:S1∪S2S1 \cup S2S1∪S2(并)
| Sno | Sname | Sdept |
|---|---|---|
| No0001 | Mary | IS |
| No0003 | Candy | IS |
| No0004 | Jam | IS |
| No0008 | Katter | IS |
| No0021 | Tom | IS |
表5:S1−S2S1 - S2S1−S2(差)
| Sno | Sname | Sdept |
|---|---|---|
| No0003 | Candy | IS |
| No0004 | Jam | IS |
- 笛卡尔积:S1×S2S1\times S2S1×S2,产生的结果包括S1和S2的所有属性列,并且S1中每条记录依次和S2中所有记录组合成一条记录,最终属性列为S1+S2属性列,记录数为S1*S2记录数。
- 投影π\piπ:实际是按条件选择某关系模式中的某列,列也可以用数字表示。
- 选择σ\sigmaσ:实际是按条件选择某关系模式中的某条记录。
表6:S1×S2S1 \times S2S1×S2(笛卡尔积)
| Sno | Sname | Sdept | Sno | Sname | Sdept |
|---|---|---|---|---|---|
| No0001 | Mary | IS | No0001 | Mary | IS |
| No0001 | Mary | IS | No0008 | Katter | IS |
| No0001 | Mary | IS | No0021 | Tom | IS |
| No0003 | Candy | IS | No0001 | Mary | IS |
| No0003 | Candy | IS | No0008 | Katter | IS |
| No0003 | Candy | IS | No0021 | Tom | IS |
| No0004 | Jam | IS | No0001 | Mary | IS |
| No0004 | Jam | IS | No0008 | Katter | IS |
| No0004 | Jam | IS | No0021 | Tom | IS |
表7:π\piπ(投影)
| Sno | Sname |
|---|---|
| No0001 | Mary |
| No0003 | Candy |
| No0004 | Jam |
表8:σ\sigmaσ(选择)
| Sno | Sname | Sdept |
|---|---|---|
| No0003 | Candy | IS |
- 自然连接的结果显示全部的属性列,但是相同属性列只显示一次,显示两个关系模式中属性相同且值相同的记录。
设有关系RRR、SSS如下左图所示,自然连接结果如下右图所示:
表 (a) 关系 RRR
| A | B | C |
|---|---|---|
| a | b | c |
| b | a | d |
| c | d | e |
| d | f | g |
表(b) 关系SSS
| A | C | D |
|---|---|---|
| a | c | d |
| d | f | g |
| b | d | g |
表(c) R⋈SR \Join SR⋈S
| A | B | C | D |
|---|---|---|---|
| a | b | c | d |
| b | a | d | g |
6. 函数依赖
- 给定一个X,能唯一确定一个Y,就成X确定Y,或者说Y依赖于X,例如Y=X*X函数。
- 函数依赖有可扩展以下两种规则:
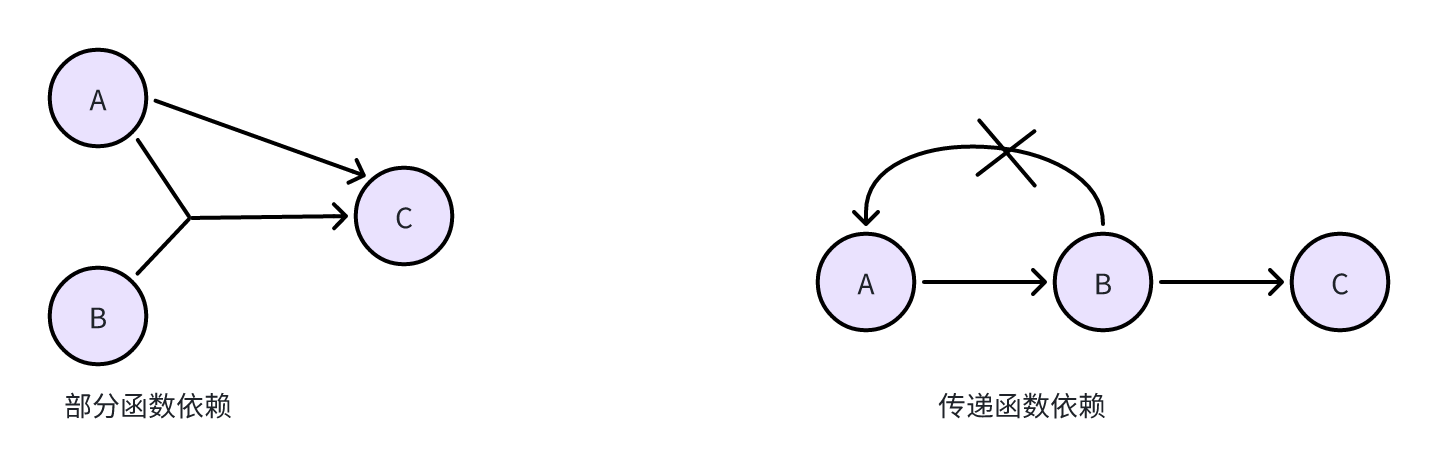
- 部分函数依赖:A可确定C,(A,B)也可以确定C,(A,B)中的一部分(即A)可以确定C,称为部分函数依赖。
- 传递函数依赖:当A和B不等价时,A可确定B,B可确定C,则A可确定C,是传递函数依赖;若A和B等价,则不存在传递,直接就可确定C。
函数依赖的公理系统(Armstrong)
- 设关系模式R<U,F>R<U,F>R<U,F>,UUU是关系模式RRR的属性全集,FFF是关系模式RRR的一个函数依赖集。对于R<U,F>R<U,F>R<U,F>来说有以下定律:
- 自反律:若Y⊆X⊆UY \subseteq X \subseteq UY⊆X⊆U,则X→YX \rightarrow YX→Y为FFF所逻辑蕴含
- 增广律:若X→YX \rightarrow YX→Y为FFF所逻辑蕴含,且Z⊆UZ \subseteq UZ⊆U,则XZ→YZXZ \rightarrow YZXZ→YZ为FFF所逻辑蕴含
- 传递律:若X→YX \rightarrow YX→Y和Y→ZY \rightarrow ZY→Z为FFF所逻辑蕴含,则X→ZX \rightarrow ZX→Z为FFF所逻辑蕴含
- 合并规则:若X→YX \rightarrow YX→Y,X→ZX \rightarrow ZX→Z,则X→YZX \rightarrow YZX→YZ为FFF所逻辑蕴含
- 伪传递律:若X→YX \rightarrow YX→Y,WY→ZWY \rightarrow ZWY→Z,则XW→ZXW \rightarrow ZXW→Z为FFF所逻辑蕴含
- 分解规则:若X→YX \rightarrow YX→Y,Z⊆YZ \subseteq YZ⊆Y,则X→ZX \rightarrow ZX→Z为FFF所逻辑蕴含
7. 键与约束
- 超键:能唯一标识此表的属性的组合。
- 候选键:超键中去掉冗余的属性,剩余的属性就是候选键
- 主键:任选一个候选键,即可作为主键。
- 外键:其他表中的主键。
- 主属性:候选键内的属性为主属性,其他属性为非主属性
- 实体完整性约束:即主键约束,主键值不能为空,也不能重复。
- 参照完整性约束:即外键约束,外键必须是其他表中已经存在的主键的值或者为空。
- 用户自定义完整性约束:自定义表达式约束,如设定年龄属性的值必须在0到150之间。
8. 范式
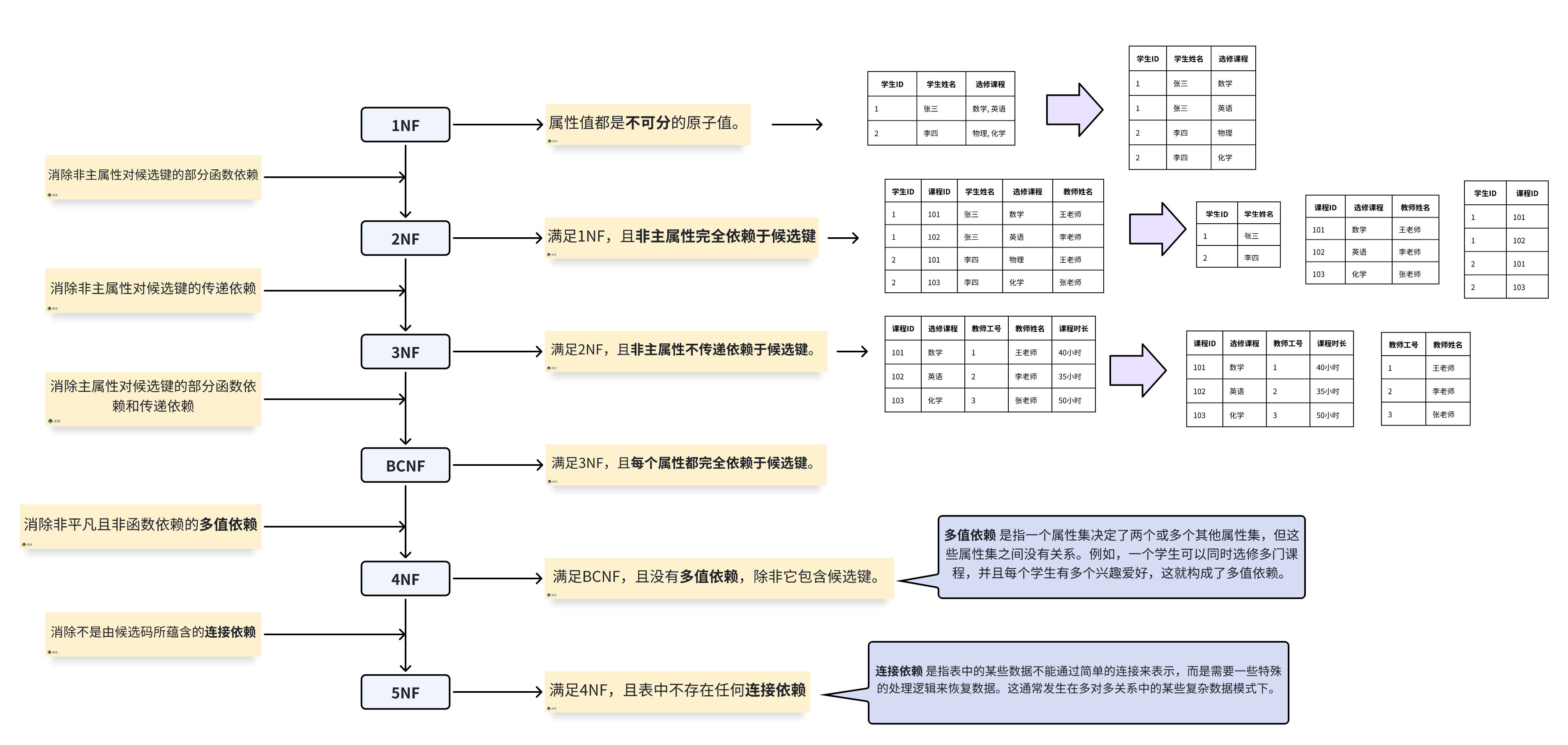
第一范式(1NF)要求属性原子性
第二范式(2NF)要求非主属性完全依赖候选键
第三范式(3NF)要求消除传递依赖
巴斯-科德范式(BCNF)要求每个非平凡函数依赖都是超键
第四范式(4NF)要求消除多值依赖
详见👉 【数据库干货】六大范式速记
9. 模式分解
范式之间的转换一般都是通过拆分属性,即模式分解,将具有部分函数依赖和传递依赖的属性分离出来,来达到一步步优化,一般分为以下两种:
-
保持函数依赖分解
对于关系模式R,有依赖集F,若对R进行分解,分解出来的多个关系模式,保持原来的依赖集不变,则为保持函数依赖的分解。另外,注意要消除掉冗余依赖(如传递依赖)- 实例:设原关系模式R(A,B,C),依赖集F(A->B,B->C,A->C),将其分解为两个关系模式R1(A,B)和R2(B,C),此时R1中保持依赖A->B,R2保持依赖B->C,说明分解后的R1和R2是保持函数依赖的分解,因为A->C这个函数依赖实际是一个冗余依赖,可以由前两个依赖传递得到,因此不需要管。
- 保持函数依赖的判断
- 如果F上的每一个函数依赖都在其分解后的某一个关系上成立,则这个分解是保持依赖的(这是一个充分条件)。也即我们课堂上说的简单方法,看每个函数依赖的左右两边属性是否都在同一个分解的模式中。
- 如果上述判断失败,并不能断言分解不是保持依赖的,还要使用下面的通用方法来做进一步判断。该方法的表述如下:
算法二:
对F上的每一个a→β使用下面的过程:
result:=α\alphaα;
while(result 发生变化) do
for each 分解后的 Ri
t = (result ∩\cap∩ Ri) + ∩\cap∩Ri
result = result∪\cup∪t
-
无损分解
分解后的关系模式能够还原出原关系模式,就是无损分解,不能还原就是有损。-
当分解为两个关系模式,可以通过以下定理判断是否无损分解:定理:如果R的分解为p={R1,R2},F为R所满足的函数依赖集合,分解p具有无损连接性的充分必要条件是R1∩\cap∩R2->(R1-R2)或者R1∩\cap∩R2->(R2-R1)。
-
当分解为三个及以上关系模式时,可以通过表格法求解,如下:
💡【思考题】
有关系模式:成绩(学号,姓名,课程号,课程名,分数)
函数依赖:学号→姓名,课程号→课程名,(学号,课程号)→分数若将其分解为:
成绩(学号,课程号,分数)
学生(学号,姓名)
课程(课程号,课程名)请思考该分解是否为无损分解 ?
由于有:学号→姓名,所以:
成绩(学号,课程号,分数,姓名)
由于有:课程号→课程名,所以:
成绩(学号,课程号,分数,姓名,课程名)初始表如下:
学号 姓名 课程号 课程名 分数 成绩 √ × √ × √ 学生 √ √ × × × 可成 × × √ √ × 根据学号→姓名,对上表进行处理,将×改成符号√;然后考虑课程号→课程名,将×改为√,得下表:
学号 姓名 课程号 课程名 分数 成绩 √ √ √ √ √ 学生 √ √ × × × 可成 × × √ √ × 从上图中可以看出,第1行已全部为√,因此本次R分解是无损联接分解。
-
10. 并发控制
- 丢失更新:事务1对数据A进行了修改并写回,事务2也对A进行了修改并写回此时事务2写回的数据会覆盖事务1写回的数据,就丢失了事务1对A的更新。即对数据A的更新会被覆盖。
- 不可重复读:事务2读A,而后事务1对数据A进行了修改并写回,此时若事务2再读A,发现数据不对。即一个事务重复读A两次,会发现数据A有误。
- 读脏数据:事务1对数据A进行了修改后,事务2读数据A,而后事务1回滚,数据A恢复了原来的值,那么事务2对数据A做的事是无效的,读到了脏数据。
丢失更新
| T1 | T2 | |
|---|---|---|
| ① | 读A=10 | |
| ② | 读A=10 | |
| ③ | A=A-5写回 | |
| ④ | A=A-8写回 |
不可重复读
| T1 | T2 | |
|---|---|---|
| ① | 读A=20 | |
| 读B=30 | ||
| 求和=50 | ||
| ② | 读A=20 | |
| A←A+50 | ||
| 写A=70 | ||
| ③ | 读A=70 | |
| 读B=30 | ||
| 求和=100(验算不对) |
读“脏”数据
| T1 | T2 | |
|---|---|---|
| ① | 读A=20 | |
| A←A+50 | ||
| 写回70 | ||
| ② | 读A=70 | |
| ③ | ROLLBACK A恢复为20 |
11. 封锁协议
- X锁是排它锁(写锁)。若事务T对数据对象A加上X锁,则只允许T读取和修改A,其他事务都不能再对A加任何类型的锁,直到T释放A上的锁。
- S锁是共享锁(读锁)。若事务T对数据对象A加上S锁,则只允许T读取A,但不能修改A,其他事务只能再对A加S锁(也即能读不能修改),直到T释放A上的S锁。
共分为三级封锁协议,如下:
-
一级封锁协议:事务在修改数据R之前必须先对其加X锁,直到事务结束才释放。可解决丢失更新问题。
T1 T2 ① 对A加写锁 ② 对A加写锁 ③ 读A=10 等待 ④ A=A-5写回 等待 ⑤ 释放对A的写锁 等待 ⑥ 读A=5 ⑦ A=A-8写回 ⑧ 释放对A的写锁 -
二级封锁协议:一级封锁协议的基础上加上事务T在读数据R之前必须先对其加S锁,读完后即可释放S锁。可解决丢失更新、读脏数据问题。
T1 T2 ① 对A加写锁 ② 读A=20 ③ A←A+50 ④ 写回70 对A加写锁 ⑤ 等待 ⑥ ROLLBACK 等待 ⑦ A恢复为20 读A=20 ⑧ 释放对A的读锁 -
三级封锁协议:一级封锁协议加上事务T在读取数据R之前先对其加S锁,直到
事务结束才释放。可解决丢失更新、读脏数据、数据重复读问题。T1 T2 ① 对A与B加S锁(读锁) 读A=20 读A=30 求和=50 ② 对A加X锁(写锁) 注:由于A已加了读锁,所以等待 ③ 读A=20 等待 读B=30 等待 求和=50 等待 释放对A和B的读锁 读A=20 A←A+50 写A=70 释放对A的写锁
12. 数据库安全
| 措施 | 说明 |
|---|---|
| 用户标识和鉴定 | 最外层的安全保护措施,可以使用用户帐户、口令及随机数检验等方式 |
| 存取控制 | 对用户进行授权,包括操作类型(如查找、插入、删除、修改等动作)和数据对象(主要是数据范围)的权限。 |
| 密码存储和传输 | 对远程终端信息用密码传输 |
| 视图的保护 | 对视图进行授权 |
| 审计 | 使用一个专用文件或数据库,自动将用户对数据库的所有操作记录下来 |
| 故障关系 | 故障原因 | 解决方法 |
|---|---|---|
| 事务本身的可预期故障 | 本身逻辑 | 在程序中预先设置Rollback语句 |
| 事务本身的不可预期故障 | 算术溢出、违反存储保护 | 由DBMS的恢复子系统通过日志,撤消事务对数据库的修改,回退到事务初始状态 |
| 系统故障 | 系统停止运转 | 通常使用检查点法 |
| 介质故障 | 外存被破坏 | 一般使用日志重做业务 |
- 静态转储:即冷备份,指在转储期间不允许对数据库进行任何存取、修改操作;优点是非常快速的备份方法、容易归档(直接物理复制操作)缺点是只能提供到某一时间点上的恢复,不能做其他工作,不能按表或按用户恢复。
- 动态转储:即热备份,在转储期间允许对数据库进行存取、修改操作,因此,转储和用户事务可并发执行;优点是可在表空间或数据库文件级备份,数据库扔可使用,可达到秒级恢复缺点是不能出错,否则后果严重,若热备份不成功,所得结果几乎全部无效。
- 完全备份:备份所有数据。
- 差量备份:仅备份上一次完全备份之后变化的数据,
- 增量备份:备份上一次备份之后变化的数据。
- 日志文件:在事务处理过程中,DBMS把事务开始、事务结束以及对数据库的插入、删除和修改的每一次操作写入日志文件。一旦发生故障,DBMS的恢复子系统利用日志文件撤销事务对数据库的改变,回退到事务的初始状态。
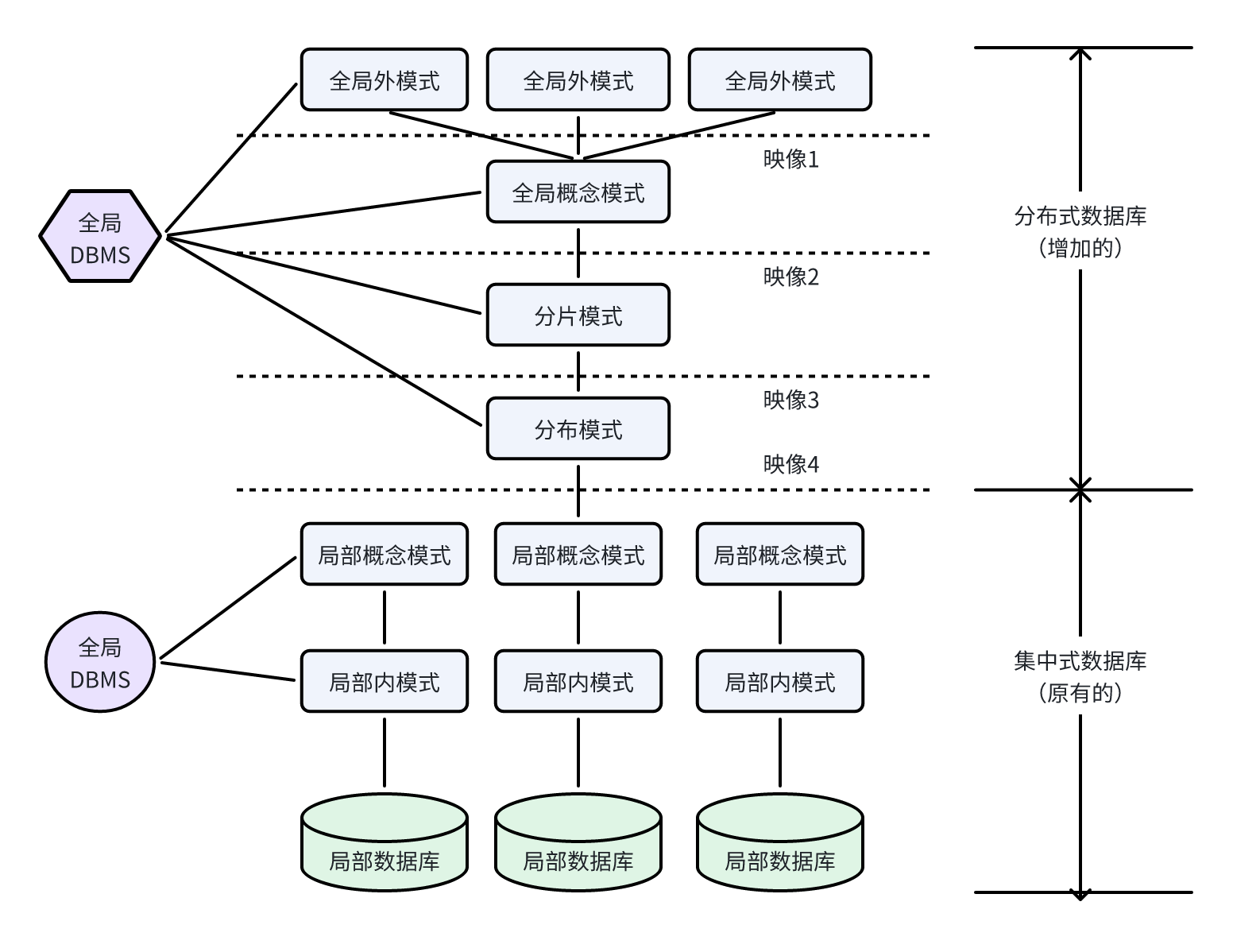
13. 分布式数据库
- 局部数据库位于不同的物理位置,使用一个全局DBMS将所有局部数据库联网管理,这就是分布式数据库。
- 分片模式
- 水平分片:将表中水平的记录分别存放在不同的地方。
- 垂直分片:将表中的垂直的列值分别存放在不同的地方。
- 分布透明性
- 分片透明性:用户或应用程序不需要知道逻辑上访问的表具体是如何分块存储的。
- 位置透明性:应用程序不关心数据存储物理位置的改变。
- 逻辑透明性:用户或应用程序无需知道局部使用的是哪种数据模型。
- 复制透明性:用户或应用程序不关心复制的数据从何而来。
14. 数据仓库技术
数据仓库是一个面向主题的、集成的、非易失的、且随时间变化的数据集合,用于支持管理决策。
- 面向主题:按照一定的主题域进行组织的。集成的:数据仓库中的数据是在对原有分散的数据库数据抽取、清理的基础上经过系统加工、汇总和整理得到的,必须消除源数据中的不一致性,以保证数据仓库内的信息是关于整个企业的-致的全局信息
- 相对稳定的:数据仓库的数据主要供企业决策分析之用,所涉及的数据操作主要是数据查询,一旦某个数据进入数据仓库以后,一般情况下将被长期保留,也就是数据仓库中一般有大量的查询操作,但修改和删除操作很少,通常只需要定期的加载、刷新。
- 反映历史变化:数据仓库中的数据通常包含历史信息,系统记录了企业从过去某一时点(如开始应用数据仓库的时点)到目前的各个阶段的信息,通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。
数据仓库的结构通常包含四个层次,如下图所示:
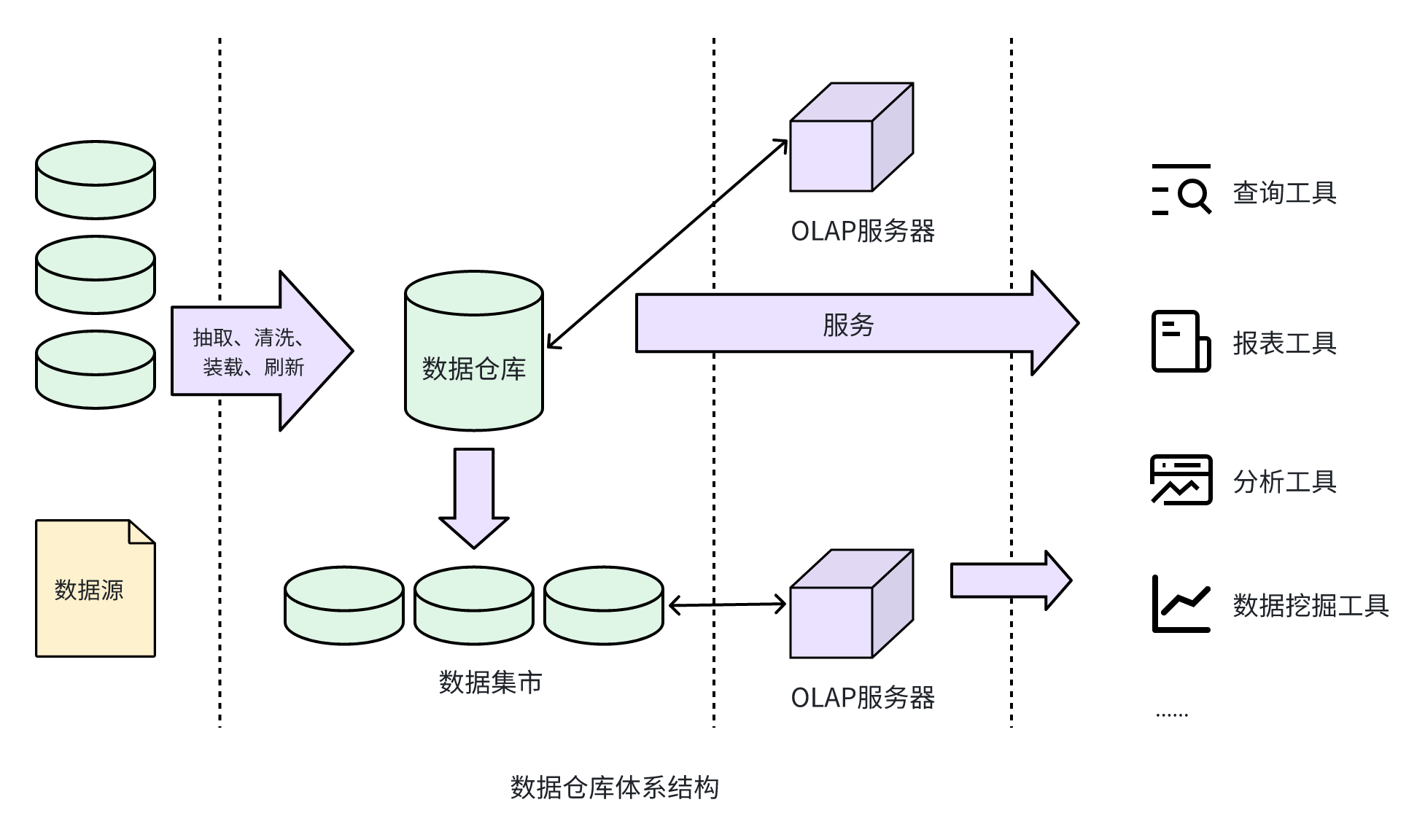
- 数据源:是数据仓库系统的基础,是整个系统的数据源泉。
- 数据的存储与管理:是整个数据仓库系统的核心。
- OLAP(联机分析处理)服务器:对分析需要的数据进行有效集成,按多维模型组织,以便进行多角度、多层次的分析,并发现趋势。
- 前端工具:主要包括各种报表工具、查询工具、数据分析工具、数据挖掘工具以及各种基于数据仓库或数据集市的应用开发工具。
商业智能(BI)系统主要包括数据预处理、建立数据仓库、数据分析和数据展现四个主要阶段。
- 数据预处理是整合企业原始数据的第一步,它包括数据的抽取(Extraction)、转换(Transformation)和加载(Load)三个过程(ETL过程);
- 建立数据仓库则是处理海量数据的基础;
- 数据分析是体现系统智能的关键,一般采用联机分析处理(0LAP)和数据挖掘两大技术。联机分析处理不仅进行数据汇总/聚集,同时还提供切片、切块下钻、上卷和旋转等数据分析功能,用户可以方便地对海量数据进行多维分析。数据挖掘的目标则是挖掘数据背后隐藏的知识,通过关联分析、聚类和分类等方法建立分析模型,预测企业未来发展趋势和将要面临的问题;
- 在海量数据和分析手段增多的情况下,数据展现则主要保障系统分析结果的可视化。
15. 反规范化技术
反规范化技术:规范化设计后,数据库设计者希望牺牲部分规范化来提高性能。
- 采用反规范化技术的益处:降低连接操作的需求、降低外码和索引的数目,还可能减少表的数目,能够提高查询效率。
- 可能带来的问题:数据的重复存储,浪费了磁盘空间;可能出现数据的完整性问题,为了保障数据 的一致性,增加了数据维护的复杂性,会降低修改速度。
具体方法:
- 增加冗余列:在多个表中保留相同的列,通过增加数据冗余减少或避免查询时的连接操作。
- 增加派生列:在表中增加可以由本表或其它表中数据计算生成的列,减少查询时的连接操作并避免计算或使用集合函数。
- 重新组表:如果许多用户需要查看两个表连接出来的结果数据,则把这两个表重新组成一个表来减少连接而提高性能。
- 水平分割表:根据一列或多列数据的值,把数据放到多个独立的表中,主要用于表数据规模很大、表中数据相对独立或数据需要存放到多个介质上时使用。
- 垂直分割表:对表进行分割,将主键与部分列放到一个表中,主键与其它列放到另一个表中,在查询时减少I/O次数。
16. 大数据
特点:大量化、多样化、价值密度低、快速化。
大数据和传统数据的比较如下:
| 比较维度 | 传统数据 | 大数据 |
|---|---|---|
| 数据量 | GB或TB级 | PB级或以上 |
| 数据分析需求 | 现有数据的分析与检测 | 深度分析(关联分析、回归分析) |
| 硬件平台 | 高端服务器 | 集群平台 |
要处理大数据,一般使用集成平台,称为大数据处理系统,其特征为:高度可扩展性、高性能、高度容错、支持异构环境、较短的分析延迟、易用且开放的接口、较低成本、向下兼容性。
17. SQL语言
这里只简单总结一下
SQL语言中的语法关键字,不区分大小写:
| 关键字 | 释义 |
|---|---|
| create table | 创建表 |
| primary key() | 指定主键 |
| foreign key() | 指定外键 |
| alter table | 修改表 |
| drop table | 删除表 |
| index | 索引 |
| view | 视图 |
CREATE TABLE S ( Sno CHAR(S) NOT NULL UNIQUE,Sname CHAR(30) UNIQUE,Status CHAR(8),City CHAR(20),PRIMARY KEY(Sno)
);
ALTER TABLE S ADD Zap CHAR(6);
DROP TABLE Student;
CREATE UNIQUE INDEX S-SNO ON S(Sno);
CREATE VIEW CS-STUDENT;
数据库查询select…from…where
分组查询group by,分组时要注意select后的列名要适应分组,having为分组查询附加条件:select sno,avg(score) from student group by sno having(avg(score)>60)
更名运算as:selectsno as“学号”from t1
字符串匹配like,%匹配多个字符串,匹配任意一个字符串: selectfrom t1where sname like 'a ’
数据库插入insert into…values():insert into t1 values(‘a’,66)
数据库删除delete from…where:delete t1 where sno=4
数据库修改update…set…where:update t1 set sname='aa’where sno=3
排序order by,默认为升序,降序要加关键字DESC:selectfrom t1 order by sno desc
SELECT[ALL|DISTINCT]<目标列表达式>[,<目标列表达式>]…FROM<表名或视图名>[,<表名或视图名>][WHERE<条件表达式>][GROUP BY<列名 1>[HAVING<条件表达式>]][ORDER BY<列名 2>[ASC|DESC]…]
DISTINCT:过滤重复的选项,只保留一条记录,
UNION:出现在两个SQL语句之间,将两个SQL语句的查询结果取或运算,即值存在于第一句或第二句都会被选出。
INTERSECT:对两个SQL语句的查询结果做与运算,即值同时存在于两个语句才被选出。
MIN、AVG、MAX:分组查询时的聚合函数