从CVPR到NeurIPS,可变形卷积+可变形空间注意力如何斩获最佳论文
来gongzhonghao【图灵学术计算机论文辅导】,快速拿捏更多计算机SCI/CCF发文资讯~
分享一个大模型时代极香的硬核方向:可变形卷积+可变形空间注意力机制。
众所周知,3D/视频感知任务里,固定网格卷积早已无法应对姿态、视角、尺度的剧烈变化,而Deformable思想用极少量新增参数即可让卷积核“漂移”到真正需要关注的像素或体素,瞬间把AMiner热度拉满——顶会顶刊中近三年相关论文激增40%。再加上多视角遮挡、跨模态对齐、时序冗余计算等痛点,可变形机制天然适配高效迁移、动态融合与持续适应。
本文精心整理了 3 篇前沿论文,旨在助力大家洞悉前沿动态、把握研究思路。满满干货,点赞收藏不迷路~
Video Super-Resolution Transformer with Masked Inter&Intra-Frame Attention
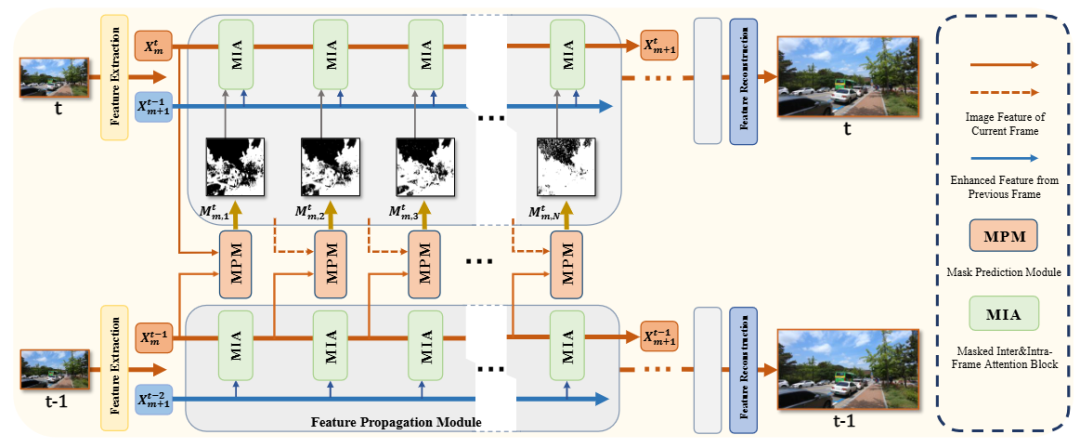
方法:先在双向二阶网格传播框架中用“帧内-帧间注意力块”把当前帧特征做Query、把前两帧已增强特征做Key/Value;再为每个处理阶段引入轻量级掩码预测网络,依据相邻帧特征差异自适应生成块级二值掩码,跳过冗余计算;最后用Charbonnier损失联合稀疏掩码损失端到端训练,推理阶段直接按掩码执行选择性计算,从而显著节省FLOPs与显存。
创新点:
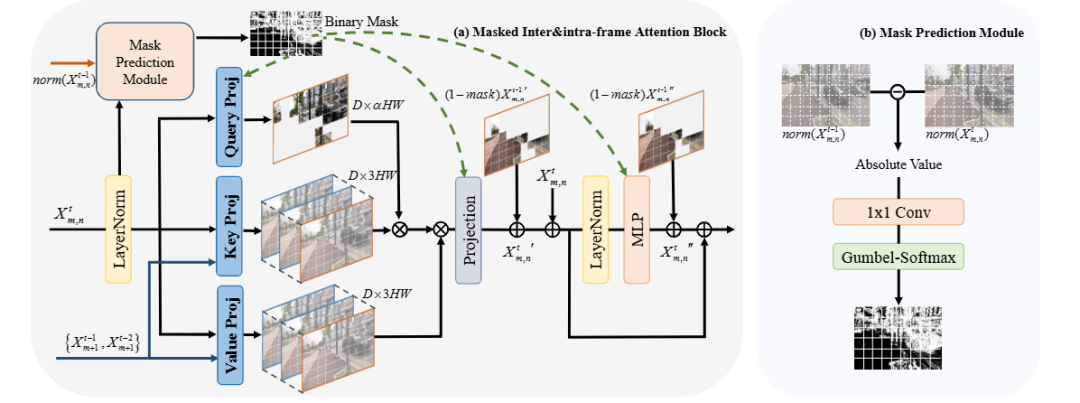
提出“帧内-帧间注意力块”,仅用当前帧生成Query、用已增强的历史帧生成Key/Value,避免联合自注意力的高开销并提升对齐效果。
设计特征级自适应掩码预测模块,根据相邻帧特征相似度为每个网络阶段生成块级掩码,实现精细的跳过策略。
构建掩码可学习的训练框架,通过Gumbel-Softmax采样与稀疏损失联合优化,使网络在训练时学会为不同层分配不同稀疏率。
总结:文章以BasicVSR++式的双向递归结构为基础,将每个特征传播模块中的Swin块替换为轻量的帧内-帧间注意力块,并用微型卷积网络根据相邻帧差异预测逐块掩码,在训练阶段联合超分损失与稀疏损失优化掩码,实现当前最高效的视频超分辨率Transformer。
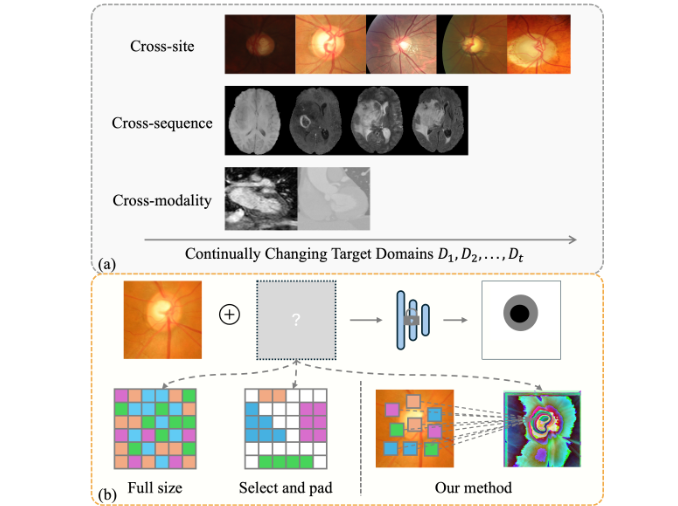
Efficient Deformable Convolutional Prompt for Continual Test-Time Adaptation in Medical Image Segmentation
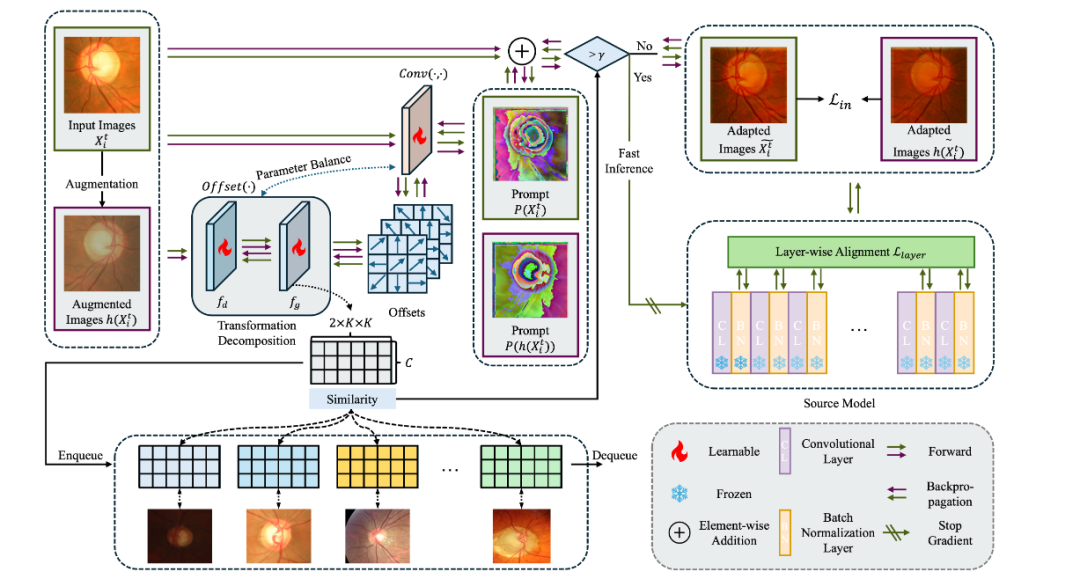
方法:把提示设计为轻量级可变形卷积:先用一个分解后的偏移分支预测像素级采样偏移,实现细粒度域对齐;再用输入级结构相似损失与逐层BN统计差异损失联合优化提示,无需解冻BN;最后建立偏移库作为隐式域指示器,当新样本与库内历史偏移高度相似时直接跳过训练,实现单样本快速推理。
创新点:
提出可变形卷积提示,仅用<200个参数就能在像素级补偿域偏移,远少于现有提示方法。
设计偏移变换分解与偏移库,平衡卷积与偏移分支参数量并缓存历史域信息,实现训练跳过加速。
构建输入级结构一致性+层间统计对齐的双重损失,无需更新BN即可完成源-目标分布对齐。
总结:EDCP在输入端叠加一个轻量可变形卷积提示,通过分解偏移预测、偏移库相似度判断及双重对齐损失,实现单样本即时连续适配,在2D/3D医学分割任务上以最少的可训练参数和训练时间取得当前最佳持续测试时适应性能。
纠结选题?导师放养?投稿被拒?对论文有任何问题的同学,欢迎来gongzhonghao【图灵学术计算机论文辅导】,获取顶会顶刊前沿资讯~
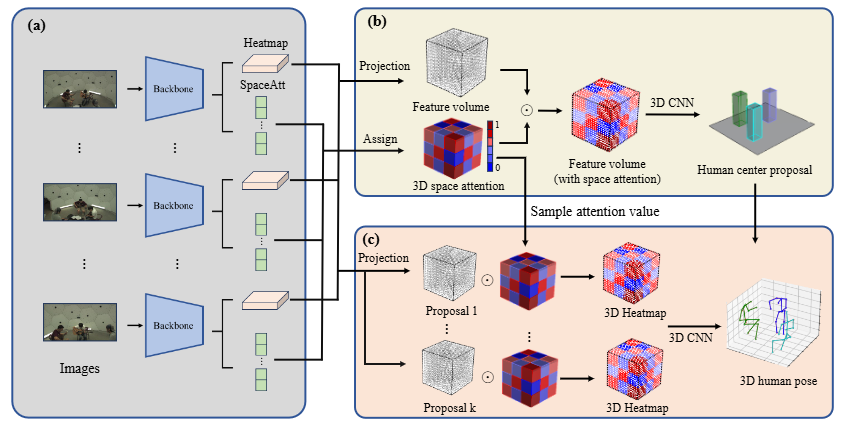
3DSA :Multi-View 3D Human Pose Estimation With 3D Space Attention Mechanisms
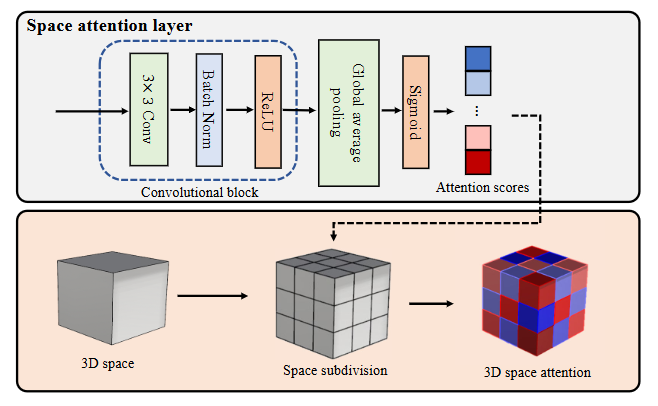
方法:先由轻量CNN从多视角图像预测热图与空间注意力分数;再利用3D空间细分算法把80×80×20体积分成若干区域,以区域为单位赋权;接着将加权后的体素特征融合并输入3D-CNN做人员提案检测;最后对每个提案采样对应注意力分数并回归精细3D姿态。
创新点:
提出3D空间注意力机制,用区域级加权显式建模不同视角对同一3D位置的可见性差异。
设计3D空间细分算法,把逐体素预测降为逐区域预测,显著降低计算量且保持性能。
模块即插即用,无需改动原有网络结构即可让VoxelPose与Faster VoxelPose在Panoptic数据集上达到SOTA。
总结:作者在现有体素化框架末端加入一个由CNN预测区域权重的3DSA分支,先将多视角热图投影为共享3D特征体,再用细分算法将其划分为若干块并赋予注意力系数,最后将加权后的特征送入3D-CNN完成多人检测与姿态回归,实验表明仅需增加不到1%参数即可在严苛AP25指标上提升10%以上,验证了视角感知注意力在3D位姿估计中的有效性。
关注gongzhonghao【图灵学术计算机论文辅导】,快速拿捏更多计算机SCI/CCF发文资讯~