零基础学习性能测试第九章:全链路追踪-系统中间件节点监控
目录
- 一、为什么需要监控中间件节点?
- 二、主流中间件监控方案
- 1. 监控体系架构
- 2. 监控工具矩阵
- 三、环境搭建实战
- 1. 部署Prometheus
- 2. 部署Grafana
- 四、中间件监控配置实战
- 1. Nginx监控
- 2. Redis监控
- 3. Kafka监控
- 4. MySQL监控
- 五、全链路追踪中的中间件监控
- 1. SkyWalking与Prometheus集成
- 2. 全链路视角的中间件监控
- 六、性能瓶颈定位实战
- 1. 瓶颈分析流程图
- 2. 典型瓶颈案例
- 七、Grafana监控大盘
- 1. 中间件核心监控面板
- 2. 面板配置示例(Redis)
- 八、告警配置实战
- 1. Prometheus告警规则
- 2. 告警集成方案
- 九、学习路径建议
- 十、避坑指南
- 总结
一、为什么需要监控中间件节点?
在全链路追踪中,中间件节点是性能瓶颈的高发区:
中间件性能问题的影响:
- Redis响应延迟 → 整个系统响应变慢
- Kafka消息积压 → 业务处理延迟
- MySQL连接池耗尽 → 服务不可用
- Nginx负载不均 → 部分节点过载
二、主流中间件监控方案
1. 监控体系架构
2. 监控工具矩阵
| 中间件 | 监控工具 | 关键指标 |
|---|---|---|
| Nginx | Prometheus+nginx_exporter | 请求率、错误率、响应时间、活跃连接 |
| Redis | Prometheus+redis_exporter | 内存使用、OPS、命中率、连接数 |
| Kafka | Prometheus+kafka_exporter | 消息积压、吞吐量、延迟、分区状态 |
| MySQL | Prometheus+mysqld_exporter | 查询性能、连接数、锁等待、缓冲池 |
| 应用 | SkyWalking | JVM、GC、线程池、SQL执行 |
三、环境搭建实战
1. 部署Prometheus
# 创建prometheus.yml
cat <<EOF > prometheus.yml
global:scrape_interval: 15sscrape_configs:- job_name: 'prometheus'static_configs:- targets: ['localhost:9090']
EOF# 启动Prometheus
docker run -d --name=prometheus \-p 9090:9090 \-v $(pwd)/prometheus.yml:/etc/prometheus/prometheus.yml \prom/prometheus
2. 部署Grafana
docker run -d --name=grafana \-p 3000:3000 \grafana/grafana
四、中间件监控配置实战
1. Nginx监控
# 安装nginx_exporter
docker run -d --name nginx-exporter \-p 9113:9113 \nginx/nginx-prometheus-exporter \-nginx.scrape-uri http://nginx-server/stub_status# Prometheus配置
scrape_configs:- job_name: 'nginx'static_configs:- targets: ['nginx-exporter:9113']
关键指标:
nginx_http_requests_total:总请求数nginx_http_request_duration_seconds:请求耗时nginx_connections_active:活跃连接数
2. Redis监控
# 安装redis_exporter
docker run -d --name redis-exporter \-p 9121:9121 \oliver006/redis_exporter \--redis.addr redis://redis-server:6379# Prometheus配置
scrape_configs:- job_name: 'redis'static_configs:- targets: ['redis-exporter:9121']
关键指标:
redis_memory_used_bytes:内存使用redis_commands_processed_total:命令处理数redis_keyspace_hits_total:缓存命中次数
3. Kafka监控
# 安装kafka_exporter
docker run -d --name kafka-exporter \-p 9308:9308 \danielqsj/kafka-exporter \--kafka.server=kafka-server:9092# Prometheus配置
scrape_configs:- job_name: 'kafka'static_configs:- targets: ['kafka-exporter:9308']
关键指标:
kafka_topic_partition_current_offset:分区偏移量kafka_consumer_group_lag:消费组延迟kafka_broker_requests_total:请求总数
4. MySQL监控
# 安装mysqld_exporter
docker run -d --name mysql-exporter \-p 9104:9104 \-e DATA_SOURCE_NAME="exporter:password@(mysql-server:3306)/" \prom/mysqld-exporter# Prometheus配置
scrape_configs:- job_name: 'mysql'static_configs:- targets: ['mysql-exporter:9104']
关键指标:
mysql_global_status_queries:查询总数mysql_global_status_threads_connected:连接数mysql_global_status_slow_queries:慢查询数
五、全链路追踪中的中间件监控
1. SkyWalking与Prometheus集成
# SkyWalking OAP配置 (application.yml)
prometheus-fetcher:selector: ${SW_PROMETHEUS_FETCHER:default}default:active: ${SW_PROMETHEUS_FETCHER_ACTIVE:true}rules:- name: "nginx_metrics"endpoint: "http://nginx-exporter:9113/metrics"metrics_path: "/metrics"- name: "redis_metrics"endpoint: "http://redis-exporter:9121/metrics"
2. 全链路视角的中间件监控
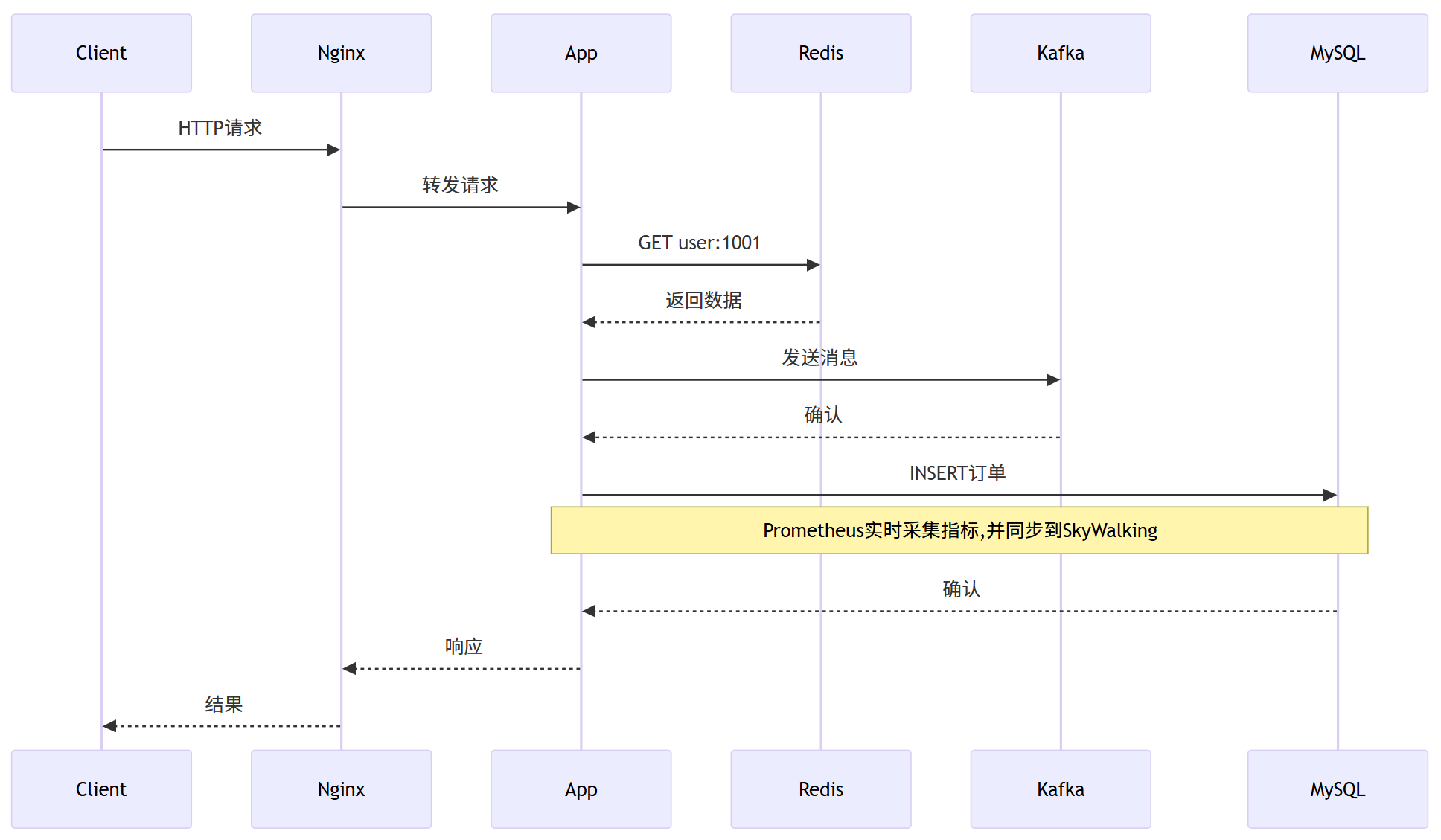
六、性能瓶颈定位实战
1. 瓶颈分析流程图
2. 典型瓶颈案例
案例:Redis响应延迟导致订单超时
现象:
- 下单接口P99延迟>2s
- SkyWalking显示Redis操作占时80%
排查步骤:
- 查看Redis指标:
redis-cli info stats | grep instantaneous_ops_per_sec # instantaneous_ops_per_sec: 85000redis-cli info memory | grep used_memory # used_memory: 15gb # maxmemory: 16gb - 发现内存使用率93%,频繁触发淘汰策略
- 分析Key模式:
redis-cli --bigkeys - 发现大Key:
user:activity:history(单个Key 1.2GB)
解决方案:
- 拆分大Key为多个小Key
- 设置合理过期时间
- 增加Redis内存
七、Grafana监控大盘
1. 中间件核心监控面板
2. 面板配置示例(Redis)
{"panels": [{"type": "graph","title": "内存使用","targets": [{"expr": "redis_memory_used_bytes","legendFormat": "内存使用"}]},{"type": "graph","title": "每秒操作数","targets": [{"expr": "rate(redis_commands_processed_total[1m])","legendFormat": "OPS"}]}]
}
八、告警配置实战
1. Prometheus告警规则
# alert.rules.yml
groups:
- name: middleware-alertsrules:- alert: RedisMemoryCriticalexpr: redis_memory_used_bytes / redis_memory_max_bytes > 0.9for: 5mannotations:summary: "Redis内存不足 (实例 {{ $labels.instance }})"description: "Redis内存使用率超过90%"- alert: KafkaConsumerLagHighexpr: kafka_consumer_group_lag > 10000for: 10mannotations:summary: "Kafka消费延迟过高 (主题 {{ $labels.topic }})"description: "消费组 {{ $labels.group }} 积压超过10000条消息"
2. 告警集成方案
九、学习路径建议
-
第一周:基础搭建
- Docker部署Prometheus+Grafana
- 配置Nginx/Redis监控
- 创建基础仪表盘
-
第二周:全链路集成
- SkyWalking与Prometheus集成
- 配置Kafka/MySQL监控
- 创建全链路监控视图
-
第三周:瓶颈分析实战
- 模拟中间件瓶颈场景
- 使用监控工具定位问题
- 实施优化方案
-
第四周:生产级监控
- 配置告警规则
- 实现自动化报警
- 设计容量规划方案
十、避坑指南
-
指标爆炸问题:
- 使用Prometheus的
honor_labels避免冲突 - 合理设置采集间隔(15-30s)
- 使用Prometheus的
-
资源消耗控制:
- 限制Exporter的内存使用
- 使用采样减少数据量
-
安全防护:
- 为Exporter设置认证
- 使用防火墙限制访问
-
数据保留策略:
# Prometheus配置 storage:retention: 15d # 保留15天数据
总结
通过本指南,可以掌握:
- 主流中间件的监控方案部署
- 全链路追踪与指标监控的集成
- 中间件性能瓶颈的定位方法
- 生产级监控告警配置
关键成功因素:
- 动手实践:在本地环境搭建完整监控链
- 场景模拟:主动制造瓶颈并练习排查
- 持续优化:根据业务需求调整监控策略
下一步建议:
在测试环境模拟以下场景:
- 人为制造Redis内存溢出
- 设置Kafka消息积压
- 触发MySQL连接池耗尽
练习使用监控工具快速定位问题根源