[论文阅读] 人工智能 + 软件工程 | NoCode-bench:评估LLM无代码功能添加能力的新基准
NoCode-bench:评估LLM无代码功能添加能力的新基准
论文:NoCode-bench: A Benchmark for Evaluating Natural Language-Driven Feature Addition
研究背景:当AI尝试给软件"加新功能",我们需要一张靠谱的"考卷"
想象一下,你想给常用的软件加个小功能——比如让聊天工具支持邮件订阅,或者让表格软件导出新格式。如果不用写代码,只需用自然语言描述这个需求,AI就能自动完成代码修改,那该多方便?这就是"自然语言驱动的无代码开发"的愿景:让普通人也能通过说话或写字来定制软件,不用再跟复杂的代码打交道。
但这里有个大问题:我们怎么知道AI能不能做好这件事?现有的评估工具大多盯着"修bug"或"解决问题",比如给AI一个"软件崩溃了"的描述,看它能不能修好。但"加新功能"和"修bug"完全不是一回事——前者需要理解现有软件的结构,还要在不破坏原有功能的前提下新增代码,难度大得多。而且,现有基准里只有极少数任务是关于加功能的(比如SWE-bench里仅7.3%)。
就像老师想测试学生的"作文创新能力",但手里只有"改错题"的试卷,显然测不出真实水平。于是,研究者们决定打造一张专门的"考卷"——这就是NoCode-bench的由来。
主要作者及单位信息
该论文由来自浙江大学、香港科技大学、斯图加特大学的研究者合作完成,核心团队包括Le Deng、Zhonghao Jiang、Jialun Cao、Michael Pradel和Zhongxin Liu(通讯作者),其中多数作者来自浙江大学区块链与数据安全国家重点实验室。
创新点:这张"考卷"和以前的有什么不一样?
-
聚焦"无代码功能添加"这一空白领域:不同于现有基准(如SWE-bench)主要关注bug修复,NoCode-bench专门针对"用自然语言描述新功能,让AI生成代码变更"的场景,填补了该领域评估工具的空白。
-
从"发布说明"出发,保证任务真实性:以前的基准常从"问题描述"或"代码提交记录"里挖任务,容易混入模糊或错误的案例。而NoCode-bench从软件的"发布说明"入手——这是开发者自己写的"更新日志",明确标注了"新增功能",相当于直接从老师手里拿了"官方题库",任务真实性大大提高。
-
有"精简版考卷"方便快速评估:完整版包含634个任务,对资源有限的研究者不太友好。于是团队人工筛选出114个高质量任务(NoCode-bench Verified),就像"模拟卷",既能保证评估效果,又能节省时间。
研究方法:这张"考卷"是怎么出的?
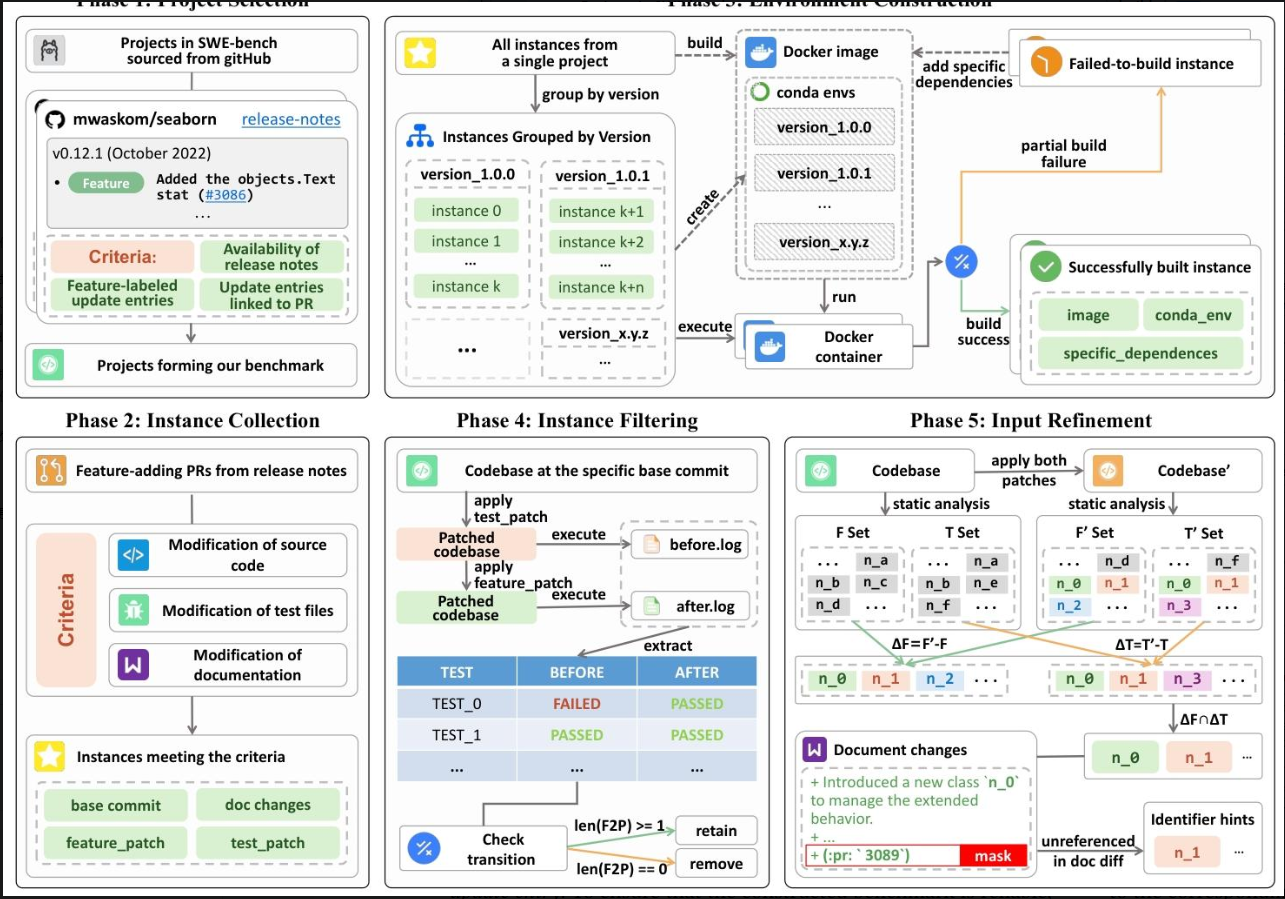
NoCode-bench的构建分5个步骤,就像出卷老师从选题到定稿的全过程:
-
选"教材"(项目选择):从SWE-bench的12个开源项目里,挑出10个符合条件的——必须有清晰的发布说明,且明确标注了"新增功能",还能关联到具体的代码修改记录(PR)。比如flask因为没有标注"功能"就被排除了。
-
找"题目素材"(实例收集):从选定的项目里爬取所有和"新增功能"相关的代码修改记录(PR),并筛选出同时改了源代码、测试文件和文档的PR——毕竟加功能不仅要写代码,还要更新说明书和测试用例。
-
搭"考场环境"(环境构建):为每个项目准备可复现的运行环境,用Docker镜像和Anaconda管理依赖,避免因为"环境不对"导致AI做对了也被判错。
-
筛"有效题目"(实例过滤):通过测试用例验证每个任务——新增功能后,必须有一些测试从"失败"变成"成功"(证明功能生效了),否则就剔除。最终留下634个有效任务。
-
优化"题目描述"(输入 refinement):有些任务的文档里没提新增的类或函数名,但测试用例里有,这种情况会导致AI写对了也通不过测试。于是研究者补充了这些"隐藏信息",还删掉了文档里的PR编号(避免AI"作弊")。
而评估实验则像"模拟考试":选了6个最先进的LLM(比如GPT-4o、Claude-4-Sonnet),用两种主流框架(Agentless和OpenHands)让它们完成任务,再通过"成功率""文件匹配率"等指标打分。
主要贡献:这张"考卷"到底有什么用?
-
填补了领域空白:首次提出专门评估"无代码功能添加"的基准,让研究者有了统一的工具来比较不同AI的能力。
-
揭示了LLM的真实水平:测试发现,最好的AI(Claude-4-Sonnet)在简单任务集里成功率仅15.79%,复杂任务集里更低。这说明现在的AI离"无代码开发"还差得远。
-
指出了AI的三大短板:
- 不会跨文件修改:多文件任务的成功率不到3%;
- 看不懂软件结构:经常改坏原有功能;
- 不会用工具:调用编辑工具时格式总出错,导致任务失败。
这些发现就像给AI开发者递了一张"改进清单",明确了未来需要突破的方向。
解决的主要问题及成果
- 解决了"无代码功能添加"缺乏专门评估工具的问题,提出了NoCode-bench基准;
- 构建了包含634个任务的数据集及114个人工验证的子集,支持多样化评估;
- 评估了主流LLM的表现,发现其在跨文件编辑、代码结构理解和工具调用上的短板,为后续研究提供了依据。
一段话总结:
NoCode-bench是一个用于评估大型语言模型(LLMs)在自然语言驱动的无代码功能添加任务上表现的基准测试集,包含来自10个项目的634个任务,涉及约114k代码变更,每个任务均配对用户文档变更与对应的代码实现,并通过开发者编写的测试用例验证。其构建通过五阶段流程(项目选择、实例收集、环境构建、实例过滤、输入优化)完成,以发布说明为起点确保任务真实性,并包含一个经人工验证的子集NoCode-bench Verified(114个任务)以支持轻量评估。评估结果显示,最先进的LLMs在NoCode-bench Verified上的最佳成功率仅为15.79%,在NoCode-bench Full上更低,主要因缺乏跨文件编辑能力、对代码库结构理解不足及工具调用能力欠缺导致。
思维导图:

详细总结:
1. 背景与目的
- 无代码开发旨在让用户通过自然语言指定软件功能,无需直接编辑代码,LLMs在此领域有潜力,但需高质量基准测试评估其能力。
- 现有基准(如SWE-bench)多关注bug修复或问题解决,较少针对无代码场景,且功能添加任务占比低(如SWE-bench仅7.3%),因此构建NoCode-bench以填补空白。
2. NoCode-bench构建(五阶段流程)
- 项目选择:从SWE-bench的12个项目中筛选出10个,要求有发布说明、特征标注的更新条目及关联的GitHub PR。
- 实例收集:爬取符合条件的特征添加PR,筛选出同时修改源代码、测试文件和文档的PR,截止2024年8月,获1571个候选实例。
- 环境构建:为每个项目构建基础Docker镜像,用Anaconda管理版本隔离,解决依赖问题确保环境可复现。
- 实例过滤:保留有F2P测试(从失败到成功的测试用例)的实例,最终获634个任务。
- 输入优化:补充测试中引用但文档未提及的实体名称,屏蔽PR编号等避免数据泄露。
3. NoCode-bench Verified
- 构建:从候选中随机抽样238个任务,由5名资深开发者按任务清晰度和评估准确性标注,最终保留114个高质量任务。
- 作用:支持资源有限情况下的轻量、可靠评估,与NoCode-bench Full(634个任务)互补。
4. 实验设置
- 研究问题(RQs):
- RQ1:与SWE-bench的特征差异
- RQ2:LLMs在Verified子集的表现
- RQ3:LLMs在Full子集的表现
- RQ4:LLMs失败的原因
- 模型与框架:6个LLMs(3个开源:Qwen3-235B等;3个闭源:GPT-4o等),采用Agentless和OpenHands框架。
- 评估指标:成功率(Success%)、应用率(Applied%)、文件匹配率(File%)、回归测试通过率(RT%)等。
5. 实验结果
| 维度 | NoCode-bench vs SWE-bench |
|---|---|
| 输入复杂度 | 文档变更平均长度约为SWE-bench问题描述的2倍(739.06 vs 480.37 tokens) |
| 定位难度 | 平均修改文件2.65个(SWE-bench 1.66个),13.56%实例需新增/删除文件(SWE-bench 1.70%) |
| 编辑难度 | 平均代码变更179.12行(SWE-bench 37.71行),20%实例变更超200行 |
- RQ2(Verified子集):Claude-4-Sonnet表现最佳,成功率15.79%;Agentless框架应用率(98%)高于OpenHands(59%)。
- RQ3(Full子集):平均成功率5.68%,低于Verified子集,因任务更复杂且含噪声。
- RQ4(失败原因):
- 跨文件编辑能力不足:多文件任务成功率仅2.03%(Full子集)。
- 代码库结构理解不足:修改破坏现有功能(如DeepSeek-v3的错误修改)。
- 工具调用能力欠缺:Gemini-2.5-Pro因格式错误成功率为0。
6. 结论
NoCode-bench为无代码功能添加任务提供了挑战性基准,现有LLMs表现不佳,需在跨文件编辑、代码库理解和工具调用方面改进。
关键问题:
-
NoCode-bench与现有软件工程基准(如SWE-bench)的核心区别是什么?
答:NoCode-bench聚焦无代码功能添加场景,以文档变更为输入,而SWE-bench等多关注传统问题解决,以 issue 描述为输入;NoCode-bench任务涉及更多跨文件编辑(平均2.65个文件 vs SWE-bench 1.66个)、更长代码变更(平均179行 vs SWE-bench 37行),且包含更高比例的文件增删(13.56% vs 1.70%),难度更高。 -
LLMs在NoCode-bench上的评估表现如何?主要发现是什么?
答:最先进的LLMs表现较差,在Verified子集上最佳成功率为15.79%(Claude-4-Sonnet),在Full子集上平均成功率仅5.68%;Agentless框架整体表现优于OpenHands;模型在单文件任务上的成功率(如Claude-4-Sonnet达24.59%)显著高于多文件任务(仅3.77%),表明跨文件编辑是主要瓶颈。 -
导致LLMs在NoCode-bench任务中失败的关键原因有哪些?
答:主要有三点:一是缺乏跨文件编辑能力,多文件任务成功率极低;二是对代码库结构理解不足,修改易破坏现有功能(如DeepSeek-v3的错误实现);三是工具调用能力欠缺,模型难以生成符合格式的工具指令(如Gemini-2.5-Pro因格式错误成功率为0)。
总结:一张难住了当前AI的"考卷"
NoCode-bench是首个聚焦"自然语言驱动无代码功能添加"的基准,包含634个真实任务(及114个精选任务),通过严谨的五阶段流程构建而成。实验显示,即使是最先进的LLM,在这张"考卷"上的表现也很糟糕,主要因为跨文件编辑、软件结构理解和工具调用能力不足。
这不仅是对当前AI的"压力测试",更为未来的研究指明了方向——要实现"无代码开发",AI还有很长的路要走。