Spring框架
概论:这一部分主要是讲解当前公司中所使用的技术、框架.
为什么要学习框架,举个例子:走一条道我们走山路是1个小时到达,但是走高速公路就是20分钟到达.走两条路所要花销都是一致的,而且走高速公路还可以使用公路的配套设施(比如服务站加油站之类的,而走山路只能走自己的路),此时我们大多数人都会选择走高速公路.
分析一下servlet的痛点:
1. 添加外部的jar不方便,容易出错,比如添加了一个不匹配的外部的jar版本.
2. 运行和调试的时候需要配套tomcat不方便.
3. 发布不方便servlet项目必须依靠外置的tomcat(外置的web容器)运行.
4. 路由器配置不方便,一个访问地址对应一个servlet类
所以此处我们就使用当前全球最为流行的spring框架进行servlet的替代,让编程能够更加的高效,简单,且能够实现更多的功能.
spring的定义:包含了众多工具的IoC容器.
什么是Ioc:
IoC就是(控制反转)
比如制造一辆汽车,
车 -> 车身 -> 框架 -> 轮胎/发动机
车的制作的每一步流程都是依托于前一步流程的,不可分开.
但是这样制造汽车会影响开发速率,并且流程中的耦合性太高,如果前一步出错(如框架有问题),之后的流程就都会收到影响.
而如今生产汽车引入了流水线,分别制造各个组件.就节省了生产成本,与开发时间.
并且汽车各个部分的组件也可以进行客制化定制.(想要怎样的零件就生产怎样的零件)
ioc其实就相当于现在流水线.不在关注该类的依赖,而是把自己这个类的生命周期交给别的流程让其控制.就相当于将我们每个类的生命周期交给spring,让spring去控制依赖这样可以极大程度上的解耦合.
所以说IoC不是一个具体的技术,是一个思想(就是相当于把自己类的生命周期交给别的类来使用的一种思想)

怎么理解spring的定义:包含了众多工具的IoC容器.
spring既然是一个容器,故定然有两个功能:
1.存对象
2.取对象
所以说我们要学习的东西也就明确是:存对象和取对象
Spring IoC 优点:
1. 解耦
2. 使用更加方便了(不需要手动进行创建,和关注这个对象背后的关系了)
3. 更加高效
DI的概念:
DI就是(依赖注入)
IoC和DI是一对cp,一般都是同时出现且存在的.
DI(依赖注入)就是在IoC过程中,将依赖的某个对象动态注入(动态拿到当前类当中)的这个行为.
所以说DI就是在主动获取对象.(主要实现方式其实就是一个注解)
所以说IoC( 思想 ) / Spring IoC( 框架 ) / DI( 技术 )
一、安装spring boot 简单方式:
首先寻找一份免费的和你idea版本对应的intellij-spring-assistant-2022.1.2.zip

然后这样添加: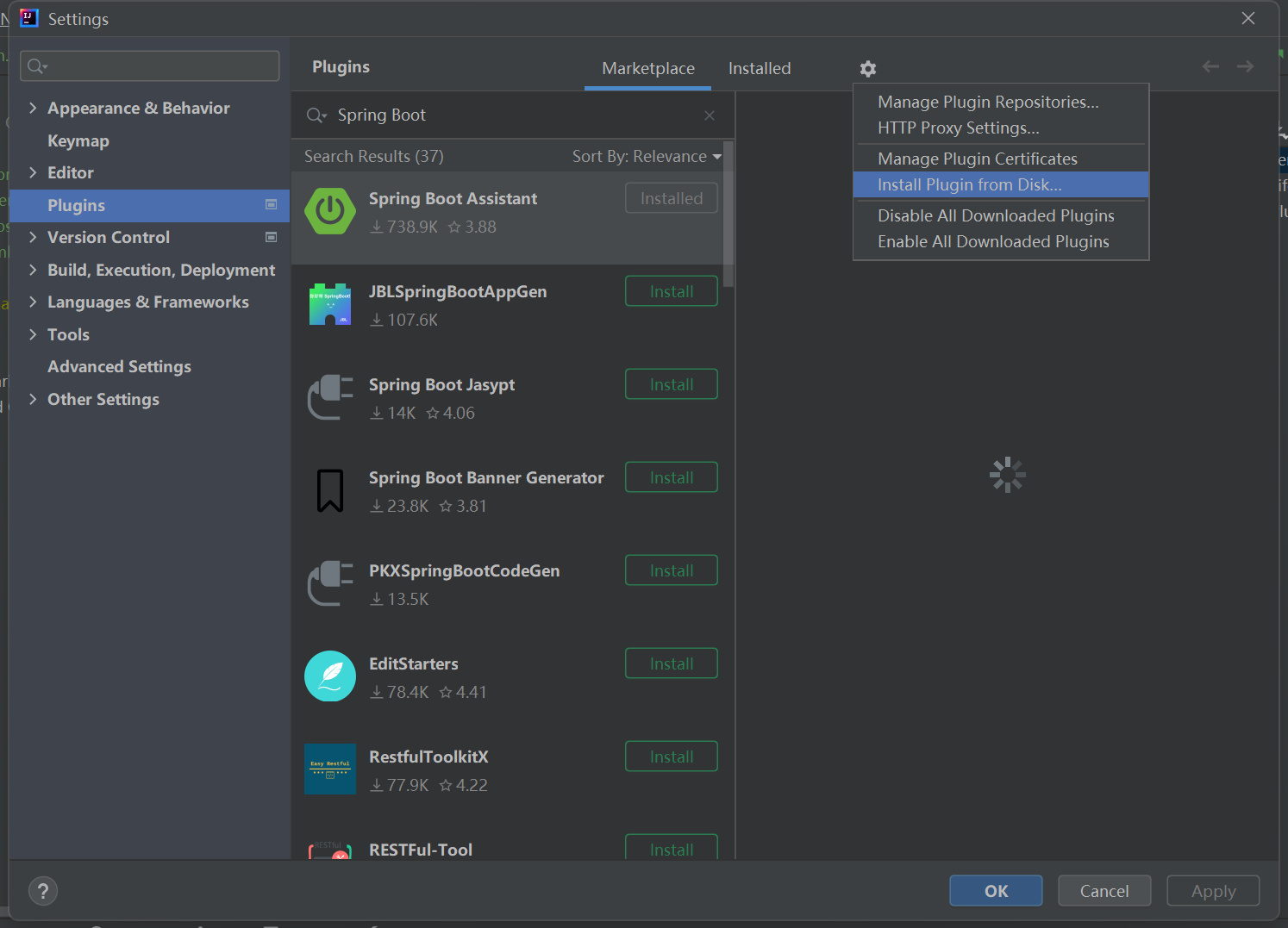
寻找安装包: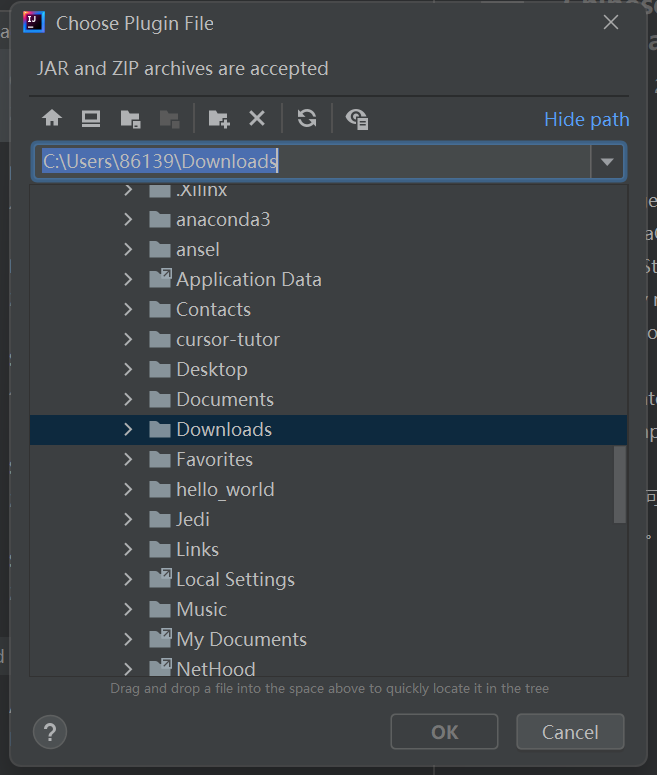
然后重启idea就安装好了:
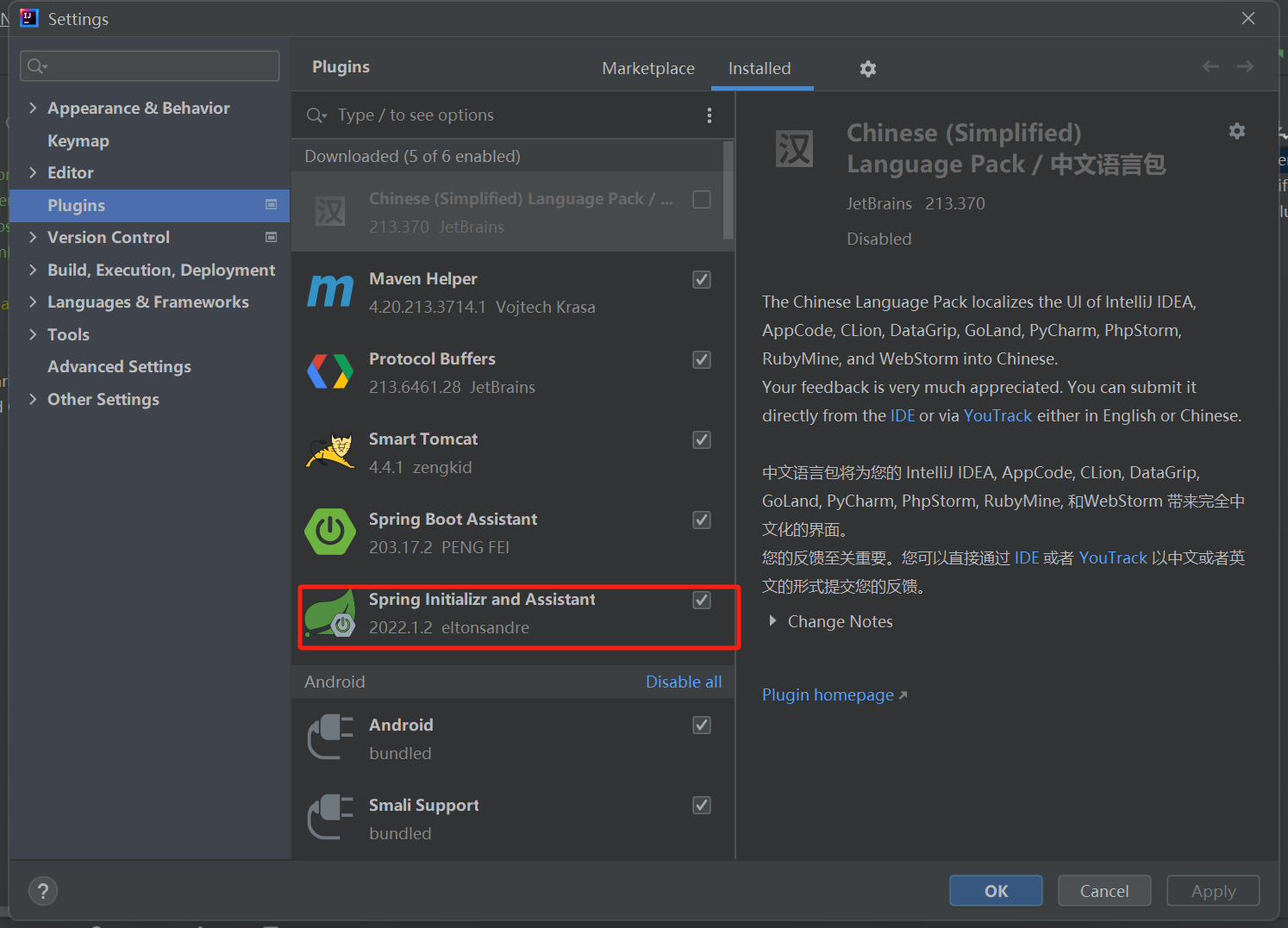
创建项目:
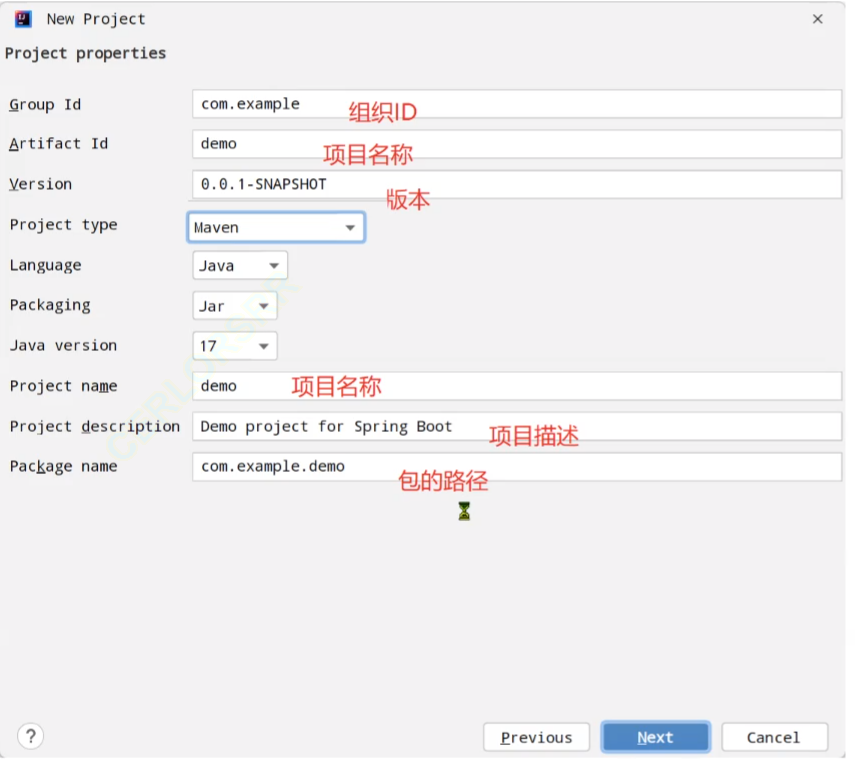
主要就是改一下maven
选择maven版本
添加javaweb:
这样就创建成功了:
另外创建的目录都是这个意思:
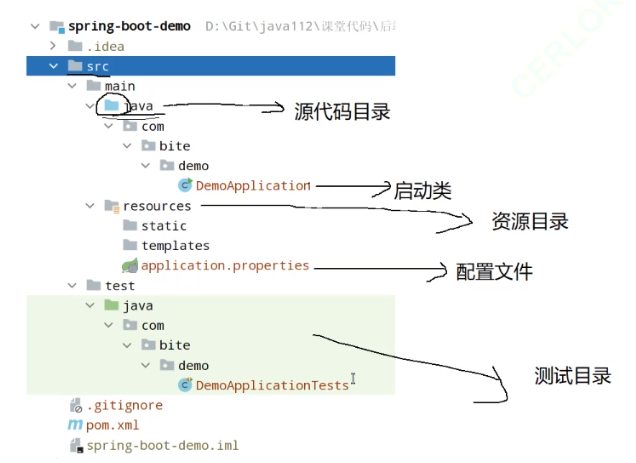
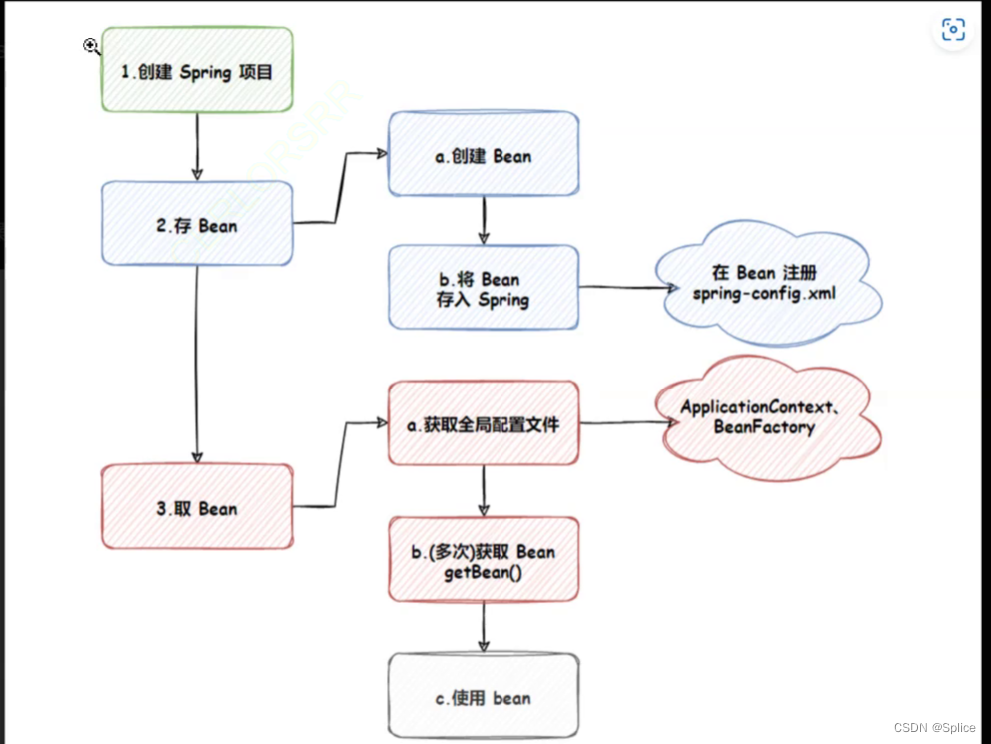
二、spring的创建和使用:
1. spring 项目的创建
创建一个Spring(Core):
a.创建一个maven项目
此时就已经初始化好了!!!
b.添加Spring依赖
添加依赖最终要的一部就是设置国内源(配置国内源的目的是让maven不再从国际上的服务器进行配置提高成功率和速度)
maven helper(控制依赖的插件)
在idea中有两个配置文件的设置:
然后在相关目录中添加setting.xml文件
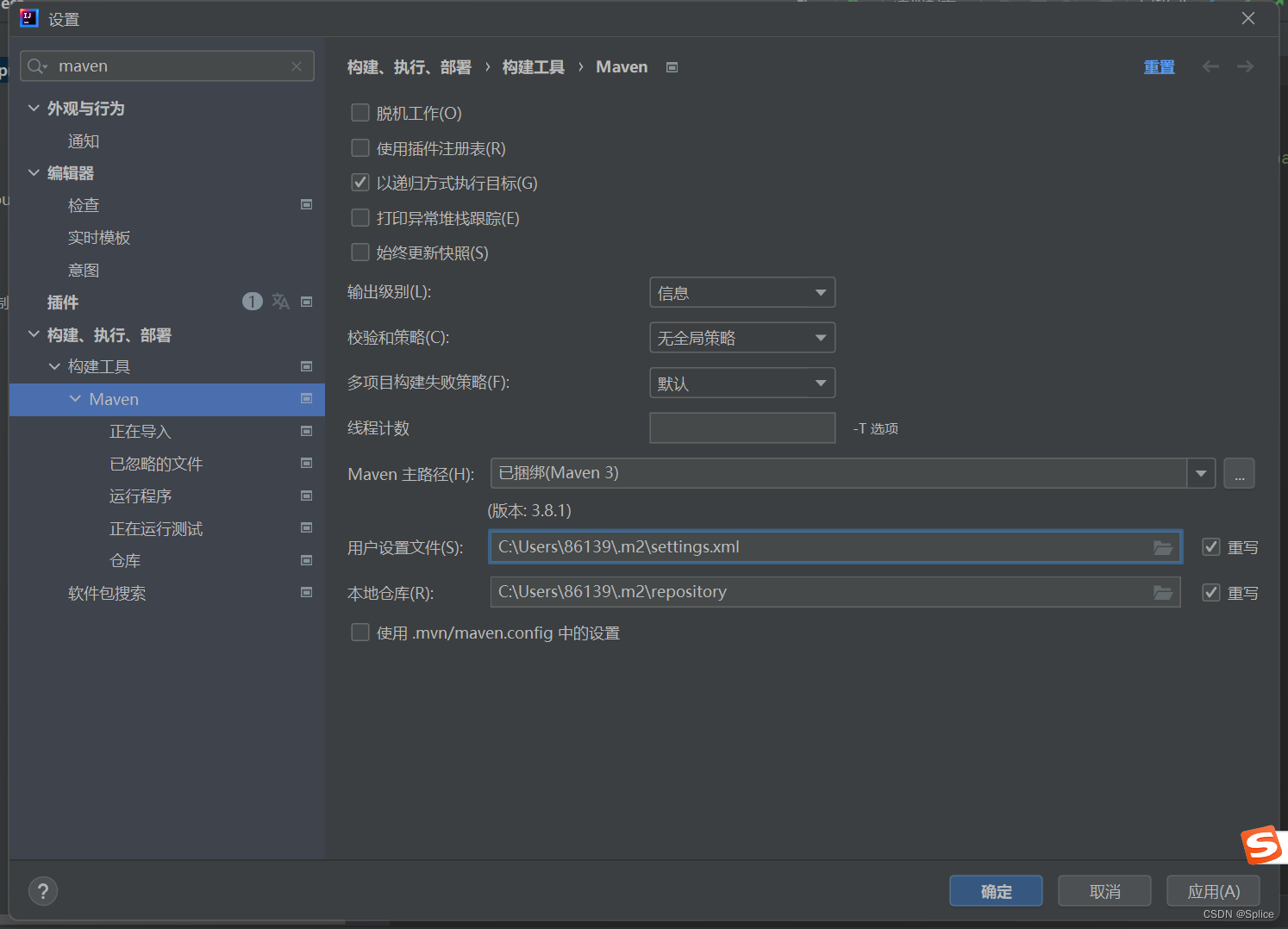
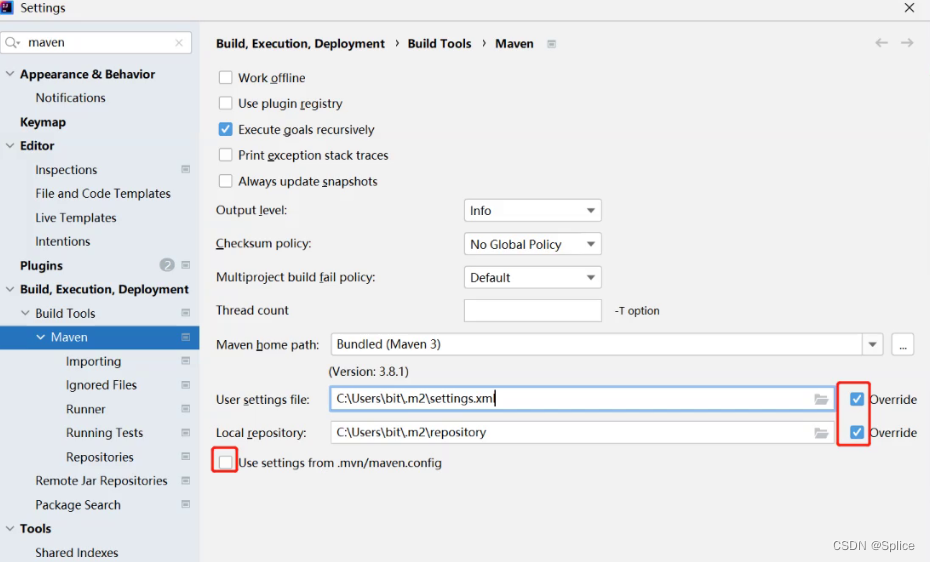
三个√需要进行更改. 而且注意路径不要有中文
然后根据上面的路径进入settings.xml
在这个setting 文件中,有一段镜像的国内源的url:
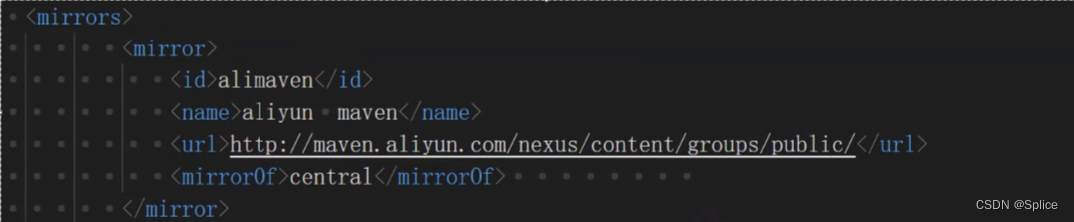
有了这个进行依赖将会从阿里的服务器进行获取,而不是国外的maven仓库了.
然后重新下载jar包:
为了保证所有jar包走的都是国内源,我们要清空本地所有的jar包,然后再重新下载.

jar包保存在这里 .
另外,还有可能有其他的问题:
比如说运营商问题之类的,这个问题可以换一个网络如:联通移动之类的.
然后添加spring框架的依赖:
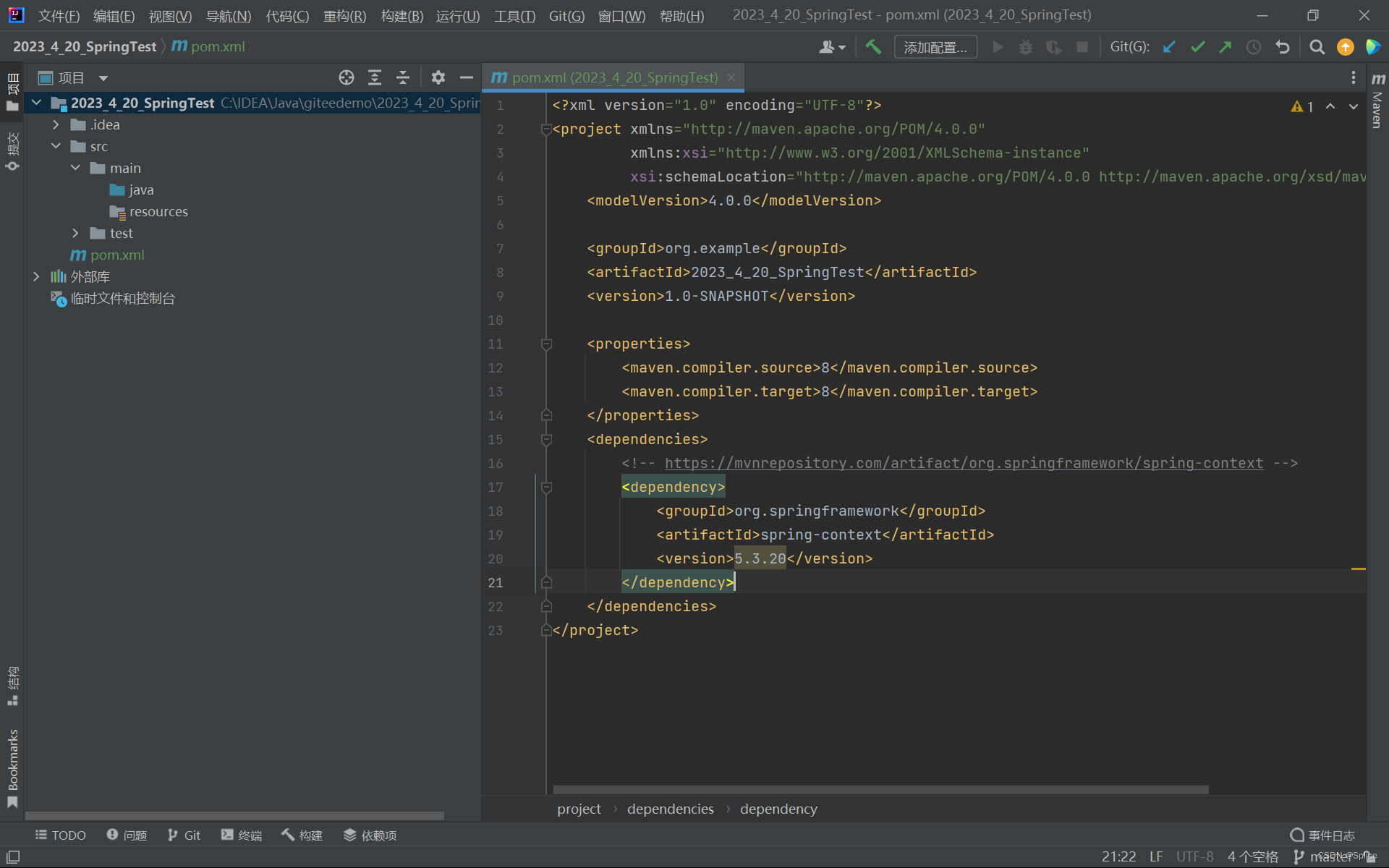
<!-- https://mvnrepository.com/artifact/org.springframework/spring-context --><dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version>5.3.20</version></dependency>c.创建启动类
2.将 bean 存储 Spring ( 容器 )
首先是创建一个文件:
然后将这段配置文件复制到上面:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:content="http://www.springframework.org/schema/context"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd">
</beans>在这个文件中就可以自己写bean对象.
如果目录是这样子的结构的:
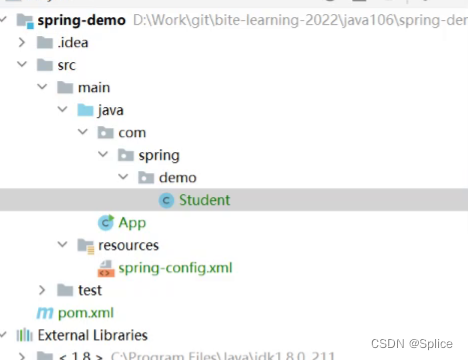
我们的bean标签中就需要这样进行规定:
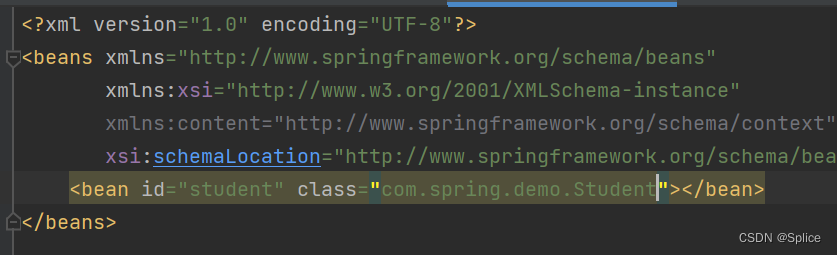
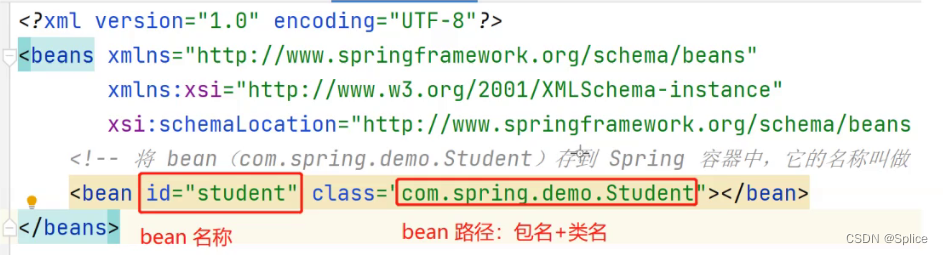
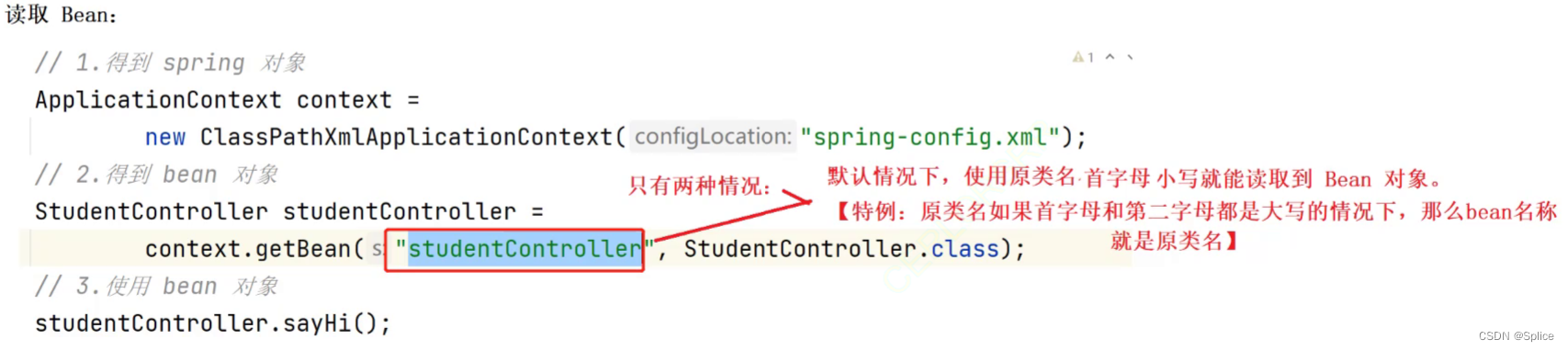
3.从 Spring 中获取 bean[ DI ]
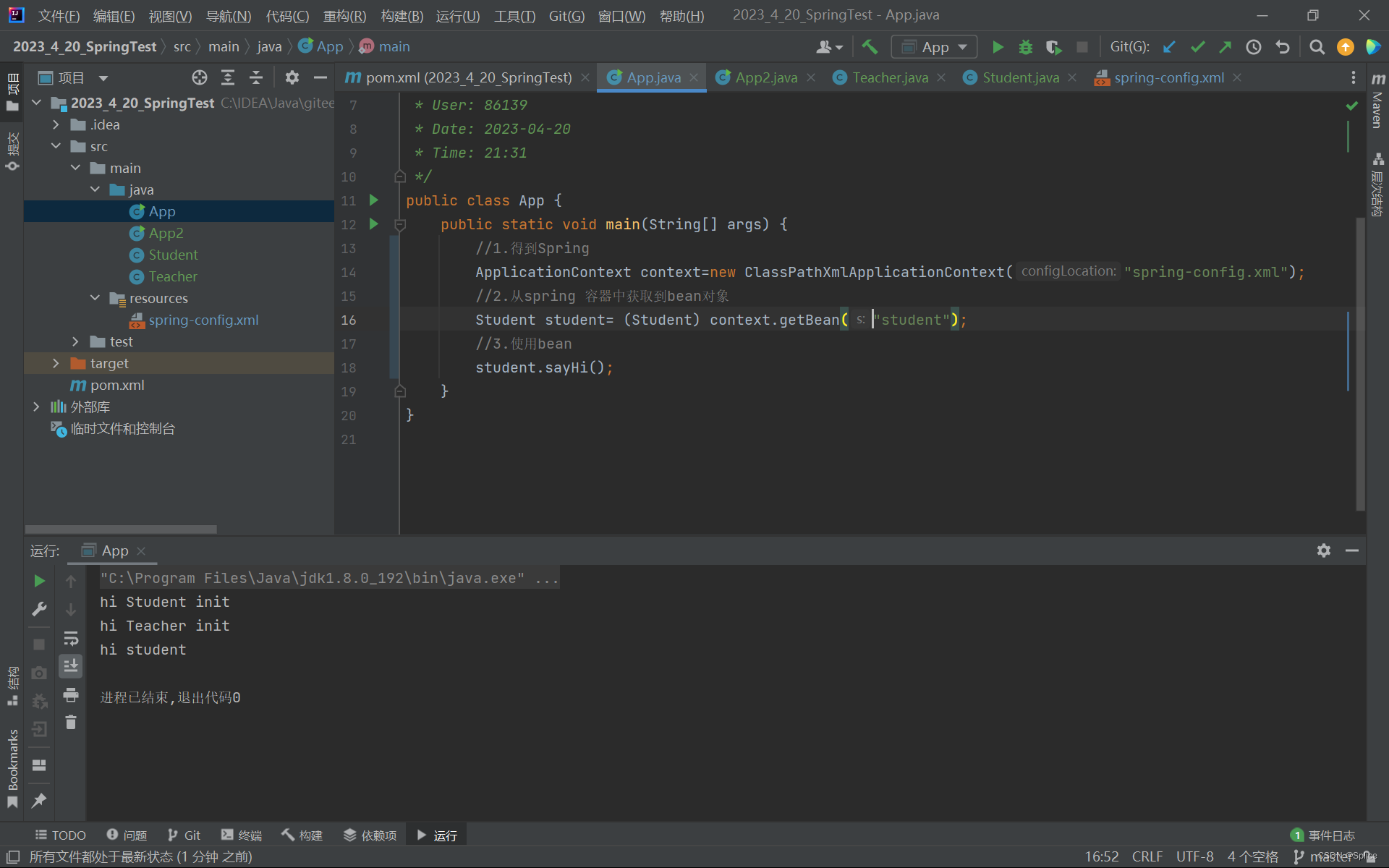
首先是得到Spring (上下文) 对象.
第一种方法:
使用ApplicationContext类进行对象的创建(注意要填写正确的配置文件)
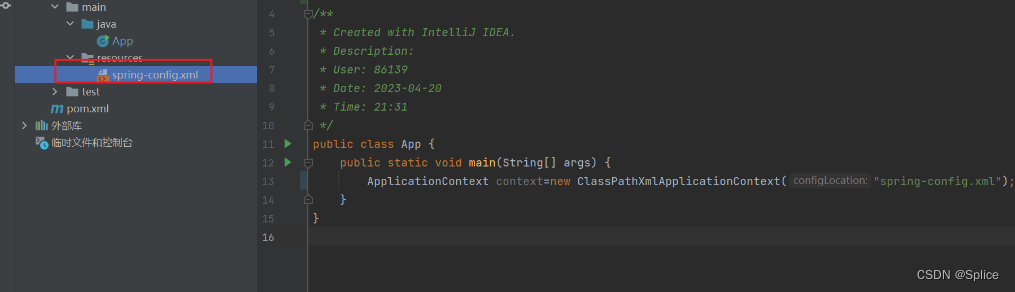
然后从spring容器中获取我们的bean:
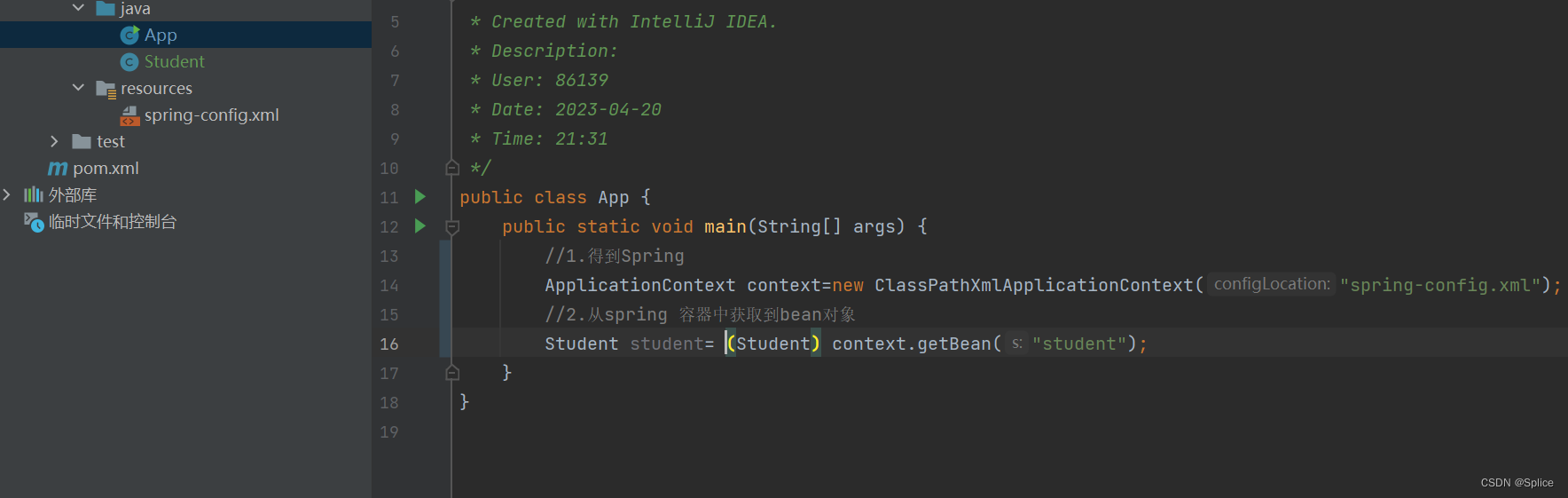
注意此时的getbean括号内存储的是这个id,怎么存所以怎么取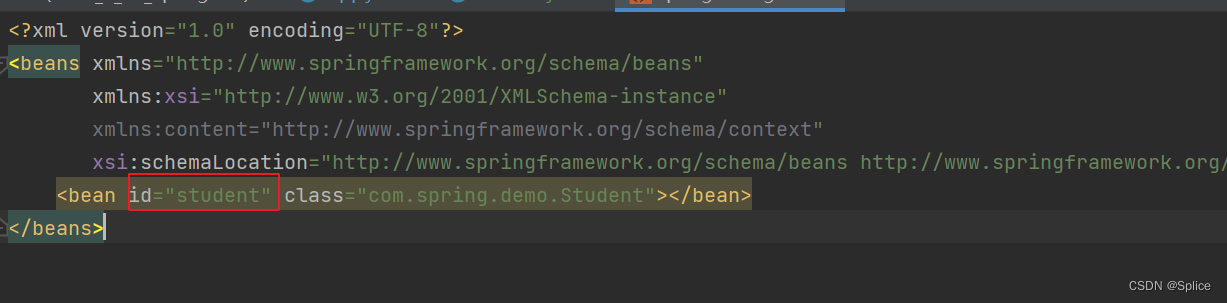
然后就是使用bean
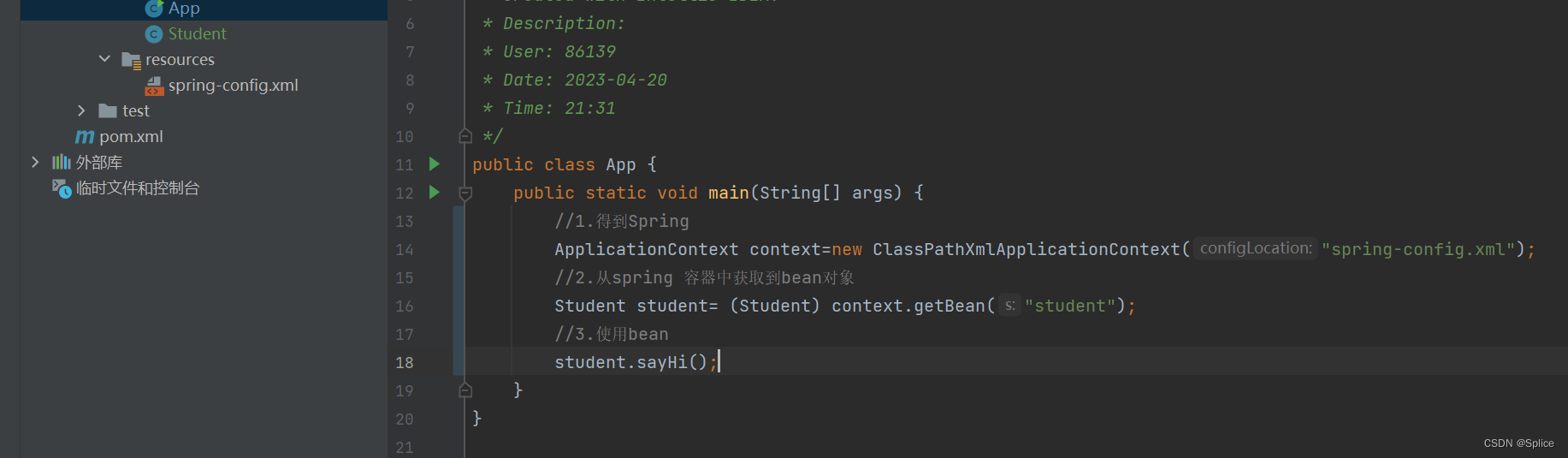
注意:在代码编写的时候需要注意路径与id:
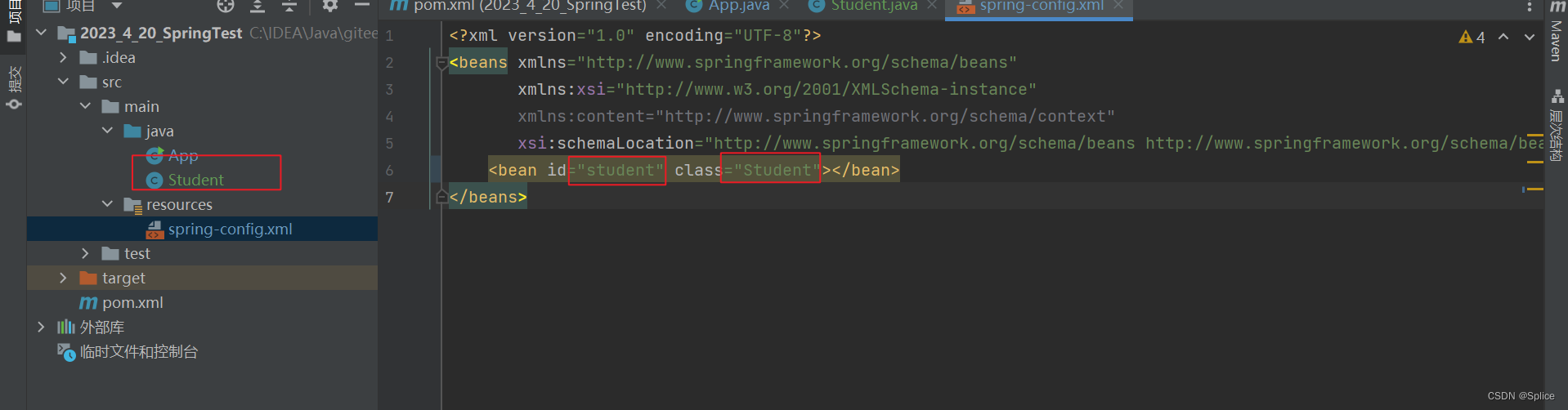
这个代码编写的目的在于:
没new对象却实现了类里的方法的调用.
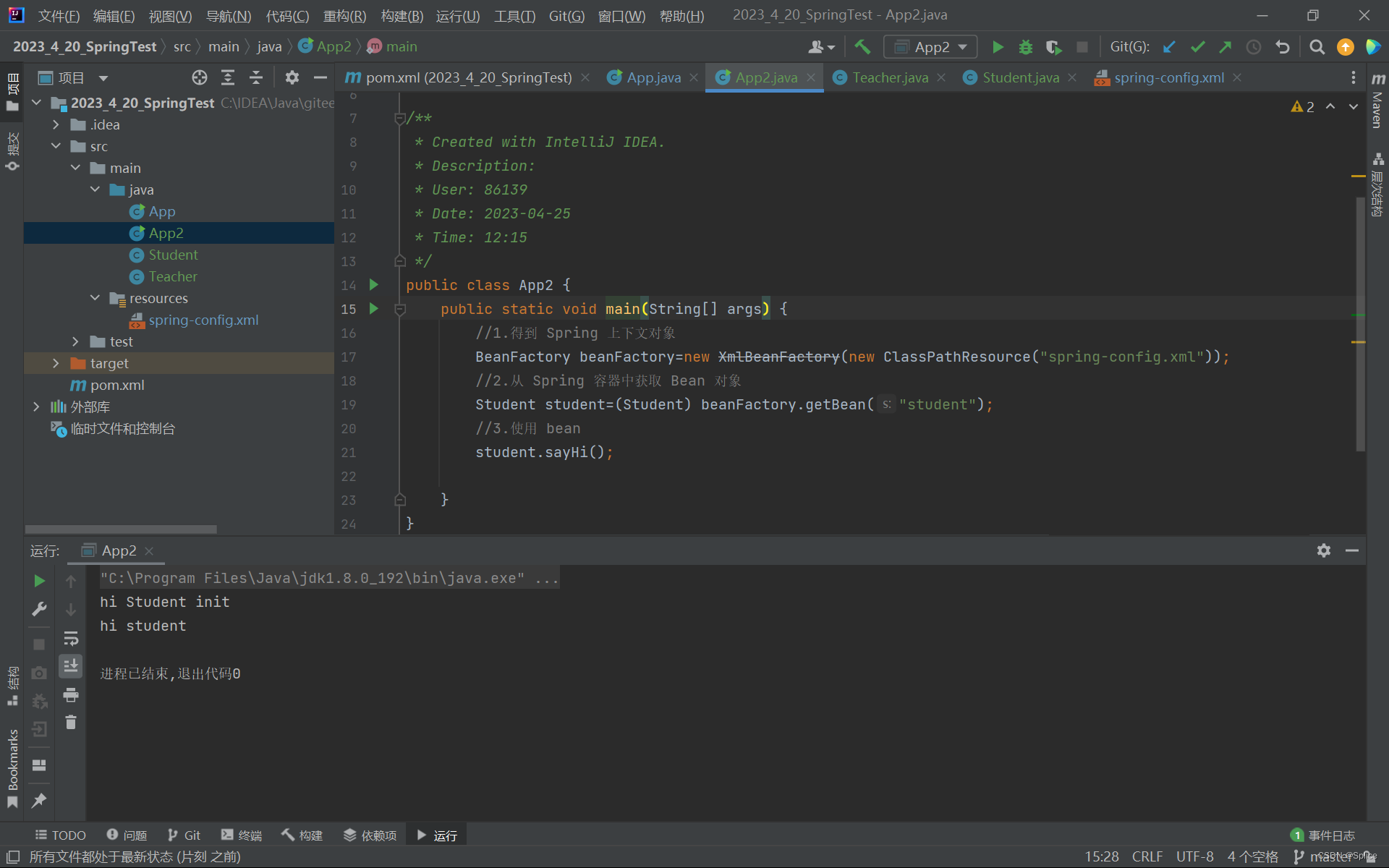
第二种方法:
跟第一种方法类似,但是这种方法其实就是ApplicationContext类的一个"替代",类似古代的"钦差"之类的,"见钦差如见皇帝"这个意思.
这两种方法的区别:
首先准备两个构造方法和普通方法
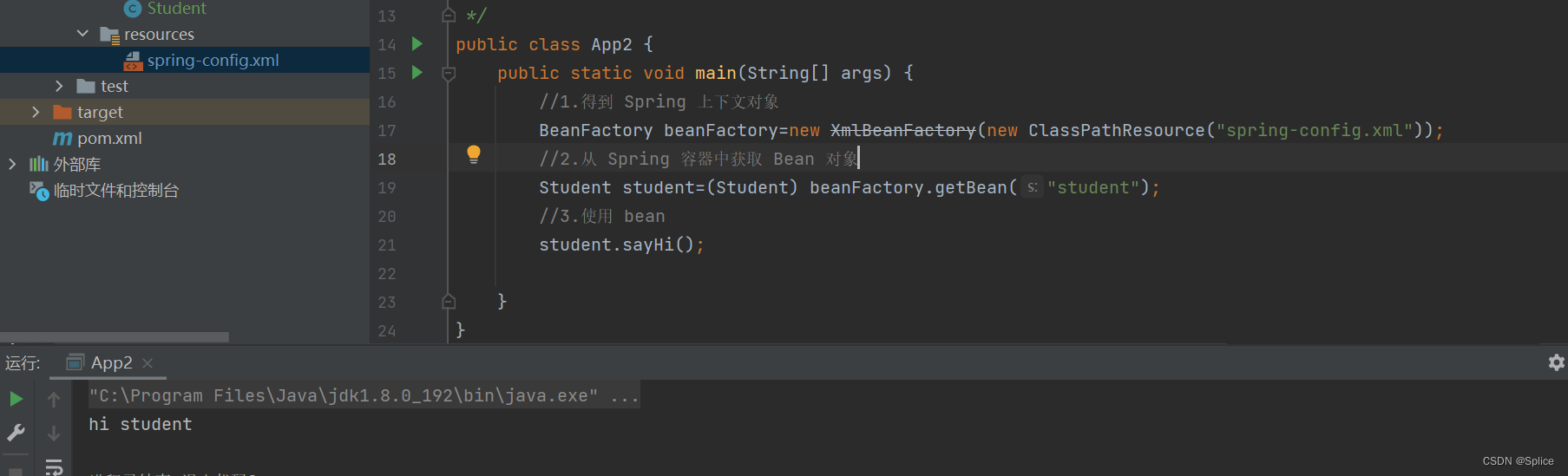
分别运行两种方法:
 当使用的是ApplicationContext的时候,运行到
当使用的是ApplicationContext的时候,运行到
ApplicationContext context=new ClassPathXmlApplicationContext("spring-config.xml");
的时候会将所有的bean对象初始化.
而BeanFactory是当你执行到
Student student=(Student) beanFactory.getBean("student");
时,才会初始化指定的bean对象初始化.
所以说,ApplicationContext比较占用内存,但是效率高调用快;但是BeanFactory比较省内存,但是调用慢,效率低.
从继承和功能的角度:ApplicationContext是BeanFactory的子类,所以它除了有BeanFactory的全部功能,还有一些它独特的功能.(对国际化支持,资源访问支持,时间传播)
获取Bean的三种方式:
1.通过名称进行获取
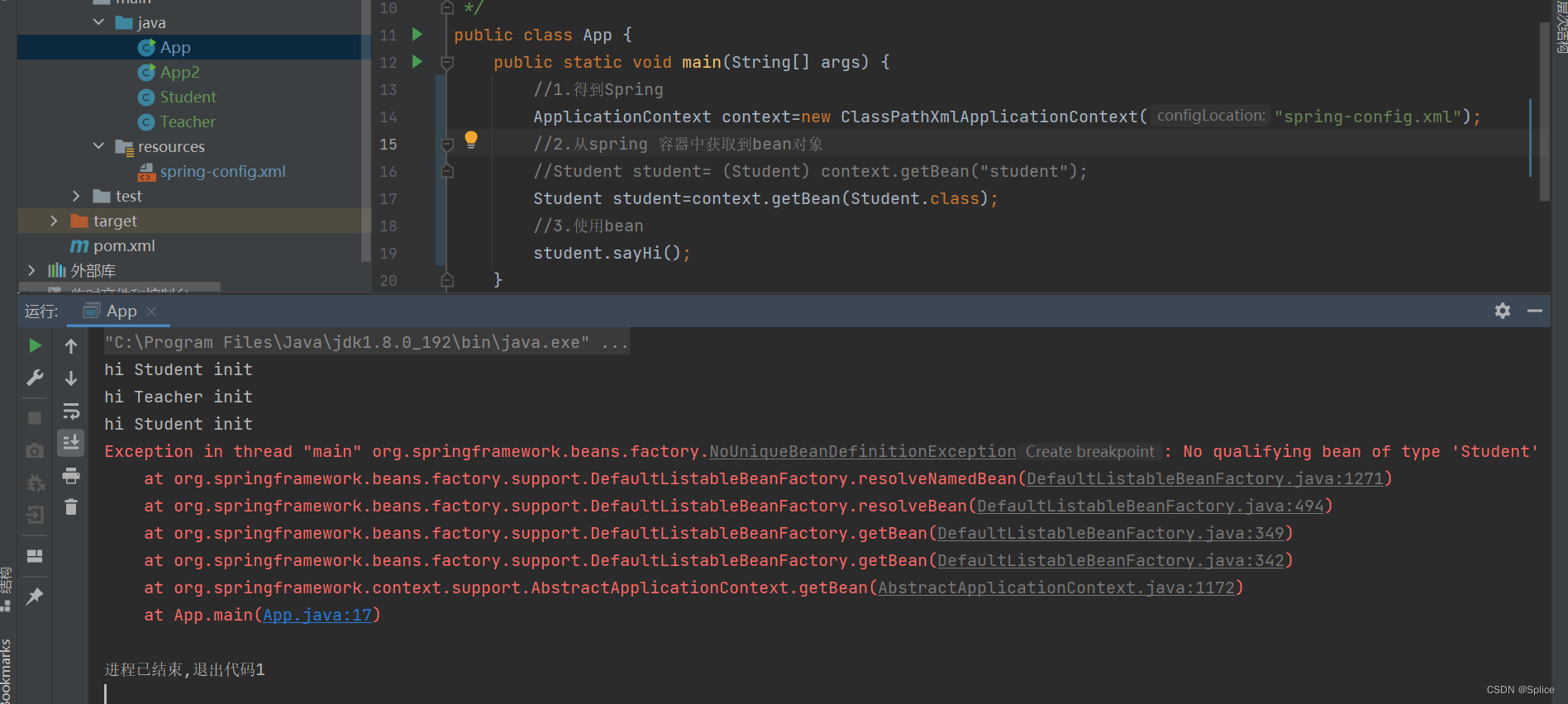
2.通过类型进行获取 
但是这种获取的方式只能让这一个类型在spring 存一次,如果在bean中存储同一个类型进行多次获取,就会报错.
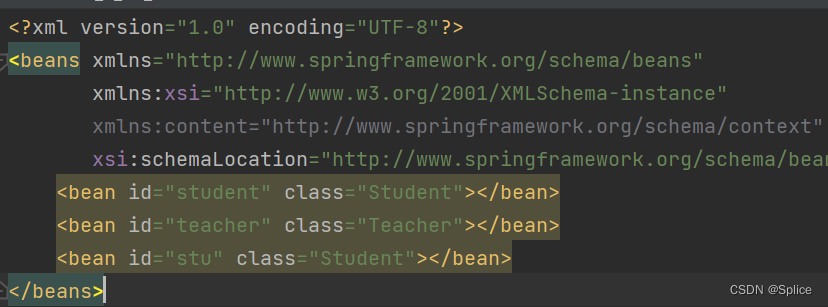
3.类型和名称一块获取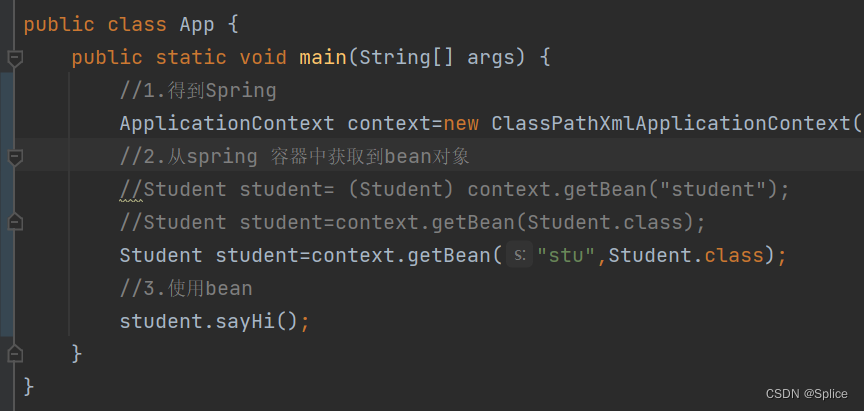
其实每一个人工创建的bean,spring都会单独创建一块区域来进行存储,所以算输出的结果相同,但不是同一个bean也是不一样的.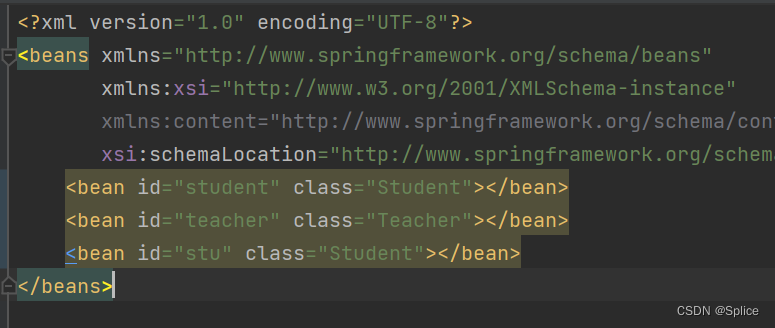
比如说此时student和stu所打印的内容都是一样的.
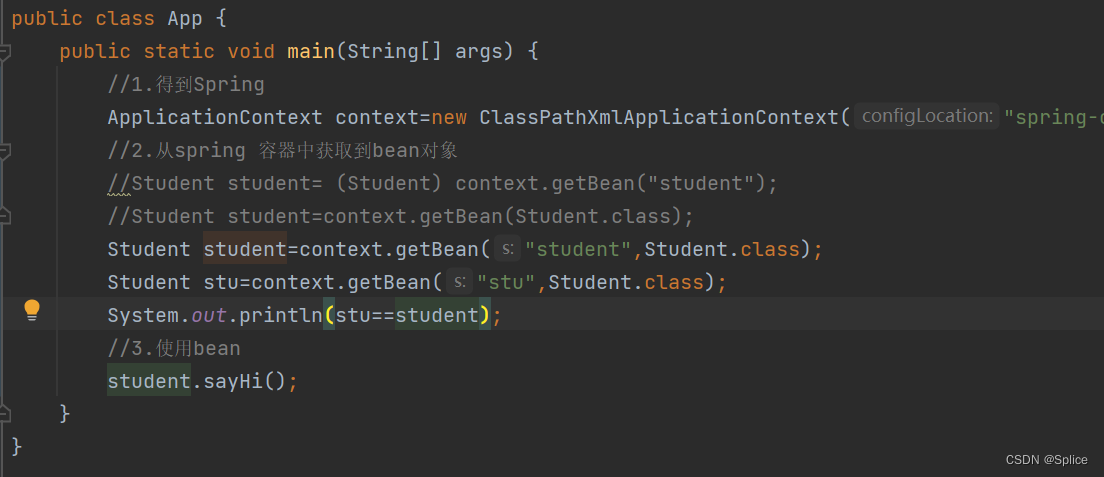
此时打印的结果是:
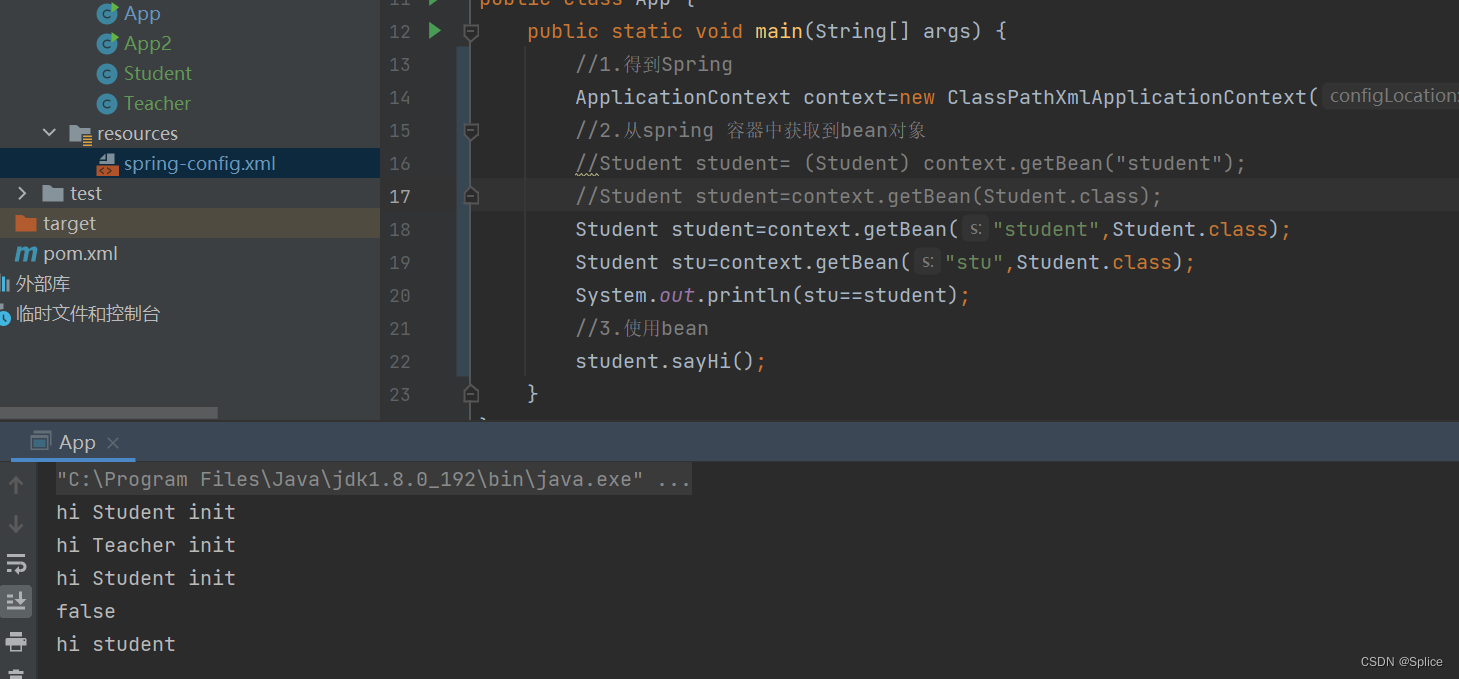
三、Spring中的简单的读取对象(使用类注解)
注解:可以开启提交和回滚事务(一种是在编译器的环境下直接加代码,一种是通过拦截然后开启事务的方式实现)
之前其实是:
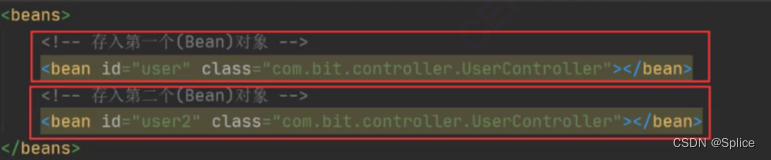
在beans中添加bean,这种方式其实比new更复杂.
此时如果有一种方法,使用注解直接充当sping 的入口.
五大类注解:
1. @Controller
控制器:验证用户请求的数据正确性.(相当于安保系统)
2. @Service
服务:编排和调度具体执行方法的.(客服中心)
3. @Repository
持久层:和数据库进行交互.(执行者)
另外,我们平时所说的DAO层,DAO(Data Access Object)数据访问层,而@Repository就是其中的一种实现
4. @Component
组件:(工具类)
5. @Configuration
配置类: (项目中的一些配置)
使用五大注释:
首先创建一个spring项目:
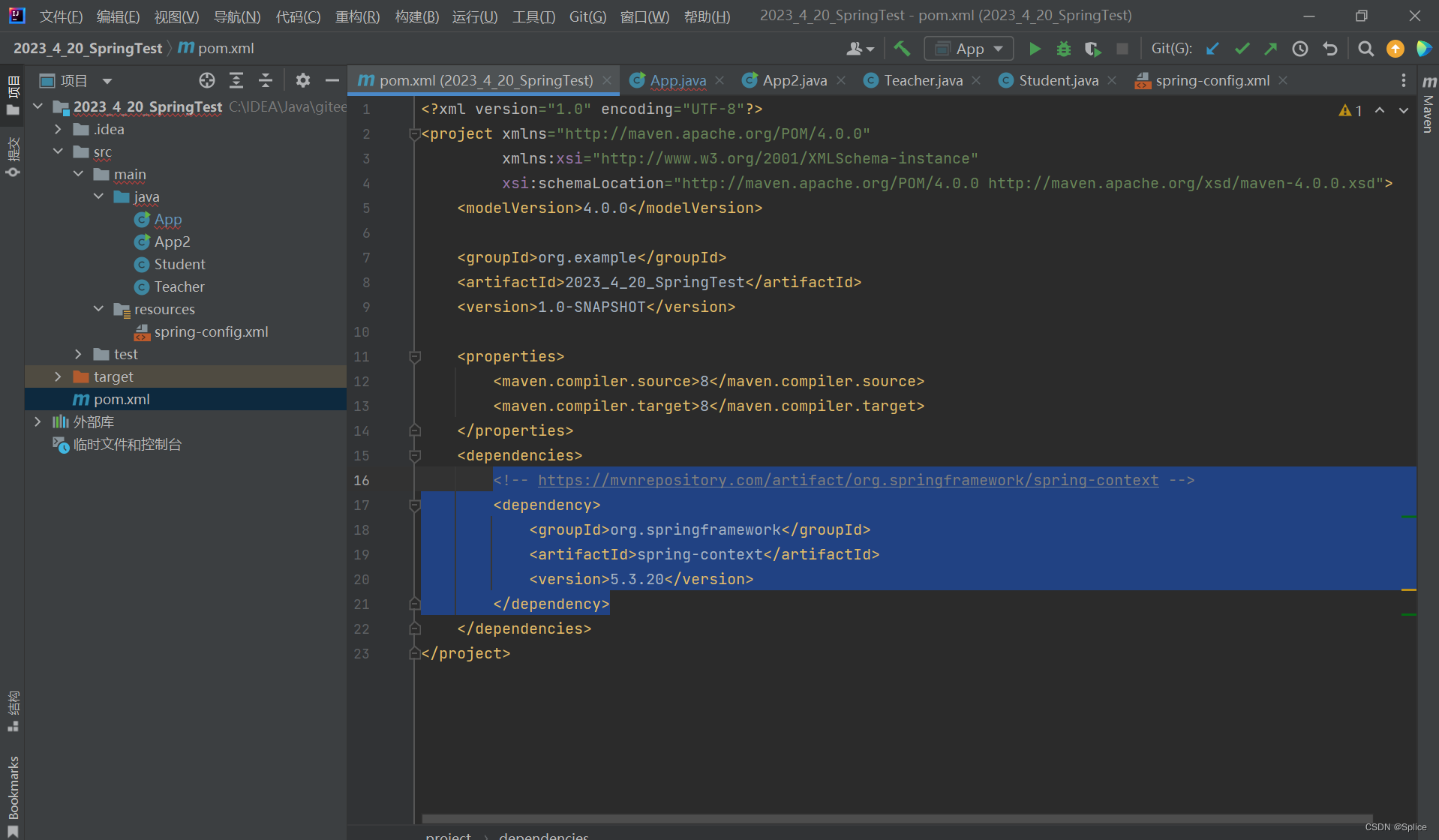
引入依赖等和上面一致.
另外,在使用注释之前还需要做一些准备:
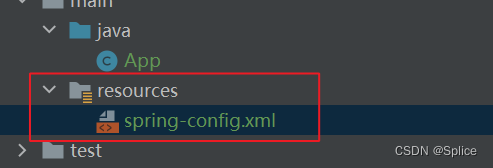
在resources目录底下设置配置文件.
<?xml version="1.0" encoding="UTF-8"?>
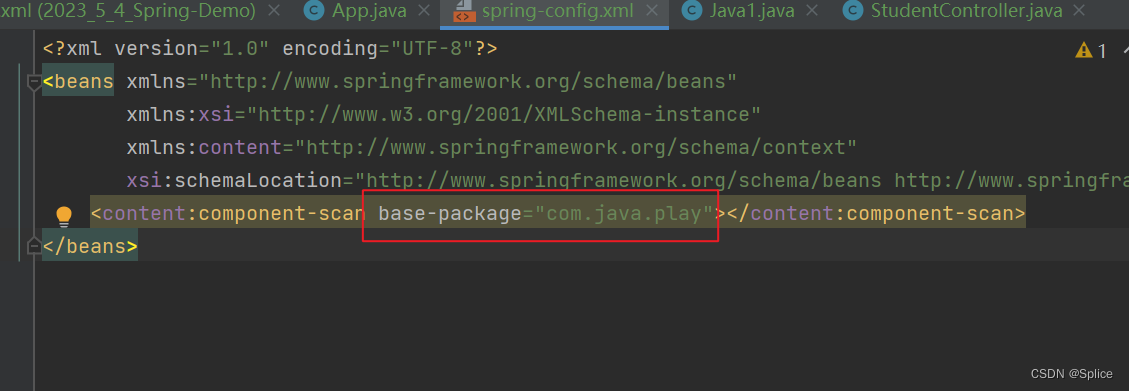
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:content="http://www.springframework.org/schema/context"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd"><content:component-scan base-package="com.bit.service"></content:component-scan>
</beans>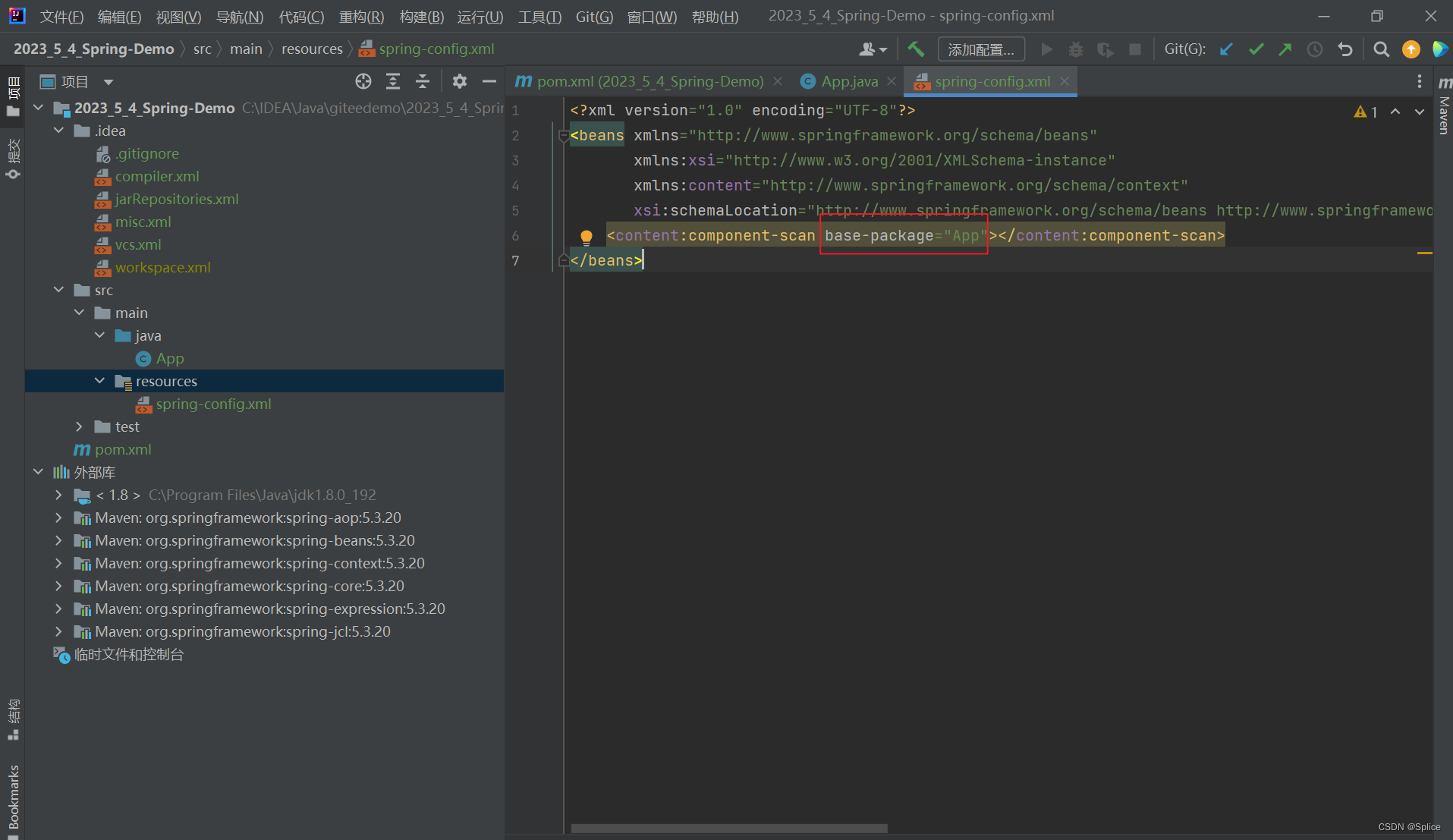
注意此处的红框中是指定的文件夹,就是让spring指定的去扫描文件,这样可以让程序运行的效率更上一层楼.
设置一个类,调用里面的方法,此时这个注释就是充当了之前bean标签的作用.
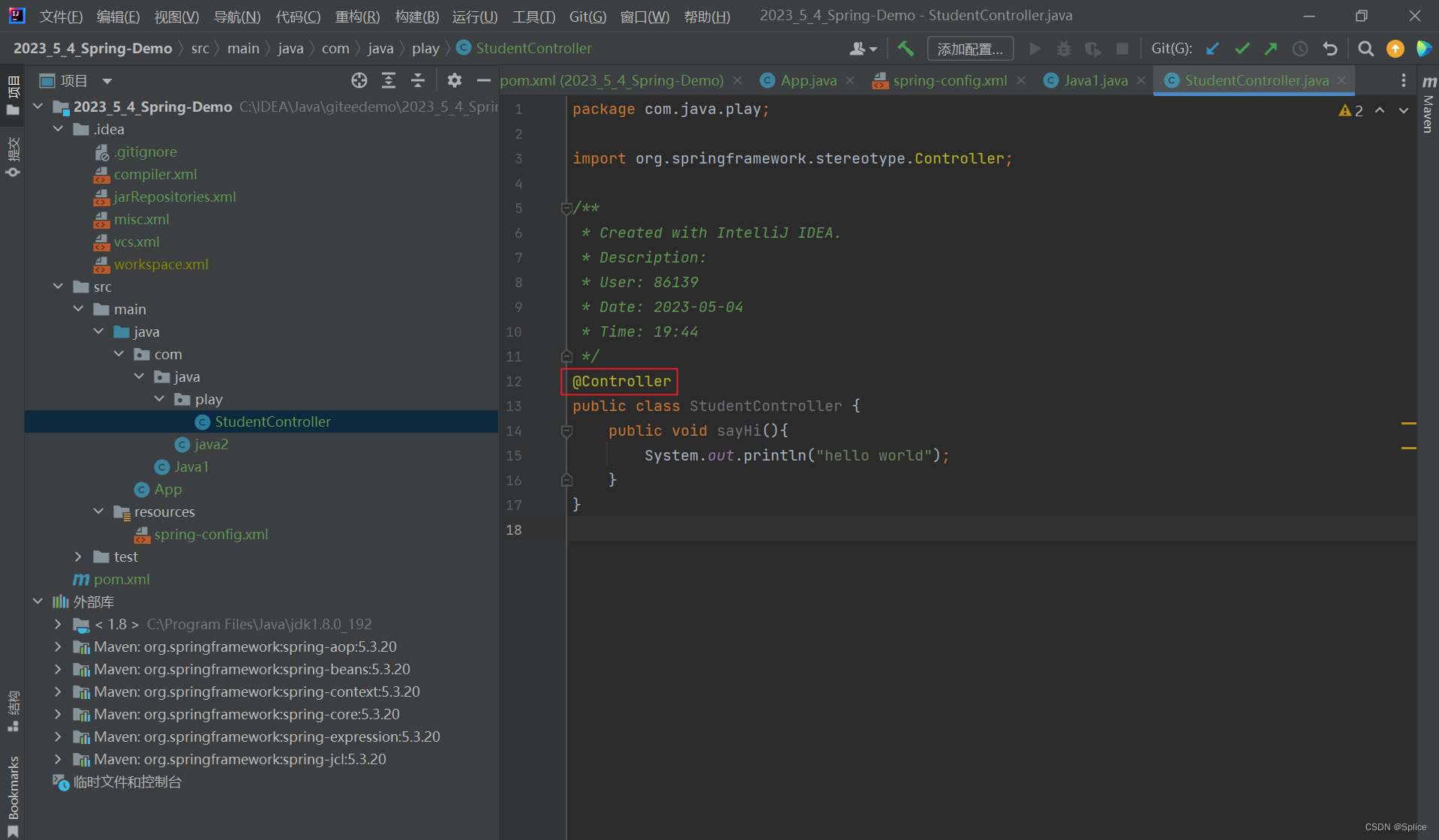
之后编写主类,跟之前的一致:
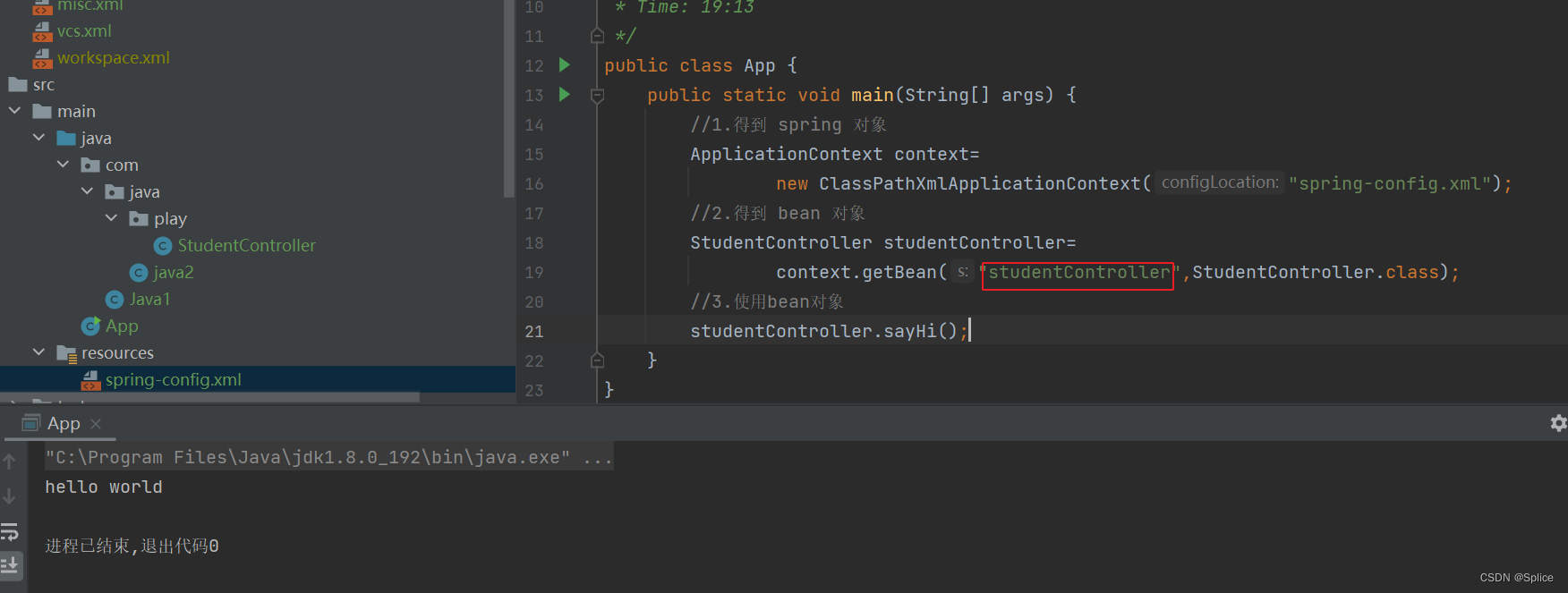
只不过这里的id变为了类名的小驼峰形式.
所以要记住是使用:小驼峰进行访问
Springboot使用方式:
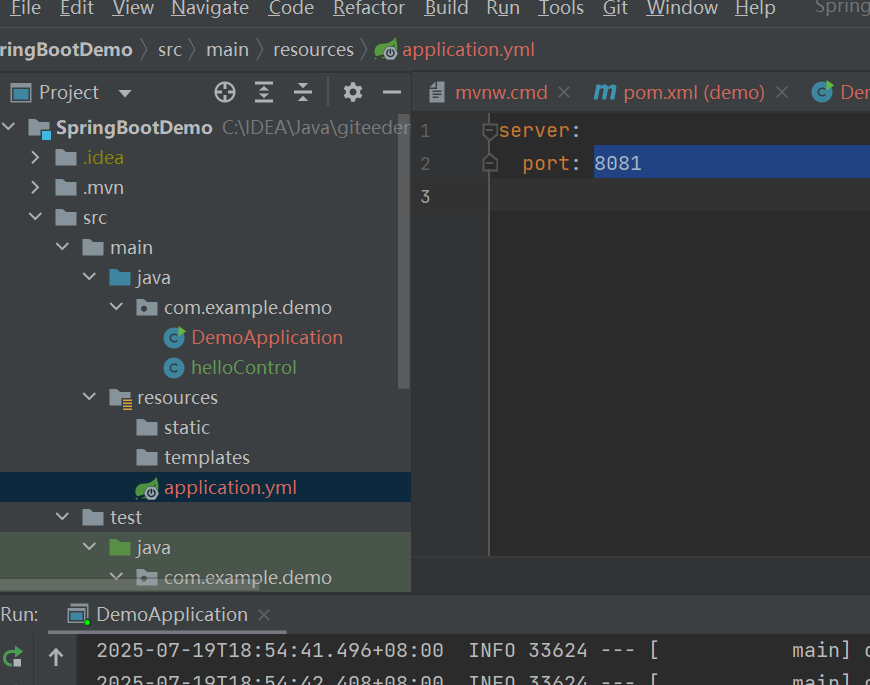
首先这里修改了端口号
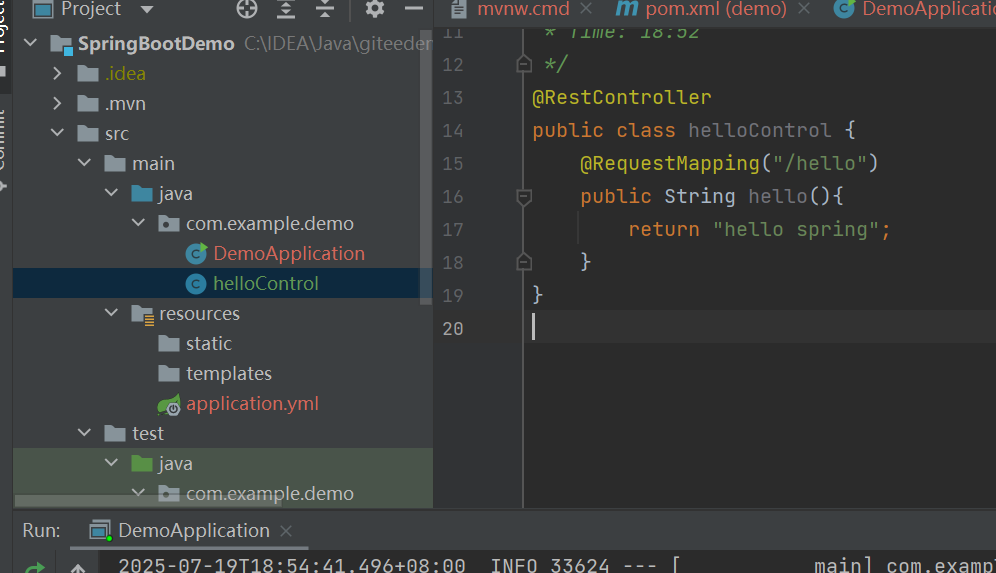
写了一个接口返回hello spring,并设定了url
调用了这个url,成功访问: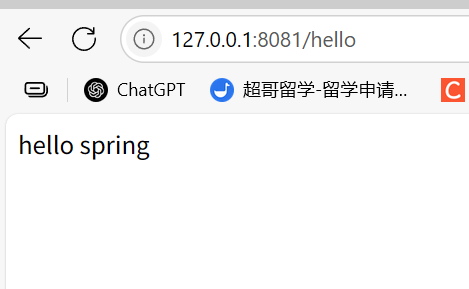

四、什么是MVC:
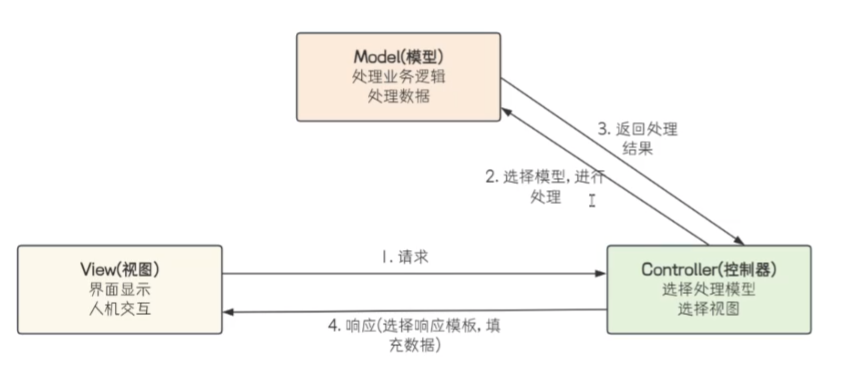
就像面试一样,我去面试的话HR来接待,但相应的面试需要公司负责人进行接触,公司具体项目负责人去找人充当面试官
HR -> view
公司具体项目负责人 -> controller
面试官 -> model
也就是一个接待用户,一个找具体谁来干活,一个干活
五、什么是springMVC:
spring结合自身的特点也创造了一款独特的MVC,符合自身特点的:
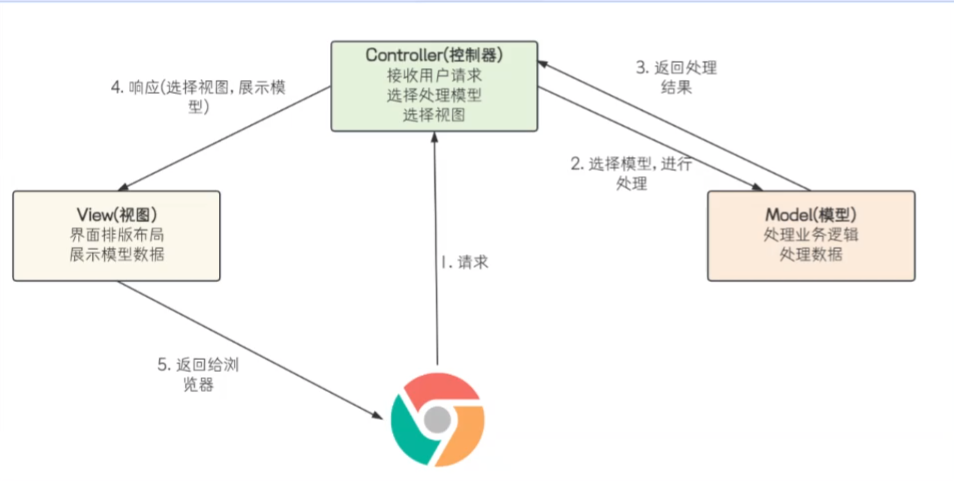
这个也就是,面试人直接去找部门负责人,然后部门负责人去找相对应面试官安排面试,然后面试通过后部门负责人告诉HR面试人面试通过了,让HR给这个人发offer,HR再和面试人交接
六、SpringBoot常用方法:
建立连接
@RequestMapping-类路径
@RestController-spring标识,告诉spring这个是个需要考虑的类
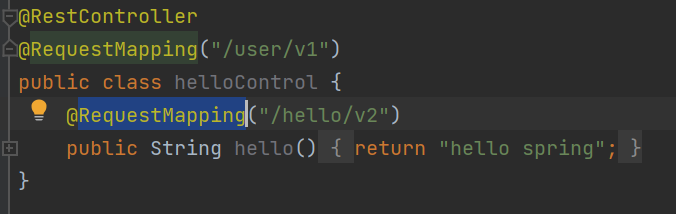
@RequestMapping制造url,我们要想访问对应页面需要再html页面中填入对应url即可成功进行交互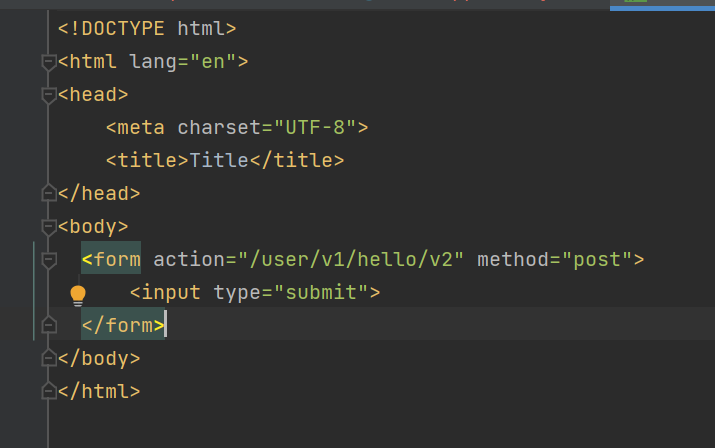
另外@RequestMapping可以设定接收信息的方法是get还是post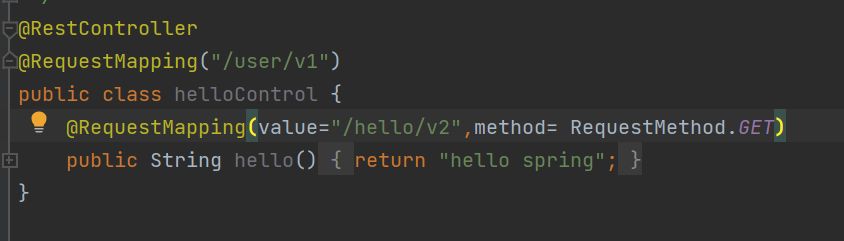
也有@GetMapping只能接受get方法:
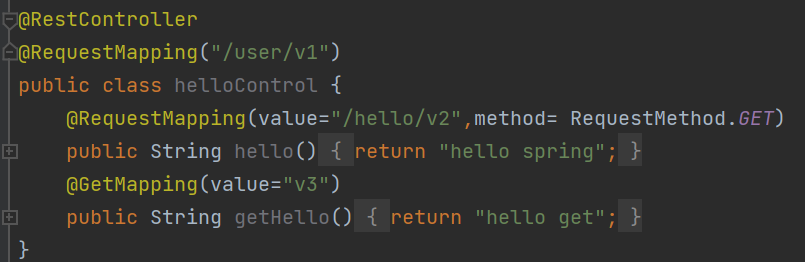
也有@PostMapping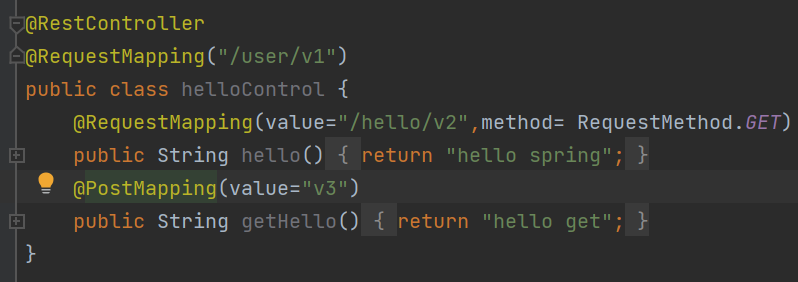
另外还有前后端传参:
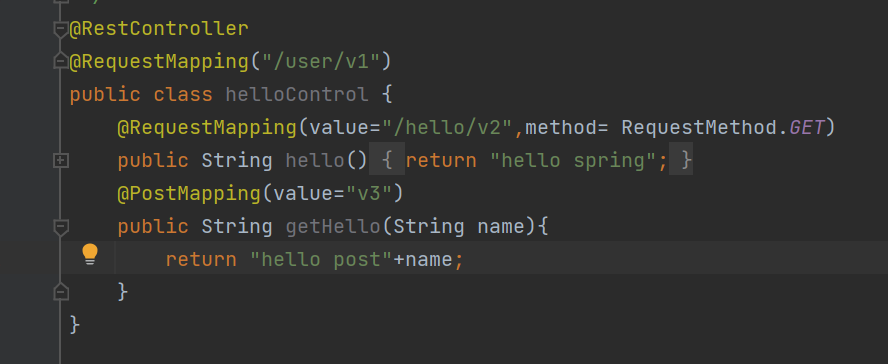
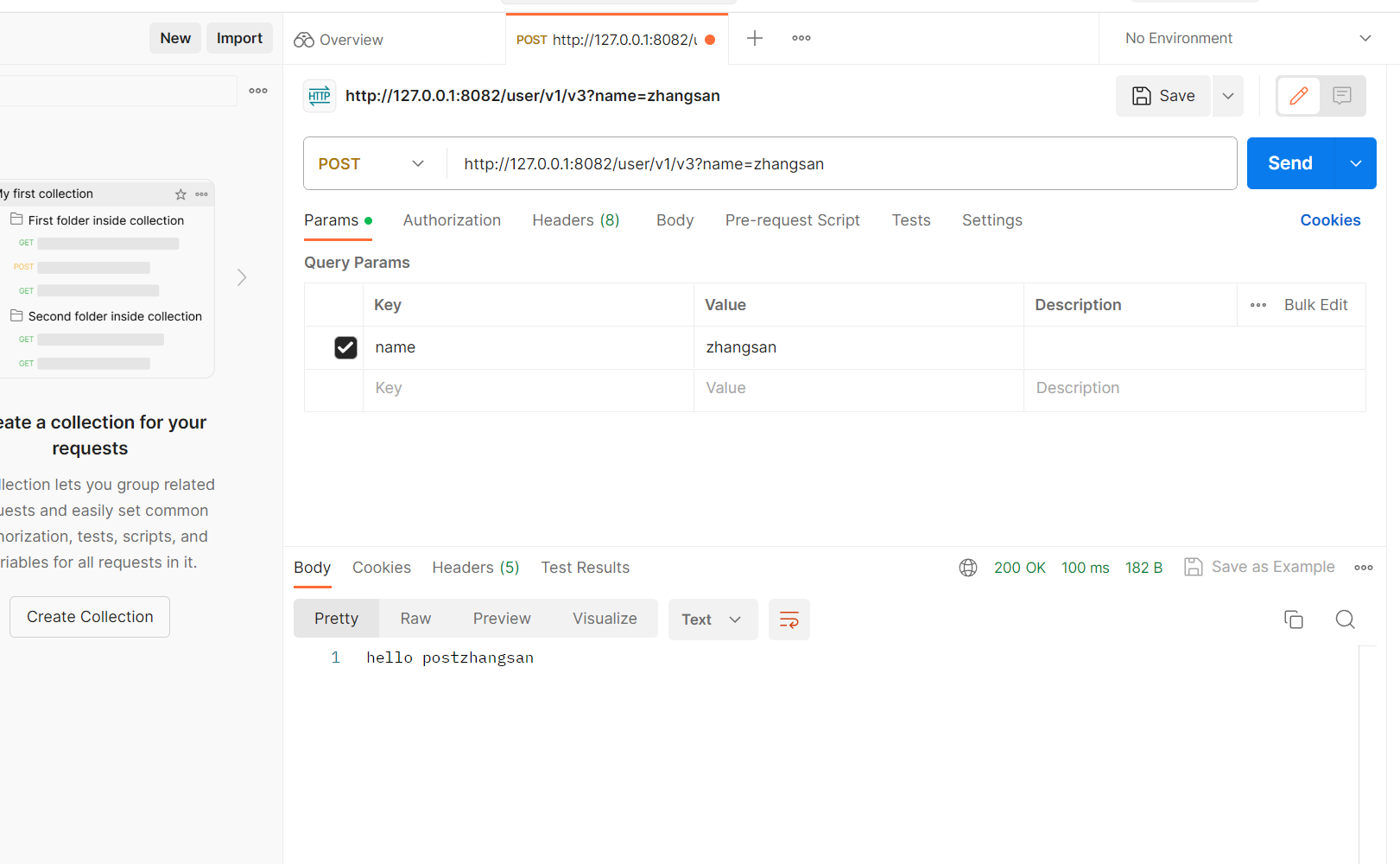
也可以传两个参数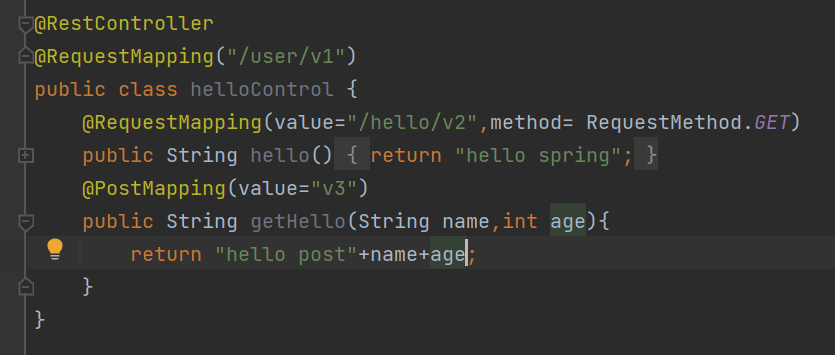
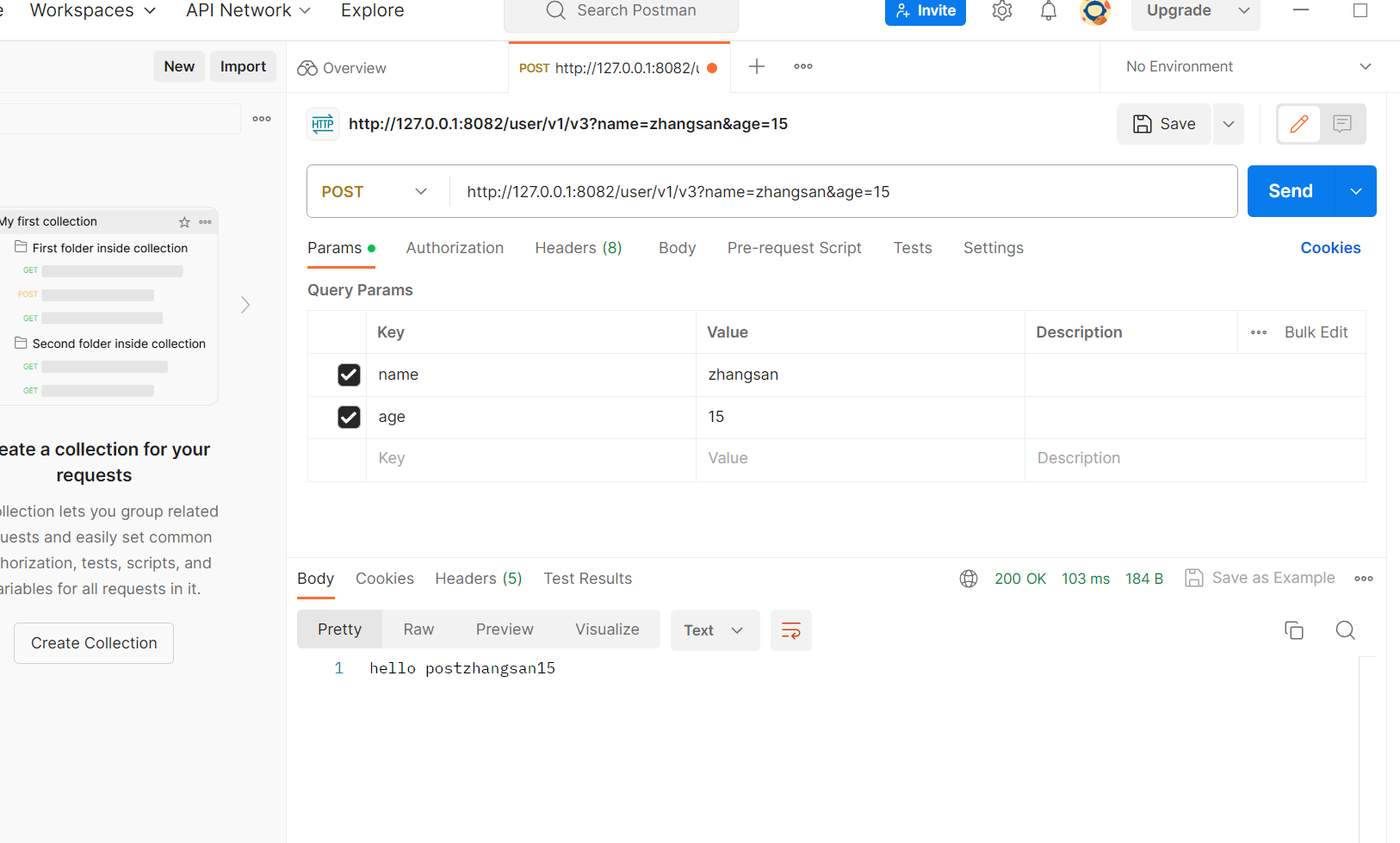
servlet和springboot的区别: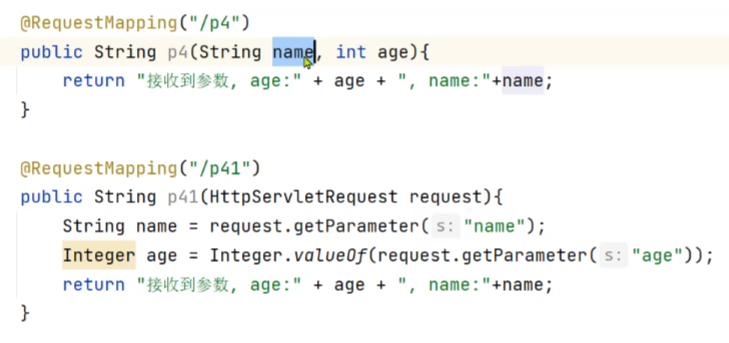
前后端传递多个参数:
现在企业中通常传递多个对象的方式是这样的:
首先封装对象:
package com.example.demo;/*** Created with IntelliJ IDEA.* Description:* User: 86139* Date: 2025-07-21* Time: 21:33*/
public class User {private String name;private Integer age;private Integer gender;public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}public Integer getGender() {return gender;}public void setGender(Integer gender) {this.gender = gender;}@Overridepublic String toString() {return "User{" +"name='" + name + '\'' +", age=" + age +", gender=" + gender +'}';}
}
然后直接打印对象:
@RequestMapping("/p1")public String test(User user){return "user:"+user}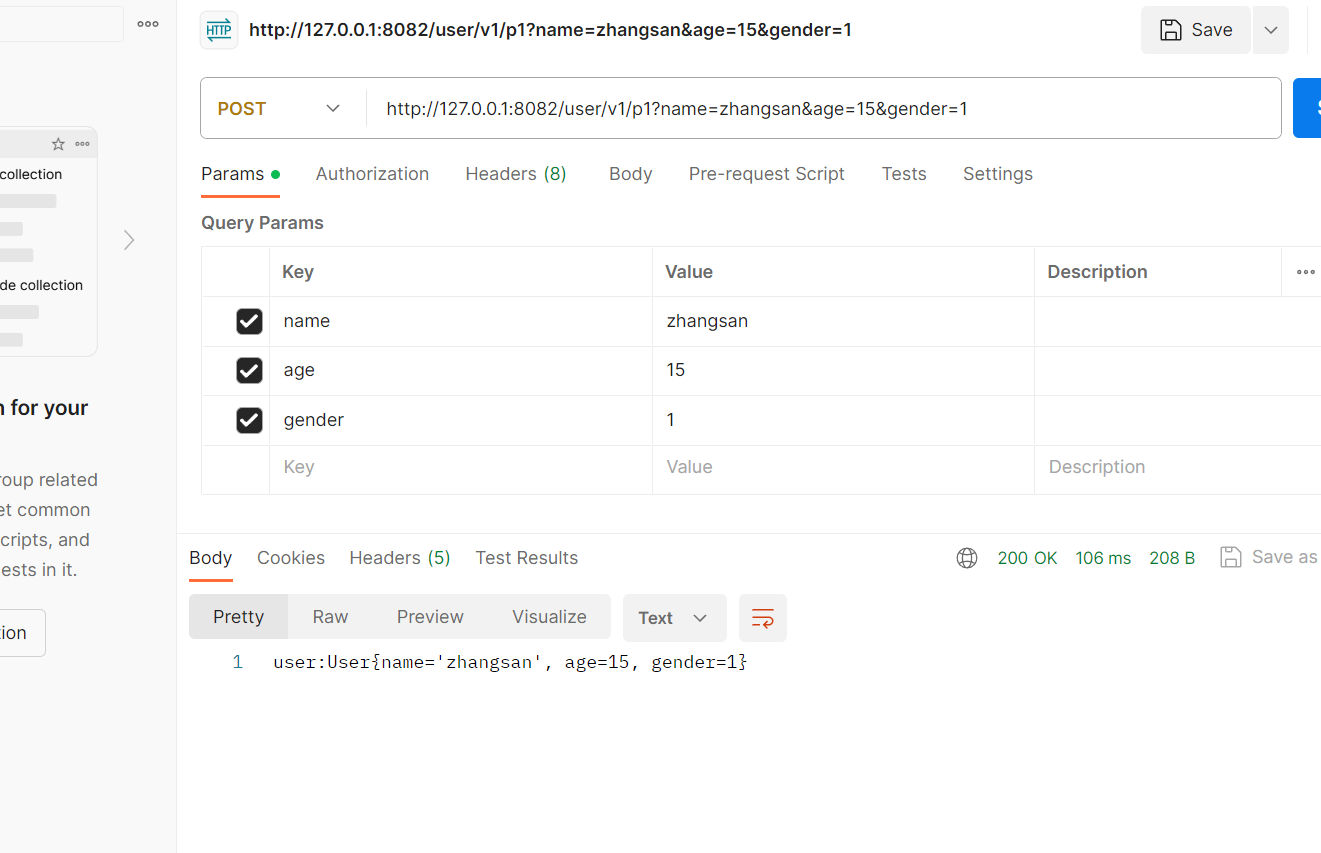
如果前端想要传的'name'与后端传的这个'username'不一样,也就是后端不想要用前端传输的这个name进行存储:
@RequestMapping("/p2")public String test2(@RequestParam("userName") String name){return "name:"+name;}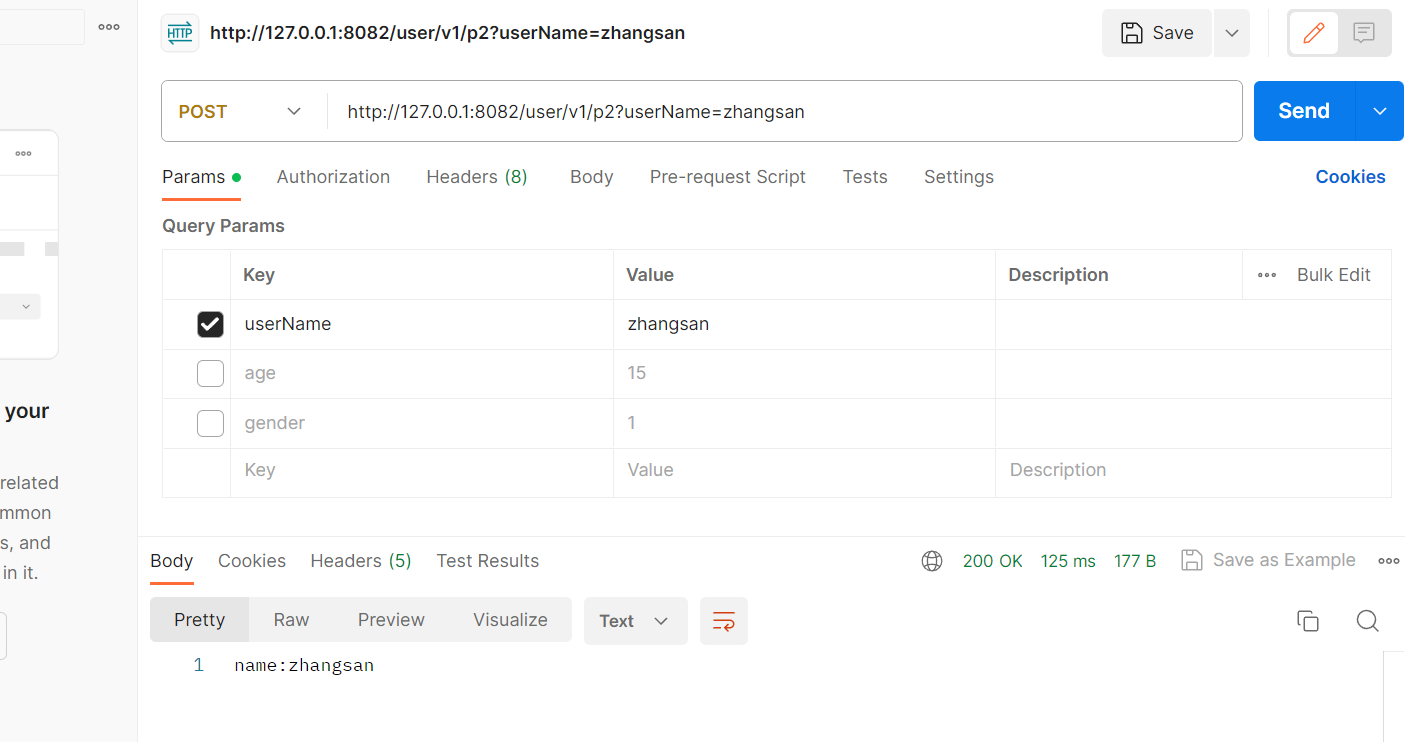
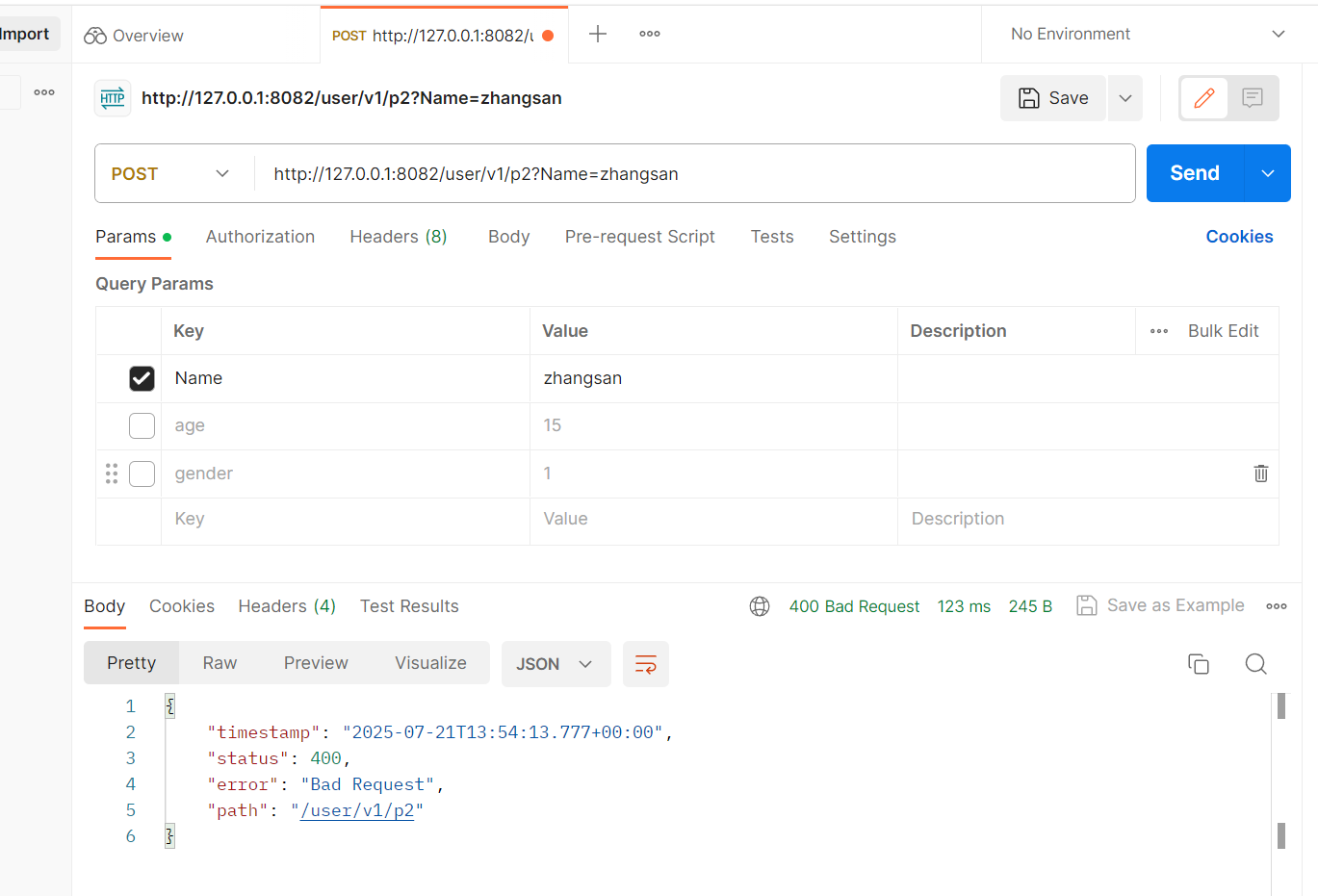
但如果设定了这个参数绑定@RequestParam后再传之前的变量名,则显示报错400
但是这样太绝对了,如果收到不一致的值直接报错,会导致程序结束,我们想要收到不一致的值返回false怎么办呢?
如果不写这个required的话就默认是value.
@RequestMapping("/p2")public String test2(@RequestParam(value="userName",required = false) String name){return "name:"+name;}这样就可以了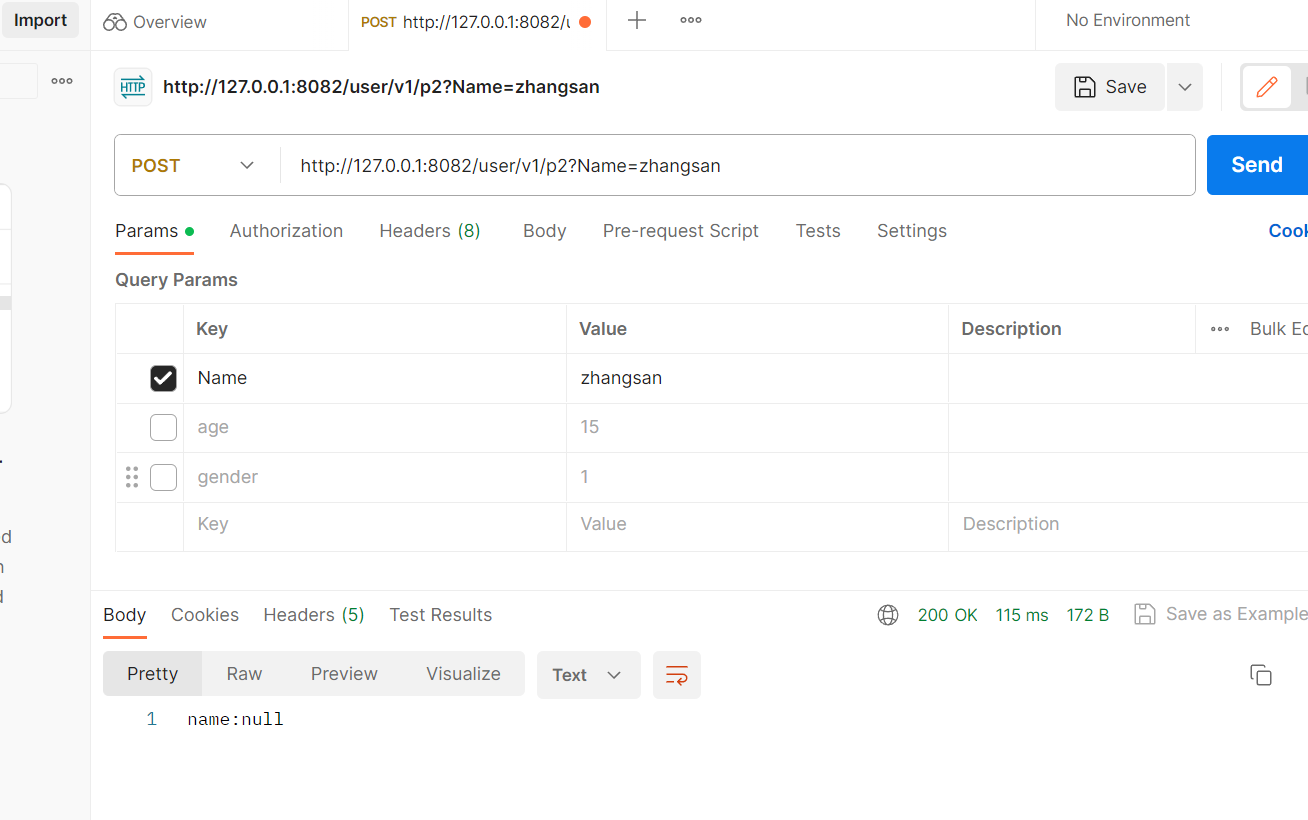
通过数组传参:
@RequestMapping("/p3")public String test3(String[] arr){return "name:"+ Arrays.toString(arr);}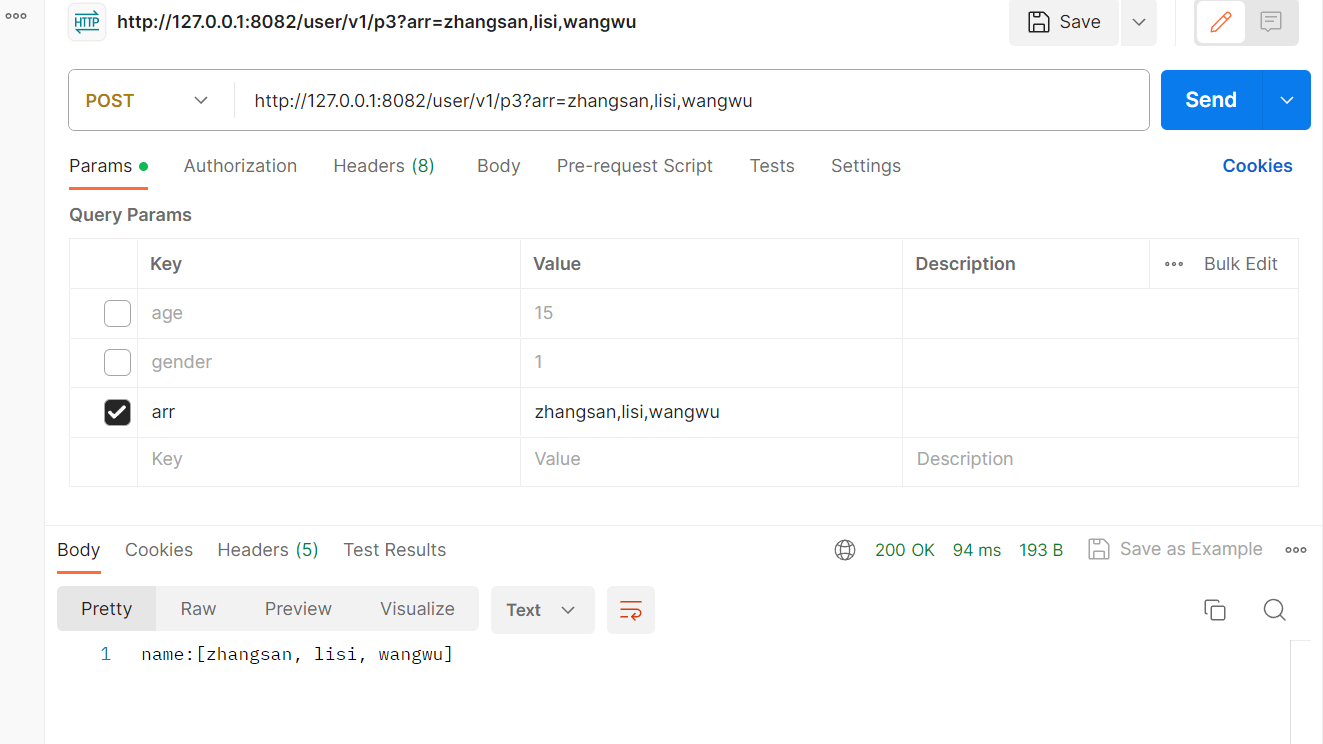
也可以这样: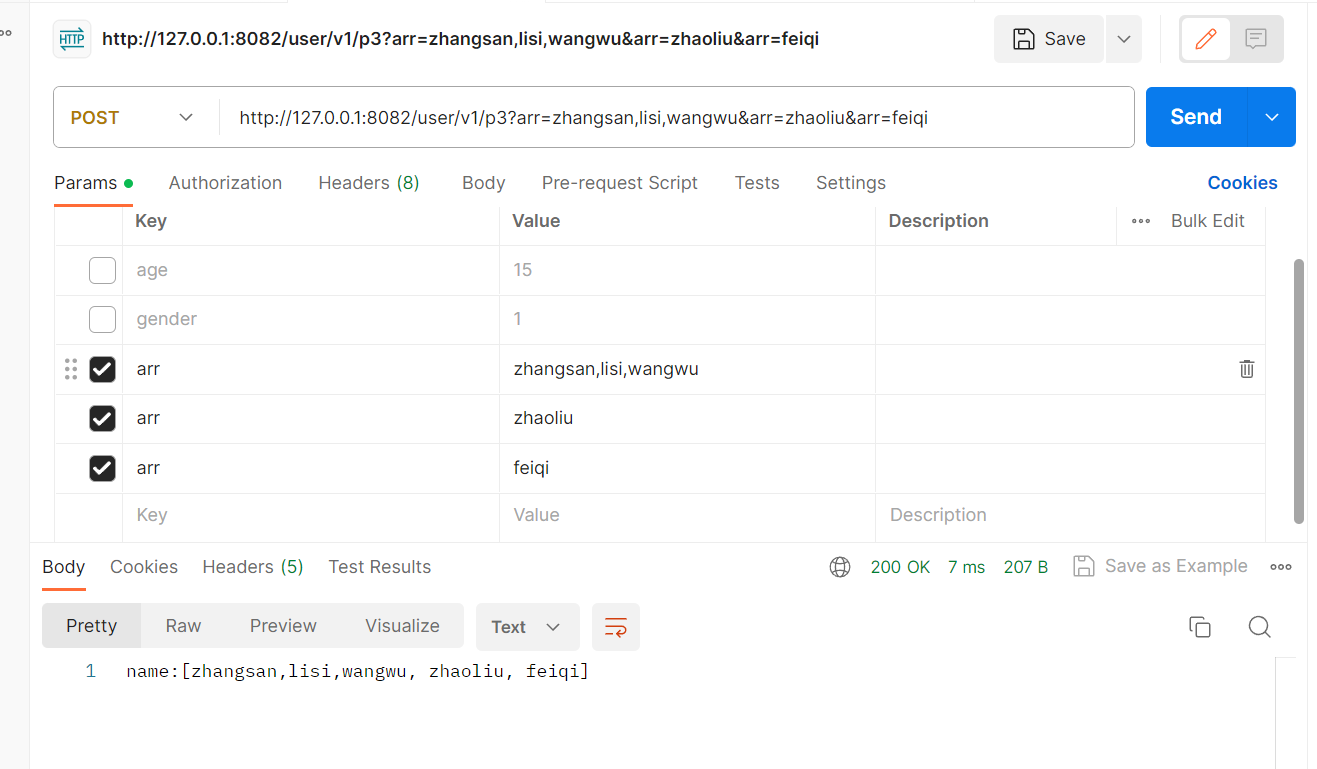
当前端没有指定数据进行传参时,我们后端可以手动参数绑定将其设置为数组:
@RequestMapping("/p4")public String test4(@RequestParam List<String> list){return "name:"+ list;}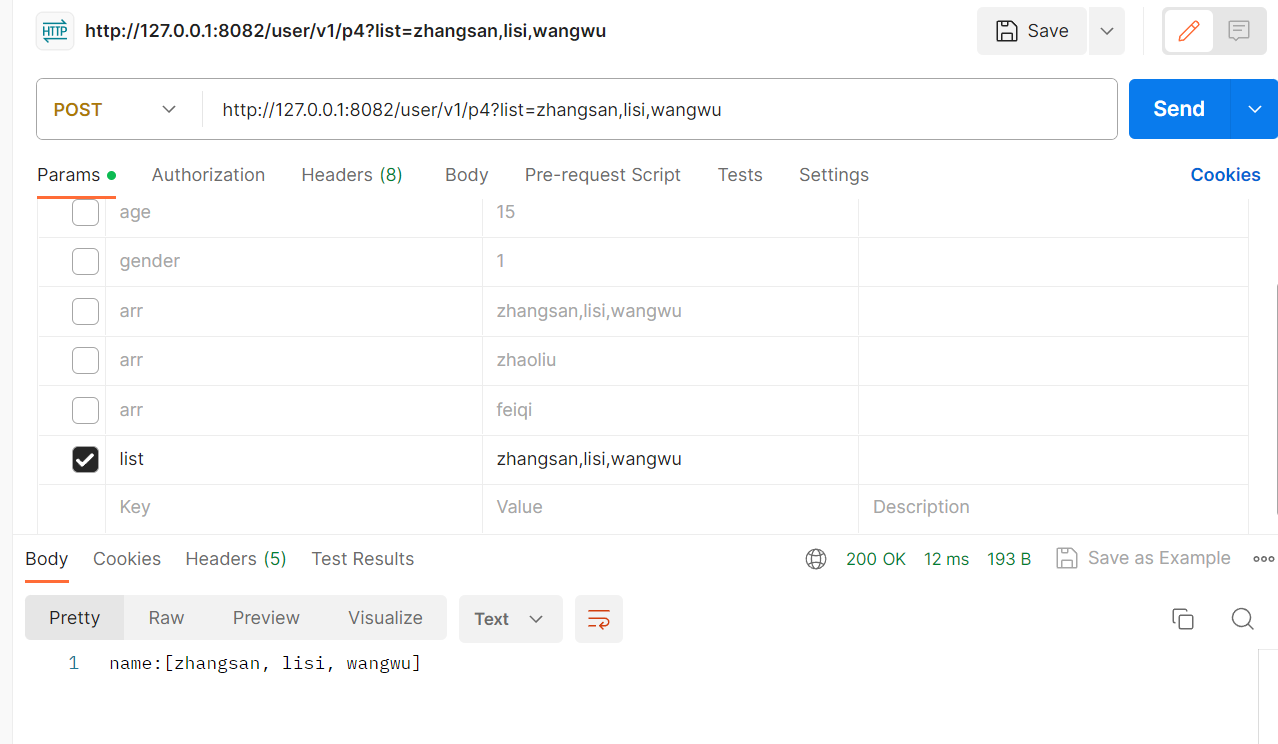
idea中对象转JSON格式:
public class test {public static void main(String[] args) throws JsonProcessingException {ObjectMapper objectMapper=new ObjectMapper();User user=new User();user.setName("zhangsan");user.setAge(20);user.setGender(1);String s=objectMapper.writeValueAsString(user);System.out.println(s);}}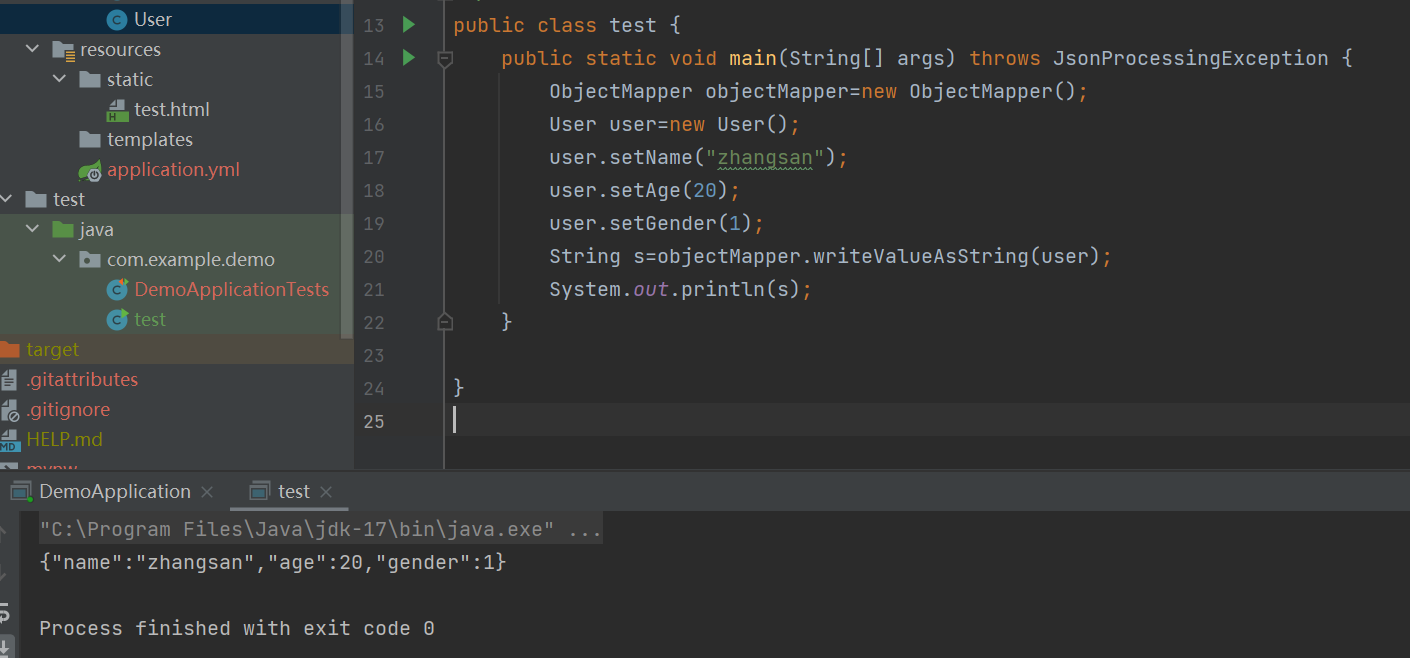
idea中Json转对象:
public class test {public static void main(String[] args) throws JsonProcessingException {ObjectMapper objectMapper=new ObjectMapper();User user=new User();user.setName("zhangsan");user.setAge(20);user.setGender(1);String s=objectMapper.writeValueAsString(user);
// System.out.println(s);User user1=objectMapper.readValue(s,User.class);System.out.println(user1);}}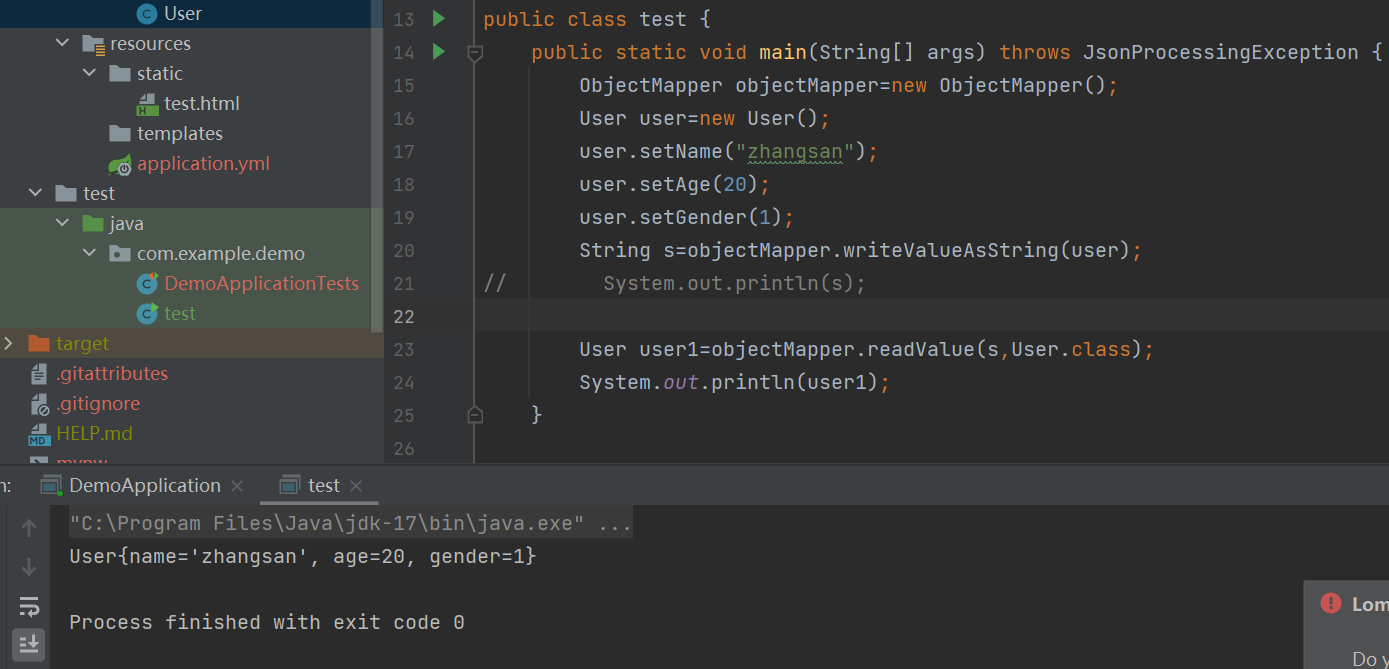
前端传递JSON和传递对象的区别:

而我们在场景中经常遇到的是接收JSON数据,如何更加简单的接收Json格式数据将其转化为对象呢?
转化Json格式为对象:
@RequestMapping("/p5")public String tset5(@RequestBody User user){return "user:"+user;}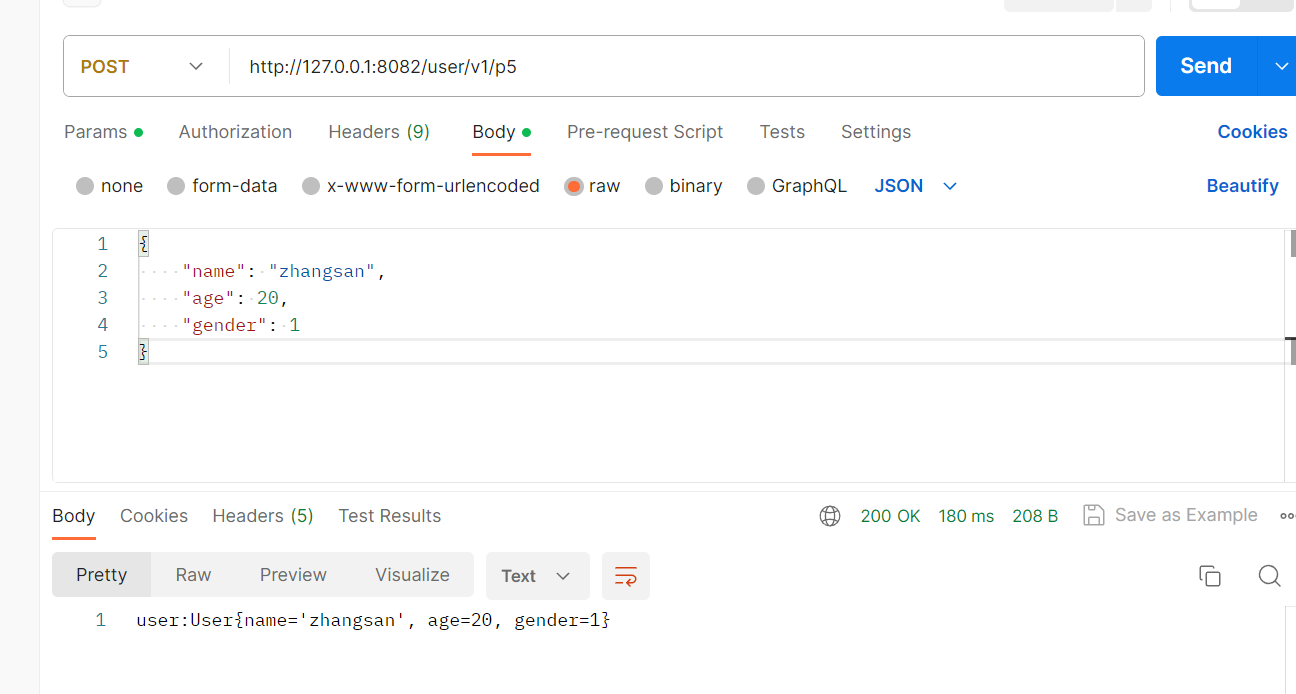
获取url中id:
@RequestMapping("/p6/{id}")public String test6(@PathVariable("id")String id){return "id:"+id;}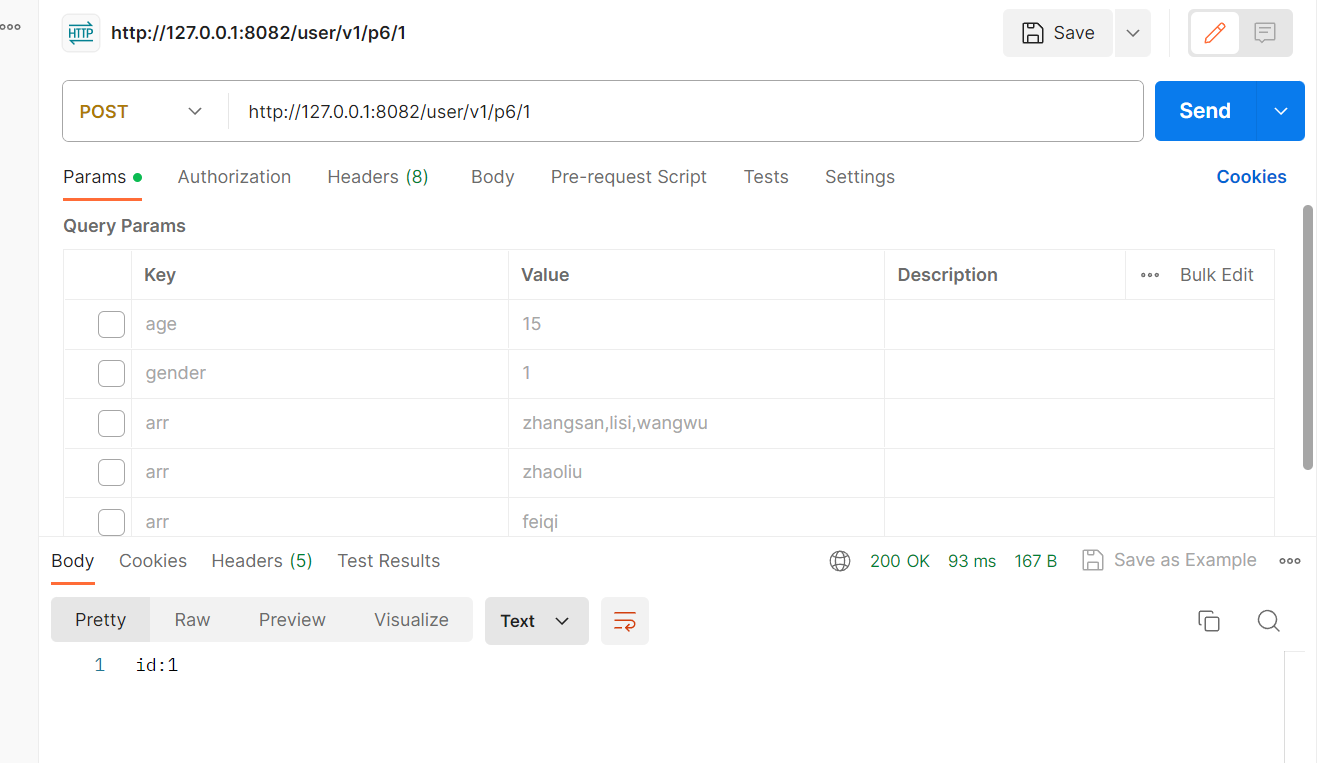
也可以获取多个参数:
@RequestMapping("/p6/{id}/{name}")public String test6(@PathVariable("id")String id,@PathVariable("name")String name){return "id,name:"+id+name;}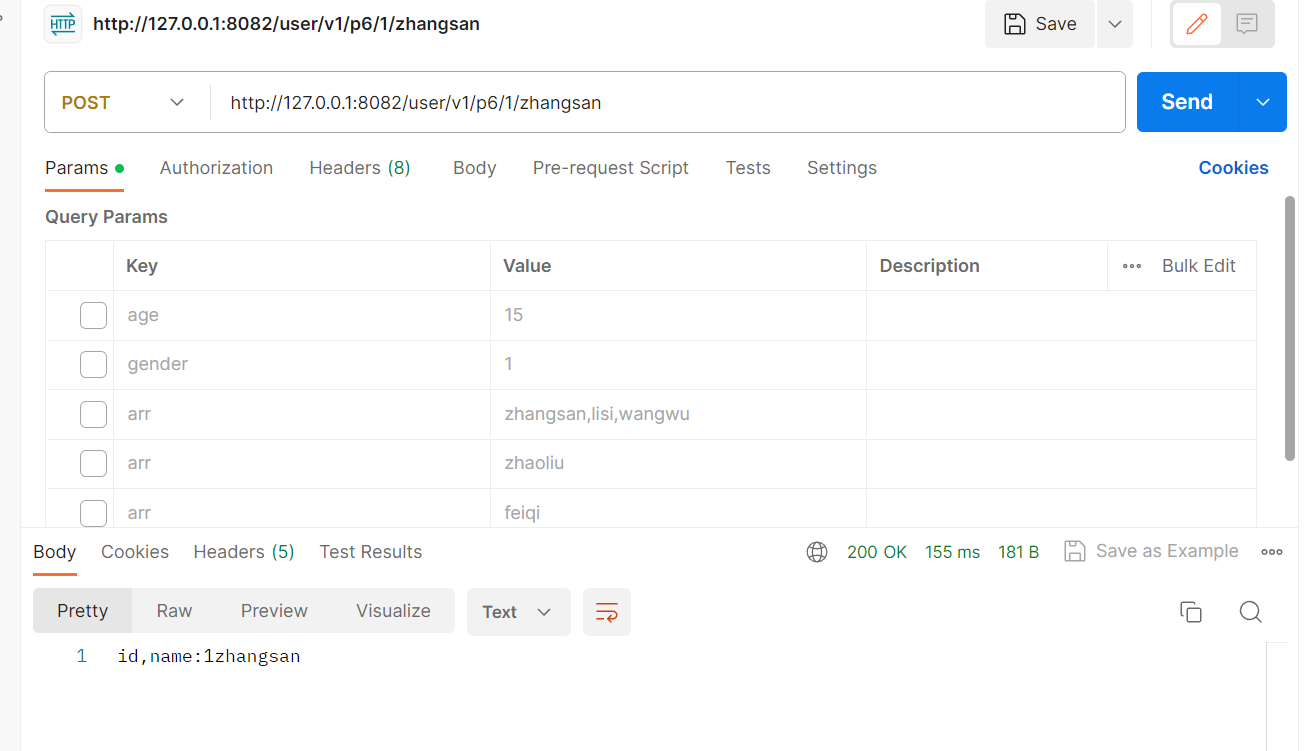
上传文件及其重命名:

七、cookie:
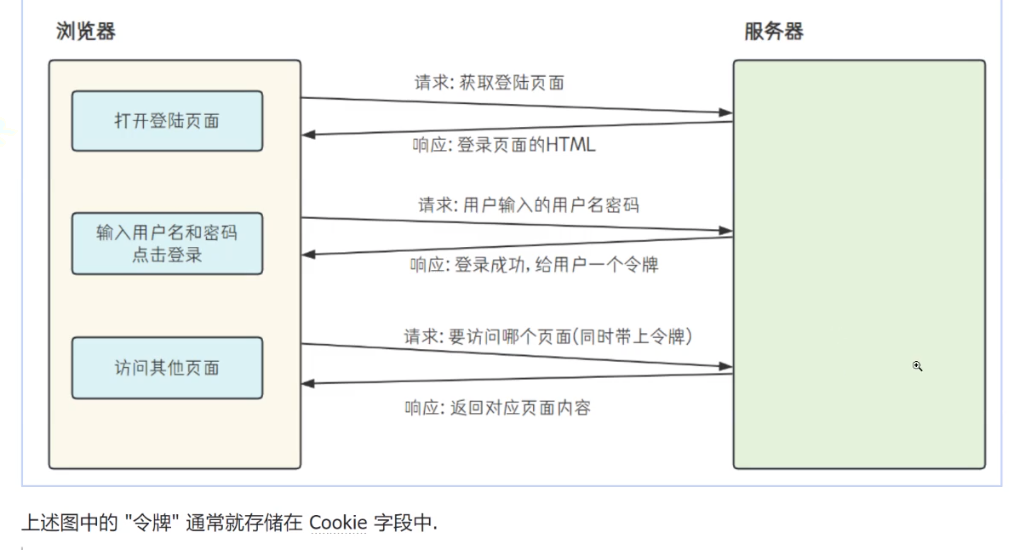
八、session:

九、Cookie和Session 的区别:

如何获取cookie值:
@RequestMapping("/helloCookie")public String Cookie(HttpServletRequest httpServletRequest){Cookie[] cookies=httpServletRequest.getCookies();for(Cookie cookie:cookies){if(cookie != null) {System.out.println(cookie.getName()+":"+cookie.getValue());}else{break;}}return "cookie获取成功!!!";}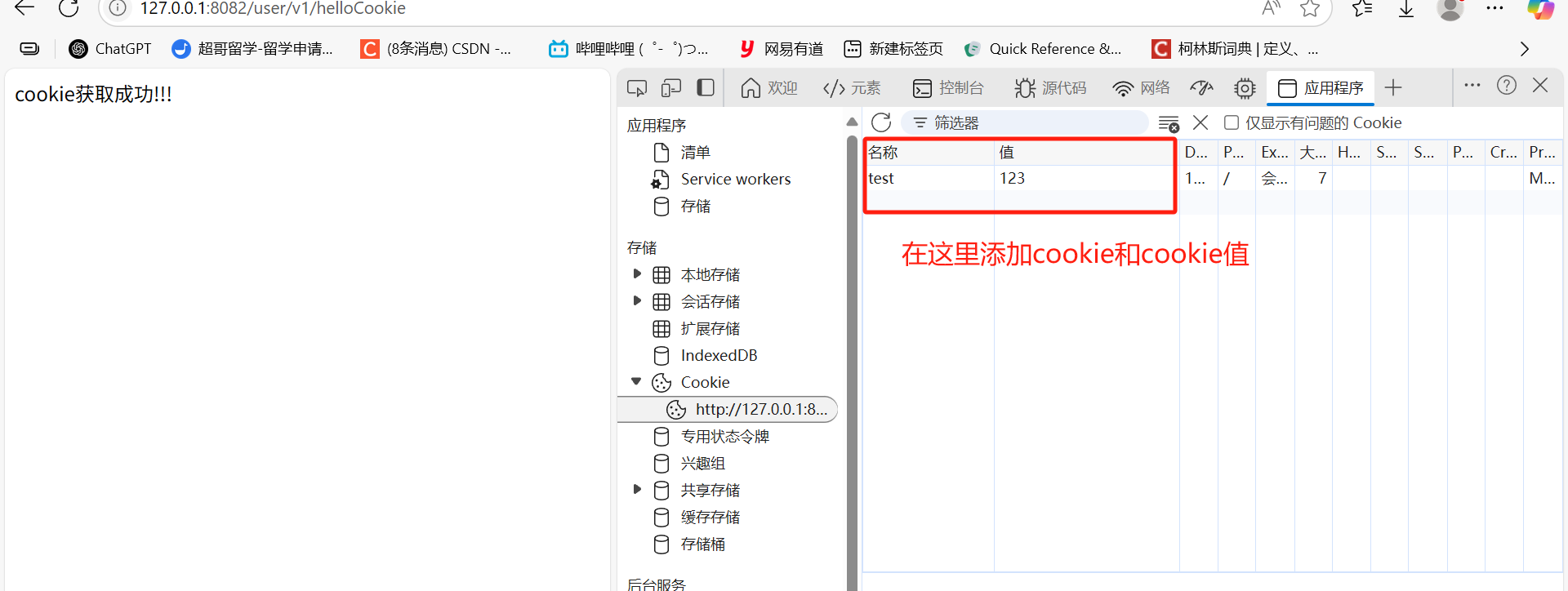
我们可以看到在服务器控制台是可以正常打印cookie值的: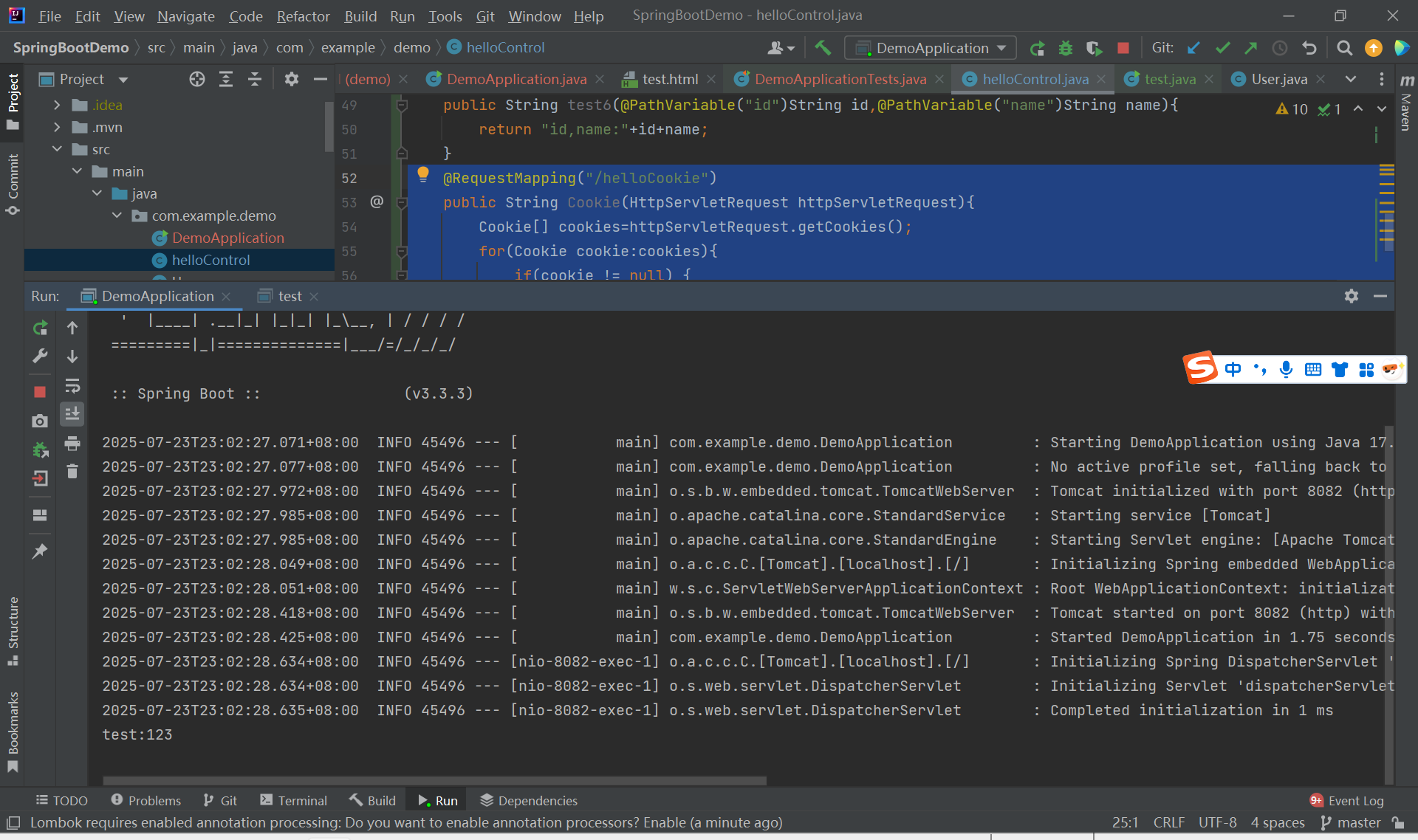
另外还有一种获取cookie值的方法:
直接将cookie名写入代码:
@RequestMapping("/helloCookie2")public String Cookie2(@CookieValue("test")String test){return "test:"+test;}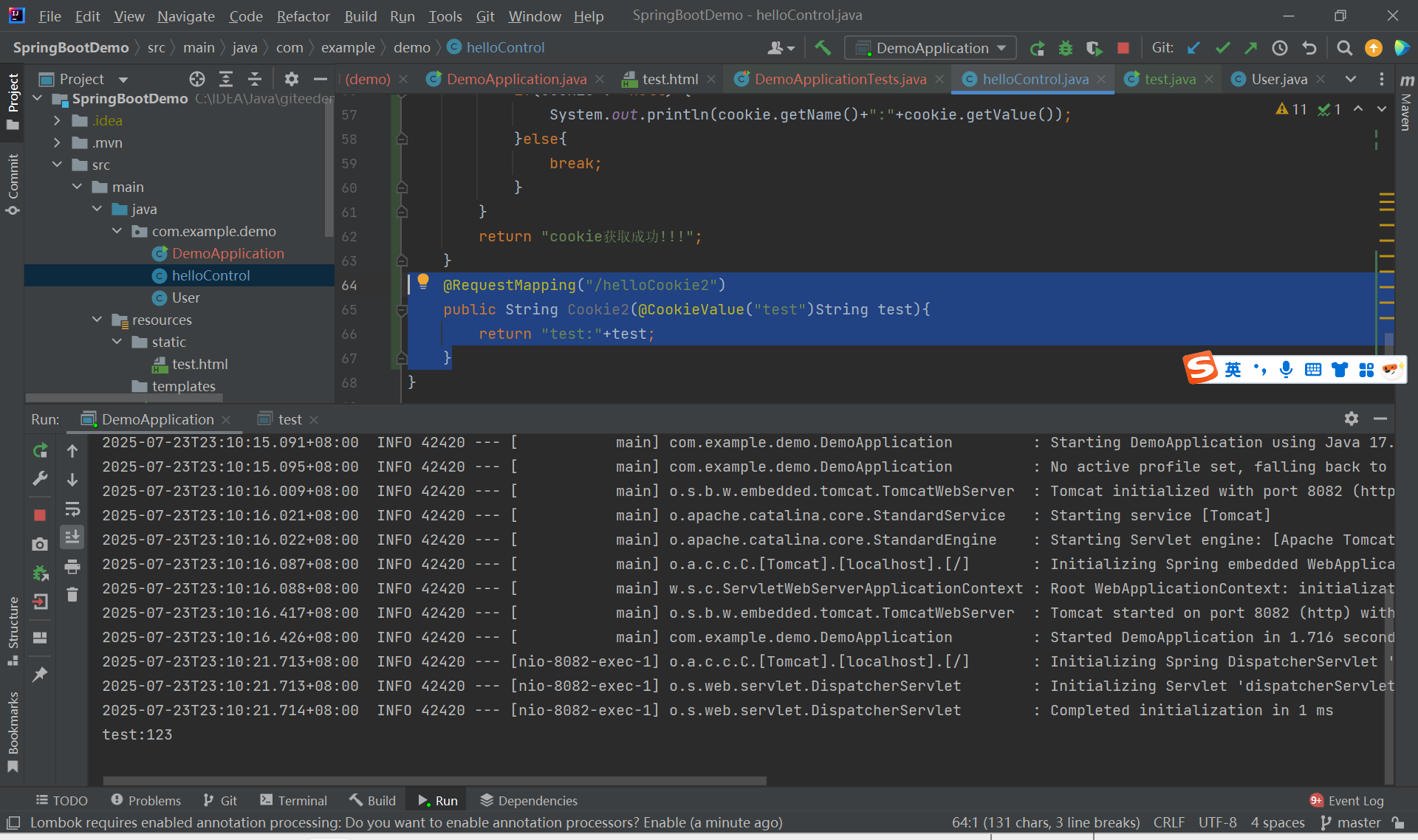
set以及get session:
@RequestMapping("/setSeesion")public String Session2(HttpServletRequest httpServletRequest){HttpSession session=httpServletRequest.getSession();session.setAttribute("userName","zhangsan");session.setAttribute("age",15);return "设置session成功";}@RequestMapping("/getSeesion")public String Session1(HttpServletRequest httpServletRequest){HttpSession session=httpServletRequest.getSession();String userName=(String)session.getAttribute("userName");System.out.println(session.getAttribute("age"));return "从cookie中获取值,session:"+userName;}首先模拟客户端建立cookie输入userName与age,然后生成了session
然后再重session中重新获取组成session的cookie:

这样获取session也行:
优化一下:

获取session有三种方式,可以根据应用场景进行选择.
User-Agent:
User-Agent是跟着一个session走的,后台需要知道这个人的喜好以及很多个人信息,就存储在User-Agent中,而想要获取User-Agent也有两种方法:
@RequestMapping("/User-Agent1")public String agent1(HttpServletRequest httpServletRequest) {String user = httpServletRequest.getHeader("User-Agent");return "User-Agent:" + user;}@RequestMapping("/User-Agent2")public String agent2(@RequestHeader("User-Agent")String user) {return "User-Agent:"+user;}
上面应用的几乎都是spring 中request的功能,接下来我们要研究的就是response的功能了:
十、response
如果想要直接通过后端代码进行前端的页面跳转应该怎么办呢?
@Controller
@RequestMapping("/response")
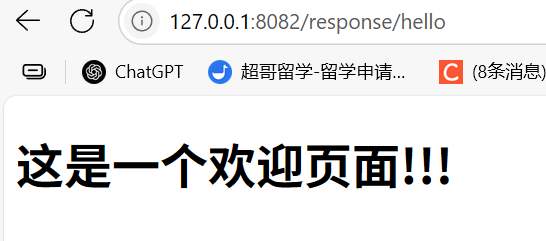
public class send {@RequestMapping("/hello")public String send(){return "/hello.html";}
}
此处用的标签是@controller而不是@Restcontroller,它俩的关系是@Restcontrollers是在@controller的基础上完善的:
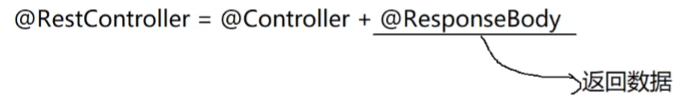
所以说返回数据 -> @ResponseBody
返回页面 -> @Controller
@ResponseBody@RequestMapping("/this is data")public String data(){return "data.html";}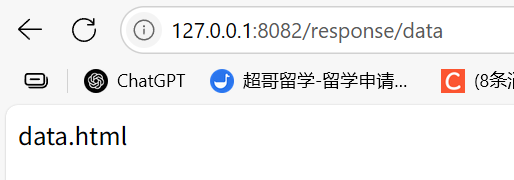
返回Json:
@ResponseBody@RequestMapping("/returnJson")public User returnJson(){User user=new User();user.setName("zhangsan");user.setAge(20);user.setGender(1);return user;}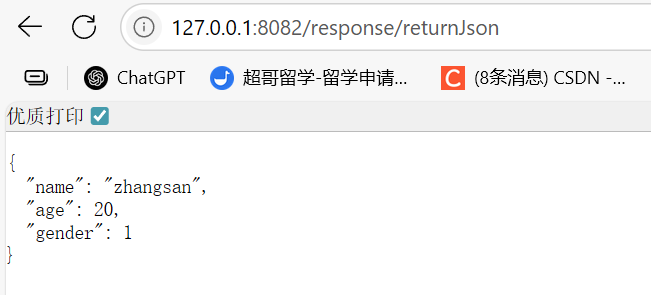
设置状态码:
@ResponseBody@RequestMapping("/returnJson")public User returnJson(HttpServletResponse httpServletResponse){User user=new User();user.setName("zhangsan");user.setAge(20);user.setGender(1);httpServletResponse.setStatus(500);return user;}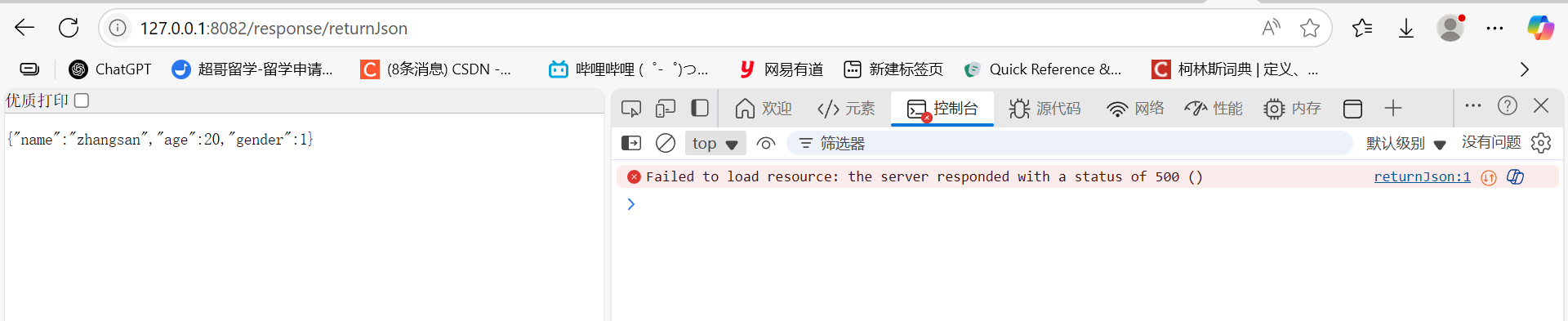
虽然程序不会结束,但是会返回一个500的状态码
设置Header:
这个主要就是能改变header中的传输的信息的类型: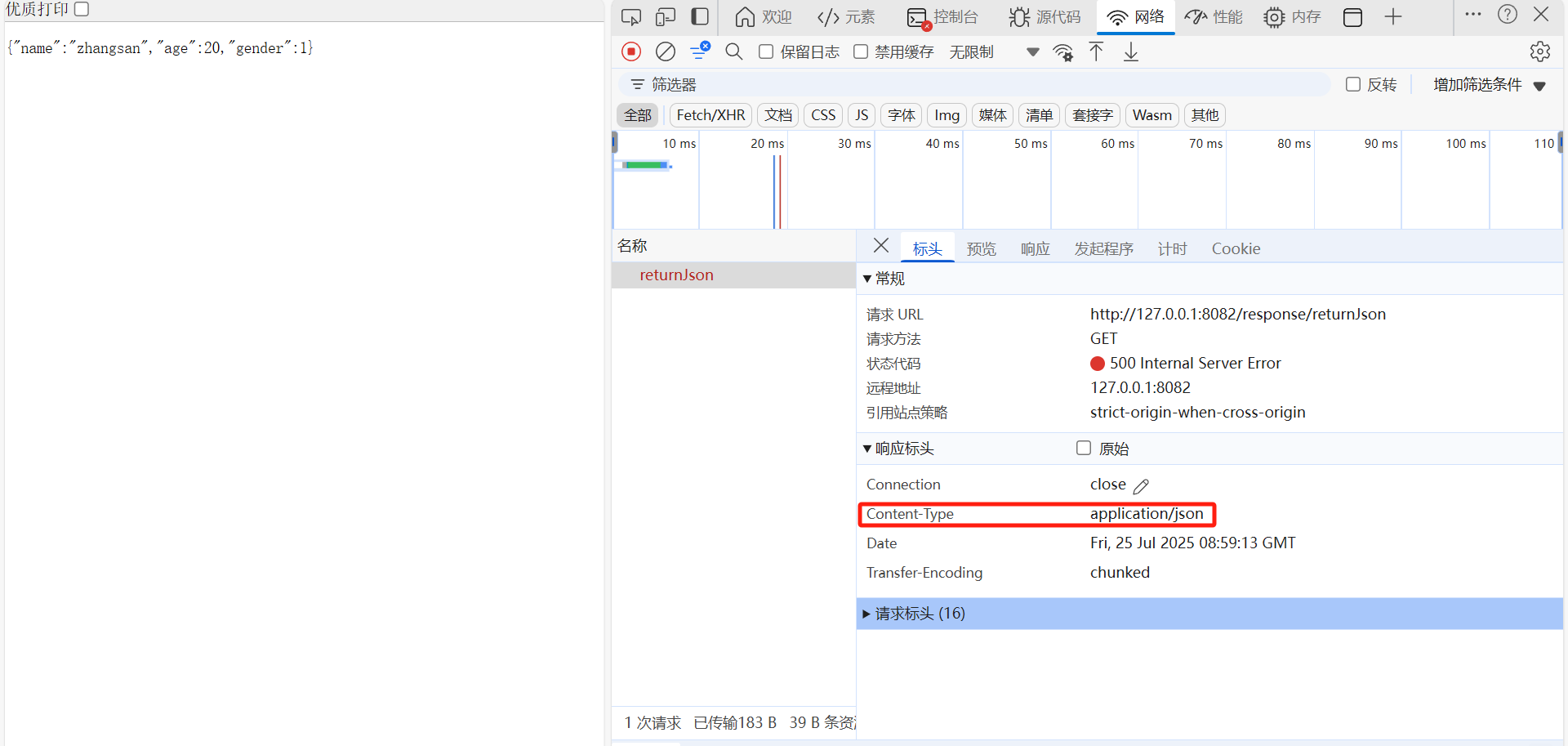
@ResponseBody@RequestMapping(value="/setHeader",produces = "application/json")public String setHeader(){return "{\"name\":\"zhangsan\",\"age\":20,\"gender\":1}";}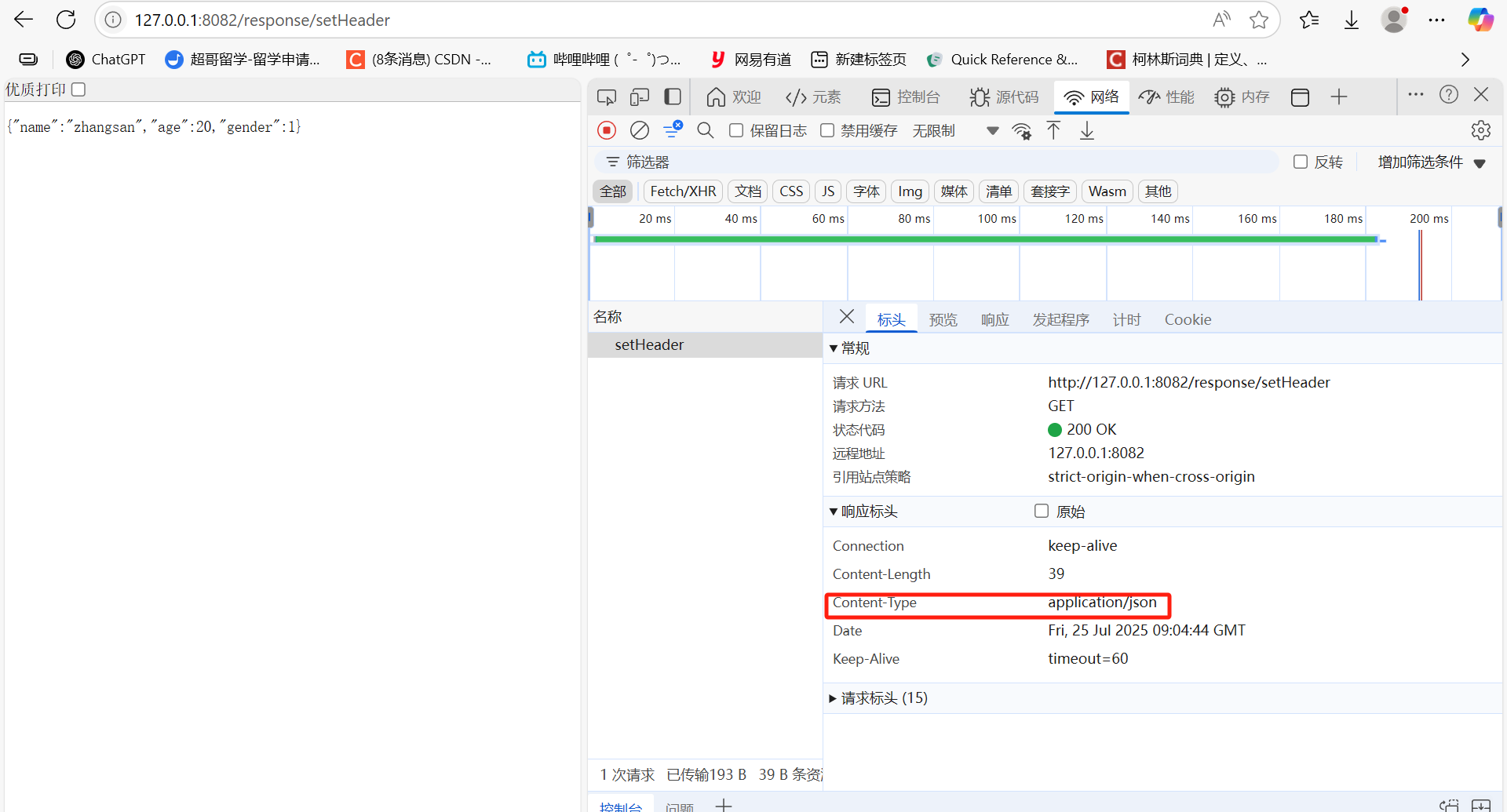
也可以这样设置:
@ResponseBody@RequestMapping("setHeader2")public void setHeader2(HttpServletResponse response){response.setHeader("test","myTest");}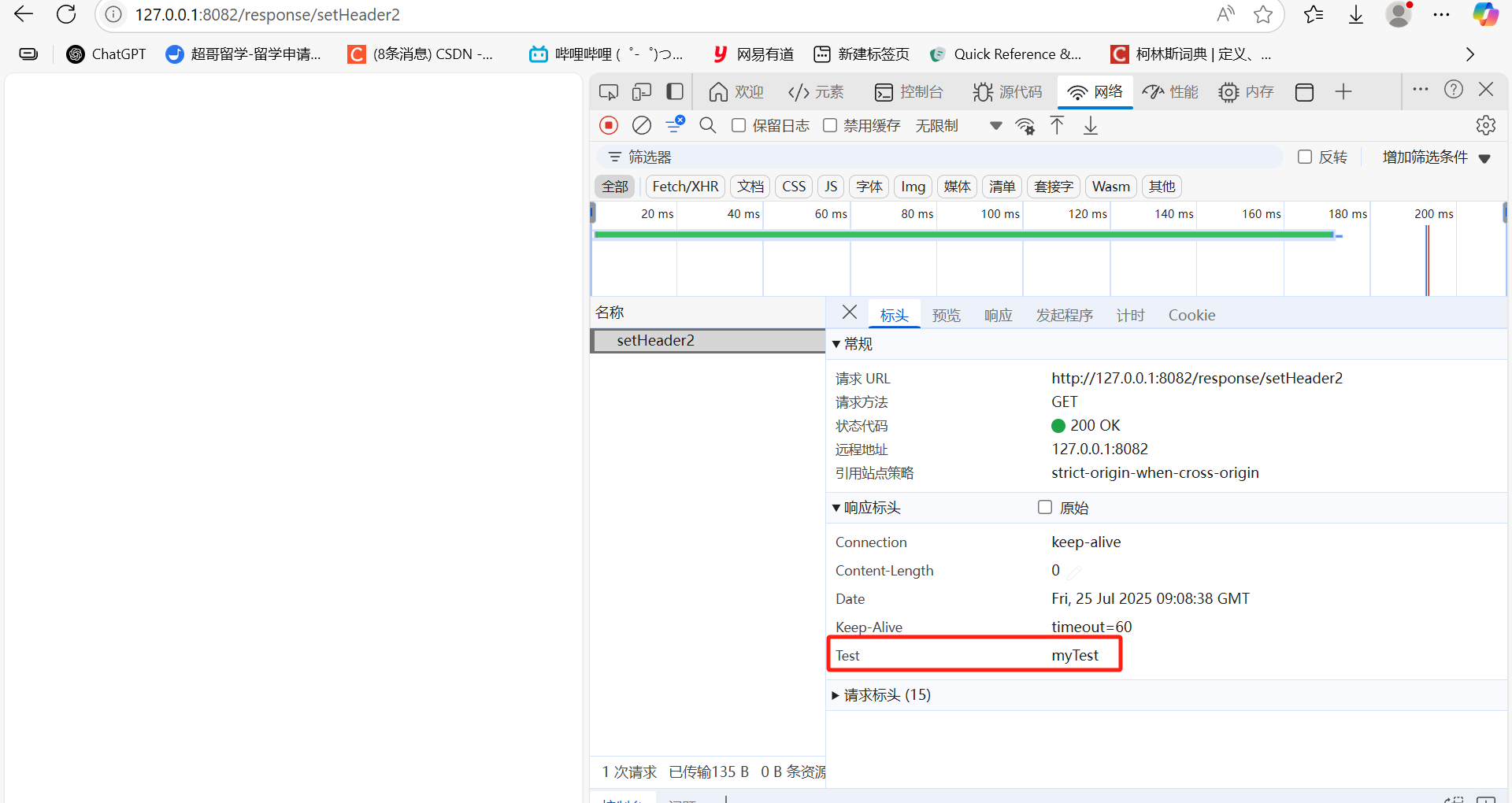
十一、MVC与三层架构:
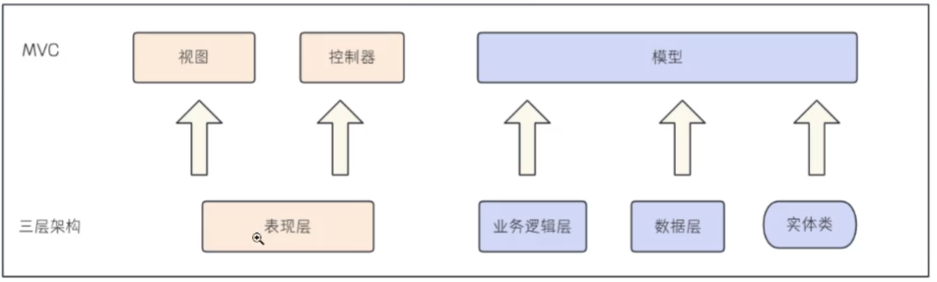
三层架构是现在开发中常用的设计模式:表现层、业务逻辑层、数据访问层
MVC强调数据和视图分离,将数据展示和数据处理分开,通过控制器对二者进行组合
三层架构强调不同维度数据处理的高内聚和低耦合,将交互页面,业务处理和数据库操作分开
总结:

