KNN算法:从原理到实战全解析
一 算法介绍
K近邻(K-Nearest Neighbors, KNN)是一种基于实例的监督学习算法,适用于分类和回归任务。其核心思想是通过计算待预测样本与训练集中样本的距离,选取距离最近的K个邻居,根据这些邻居的标签进行投票(分类)或均值计算(回归)来预测结果。
二 原理
-
距离度量:常用欧氏距离(Euclidean Distance)计算样本间的相似性,公式为:
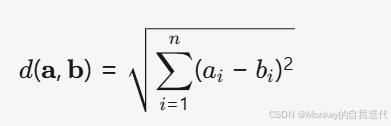
,这里表示a,b两点间的距离。其他可选距离包括曼哈顿距离、余弦相似度等。 -
K值选择:K是用户定义的超参数,影响模型复杂度。较小的K容易过拟合,较大的K可能忽略局部特征。通常通过交叉验证确定最优K值。
-
决策规则:
- 分类:统计K个邻居中最多数的类别作为预测结果。
- 回归:取K个邻居目标值的平均值作为预测输出。
三 具象化
根据上面原理我们知道主要是依据距离来判断的,可能会有点模糊,下面我来举例说明:
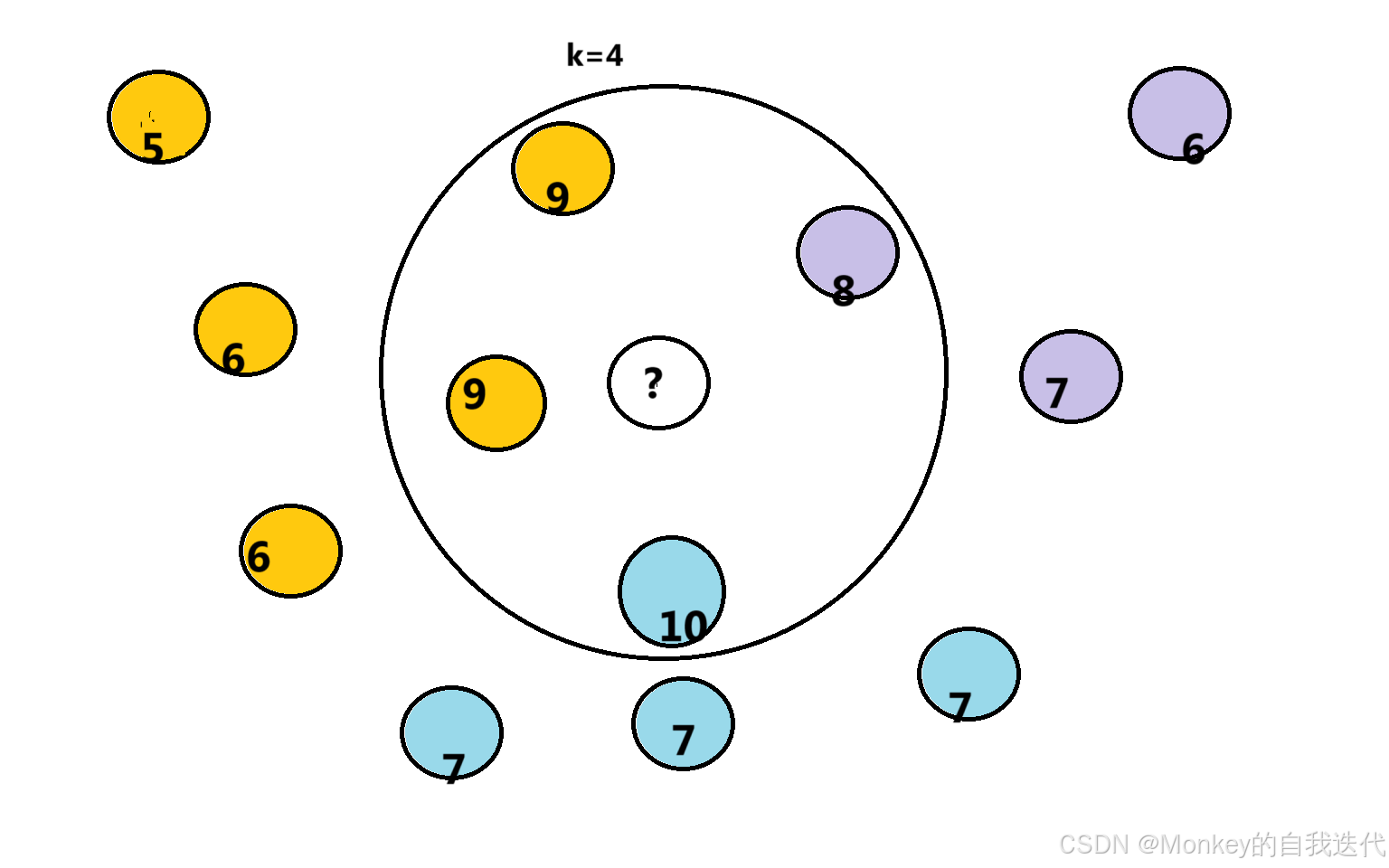
在图中表示有多个圈圈,每个圈圈都有各自的价格和颜色。
1 分类
在这个中,这里我们k=4,意思就是找具体他们最近的四个元素,如何找其中一个颜色最多的那个就把我们这个未知的归为那一类,这里我们距离是按坐标算的。我们可以想一下,这里每个圈圈的坐标就是它的特征,如果是其他类型的数据,我们也可以用他们的特征之间的差距,去找临近的一个,如何去分类
2 回归
这个和上面差不多,在找到最近的几个,如何依据他们的值,如何去求平均,就可以得到他们的具体值了。
四 代码实现
1 分类
# 导入库
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score# 加载数据
iris = load_iris()
X, y = iris.data, iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建KNN分类器(K=5)
knn_classifier = KNeighborsClassifier(n_neighbors=5)# 训练模型
knn_classifier.fit(X_train, y_train)# 预测并评估
y_pred = knn_classifier.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"分类准确率: {accuracy:.2f}") # 示例输出:分类准确率: 0.98[4,11](@ref)- 使用
sklearn.neighbors.KNeighborsClassifier实现分类。 - 通过
n_neighbors参数控制邻居数量(K值),默认K=5。
2 回归
# 导入库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsRegressor
from sklearn.metrics import mean_squared_error# 生成模拟数据
np.random.seed(0)
X = np.sort(5 * np.random.rand(100, 1), axis=0)
y = np.sin(X).ravel() + np.random.normal(0, 0.1, X.shape[0])# 划分训练集和测试集
X_train, X_test = X[:80], X[80:]
y_train, y_test = y[:80], y[80:]# 创建KNN回归器(K=3)
knn_regressor = KNeighborsRegressor(n_neighbors=3, weights='distance')# 训练模型
knn_regressor.fit(X_train, y_train)# 预测并评估
y_pred = knn_regressor.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f"均方误差(MSE): {mse:.4f}") # 示例输出:均方误差(MSE): 0.0123[6,7](@ref)我们会发现,python的sklearn包封装的特别好,我们几乎可以不用了解内部计算过程,只需要他是解决什么问题,有个大致了解就可以使用了。
扩展
我们从sklearn的官网上查看这个,有很多参数,下面我们拓展的讲几项。
KNeighborsClassifier(n_neighbors=5, *, weights='uniform', algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=无, n_jobs=无)[来源]
1 weights权重
这个就是,在我们计算的过程中,某些东西可能影响比较大,那么就会对最终结果印象较大。
用于预测的权重函数。可能的值:
-
'uniform' :统一的权重。每个邻域中的所有点 权重相等。
-
'distance' :按距离的倒数加权点。 在这种情况下,查询点的更近邻居将有一个 比距离较远的邻居具有更大的影响力。
-
[callable] :一个用户定义的函数,它接受 距离数组,并返回相同形状的数组 包含权重。
在统计学中,k-最近邻算法(k-NN)是一种非参数监督学习方法。它最初由 Evelyn Fix 和 Joseph Hodges 于 1951 年开发,[1]后来由 Thomas Cover 扩展。[2]大多数情况下,它用于分类,作为 k-NN 分类器,其输出是类成员资格。对象通过其邻居的多个投票进行分类,该对象被分配给其 k 个最近邻中最常见的类(k 是正整数,通常很小)。如果 k = 1,则对象被简单地分配给该单个最近邻的类。
k-NN 算法也可以推广用于回归。在 k-NN 回归(也称为最近邻平滑)中,输出是对象的属性值。该值是 k 个最近邻值的平均值。如果 k = 1,则输出将简单地分配给该单个最近邻的值,也称为最近邻插值。
对于分类和回归,一种有用的技术是为邻居的贡献分配权重,以便较近的邻居比远邻对平均值的贡献更大。例如,常见的加权方案包括为每个邻居提供 1/d 的权重,其中 d 是到邻居的距离。[3]
输入由数据集中最接近的 k 个训练示例组成。 邻居取自一组对象,其类(用于 k-NN 分类)或对象属性值(用于 k-NN 回归)已知。这可以被认为是算法的训练集,尽管不需要显式训练步骤。
k-NN 算法的一个特点(有时甚至是一个缺点)是它对数据的局部结构敏感。 在 k-NN 分类中,函数仅在局部近似,所有计算都推迟到函数评估。由于该算法依赖于距离,如果特征代表不同的物理单位或尺度差异很大,那么对训练数据进行特征归一化可以大大提高其准确性。[4]
参数选择
k 的最佳选择取决于数据;通常,较大的 k 值会降低噪声对分类的影响,[8]但使类之间的边界不那么明显。可以通过各种启发式技术选择一个好的 k(参见超参数优化)。该类被预测为最接近训练样本的类(即当 k = 1 时)的特殊情况称为最近邻算法。
k-NN 算法的准确性可能会因存在嘈杂或不相关的特征,或者如果特征尺度与其重要性不一致而严重下降。在选择或缩放特征以改进分类方面投入了大量研究工作。一种特别流行的[需要引用]方法是使用进化算法来优化特征缩放。[9]另一种流行的方法是通过训练数据与训练类的互信息来缩放特征。[需要引用]
在二元(两类)分类问题中,选择 k 作为奇数是有帮助的,因为这可以避免平局投票。在此设置中选择经验最优 k 的一种流行方法是通过引导方法。[10]
距离计算方法
1. 欧氏距离(Euclidean Distance)
2. 曼哈顿距离(Manhattan Distance)
3. 闵可夫斯基距离(Minkowski Distance)
4. 切比雪夫距离(Chebyshev Distance)
5. 马氏距离(Mahalanobis Distance)
6. 余弦相似度(Cosine Similarity)
7. 汉明距离(Hamming Distance)
8. 杰卡德距离(Jaccard Distance)
9. 布雷叶距离(Bray-Curtis Distance)
10. 马氏重合距离(Mahalanobis–Ovchinnikov Distance)